TF-IDF(Term Frequency-Inverse Document Frequency)是一種用于資訊檢索與文本挖掘的常用加權技術。通常在搜索引擎中應用,可以作為文件與用戶查詢之間相關程度的度量或評級。
TF詞頻(Term Frequency)是指某一個給定的詞語在該文件中出現(xiàn)的次數。IDF反文檔頻率(Inverse Document Frequency)是指如果包含詞條的文檔越少,IDF越大,則說明詞條的類別區(qū)分能力越強。
TF-IDF是一種統(tǒng)計方法,用于評估字詞或文件的重要程度。例如:
在文件集中的字詞會隨著出現(xiàn)次數的增加呈正比增加趨勢。
在語料庫中的文件會隨著出現(xiàn)頻率的增加呈反比下降趨勢。
TF-IDF組件基于詞頻統(tǒng)計算法的輸出結果(而不是基于原始文檔),計算各詞語對于各文章的TF-IDF值。
使用說明
由于TF-IDF組件是基于詞頻統(tǒng)計算法的輸出結果,因此TF-IDF組件需要接入到詞頻統(tǒng)計組件的下游。
組件配置
您可以使用以下任意一種方式,配置TF-IDF組件參數。
方式一:可視化方式
在Designer工作流頁面配置組件參數。
頁簽 | 參數 | 描述 |
字段設置 | 選擇文檔ID列 | 您可以直接選擇詞頻統(tǒng)計組件輸出的文檔ID列(id列)或自行將原始文檔處理為相應格式,詳情請參見詞頻統(tǒng)計示例部分的輸出介紹。 |
選擇單詞列 | 您可以直接選擇詞頻統(tǒng)計組件輸出的單詞列(word列)或自行將原始文檔處理為相應格式,詳情請參見詞頻統(tǒng)計示例部分的輸出介紹。 | |
選擇單詞計數列 | 您可以直接選擇詞頻統(tǒng)計組件輸出的單詞計數列(count列)或自行將原始文檔處理為相應格式,詳情請參見詞頻統(tǒng)計示例部分的輸出介紹。 | |
執(zhí)行調優(yōu) | 計算核心數 | 節(jié)點個數,默認自動計算。 |
每個核心內存 | 單個節(jié)點內存大小,單位為MB。 |
方式二:PAI命令方式
使用PAI命令方式,配置該組件參數。您可以使用SQL腳本組件進行PAI命令調用,詳情請參見SQL腳本。
PAI -name tfidf
-project algo_public
-DinputTableName=rgdoc_split_triple_out
-DdocIdCol=id
-DwordCol=word
-DcountCol=count
-DoutputTableName=rg_tfidf_out;參數名稱 | 是否必選 | 描述 | 默認值 |
inputTableName | 是 | 輸入表名稱。 | 無 |
inputTablePartitions | 否 | 輸入表中,參與訓練的分區(qū)。 格式為 | 輸入表的所有分區(qū) |
docIdCol | 是 | 標識文章ID的列名,僅可指定一列。 | 無 |
wordCol | 是 | Word列名,僅可指定一列。 | 無 |
countCol | 是 | Count列名,僅可指定一列。 | 無 |
outputTableName | 是 | 輸出表名稱。 | 無 |
lifecycle | 否 | 輸出表生命周期。正整數。單位:天 | 無 |
coreNum | 否 | 核心數,與memSizePerCore同時設置才生效。 | 自動計算 |
memSizePerCore | 否 | 內存數,與coreNum同時設置才生效。 | 自動計算 |
示例
以TF-IDF組件實例中的輸出表作為TF-IDF組件的輸入表,對應的參數設置如下:
選擇文檔ID列: id
選擇單詞列:word
選擇單詞計數列:count
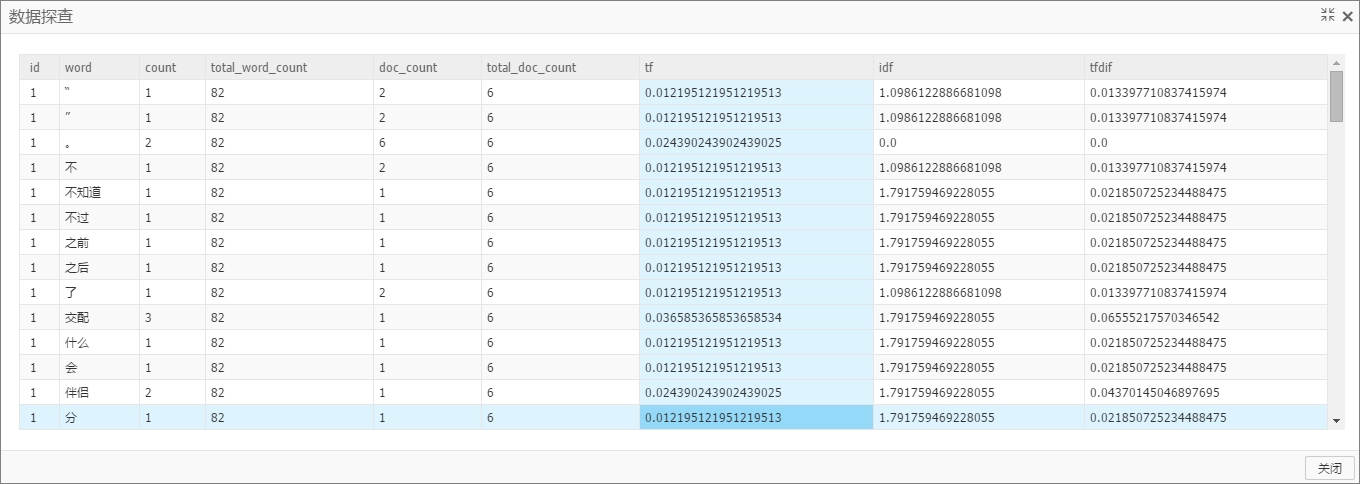
輸出表有9列:docid、word、word_count(當前word在當前doc中出現(xiàn)次數)、total_word_count(當前doc中總word數)、doc_count(當前word的總doc數)、total_doc_count(全部doc數)、tf、idf和tfidf。