快速開始預置了中文標題生成模型,您可以直接部署該模型。針對定制化場景,您也可以使用自己的數據集對模型進行微調訓練。本文為您介紹如何在快速開始完成中文標題生成任務。
前提條件
已創建OSS Bucket存儲空間,具體操作請參見控制臺創建存儲空間。
一、進入模型詳情頁面
進入快速開始頁面。
登錄PAI控制臺。
在左側導航欄單擊工作空間列表,在工作空間列表頁面中單擊待操作的工作空間名稱,進入對應工作空間內。
在左側導航欄單擊快速開始,進入快速開始頁面。
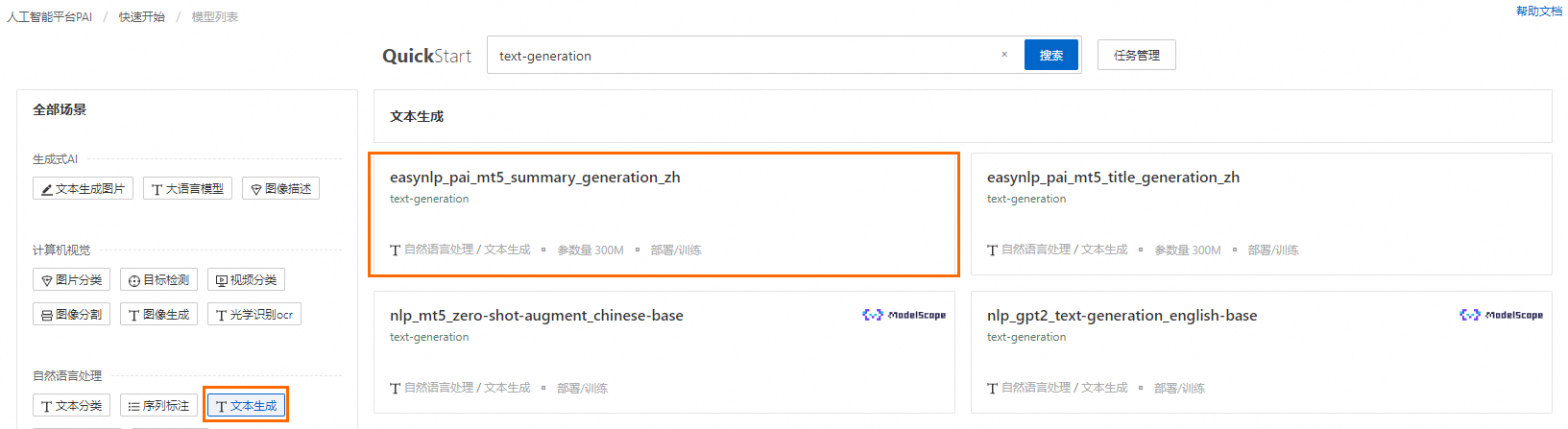
在快速開始首頁,單擊自然語言處理區域下的文本生成。在右側的模型列表中,單擊easynlp_pai_mt5_title_generation_zh模型卡片,進入模型詳情頁面。
二、直接部署和調試模型
部署模型服務
在模型詳情頁面,單擊模型部署。
在模型部署詳情頁面,確認部署信息后,單擊部署。
在計費提醒對話框中,單擊確定。
頁面將自動跳轉到服務詳情頁面。您可以在基本信息區域查看服務狀態。當狀態變為運行中時,表明服務部署成功。
在線調試模型
通過控制臺進行在線調試
在服務詳情頁面的在線預測文本框中輸入請求數據,請求數據示例如下。
{ "data": ["在廣州第一人民醫院,一個上午6名患者做支氣管鏡檢查,5人查出肺癌,且4人是老煙民!專家稱,吸煙和被動吸煙是肺癌的主要元兇。"] }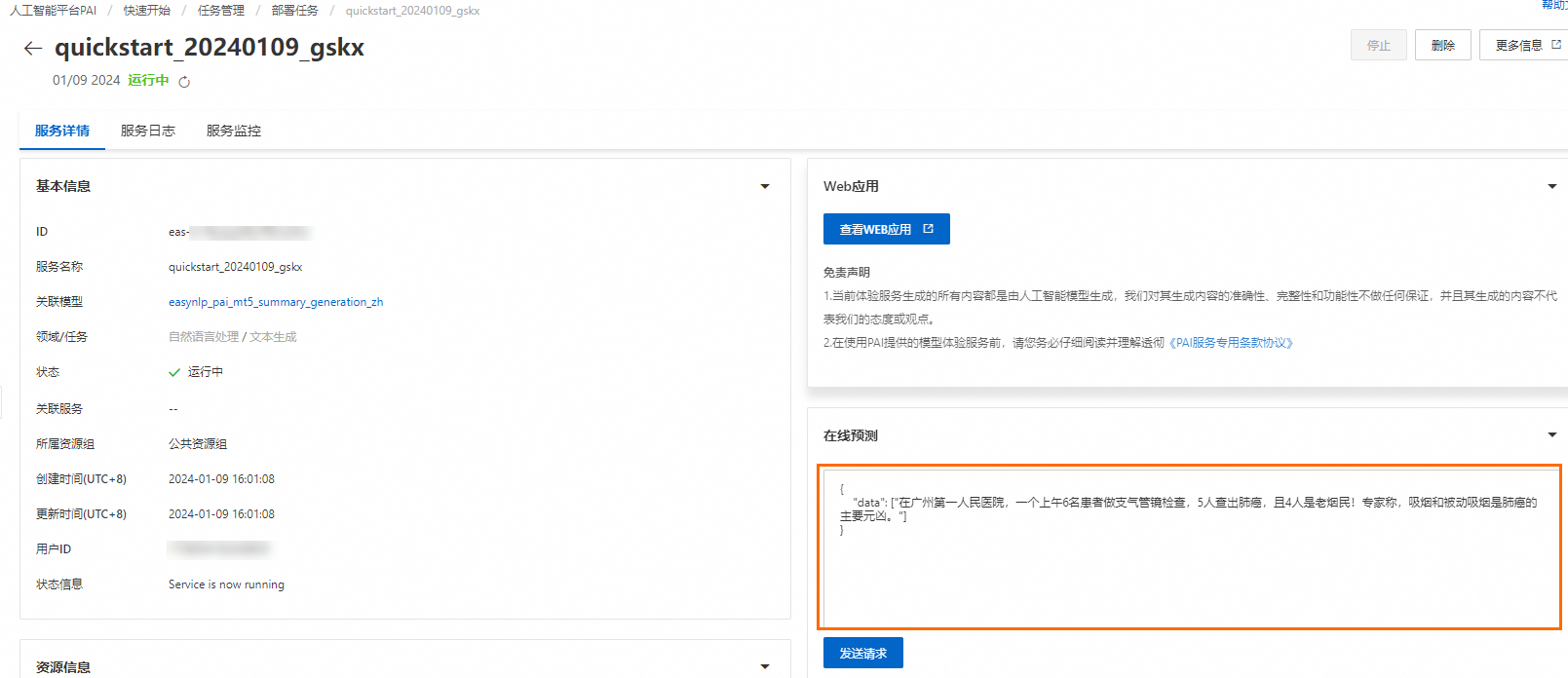
單擊發送請求。
您可以在頁面下方查看輸出結果。
通過Python代碼進行在線調試
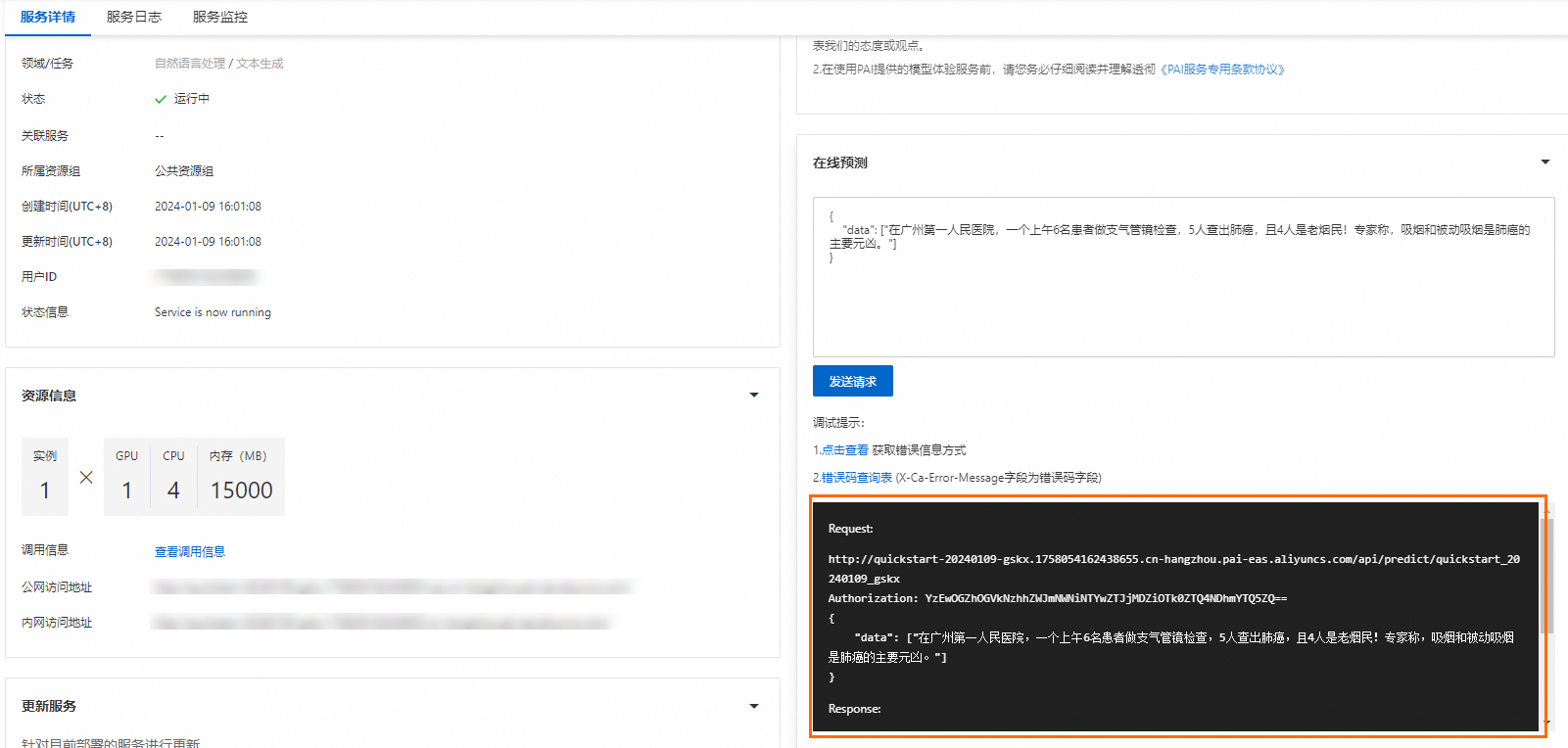
查看服務的調用信息。
在服務詳情頁面的資源信息區域,單擊查看調用信息。
在調用信息對話框的公網地址調用頁簽中,查看訪問地址和Token,并保存到本地。
使用以下示例代碼發送服務請求。
import requests url = "<PredictionServiceEndpoint>" token = "<PredictionServiceAccessToken>" request_body = '{"data": ["在廣州第一人民醫院,一個上午6名患者做支氣管鏡檢查,5人查出肺癌,且4人是老煙民!專家稱,吸煙和被動吸煙是肺癌的主要元兇。"]}' request_body = request_body.encode('utf-8') headers = {"Authorization": token} resp = requests.post(url=url, headers=headers, data=request_body) print(resp.content.decode()) print("status code:", resp.status_code)其中:url和token需要分別配置為上述步驟中保存到本地的訪問地址和Token。
系統返回結果如下圖所示。

三、微調訓練模型
(可選)準備數據集。
說明如果您希望使用自己的數據來微調訓練模型,可以按照以下操作步驟來準備訓練數據集。
快速開始提供了訓練數據集。您可以使用默認數據集,也可以自己準備數據。訓練數據格式為:
{"text": "<text>", "summary": "summary"} {"text": "<text>", "summary": "summary"} {"text": "<text>", "summary": "summary"} ...... {"text": "<text>", "summary": "summary"}將已準備的數據上傳到OSS存儲空間,具體操作,請參見控制臺上傳文件。
提交訓練作業。
返回模型詳情頁面,具體操作,請參見一、進入模型詳情頁面。
在模型訓練區域,將訓練設置>輸出路徑配置為OSS Bucket路徑,并單擊訓練。本示例使用默認數據集進行模型微調訓練。
說明如果您準備了訓練數據集,在模型訓練區域,參照微調訓練模型操作步驟更新訓練數據集后,再單擊訓練。
頁面將自動跳轉到任務詳情頁面。您可以單擊任務日志,查看訓練過程。
四、部署和調試微調后的模型
在任務詳情頁面模型部署區域,單擊部署。
頁面自動跳轉到服務詳情頁面,您可以在基本信息區域查看模型服務部署狀態。當狀態變為運行中時,表明模型服務已成功部署。
在線調試模型,具體操作,請參見在線調試模型。