分布式訓練(DLC)任務支持查看并監控資源狀況,并且提供了全面詳細的監控指標,幫助您更好地掌握資源負載情況。通過監控報警功能,您可以對DLC訓練任務的資源水位進行實時監控,并靈活地配置報警規則和報警通知。如果資源水位出現波動,例如GPU使用率超過設定閾值,則會發送報警通知。本文為您介紹如何通過云監控和ARMS查看監控數據、配置監控報警通知、訂閱監控指標等。
前提條件
設置DLC訓練任務的監控與報警,您需要先創建一個或多個DLC訓練任務。詳情請參見創建訓練任務。
使用限制
功能分類 | 支持的資源類型 | 支持的地域 |
DLC | 靈駿智算資源 |
|
通用計算資源 |
|
操作賬號和權限要求
阿里云主賬號:使用該賬號可完成所有操作,無需額外授權。
RAM賬號:
當您需要查看某個工作空間相應DLC任務的監控數據時,您需要為RAM賬號添加以下權限:
當您需要查看某個工作空間相應DLC任務的監控數據,并配置監控報警通知時,您需要為RAM賬號添加以下權限:
監控指標說明
監控指標主要包括CPU、內存、磁盤、網絡、RDMA、CPFS,以及GPU相關指標,如顯存使用率、算力使用率、SM設備使用率、PCIE及NVLink接收/發送數據量等。當前維度主要支持:作業(任務)維度、Pod(Worker)維度和GPU單卡維度。下面是一些典型的健康指標,全量指標列表及細節說明請參見分布式訓練(DLC)指標列表。
作業(任務)維度
監控指標 | 描述 |
CPU使用率(作業維度) | 指定作業的CPU使用百分比。 |
內存使用率(作業維度) | 指定作業的內存使用百分比。 |
磁盤讀取數據量(作業維度) | 指定作業的磁盤讀取數據量(MiB)。 |
磁盤寫入數據量(作業維度) | 指定作業的磁盤寫入數據量(MiB)。 |
網絡接收數據量(作業維度) | 指定作業的網絡接收數據量(MiB)。 |
網絡發送數據量(作業維度) | 指定作業的網絡發送數據量(MiB)。 |
GPU算力使用率(作業維度) | 指定作業的GPU算力使用率。 |
GPU顯存使用率(作業維度) | 指定作業的GPU顯存使用率。 |
GPU SM設備使用率(作業維度) | 指定作業的GPU SM設備使用率。 |
GPU設備功耗(作業維度) | 指定作業的GPU設備功耗。 |
GPU溫度(作業維度) | 指定作業的GPU溫度。 |
GPU整卡健康情況(作業維度) | 指定作業的包含的GPU整體健康情況(100%為健康,低于100%則存在部分卡異常)。 |
RDMA接收數據量(作業維度) | 指定作業的RDMA接收數據量。 |
RDMA發送數據量(作業維度) | 指定作業的RDMA發送數據量。 |
CPFS寫入數據量(作業維度) | 指定作業的CPFS設備寫入數據量(MB)。 |
CPFS讀取數據量(作業維度) | 指定作業的CPFS設備讀取數據量(MB)。 |
NVLink接收數據量(作業維度) | 指定作業的GPU設備NVLink上的接收數據量。 |
NVLink發送數據量(作業維度) | 指定作業的GPU設備NVLink上的發送數據量。 |
PCIE接收數據量(作業維度) | 指定作業的GPU設備PCIE上的接收數據量。 |
PCIE發送數據量(作業維度) | 指定作業的GPU設備PCIE上的發送數據量。 |
更多指標,請參考分布式訓練(DLC)指標列表。 | |
GPU單卡維度
監控指標 | 描述 |
GPU顯存設備接口使用率(卡維度) | 指定Pod的單張/多張卡的GPU顯存設備接口使用率。 |
GPU SM設備使用率(卡維度) | 指定Pod的單張/多張卡的GPU SM設備使用率。 |
GPU設備功耗(卡維度) | 指定Pod的單張/多張卡的GPU設備功耗。 |
GPU溫度(卡維度) | 指定Pod的單張/多張卡的GPU設備溫度。 |
GPU整卡健康情況(卡維度) | 指定Pod的單張/多張卡的GPU整體健康情況(100%為健康,低于100%則存在部分卡異常)。 |
更多指標,請參考分布式訓練(DLC)指標列表。 | |
Pod(Worker)維度
監控指標 | 描述 |
CPU使用率(Pod維度) | 指定Pod的CPU使用百分比。 |
內存使用率(Pod維度) | 指定Pod的內存使用百分比。 |
磁盤讀取數據量(Pod維度) | 指定Pod的磁盤讀取數據量(MiB)。 |
磁盤寫入數據量(Pod維度) | 指定Pod的磁盤寫入數據量(MiB)。 |
網絡接收數據量(Pod維度) | 指定Pod的網絡接收數據量(MiB)。 |
網絡發送數據量(Pod維度) | 指定Pod的網絡發送數據量(MiB)。 |
GPU算力使用率(Pod維度) | 指定Pod的GPU算力使用率。 |
GPU顯存使用率(Pod維度) | 指定Pod的GPU顯存使用率。 |
GPU SM設備使用率(Pod維度) | 指定Pod的GPU SM設備使用率。 |
GPU設備功耗(Pod維度) | 指定Pod的GPU設備功耗。 |
GPU溫度(Pod維度) | 指定Pod的GPU溫度。 |
GPU整卡健康情況(Pod維度) | 指定Pod的包含的GPU整體健康情況(100%為健康,低于100%則存在部分卡異常)。 |
RDMA接收數據量(Pod維度) | 指定Pod的RDMA接收數據量(MiB)。 |
RDMA發送數據量(Pod維度) | 指定Pod的RDMA發送數據量(MiB)。 |
CPFS讀取數據量(Pod維度) | 指定Pod的CPFS設備讀取數據量(MiB)。 |
CPFS寫入數據量(Pod維度) | 指定Pod的CPFS設備寫入數據量(MiB)。 |
NVLink接收數據量(Pod維度) | 指定Pod的GPU設備NVLink上的接收數據量。 |
NVLink發送數據量(Pod維度) | 指定Pod的GPU設備NVLink上的發送數據量。 |
PCIE接收數據量(Pod維度) | 指定Pod的GPU設備PCIE上的接收數據量。 |
PCIE發送數據量(Pod維度) | 指定Pod的GPU設備PCIE上的發送數據量。 |
更多指標,請參考分布式訓練(DLC)指標列表。 | |
使用云監控
云監控(CloudMonitor)是一項針對阿里云資源和互聯網應用進行監控的服務,為云上用戶提供開箱即用的企業級開放型一站式監控解決方案。您可以登錄云監控控制臺,查看PAI-分布式訓練(DLC)任務監控數據,并設置告警通知。云監控還支持通過API訂閱指標數據,助您建立自己的監控系統和數據大盤。更多關于云監控的詳細介紹,請參見什么是云監控。
計費說明
使用云監控服務會產生一定的費用,詳細的計費說明,請參見云監控計費說明。
查看監控數據
登錄云監控控制臺。
在左側導航欄,選擇。
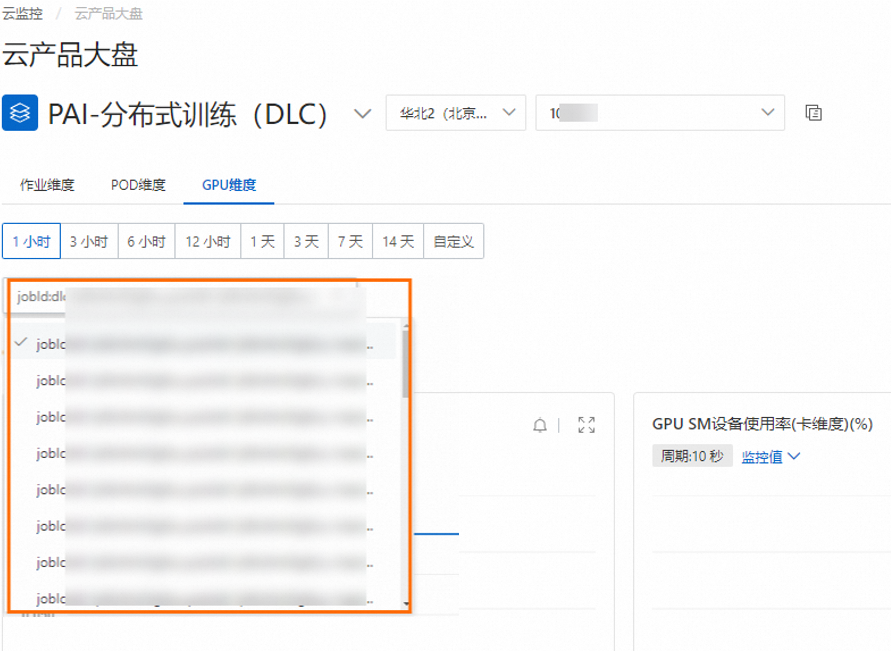
在云產品大盤頁面,選擇PAI-分布式訓練(DLC)。在搜索框內,選擇或搜索工作空間ID,該工作空間中DLC任務對應的監控圖表會在頁面下方展示。如何查詢工作空間ID,請參見管理工作空間。
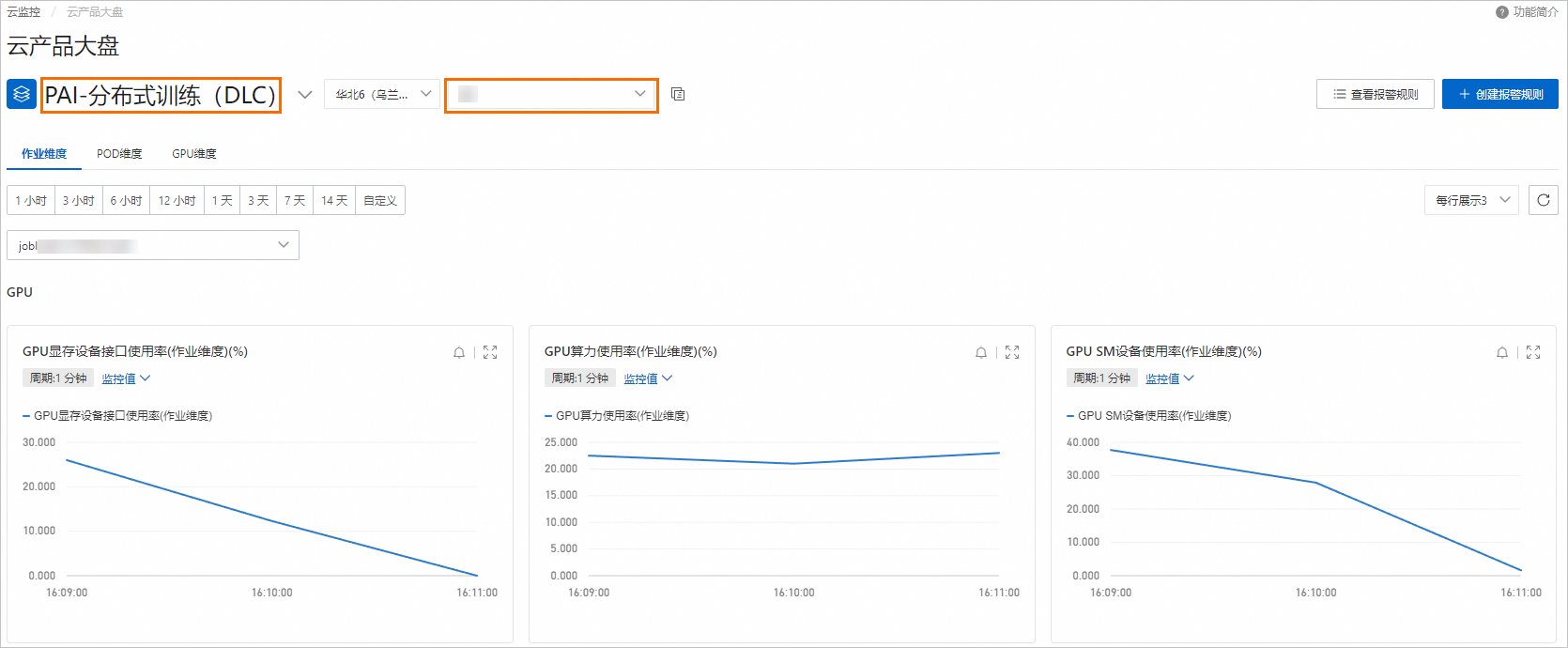 在對應監控圖表中,可以進行以下操作:
在對應監控圖表中,可以進行以下操作:切換監控維度:目前支持作業維度、POD(Worker)維度及GPU維度的監控指標展示。
單擊作業維度,您可以選擇或輸入DLC任務ID,查看單個任務的監控數據視圖。
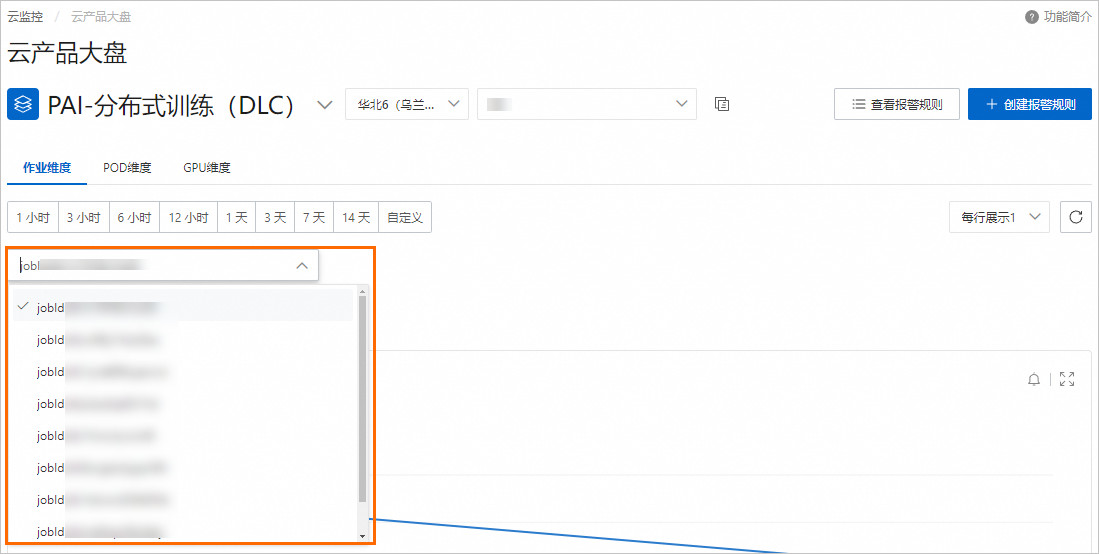
單擊POD維度,您可以選擇或輸入POD ID,查看單個POD的監控數據視圖。
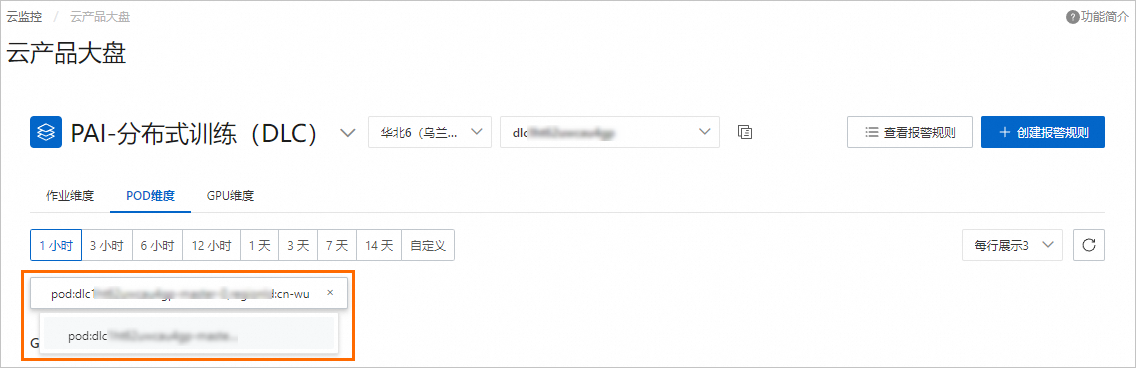
單擊GPU維度,您可以選擇或輸入POD ID,查看指定DLC任務單個POD的GPU維度的監控數據視圖。
切換展示時間范圍:

放大視圖:您可以單擊每個圖表右上角的放大按鈕
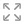 ,查看監控數據的細節視圖。
,查看監控數據的細節視圖。
配置監控報警
通過監控報警功能,您可以監控分布式訓練(DLC)任務的資源水位,并靈活地配置報警規則。如果資源水位出現波動,例如低于配置的報警規則時,則會發送報警通知。本章節為您介紹如何通過云監控控制臺和API的方式,配置監控報警功能。
配置報警聯系人
創建報警聯系人。
登錄云監控控制臺。
在左側導航欄,選擇。
在報警聯系人頁簽,單擊創建聯系人。
在設置報警聯系人面板,填寫報警聯系人的姓名、手機號碼、郵箱和Webhook地址,其他參數均保持默認值。
說明報警通知信息語言默認為自動,表示云監控根據當前阿里云賬號注冊時的語言,自動適配報警通知信息的語言。
信息驗證無誤后,單擊確認。
創建報警聯系組。
登錄云監控控制臺。
在左側導航欄,選擇。
單擊報警聯系組頁簽。
在報警聯系組頁簽,單擊新建聯系人組。
在新建聯系人組面板,填寫報警聯系人組的組名,并選擇已有報警聯系人。
單擊確認。
配置報警規則
在云監控控制臺的左側導航欄,選擇。
在云產品監控頁面,搜索并進入PAI-分布式訓練(DLC)。
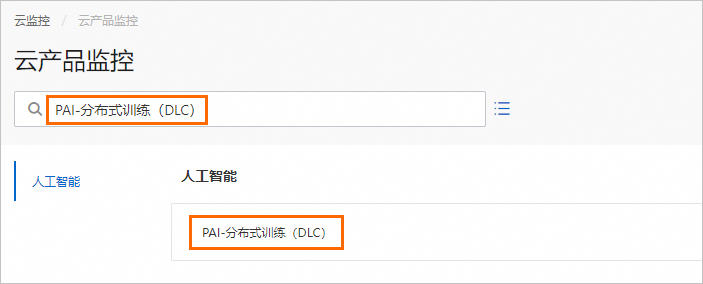
在PAI-分布式訓練(DLC)頁面,選擇服務所在的地域,并單擊創建報警規則。
在創建報警規則面板,配置下列參數,并單擊確認。
參數
描述
產品
云監控管理的產品名稱,選擇PAI-分布式訓練(DLC)。
資源范圍
報警規則的作用范圍,目前支持全部資源、實例(作業):
全部資源:DLC的任何資源滿足報警規則,都會發送報警通知。
實例:根據您選定的產品,您需要在關聯資源中添加需要關聯的工作空間。僅添加的工作空間下的DLC作業滿足報警規則時,才發送報警通知。
規則描述
報警規則主體,當監控數據滿足指定條件時,觸發報警規則。規則描述的設置方法,請參見創建報警規則。
通道沉默周期
報警發生后如果未恢復正常,間隔多久重復發送一次報警通知。
生效時間
報警規則的生效時間。報警規則只在生效時間內才會檢查監控數據是否需要報警。
標簽
自定義設置報警規則的標簽。包括標簽名稱和標簽值。
報警聯系人組
發送報警的聯系人組,選擇已綁定報警聯系人的報警組。
在PAI-分布式訓練(DLC)頁面,單擊查看報警規則,即可查看已創建的報警規則詳情、報警歷史等,并支持修改規則。
您可以通過調用API的方式,配置監控報警服務,功能包括查看報警歷史、管理報警模板、配置報警規則和報警聯系人等。具體調用方法和詳情介紹,請參見云監控API目錄:報警服務。
訂閱監控指標
云監控提供完善的API服務,您可以通過調用API的方式,訂閱DLC的監控指標及數據,搭建自己的監控系統和數據大盤。具體操作步驟,請參見云產品監控API目錄。
云監控API | API概述 |
調用DescribeMetricLast接口查詢指定監控項的最新監控數據。 | |
調用DescribeMetricList接口查詢指定云產品的指定監控項的監控數據。 | |
調用DescribeMetricData接口查詢指定云產品的某個監控項的監控數據。 | |
調用DescribeMetricMetaList接口查詢云監控開放的監控項詳情。 | |
調用DescribeProjectMeta接口查詢云監控支持的時序類監控項產品列表。 | |
調用DescribeMetricTop接口先查詢指定云產品的指定監控項的最新監控數據,再查詢該監控項排序后的監控數據。 |
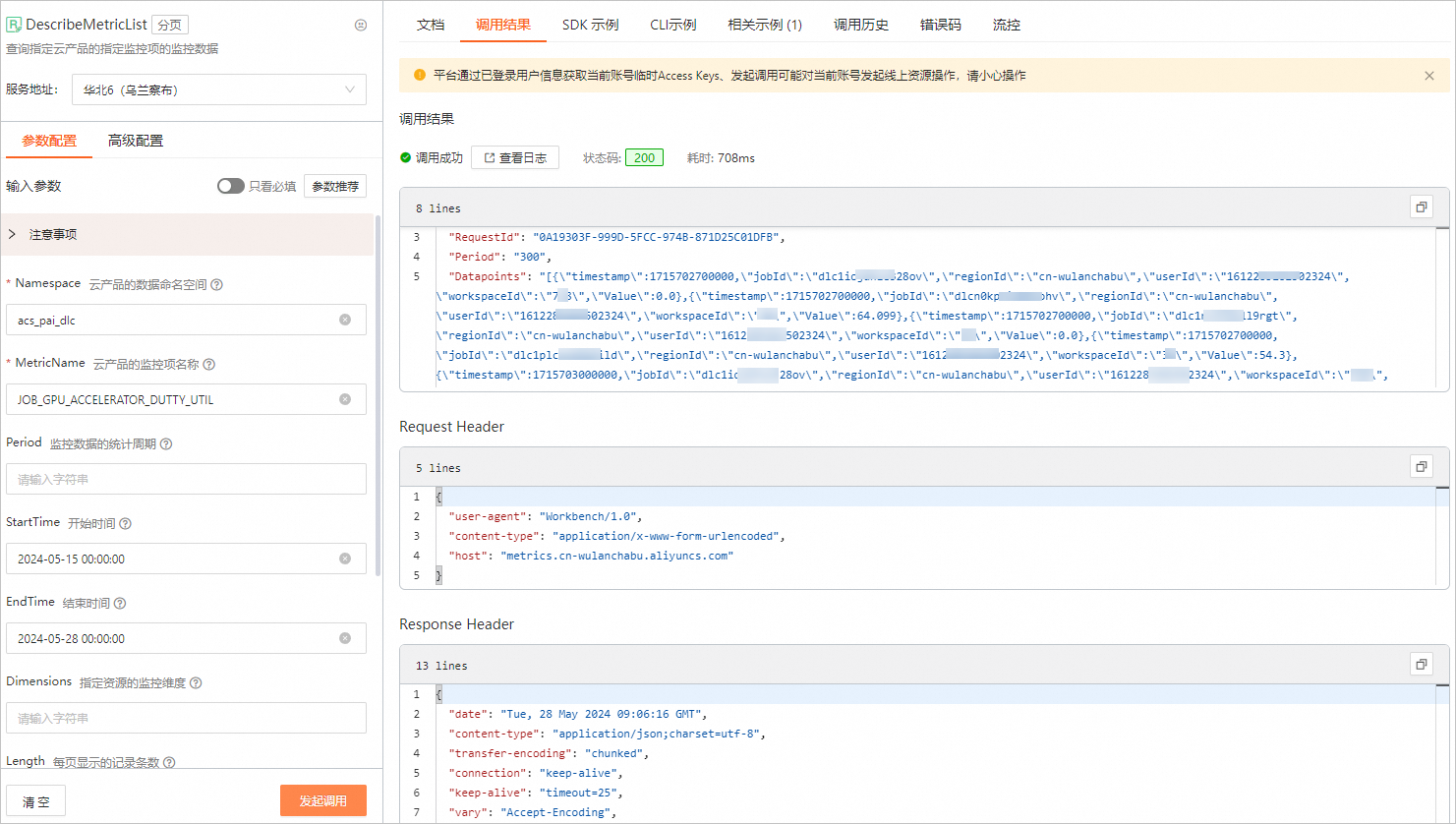
以DescribeMetricList接口為例,為您說明如何調用該API來查詢PAI-分布式訓練(DLC)產品下指定指標的監控數據。
前往分布式訓練(DLC)指標列表頁面。
在指標列表頁面,單擊目標指標操作列下的獲取指標數據。

在OpenAPI門戶頁面,配置以下關鍵參數,其他參數取默認配置。更多參數配置說明,請參見DescribeMetricList。
參數
描述
Namespace
配置為acs_pai_dlc。
MetricName
配置對應的監控指標。例如CARD_GPU_DRAM_ACTIVE_UTIL。
StartTime
開始時間。例如2024-05-15 00:00:00。
EndTime
結束時間。例如2024-05-28 00:00:00。
說明StartTime和EndTime之間的間隔小于等于31天。
參數配置完成后,單擊發起調用,即可查看相應時間的監控數據。
使用ARMS
應用實時監控服務ARMS(Application Real-Time Monitoring Service)是一款阿里云云原生可觀測產品平臺。基于ARMS提供的能力,您可以自定義一套PAI-DLC分布式訓練服務的Grafana大盤,以及使用Prometheus配置靈活的報警規則,幫助您全面詳細地監控DLC任務指標數據。關于ARMS更詳細的內容介紹,請參見應用實時監控服務ARMS。
計費說明
使用ARMS服務會產生一定的費用,詳細的計費說明,請參見ARMS計費說明。
接入監控數據
具體操作步驟如下:
登錄ARMS控制臺,然后在左側導航欄,單擊接入中心。
在接入中心頁面,單擊左側人工智能頁簽,然后單擊阿里云 PAI-DLC分布式訓練服務。
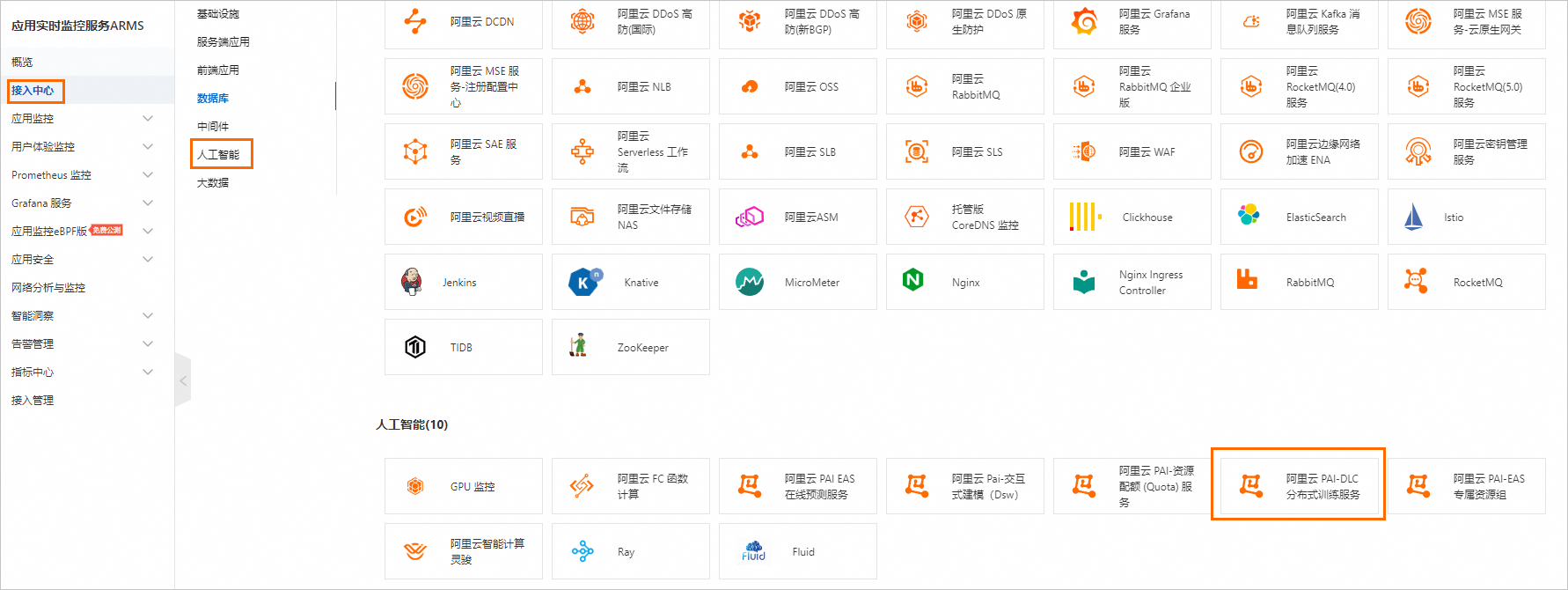
在彈出面板的開始接入頁簽,選擇數據存儲地域并配置接入名稱,然后單擊確定。
大約需要等待1~2分鐘,即可完成PAI-DLC分布式訓練服務的接入。您也可以切換到效果預覽、采集指標及告警規則模板頁簽,分別查看指標監控大盤、支持采集的指標以及告警規則名稱和模板詳情。
安裝完成后,您可以單擊接入管理,查看已接入環境的詳細信息。
查看Grafana大盤
進入云服務環境詳情頁面。具體操作,請參見步驟二:查看監控大盤。
在組件管理頁簽的組件類型區域,選擇阿里云PAI-DLC分布式訓練服務,并單擊右側的大盤,即可查看內置的Grafana大盤。

單擊大盤名稱,查看監控大盤。

配置Prometheus報警
您可以通過Prometheus配置監控報警,具體操作步驟如下:
進入云服務環境詳情頁面。具體操作,請參見步驟二:查看監控大盤。
在組件管理的組件類型列表中,選擇阿里云PAI-DLC分布式訓練服務并單擊告警規則,即可查看內置的告警規則。
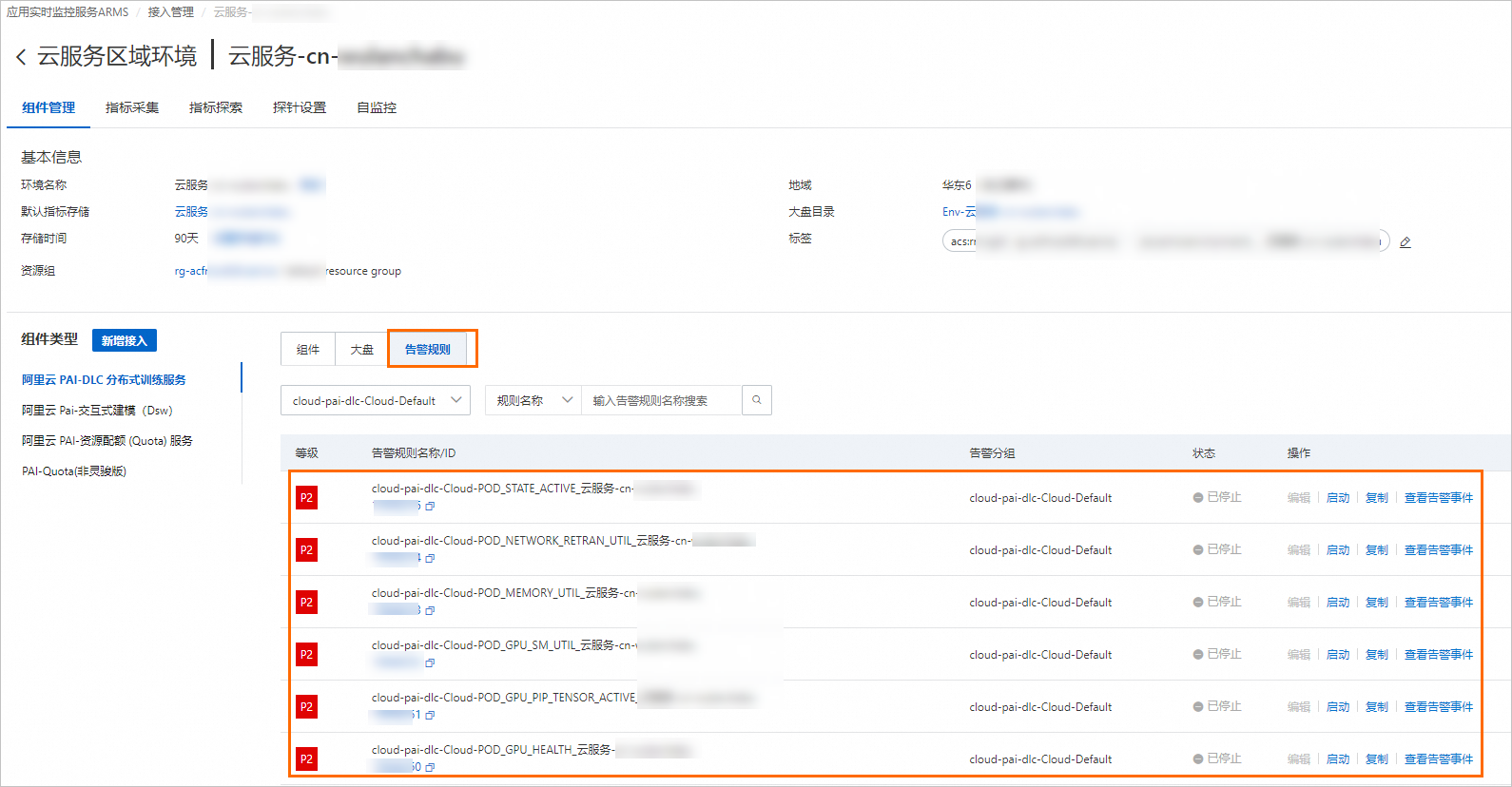
內置的告警規則會產生告警事件,但是不會進行告警通知,您可以通過以下兩種配置方法將告警通知發送到郵件或其他平臺:
通過設置通知策略,制定針對告警事件的匹配規則。當匹配規則被觸發時,系統會以您指定的通知方式向通知對象發送告警信息。具體操作,請參見通知策略。
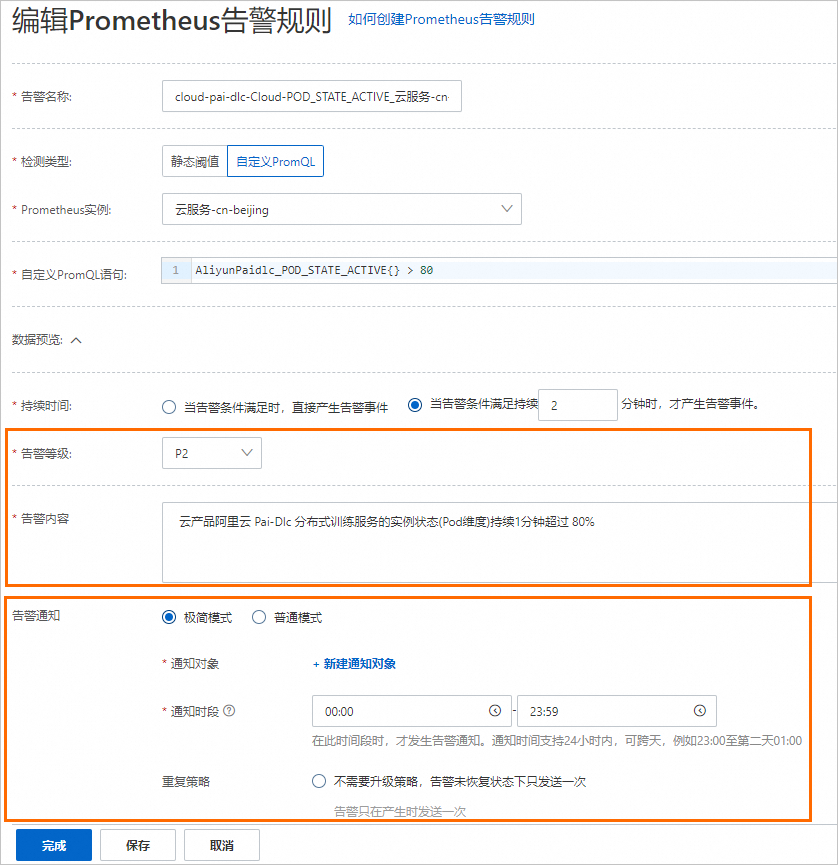
通過編輯告警規則配置通知方式。
 在編輯Prometheus告警規則頁面,您也可以自定義告警條件、持續時間、告警內容以及告警通知等。有關告警詳細配置的信息,請參見Prometheus告警規則。
在編輯Prometheus告警規則頁面,您也可以自定義告警條件、持續時間、告警內容以及告警通知等。有關告警詳細配置的信息,請參見Prometheus告警規則。