本文介紹了如何進行緩沖區(qū)管理。
背景信息
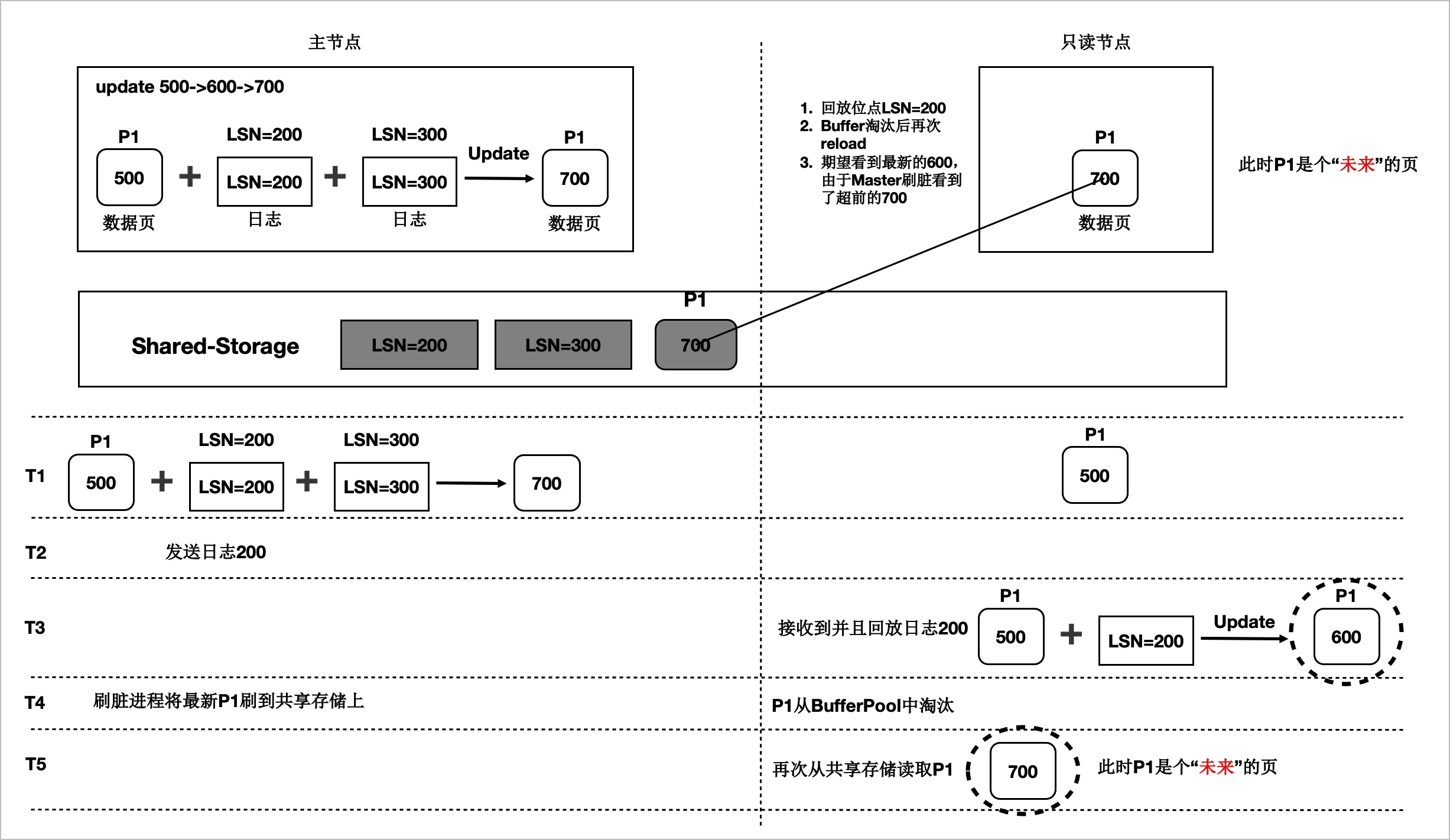
- 未來頁數(shù)據(jù)頁中包含只讀節(jié)點尚未回放到的數(shù)據(jù)。例如,只讀節(jié)點回放LSN為200的WAL日志,但數(shù)據(jù)頁中已經(jīng)包含LSN為300的WAL日志對應的改動。此類數(shù)據(jù)頁被稱為未來頁。
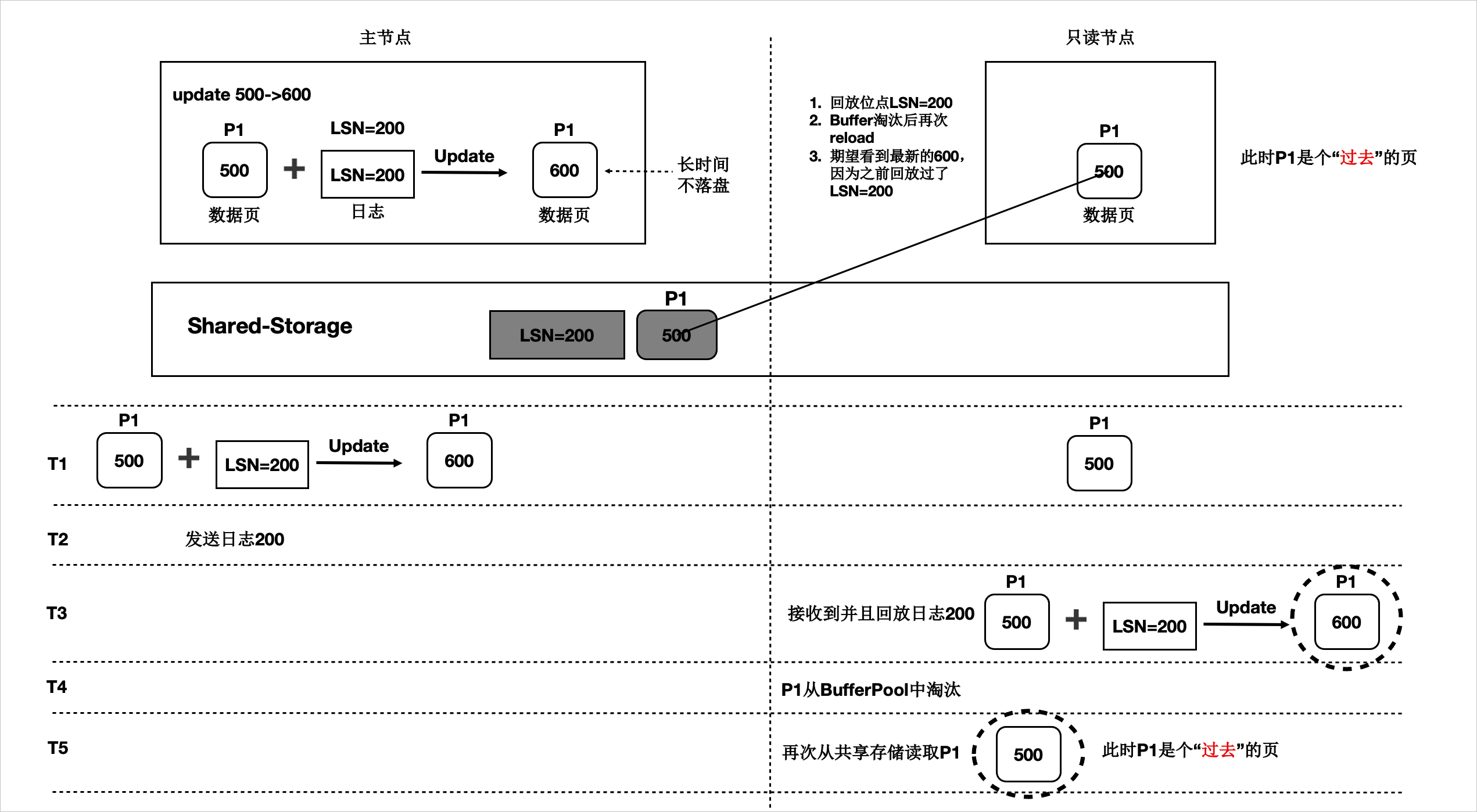
- 過去頁數(shù)據(jù)頁中未包含所有回放位點之前的改動。例如,只讀節(jié)點將數(shù)據(jù)頁回放到LSN為200的WAL日志,但該數(shù)據(jù)頁在從Buffer Pool淘汰之后,再次從共享存儲中讀取的數(shù)據(jù)頁中沒有包含LSN為200的WAL日志的改動,此類數(shù)據(jù)頁被稱為過去頁。
 對于只讀節(jié)點而言,只需要訪問與其回放位點相對應的數(shù)據(jù)頁。但如果讀取到如上所述的未來頁和過去頁時,可以按照以下步驟處理:
對于只讀節(jié)點而言,只需要訪問與其回放位點相對應的數(shù)據(jù)頁。但如果讀取到如上所述的未來頁和過去頁時,可以按照以下步驟處理:- 對于過去頁,只讀節(jié)點需要回放數(shù)據(jù)頁上截止回放位點之前缺失的WAL日志,對過去頁的回放由每個只讀節(jié)點根據(jù)自己的回放位點完成,屬于只讀節(jié)點回放功能,此處暫不贅述。
- 對于未來頁,只讀節(jié)點無法將未來的數(shù)據(jù)頁轉(zhuǎn)換為所需的數(shù)據(jù)頁,因此需要在主節(jié)點將數(shù)據(jù)寫入共享存儲時考慮所有只讀節(jié)點的回放情況,從而避免只讀節(jié)點讀取到未來頁,這也是Buffer管理需要解決的主要問題。
術(shù)語
| 名詞 | 說明 |
|---|---|
| Buffer Pool | 緩沖池,一種用來存儲最常訪問的數(shù)據(jù)的內(nèi)存結(jié)構(gòu),通常以頁為單位來緩存數(shù)據(jù)。PolarDB中每個節(jié)點都有自己的Buffer Pool。 |
| LSN | Log Sequence Number,日志序列號,是WAL日志的唯一標識。LSN在全局是遞增的。 |
| Apply LSN | 回放位點,表示只讀節(jié)點回放日志的位置,一般用LSN來標記。 |
| Oldest Apply LSN最老回放位點 | 最老回放位點,表示所有只讀節(jié)點中LSN最小的回放位點。 |
刷臟控制
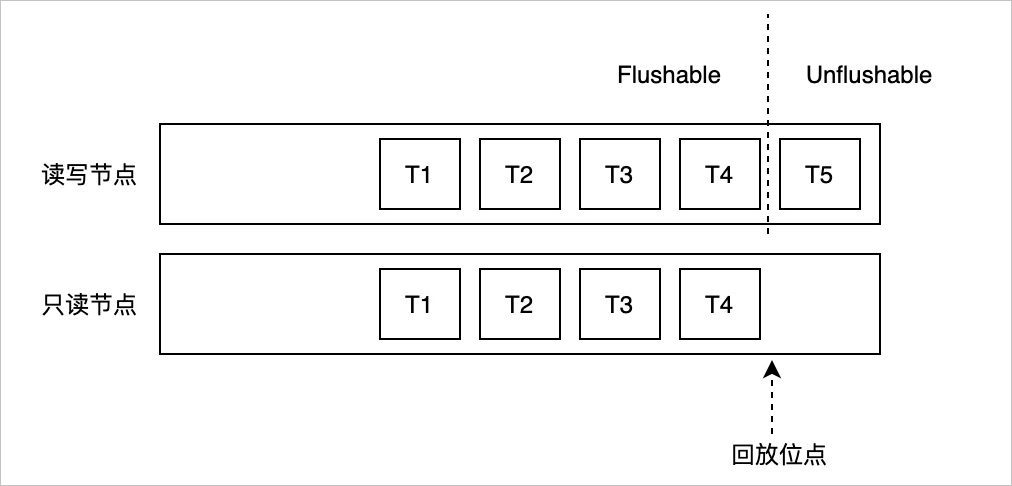
- Buffer最近一次修改對應的LSN,即Buffer Latest LSN。
- 最老回放位點,所有只讀節(jié)點中最小的回放位點,即Oldest Apply LSN。
if buffer latest lsn <= oldest apply lsn
flush buffer
else
do not flush buffer一致性位點
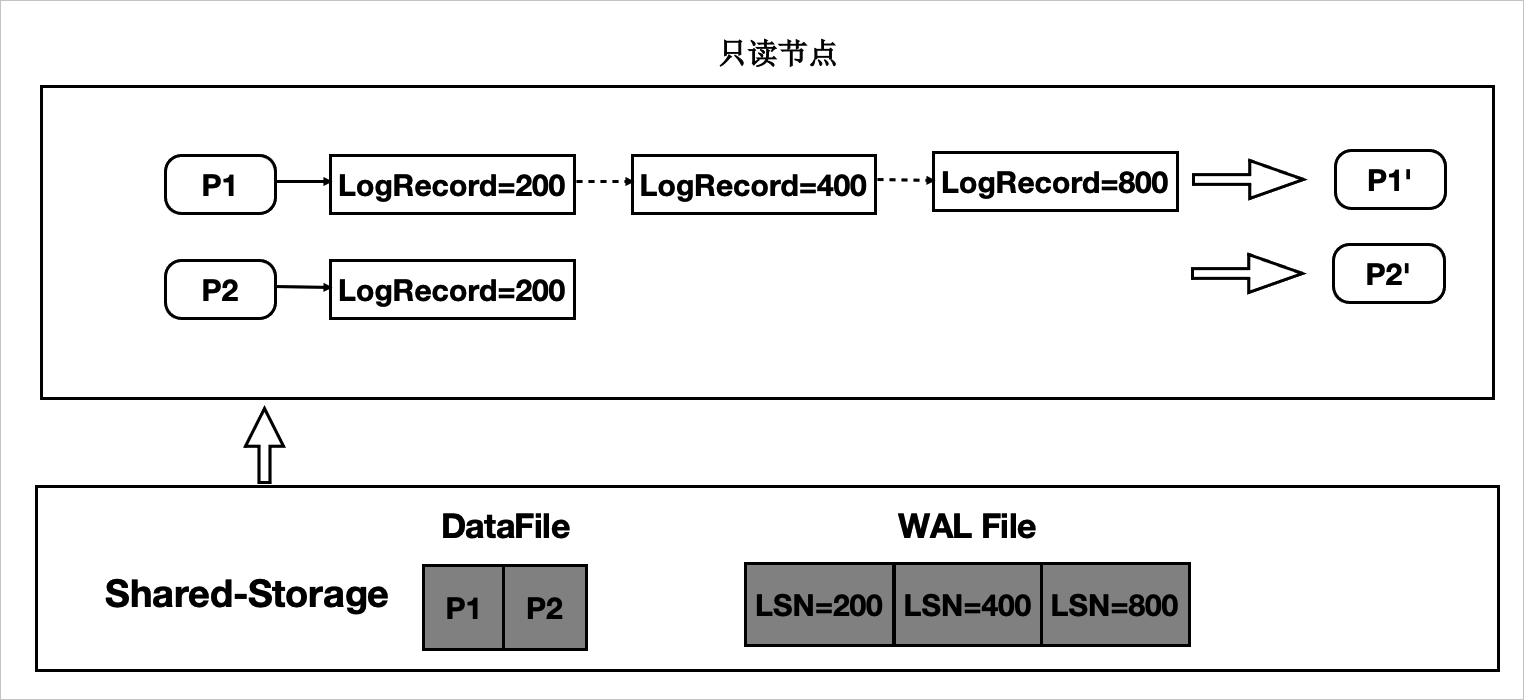 數(shù)據(jù)頁上的修改越多,其對應的LSN也越多,回放所需耗時也越長。為了盡量減少數(shù)據(jù)頁需要回放的LSN數(shù)量,PolarDB引入了一致性位點的概念。
數(shù)據(jù)頁上的修改越多,其對應的LSN也越多,回放所需耗時也越長。為了盡量減少數(shù)據(jù)頁需要回放的LSN數(shù)量,PolarDB引入了一致性位點的概念。
一致性位點表示該位點之前的所有WAL日志修改的數(shù)據(jù)頁均已經(jīng)持久化到存儲。主備節(jié)點之間,主節(jié)點向備節(jié)點發(fā)送當前WAL日志的寫入位點和一致性位點,備節(jié)點向主節(jié)點發(fā)送當前回放的位點。由于一致性位點之前的WAL修改都已經(jīng)寫入共享存儲,備節(jié)點無需再回放該位點之前的WAL日志。因此,可以將LogIndex中所有小于一致性位點的LSN清理掉,既加速回放效率,同時還能減少LogIndex占用的空間。
- FlushList
為了維護一致性位點,PolarDB為每個Buffer引入了一個內(nèi)存狀態(tài),即第一次修改該Buffer對應的LSN,稱之為Oldest LSN,所有Buffer中最小的Oldest LSN即為一致性位點。
一種獲取一致性位點的方法是遍歷Buffer Pool中所有Buffer,找到最小值,但遍歷代價較大,CPU開銷和耗時都很大。為高效獲取一致性位點,PolarDB引入FlushList機制,將Buffer Pool中所有臟頁按照Oldest LSN從小到大排序。借助FlushList,獲取一致性位點的時間復雜度可以達到 O(1)。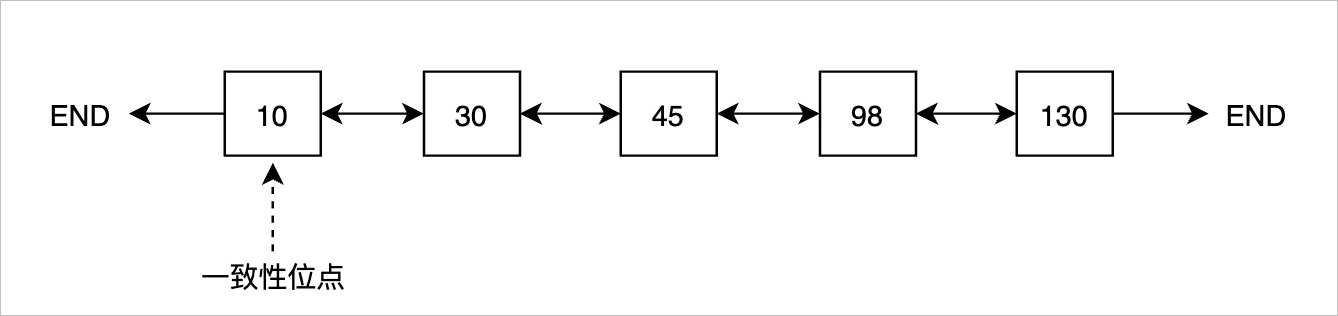
第一次修改Buffer并將其標記為臟頁時,將該Buffer插入到FlushList中,并設置其Oldest LSN。Buffer被寫入存儲時,將該內(nèi)存中的標記清除。
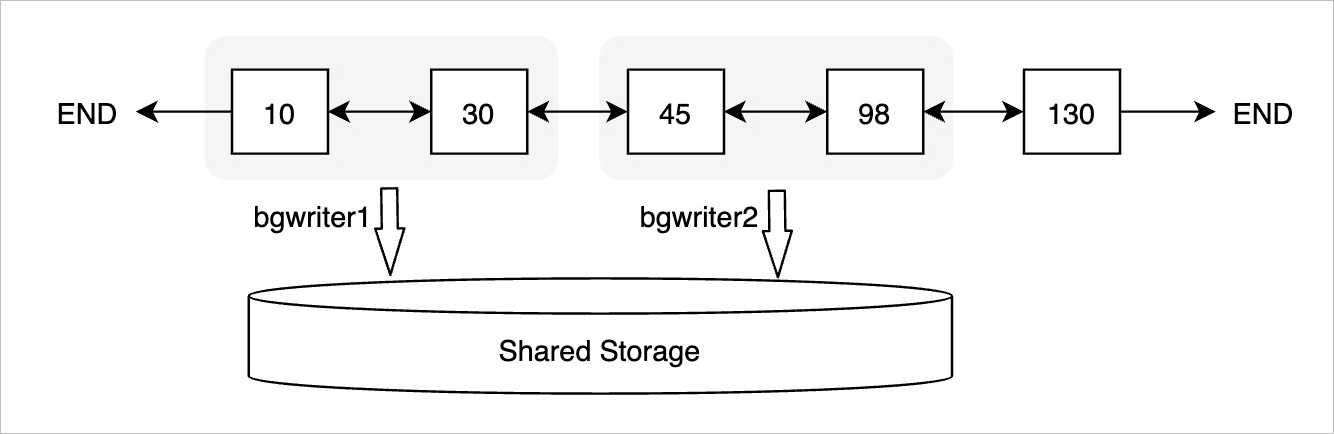
為高效推進一致性位點,PolarDB的后臺刷臟進程(bgwriter)采用先被修改的Buffer先落盤的刷臟策略,即bgwriter會從前往后遍歷FlushList,逐個刷臟,一旦有臟頁寫入存儲,一致性位點就可以向前推進。如上圖所示,如果Oldest LSN為10的Buffer落盤,一致性位點就可以推進到30。
- 并行刷臟為進一步提升一致性位點的推進效率,PolarDB實現(xiàn)了并行刷臟。每個后臺刷臟進程會從FlushList中獲取一批數(shù)據(jù)頁進行刷臟。
熱點頁
引入刷臟控制之后,僅滿足刷臟條件的Buffer才能寫入存儲。如果某個Buffer修改非常頻繁,可能導致Buffer Latest LSN總是大于Oldest Apply LSN,該Buffer始終無法滿足刷臟條件,此類Buffer稱之為熱點頁。熱點頁會導致一致性位點無法推進,為解決熱點頁的刷臟問題,PolarDB引入了Copy Buffer機制。
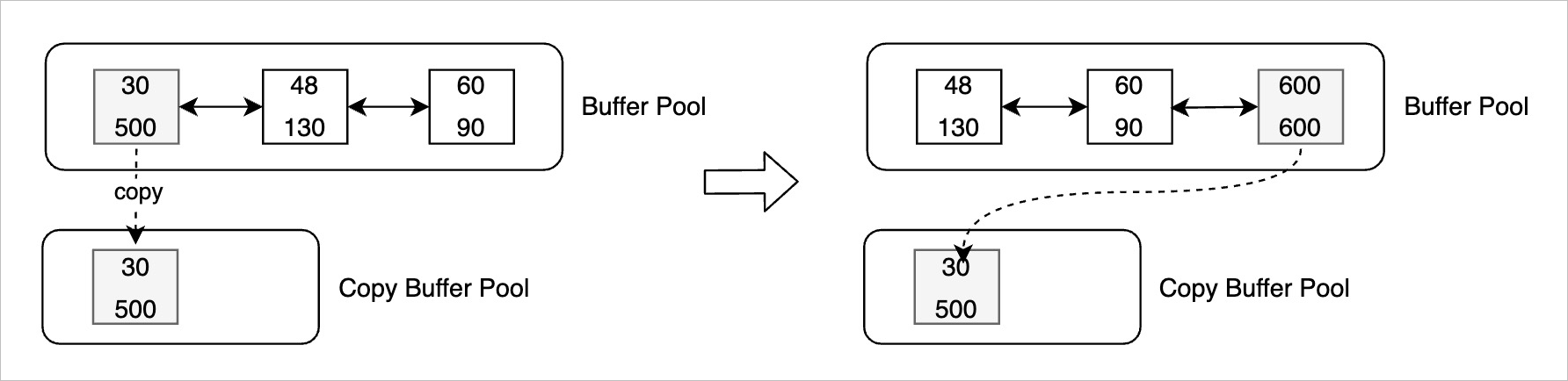
Copy Buffer機制會將特定的、不滿足刷臟條件的Buffer從Buffer Pool中拷貝至新增的Copy Buffer Pool中,Copy Buffer Pool中的Buffer不會再被修改,其對應的Latest LSN也不會更新,隨著Oldest Apply LSN的推進,Copy Buffer會逐步滿足刷臟條件,從而可以將Copy Buffer落盤。
- 如果Buffer不滿足刷臟條件,判斷其最近修改次數(shù)以及距離當前日志位點的距離,超過一定閾值,則將當前數(shù)據(jù)頁拷貝至Copy Buffer Pool中。
- 下次再刷該Buffer時,判斷其是否滿足刷臟條件。如果滿足,則將該Buffer寫入存儲并釋放其對應的Copy Buffer。
- 如果Buffer不滿足刷臟條件,則判斷其是否存在Copy Buffer。若存在且Copy Buffer滿足刷臟條件,則將Copy Buffer落盤。
- Buffer被拷貝到Copy Buffer Pool之后,如果對該Buffer進行修改,則會重新生成該Buffer的Oldest LSN,并將其追加到FlushList末尾。
Lazy Checkpoint
PolarDB引入的一致性位點概念,與checkpoint的概念類似。PolarDB中checkpoint位點表示該位點之前的所有數(shù)據(jù)都已經(jīng)落盤,數(shù)據(jù)庫Crash Recovery時可以從checkpoint位點開始恢復,提升恢復效率。普通的checkpoint會將所有Buffer Pool中的臟頁以及其他內(nèi)存數(shù)據(jù)落盤,這個過程可能耗時較長且在此期間I/O吞吐較大,可能會對正常的業(yè)務請求產(chǎn)生影響。
借助一致性位點,PolarDB引入了一種特殊的checkpoint:Lazy Checkpoint。之所以稱之為Lazy,是與普通的checkpoint相比,Lazy Checkpoint不會把Buffer Pool中所有的臟頁落盤,而是直接使用當前的一致性位點作為checkpoint位點,極大地提升了checkpoint的執(zhí)行效率。