本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
PAI-TensorFlow支持讀取OSS對象存儲數據和MaxCompute表數據。
公共云GPU服務器即將過保下線,您可以繼續提交CPU版本的TensorFlow任務。如需使用GPU進行模型訓練,請前往DLC提交任務,具體操作請參見創建訓練任務。
讀取OSS數據
主流程 | 描述 |
上傳數據至OSS 使用深度學習處理數據時,數據需要先存儲到OSS的Bucket中。 |
|
OSS授權 | 當您在PAI中讀寫OSS Bucket組件時,需要授予AliyunODPSPAIDefaultRole系統默認角色給數加服務賬號,詳情請參見PAI服務賬號授權。 |
RAM授權 RAM授權可以使PAI獲得OSS的訪問權限 | 獲取PAI訪問OSS的權限,詳情請參見依賴的其他云產品:OSS。 |
TensorFlow讀取OSS數據 | 連接組件讀OSS數據和TensorFlow。 |
默認角色AliyunODPSPAIDefaultRole包含權限信息如下。
權限名稱(Action) | 權限說明 |
oss:PutObject | 上傳文件或文件夾對象 |
oss:GetObject | 獲取文件或文件夾對象 |
oss:ListObjects | 查詢文件列表信息 |
oss:DeleteObjects | 刪除對象 |
TensorFlow讀取OSS數據的方法:
低效的IO方式
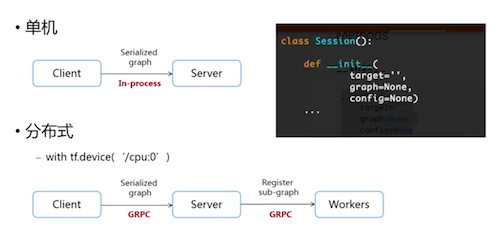
本地執行TensorFlow代碼和分布式云端執行TensorFlow的區別:
本地讀取數據:Server端直接從Client端獲取Graph進行計算。
云端服務:Server獲得Graph后,還需要將計算下發至各Worker處理。
注意事項
不建議使用Python本地讀取文件的方式。
PAI支持Python自帶IO方式,但需要將數據源和代碼打包上傳。這種讀取方式是將數據寫入內存之后再計算,效率比較低,不建議使用。示例代碼如下。
import csv csv_reader=csv.reader(open('csvtest.csv')) for row in csv_reader: print(row)不建議使用第三方庫讀取文件的方式。
使用第三方庫(如TFLearn、Pandas)的數據IO方式讀取數據。通常,第三方庫是通過封裝Python的讀取方式實現,所以在PAI使用時也會造成效率低下的問題。
不建議使用Preload讀取文件的方式。
如果您發現GPU并沒有比本地的CPU速度快很多,則有可能是數據IO,導致性能浪費。Preload讀取方式先將數據全部都讀到內存中,然后再通過Session計算,例如Feed讀取方式。這樣會造成性能浪費,同時內存限制也無法計算大數據。
例如,硬盤中有圖片數據集0001.jpg,0002.jpg,0003.jpg,…… 。先讀取數據后再計算,假設讀入用時0.1s,計算用時0.9s,這樣每過1s,GPU都會有0.1s空閑,降低了運算的效率。

高效的IO方式
TensorFlow讀取方式是將數據讀取轉換成OP,通過Session.run的方式讀取數據。讀取線程將文件系統中的圖片讀入到一個內存的隊列中。計算是另一個線程,并直接從內存隊列中讀取進行計算。這樣解決了GPU因IO空閑而浪費性能的問題。

在PAI通過OP的方式讀取數據的代碼如下。
import argparse import tensorflow as tf import os FLAGS=None def main(_): dirname = os.path.join(FLAGS.buckets, "csvtest.csv") reader=tf.TextLineReader() filename_queue=tf.train.string_input_producer([dirname]) key,value=reader.read(filename_queue) record_defaults=[[''],[''],[''],[''],['']] d1, d2, d3, d4, d5= tf.decode_csv(value, record_defaults, ',') init=tf.initialize_all_variables() with tf.Session() as sess: sess.run(init) coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess,coord=coord) for i in range(4): print(sess.run(d2)) coord.request_stop() coord.join(threads) if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--buckets', type=str, default='', help='input data path') parser.add_argument('--checkpointDir', type=str, default='', help='output model path') FLAGS, _ = parser.parse_known_args() tf.app.run(main=main)其中:
dirname:OSS文件路徑,可以是數組。
reader:TensorFlow內置各種類型reader API,可以根據需求選用。
tf.train.string_input_producer:將文件生成隊列。
tf.decode_csv:是一個Splite功能的OP,可以獲取每一行的特定參數。
通過OP獲取數據,在Session中需要tf.train.Coordinator()和tf.train.start_queue_runners(sess=sess,coord=coord)。
讀取MaxCompute數據
您可以直接使用Designer的TensorFlow組件讀寫MaxCompute數據。
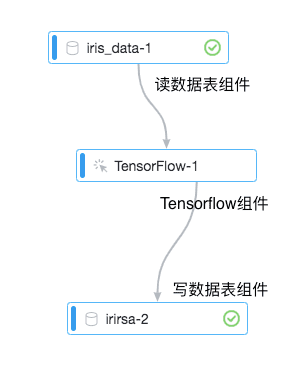
下文以iris數據集為例,為您介紹如何讀取MaxCompute數據。
主流程 | 描述 |
連接組件 | 拖動組件并連接。 |
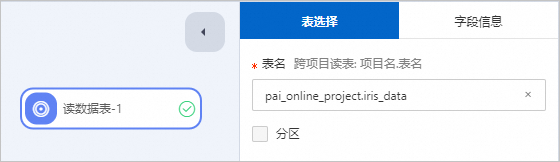
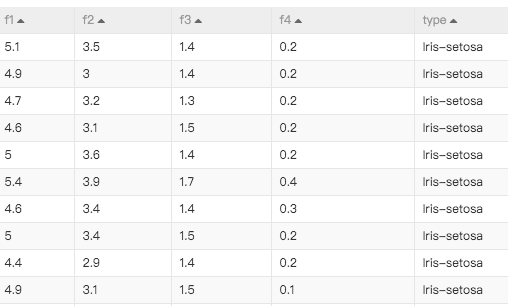
配置讀數據表組件 | 在讀數據表組件中,輸入如下代碼。 即可獲取數據。 數據格式如下。 |
配置Tensorflow組件 |
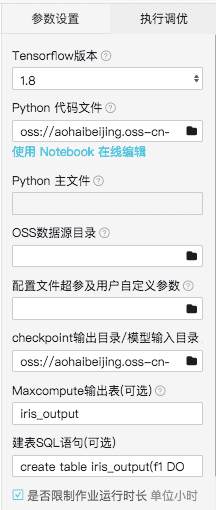
如果輸入MaxCompute表,輸出也是MaxCompute表,則只需要接入②和⑤。 讀寫MaxCompute表需要配置數據源、代碼文件、輸出模型路徑、建表等操作。
組件API命令 其中,${}類型的參數需要替換成您的真實數據。 |
讀數據表 | 推薦通過TableRecordDataset讀寫MaxCompute表,詳細的接口使用說明及示例請參見TableRecordDataset。 |
寫數據表 |