PolarDB MySQL版8.0版本重磅推出彈性并行查詢框架,當您的查詢數據量到達一定閾值,就會自動啟動并行查詢框架,從而使查詢耗時指數級下降。
功能簡介
彈性并行查詢(Elastic Parallel Query,ePQ)目前支持單機并行和多機并行兩種并行引擎,單機并行引擎等效于原有的并行查詢,多機并行引擎支持集群內跨節點的自適應彈性調度。
PolarDB MySQL版8.0.1版本支持單機并行查詢,查詢時在存儲層將數據分片到不同的線程上,單個節點內多個線程并行計算,將結果流水線匯總到總線程。最后總線程做簡單歸并返回給用戶,提高查詢效率。
PolarDB MySQL版8.0.2版本除了支持原有的單機并行查詢,又將線性加速能力提升了一個等級,引入了多節點分布式并行計算能力,即多機并行查詢。基于代價將執行計劃優化為更靈活的并行執行計劃,改進了單機并行查詢可能存在的Leader單點瓶頸和Worker負載不均衡的問題,同時突破了單個節點在CPU、Memory、IO上的資源瓶頸。基于多節點的資源視圖,自適應的調度并行計算任務,在大幅提升并行計算能力、降低查詢延遲的同時,平衡了各節點的資源負載,提升集群整體的資源利用率。
彈性并行查詢(Elastic Parallel Query)針對云上用戶實例CPU資源利用率較低、使用不均衡的特征,充分挖掘集群中多核CPU的并行處理能力,以8核32 GB(獨享規格)的PolarDB MySQL版集群版為例,示意圖如下所示:

前提條件
PolarDB MySQL版集群需滿足如下條件:
單機并行:
數據庫引擎版本為8.0.1,內核小版本需為8.0.1.0.5及以上。
產品版本:企業版/標準版。
單機并行:
數據庫引擎版本為8.0.2,內核小版本需為8.0.2.1.4.1及以上。
產品版本:企業版。
多機并行:
數據庫引擎版本為8.0.2,內核小版本需為8.0.2.2.6及以上。
產品版本:企業版。
如何查看集群版本,請參見查詢版本號。
應用場景
并行查詢適用于大部分SELECT語句,例如大表查詢、多表連接查詢、計算量較大的查詢。對于非常短的查詢,效果并不顯著。同時由于并行方式的多樣化,可以適用于多種廣泛而靈活的應用場景:
海量數據分析場景
在中等及更大規模數據量的情況下,分析類業務的報表查詢SQL通常復雜且比較耗費時間,通過開啟并行查詢可以線性降低查詢的響應時間。
資源負載不均衡場景
集群內的多個節點可以借助數據庫代理的負載均衡能力,使每個節點的并發連接數大致相同。但由于不同查詢的計算復雜度、資源使用方式各有差異,基于連接數的load balance無法完全避免節點間負載不均衡的問題。同所有分布式數據庫一樣,熱點節點也會對PolarDB造成一定的負面影響:
如果RO節點過熱使得查詢執行過慢,可能造成RW節點無法purge undo log導致磁盤空間膨脹。
如果RO節點過熱導致redo apply過慢,會導致RW節點無法刷臟降低RW節點的寫吞吐性能。
彈性并行查詢引入全局資源視圖機制,并基于該視圖做自適應調度,依據各節點的資源利用率和數據親和性反饋,將查詢的部分甚至全部子任務調度到有空閑資源的節點上,在保證目標并行度的基礎上均衡集群資源使用率。
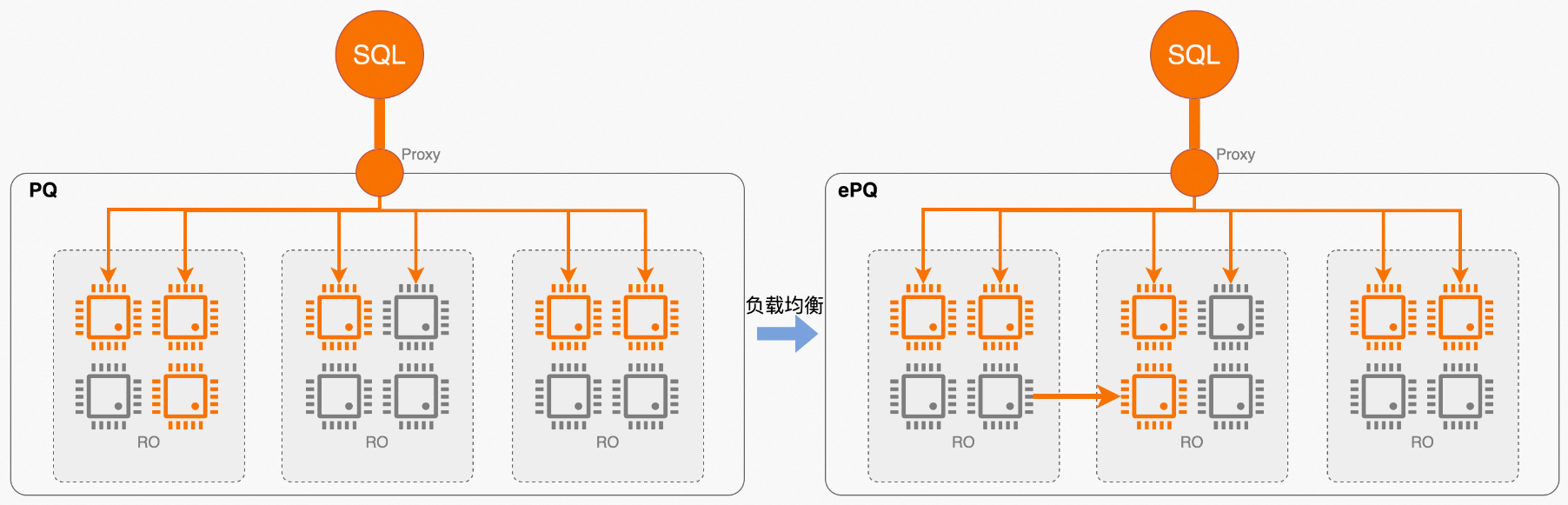
彈性計算場景
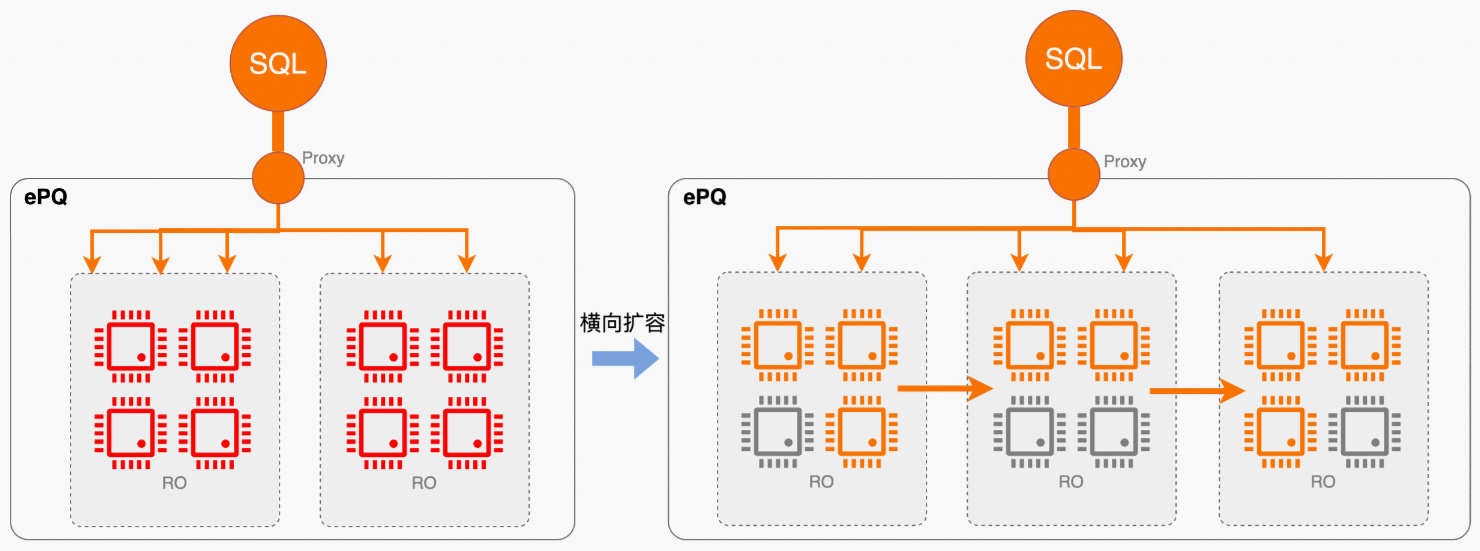
如前所述,彈性是云原生數據庫的PolarDB的核心能力之一,自動擴、縮容功能提供了對短查詢類業務非常友好的彈性能力,但之前并不適用于復雜分析類業務,因為對于大查詢場景,單條查詢仍無法通過增加節點實現提速。而現在開啟彈性并行查詢(ePQ)的集群,新擴展的節點會自動加入到集群分組中共享計算資源,彌補了之前彈性能力上的這一短板。
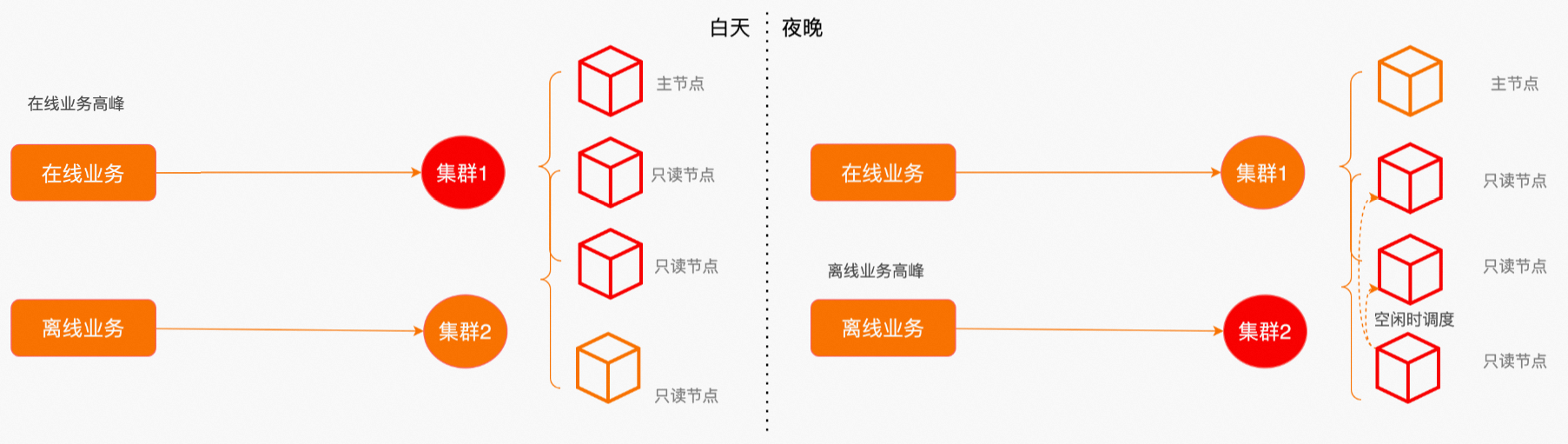
在離線業務混合場景
前面提到了多個子集群的物理資源隔離能力,最徹底的隔離方式是將在線交易業務和離線分析業務劃定為不同節點集合,但如果用戶在意成本,這種模式會顯得有些浪費。因為很多情況下,在、離線業務會有不同的高、低峰特性,更經濟的方式是通過錯峰使用,讓不同業務共享部分集群資源,但使用不同的集群地址承接業務。通過開啟彈性并行,讓離線業務重疊使用在線業務低峰期的空閑資源,進一步降本增效。
使用說明
關于如何使用彈性并行查詢,請參見使用說明。
性能指標
本次測試將使用TPC-H生成100 GB數據來測試PolarDB MySQL版8.0版本集群的性能指標。測試用的PolarDB集群規格為32核256 GB(獨享規格)×4節點,單節點并行度max_parallel_degree分別設置為32和0,對比PolarDB串行執行、單節點32并行度執行、4節點128并行度執行的性能數據,具體測試步驟請參見并行查詢性能。
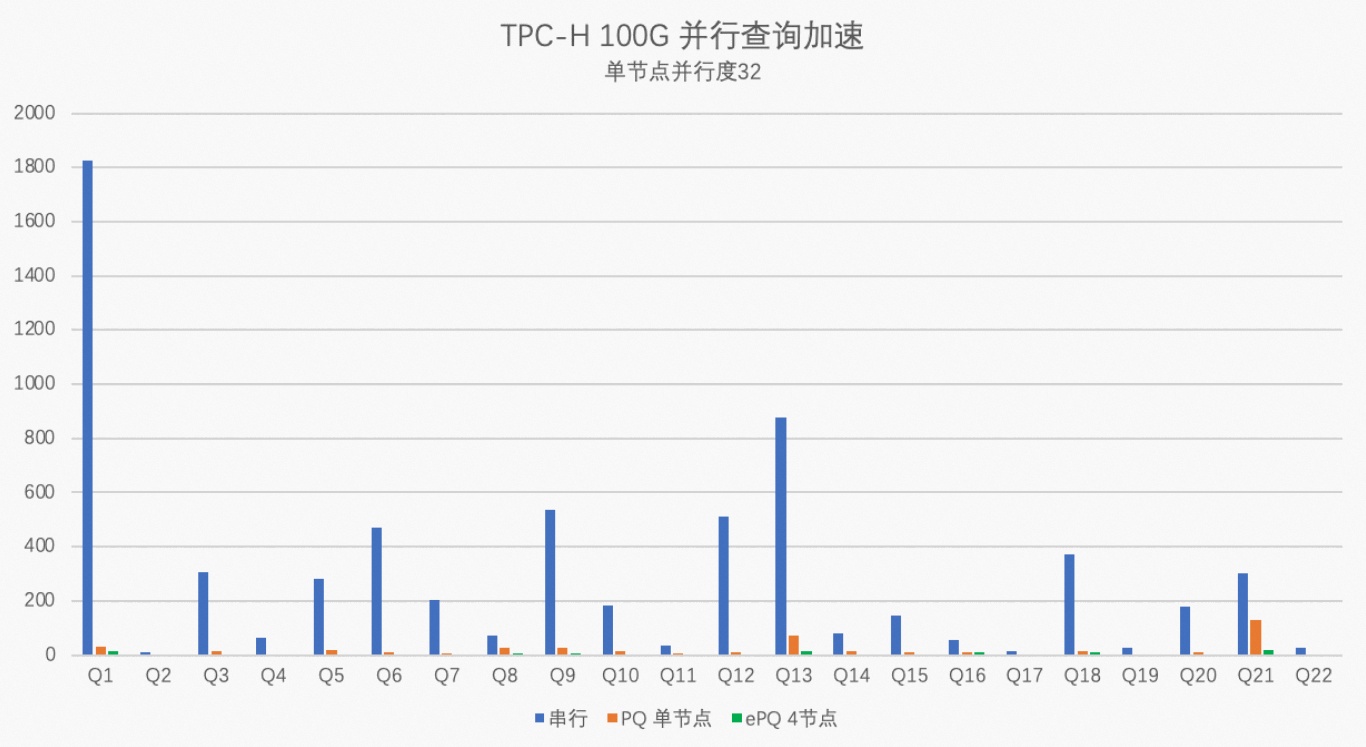
通過以上測試結果圖得出,TPC-H中100%的SQL可以被加速,平均加速比在17倍,最高加速比56倍。
開啟多機并行后,平均加速比在59倍,最高加速比159倍。
本文的TPC-H的實現基于TPC-H的基準測試,并不能與已發布的TPC-H基準測試結果相比較,本文中的測試并不符合TPC-H基準測試的所有要求。
并行執行EXPLAIN
更多關于EXPLAIN執行計劃輸出中與并行查詢相關的內容,請參見使用EXPLAIN查看并行計劃。
相關概念
并行掃描
在并行掃描中,每個Worker并行獨立掃描數據表中的數據。Worker掃描產生的中間結果集將會返回給Leader線程,Leader線程通過Gather操作收集產生的中間結果,并將所有結果匯總返回到客戶端。
多表并行連接
并行查詢會將多表連接操作完整的下推到Worker上去執行。PolarDB優化器只會選擇一個自認為最優的表進行并行掃描,而除了該表外,其他表都是一般掃描。每個Worker會將連接結果集返回給Leader線程,Leader線程通過Gather操作進行匯總,最后將結果返回給客戶端。
并行排序
PolarDB優化器會根據查詢情況,將ORDER BY下推到每個Worker里執行,每個Worker將排序后的結果返回給Leader,Leader通過Gather Merge Sort操作進行歸并排序,最后將排序結果返回到客戶端。
并行分組
PolarDB優化器會根據查詢情況,將GROUP BY下推到Worker上去并行執行。每個Worker負責部分數據的GROUP BY。Worker會將GROUP BY的中間結果返回給Leader,Leader通過Gather操作匯總所有數據。這里PolarDB優化器會根據查詢計劃情況來自動識別是否需要再次在Leader上進行GROUP BY。例如,如果GROUP BY使用了Loose Index Scan,Leader上將不會進行再次GROUP BY;否則Leader會再次進行GROUP BY操作,然后把最終結果返回到客戶端。
并行聚集
并行查詢執行聚集函數下推到Worker上并行執行。并行聚集將基于優化器代價,選擇串行執行、一階段聚集或者兩階段聚集。
一階段聚集:將聚集操作分發到Worker中,每個worker包含對應分組中的全部數據。因此無需第二階段的匯總聚集計算,各個Worker直接計算得到所擁有分組的最終聚集結果,避免Leader再次聚集。
兩階段聚集:在第一次,參與并行查詢部分的每個Worker執行聚集步驟;第二次,Gather或Gather Merge節點將每個Worker產生的結果匯總到Leader。最后,Leader會將所有Worker的結果再次進行聚集得到最終結果。
兩階段shuffle聚集:在第一次,參與并行查詢部分的每個Worker執行聚集步驟;第二次,Repartition節點將每個Worker產生的結果,按照分組列分發到多個worker,worker并行完成最終聚集計算。最后,聚集結果匯總到Leader。
采用哪種聚集執行方式由PolarDB優化器根據代價來決定。
并行窗口函數
PolarDB優化器會根據代價計算,將Window Function分發到Worker上并行執行,每個Worker負責部分數據的計算,分發方式根據Window Function中Partition by子句的key來決定。因此如果Window Function中沒有使用Partition by子句,只能串行完成計算。但如果后續計算仍可以并行,會根據代價,重新將后續計算任務分發到多個Worker上執行,保證最大程度的并行化。
子查詢支持
在并行查詢下子查詢有四種執行策略:
在Leader線程中串行執行
當子查詢不可并行執行時,例如2個表JOIN,在JOIN條件上引用了用戶的函數,此時子查詢會在Leader線程上進行串行查詢。
在Leader上并行執行(Leader會啟動另一組Worker)
生成并行計劃后,在Leader上執行的計劃包含有支持并行執行的子查詢,但這些子查詢不能提前并行執行(即不能采用Shared access)。例如,當前如果子查詢中包括window function,子查詢就不能采用Shared access策略。
Shared access
生成并行計劃后,Worker的執行計劃引用了可并行執行的子查詢,PolarDB優化器會選擇先提前并行執行這些子查詢,讓Worker可以直接訪問這些子查詢的結果。
Pushed down
生成并行計劃后,Worker執行計劃引用了相關子查詢,這些子查詢會被整體推送到Worker上執行。
免費體驗
阿里云提供了數據庫解決方案功能體驗館,提供了真實免費的PolarDB集群環境和開箱即用的測試方法,您可以在線快捷體驗ePQ帶來的查詢效率提升。
您可前往彈性并行查詢ePQ進行體驗,詳情請參見免費體驗彈性并行查詢ePQ。