PolarDB死鎖
本文主要介紹了利用DAS的鎖分析功能與SQL洞察功能進行死鎖定位的方法。
背景信息
死鎖是關(guān)系型數(shù)據(jù)庫系統(tǒng)中最為常見的錯誤,出現(xiàn)在不同事務(wù)中同時對某些數(shù)據(jù)訪問加鎖時,都要等待對方請求中的數(shù)據(jù)而無法獲取鎖。數(shù)據(jù)庫系統(tǒng)會自動犧牲回滾代價最小的事務(wù),從而導(dǎo)致對應(yīng)的寫請求失敗。更嚴重的情況是在大量死鎖發(fā)生時,會導(dǎo)致數(shù)據(jù)庫系統(tǒng)效率低下,大量進程堆積進而引發(fā)性能問題。正常情況下,死鎖都是由于邏輯加鎖的順序?qū)е碌模簿褪俏覀兂Uf的ABA死鎖。如下圖所示: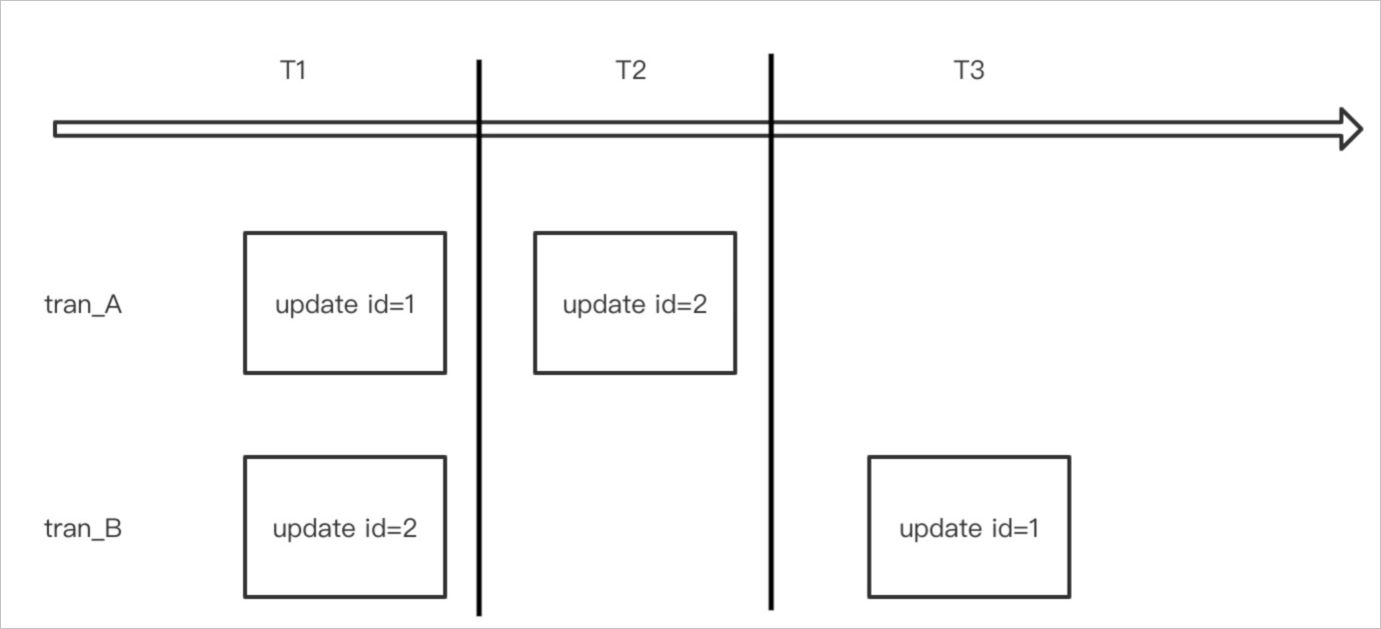 上圖中tran_A與tran_B兩個請求分別持有對方所需要的第二次update的行鎖,就形成了死鎖。如下圖所示:
上圖中tran_A與tran_B兩個請求分別持有對方所需要的第二次update的行鎖,就形成了死鎖。如下圖所示: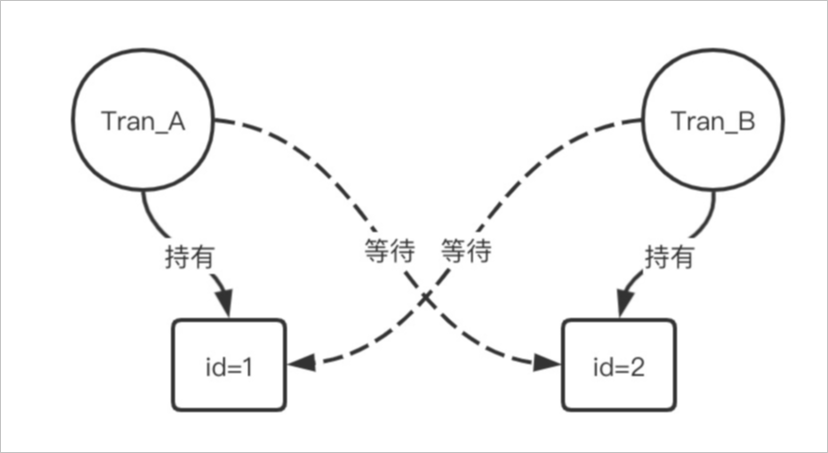 此時您的業(yè)務(wù)系統(tǒng)會收到如下報錯信息:
此時您的業(yè)務(wù)系統(tǒng)會收到如下報錯信息:
Error : Deadlock found when trying to get lock; try restarting transaction本文所說的死鎖是指deadlock,而非事務(wù)鎖造成的阻塞(block)。
死鎖定位
您可以登錄PolarDB控制臺,在菜單中選擇鎖分析,單擊創(chuàng)建分析。如果集群存在死鎖,會在發(fā)現(xiàn)死鎖列出現(xiàn)是。 目前診斷功能只能拉取最后一次死鎖,同樣是從innodb status中獲取的。如果集群不重啟,死鎖信息會一直保留最后一組日志,所以需要確認診斷后的日志是不是存量死鎖問題,也就是說發(fā)現(xiàn)的死鎖不一定是新出現(xiàn)的死鎖。
目前診斷功能只能拉取最后一次死鎖,同樣是從innodb status中獲取的。如果集群不重啟,死鎖信息會一直保留最后一組日志,所以需要確認診斷后的日志是不是存量死鎖問題,也就是說發(fā)現(xiàn)的死鎖不一定是新出現(xiàn)的死鎖。
發(fā)現(xiàn)死鎖后,單擊查看詳情,會顯示格式化后的死鎖信息。如下: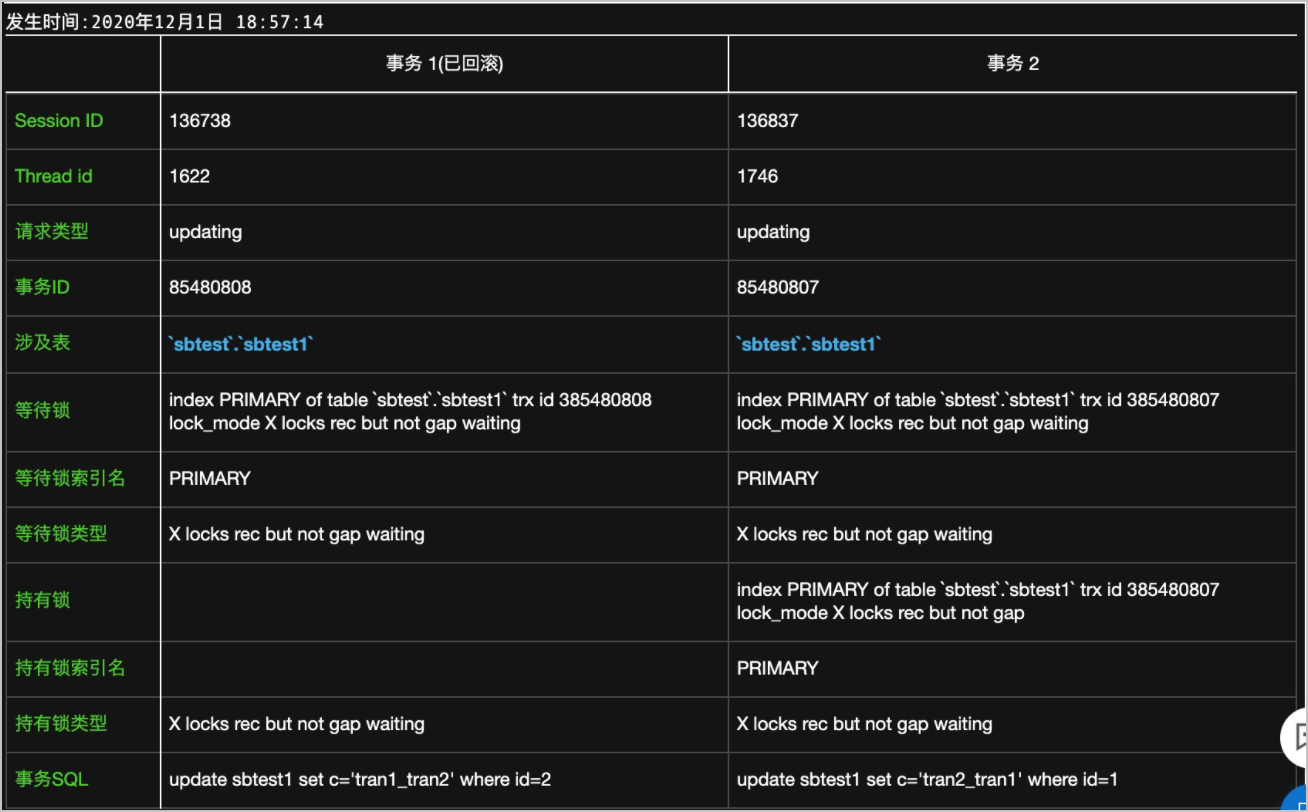
Thread id:線程ID,和SQL洞察中的線程ID對應(yīng)。
涉及表:死鎖出現(xiàn)的表。有時可能左右表不一致,是因為事務(wù)中請求的表不一致。
等待鎖索引名:DML語句會將鎖加在索引行上,所以獲取不到的鎖一定是在某個索引上。
事務(wù)SQL:引發(fā)死鎖的SQL語句。
事務(wù)流定位
事務(wù)流定位的前提條件是在死鎖發(fā)生前,PolarDB控制臺已經(jīng)開啟了SQL洞察功能,才能對執(zhí)行過的語句進行定位。
通過死鎖定位,可以獲取到回滾的事務(wù)、發(fā)生死鎖的語句、thread_id。同時也可以發(fā)現(xiàn)死鎖的犧牲事務(wù)thread_id為1622,成功事務(wù)thread id為1746。登錄PolarDB控制臺,在菜單中的搜索頁面先對犧牲事務(wù)進行查詢定位: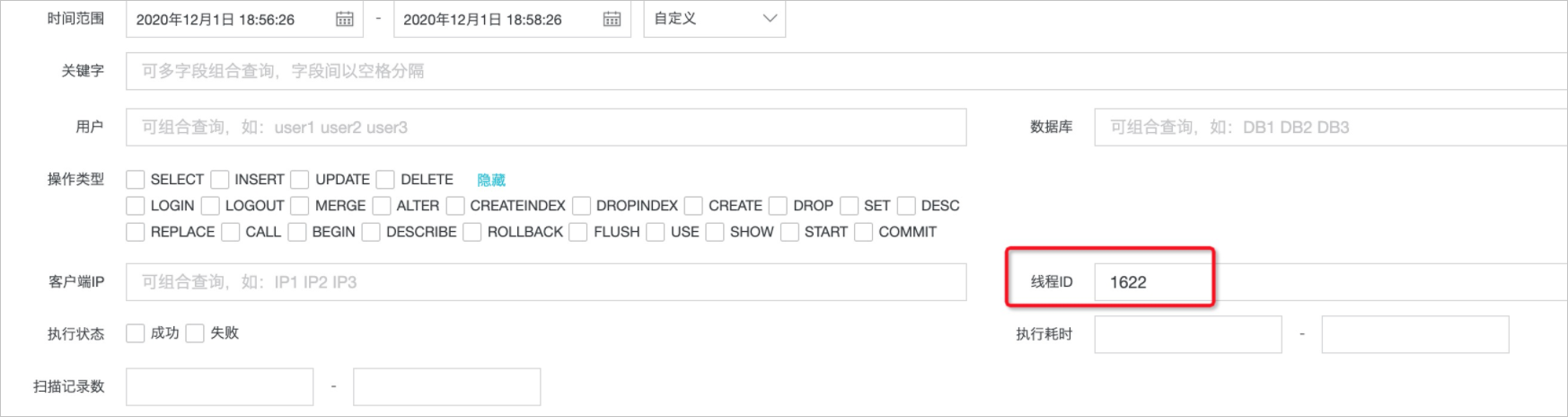 在日志列表中狀態(tài)列顯示為
在日志列表中狀態(tài)列顯示為失敗(1213),error 1213就是死鎖回滾的編碼,可以用來定位發(fā)生回滾的事務(wù)。 日志列表默認按照秒級排序,如果要獲取時序的事務(wù)流,需要通過執(zhí)行時間(毫秒)進行排序。
日志列表默認按照秒級排序,如果要獲取時序的事務(wù)流,需要通過執(zhí)行時間(毫秒)進行排序。
日志列表中的SQL語句太多,將無法通過執(zhí)行時間(毫秒)進行排序。需要繼續(xù)縮小搜索的時間范圍,減小返回的SQL數(shù)據(jù)。
然后再對執(zhí)行成功的事務(wù)thread id為1746進行查詢定位: 通過分析日志可獲取事務(wù)時間線:
通過分析日志可獲取事務(wù)時間線: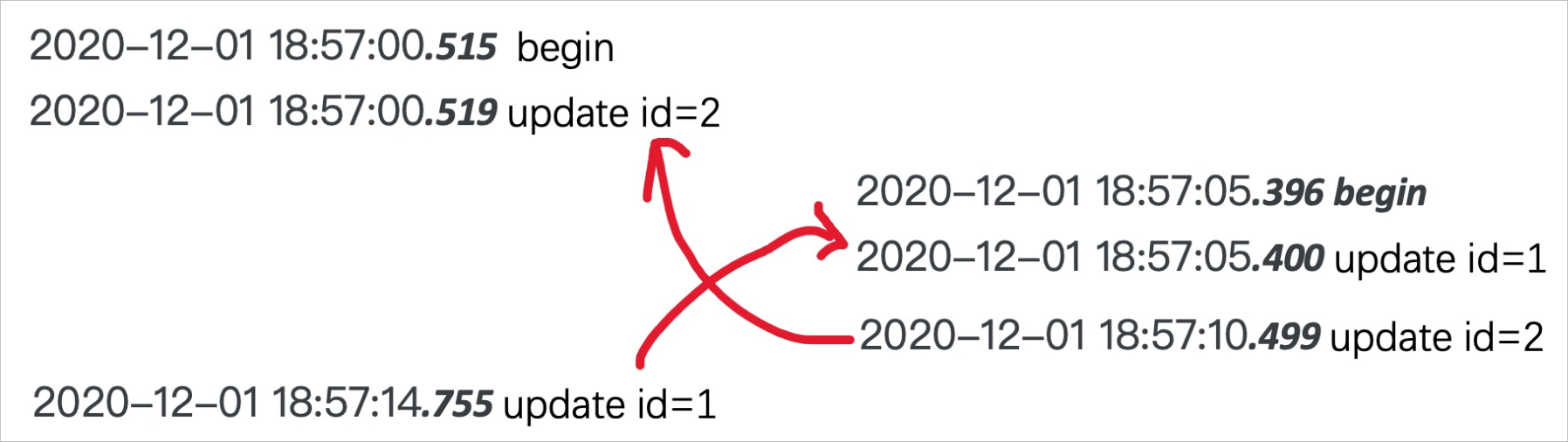
如果業(yè)務(wù)系統(tǒng)沒有開啟事務(wù),則可能是在框架中配置的。正常情況下開始語句都是set autocommit=0,有begin開始事務(wù)的場景比較少。
至此死鎖的事務(wù)流已經(jīng)分析出來了,可以交由產(chǎn)品研發(fā)人員進行定位了。