本文介紹了由于日志文件過多導致存儲空間被占滿的問題描述、解決方案以及后續維護等內容。
問題描述
PolarDB MySQL版集群由于Binlog文件、Redo日志或者Undo日志過多,占用了太多存儲空間,且在空間分析中確認日志空間使用量較高。如下圖所示:
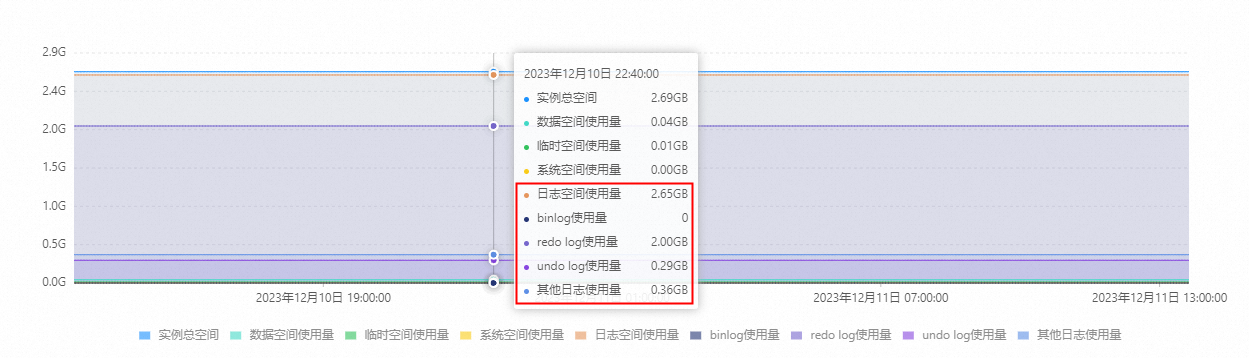
引發該問題的原因可能是由于大事務在快速生成Binlog文件、Redo文件或Undo文件時,占用了太多的集群存儲空間。
解決方案
清理Binlog文件、Undo文件或Redo文件時,界面更新有延遲,請耐心等待。
由于DML等操作(比如涉及大字段的DML操作)會快速生成Binlog文件、Undo文件或Redo文件,在這種情況下,建議您考慮升級擴展存儲空間,并且排查快速生成Binlog文件、Undo文件或Redo文件的原因。
若根據以下方案仍不能通過清理日志文件釋放足夠的存儲空間,您可以清理其他類型的數據文件來降低存儲空間使用率。詳情請參見由于數據文件過多導致集群存儲空間被占滿的解決辦法。
Binlog日志
保存策略
Binlog文件有如下兩種保存策略:
開啟Binlog后,文件默認保存3天,超過3天的Binlog文件會被自動刪除。
說明在2023年11月23日前購買的PolarDB MySQL版集群,其Binlog文件默認保存兩周(14天)。
在2024年1月17日前購買的PolarDB MySQL版集群,其Binlog文件默認保存一周(7天)。
關閉Binlog后,已有的Binlog文件會一直保留,不會自動刪除。
修改保存時長
修改Binlog保存時長不會造成連接閃斷,也不需要重啟集群。
但如果修改保存時長導致大量Binlog文件需要被清除(如10 TB),則在清除時可能會造成短時間的數據庫寫入異常。因此,在Binlog文件較大的情況下,建議在業務低峰期進行操作,并分多次縮短Binlog的保存時長,每次清除一部分Binlog數據。
若您的集群已開啟Binlog,您可以通過如下兩種方式修改Binlog文件保存時長:
若集群版本為PolarDB MySQL版5.6,您可以通過修改loose_expire_logs_hours(取值范圍為0~2376,單位為小時,默認值為72)的參數值來設置Binlog的保存時長。0表示不自動刪除Binlog文件。
若集群版本為PolarDB MySQL版5.7或8.0,您可以通過修改binlog_expire_logs_seconds(取值范圍為0~4294967295,單位為秒,默認值為259200)的參數值來設置Binlog的保存時長。0表示不自動刪除Binlog文件。
說明通過修改這兩個參數的參數值來設置Binlog的保存時長后,集群中歷史Binlog文件不會被立即自動清除。此時若您需要清除歷史Binlog文件,可以通過如下三種方法之一:
當集群中最后一個Binlog文件達到
max_binlog_size,切換到新的Binlog文件后,這些歷史Binlog文件將會被自動清除。使用高權限賬號執行flush binary logs命令可以立即觸發Binlog文件切換并清除過期的Binlog文件。
您也可重啟集群。集群重啟后將自動清除歷史Binlog文件。
若您的集群未開啟Binlog,此時如需刪除Binlog文件,您可以重新打開Binlog,將上述Binlog的保存時長參數(loose_expire_logs_hours或binlog_expire_logs_seconds)設置為一個較小的值,等文件超過保存時長自動刪除后再關閉Binlog。
Redo日志
Redo日志正常情況下會在備份完成后自動清理,無需手動干預。但由于存在Redo文件緩存池,通常Redo會占用2~11 GB左右的空間,最多時會占用11 GB,其中包括緩沖池中的8個Redo日志(8 GB)、正在寫的Redo日志(1 GB)、提前創建的Redo日志(1 GB)以及最后一個Redo日志(1 GB)。您可以通過參數loose_innodb_polar_log_file_max_reuse來調整保留的Redo文件緩存個數,從而減少日志空間占用量,但在壓力大的情況下,性能可能會出現周期性的小幅波動。
Undo日志
檢查是否有未提交的舊事務,PolarDB中的Undo log承擔MVCC的歷史版本作用,因此當有未提交事務持有舊的Read View時會阻塞Undo log的清理,造成空間積累。您可以使用以下命令查看是否存在大事務:
SELECT * FROM INFORMATION_SCHEMA.innodb_trx;PolarDB的只讀節點與讀寫節點共享存儲,只讀節點上的未提交的大事務同樣會影響Undo log的清理,在kill掉事務對應的線程后,Undo會停止繼續擴大。如果需要回收Undo文件,您可以通過如下步驟確定Undo history推進情況后,再進行Undo文件的空間清理。
當寫入壓力大時,確定是否將Undo清理滯后,PolarDB的策略會優先保證當前的寫入性能,可能會導致Undo log的清理滯后。您可以通過如下命令查看當前Undo history的長度:
SELECT COUNT FROM INFORMATION_SCHEMA.innodb_metrics WHERE name = 'trx_rseg_history_len';如果該值大于100萬,或者幾分鐘的時間內,該值還在不斷地上升,并且當前壓力確實比較大,可以通過如下步驟調整:
將參數
innodb_purge_batch_size的值調大,該操作不會重啟集群。將參數
innodb_purge_threads的值調大,建議跟集群規格中的核數一致,該操作會重啟集群,建議在業務低峰期操作,等待Undo history長度降低以后,Undo空間會停止增長,如果需要回收Undo空間,可以打開Undo truncate開關進行清理。
將
innodb_undo_log_truncate參數的值設置為ON,來打開Undo truncate開關。由于Undo truncate功能會在集群切換或重啟時帶來額外的開銷,建議在空間回收后立即關閉該功能,尤其是發起小版本升級等任務之前先關閉。需要的時候再打開。PolarDB維護8個Undo文件,當單個文件超過innodb_max_undo_log_size后,就會觸發Undo truncate。innodb_max_undo_log_size默認為8 GB,因此如果長時間超過8 GB,寫入壓力較小,并且集群版本比較老,可以嘗試做小版本升級來升級到最新版本。說明一些歷史版本存在Undo truncate相關缺陷,關閉了修改
innodb_undo_log_truncate的權限,導致在參數修改界面找不到該參數。此時需要通過小版本升級操作將當前版本升級到最新的版本。
后續維護
擴展存儲空間,PolarDB MySQL版采用存儲與計算分離的架構,您可以選擇手動擴容/縮容存儲空間或設置自動擴展標準版存儲空間兩種方式中的任意一種來擴展當前的存儲空間容量。