PageRank算法用于衡量網頁的重要性。它通過分析超鏈接,認為鏈接到某網頁的數量和質量可以表明該網頁的重要性。網頁獲得的鏈接越多,它的排名越高,同時,鏈接來源的權重也會影響最終的PageRank分數。PageRank組件能夠輸出各節點的權重。
算法說明
PageRank算法是一種基于鏈接分析的方法,用于評估網頁的相對重要性。核心原則如下:
如果一個網頁被眾多其他網頁所鏈接,那么它通常被認為是更重要或質量更高的資源。
算法不僅計算指向該網頁的鏈接數量,還考慮了每個鏈接網頁本身的權重,即這些網頁本身的PageRank值,以及它們指向其他網頁的鏈接數。
在用戶構成的社交網絡中,PageRank理念同樣適用。用戶的影響力不僅由其個人屬性決定,也受到其社交聯系的質量的影響。例如,在新浪微博中,一個用戶對其粉絲群體的影響力會受到和粉絲之間關系密切程度的影響,與用戶關系較親近的家人、同學、同事等通常會受到更大的影響。在這種人際網絡模型中,邊的權重反映了用戶之間關系的親密程度,被視作關系強度的指標。
帶鏈接權重的PageRank公式為: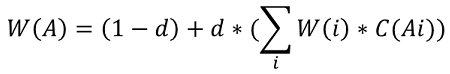
W(i):節點i的權重。
C(Ai):鏈接權重。
d:阻尼系數。
W(A):算法迭代穩定后的節點權重,即每個用戶的影響力指數。
配置組件
方法一:可視化方式
在Designer工作流頁面添加PageRank組件,并在界面右側配置相關參數:
參數類型 | 參數 | 描述 |
字段設置 | 選擇源頂點列 | 邊表的起點所在列。 |
選擇目標頂點列 | 邊表的終點所在列。 | |
選擇邊權值列 | 邊表邊的權重所在列。 | |
參數設置 | 最大迭代次數 | 算法自身會收斂并停止迭代,默認值為30。 |
阻尼系數 | 在任意時刻,用戶到達某網頁后并繼續向后瀏覽的概率。 | |
執行調優 | 進程數 | 作業并行執行的節點數。數字越大并行度越高,但是框架通訊開銷會增大。 |
進程內存 | 單個作業可使用的最大內存量,單位:MB,默認值為4096。 如果實際使用內存超過該值,會拋出 |
方法二:PAI命令方式
使用PAI命令配置PageRank組件參數。您可以使用SQL腳本組件進行PAI命令調用,詳情請參見場景4:在SQL腳本組件中執行PAI命令。
PAI -name PageRankWithWeight
-project algo_public
-DinputEdgeTableName=PageRankWithWeight_func_test_edge
-DfromVertexCol=flow_out_id
-DtoVertexCol=flow_in_id
-DoutputTableName=PageRankWithWeight_func_test_result
-DhasEdgeWeight=true
-DedgeWeightCol=weight
-DmaxIter 100;參數 | 是否必選 | 默認值 | 描述 |
inputEdgeTableName | 是 | 無 | 輸入邊表名。 |
inputEdgeTablePartitions | 否 | 全表讀入 | 輸入邊表的分區。 |
fromVertexCol | 是 | 無 | 輸入邊表的起點所在列。 |
toVertexCol | 是 | 無 | 輸入邊表的終點所在列。 |
outputTableName | 是 | 無 | 輸出表名。 |
outputTablePartitions | 否 | 無 | 輸出表的分區。 |
lifecycle | 否 | 無 | 輸出表的生命周期。 |
workerNum | 否 | 未設置 | 作業并行執行的節點數。數字越大并行度越高,但是框架通訊開銷會增大。 |
workerMem | 否 | 4096 | 單個作業可使用的最大內存量,單位:MB,默認值為4096。 如果實際使用內存超過該值,會拋出 |
splitSize | 否 | 64 | 數據切分的大小,單位:MB。 |
hasEdgeWeight | 否 | false | 輸入邊表的邊是否有權重。 |
edgeWeightCol | 否 | 無 | 輸入邊表邊的權重所在列。 |
maxIter | 否 | 30 | 最大迭代次數。 |
使用示例
添加SQL腳本組件,輸入以下SQL語句生成訓練數據。
drop table if exists PageRankWithWeight_func_test_edge; create table PageRankWithWeight_func_test_edge as select * from ( select 'a' as flow_out_id,'b' as flow_in_id,1.0 as weight union all select 'a' as flow_out_id,'c' as flow_in_id,1.0 as weight union all select 'b' as flow_out_id,'c' as flow_in_id,1.0 as weight union all select 'b' as flow_out_id,'d' as flow_in_id,1.0 as weight union all select 'c' as flow_out_id,'d' as flow_in_id,1.0 as weight )tmp;對應的數據結構圖:
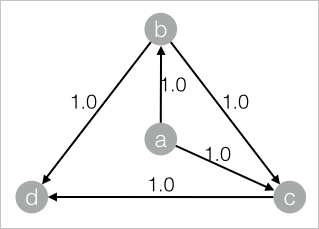
添加SQL腳本組件,輸入以下PAI命令進行訓練。
drop table if exists ${o1}; PAI -name PageRankWithWeight -project algo_public -DinputEdgeTableName=PageRankWithWeight_func_test_edge -DfromVertexCol=flow_out_id -DtoVertexCol=flow_in_id -DoutputTableName=${o1} -DhasEdgeWeight=true -DedgeWeightCol=weight -DmaxIter 100;右擊上一步的組件,選擇查看數據 > SQL腳本的輸出,查看訓練結果。
| node | weight | | ---- | ---------- | | a | 0.12841452 | | b | 0.18299069 | | c | 0.26076174 | | d | 0.42783305 |