本文介紹PolarDB PostgreSQL版(兼容Oracle)如何通過PASE插件(基于IVFFlat或HNSW算法)實現高維向量檢索。
背景信息
近年來,深度學習領域內的表示學習技術,作為人工智能的代表性技術,取得了長足性進展,在工業界中已經被大量應用,例如廣告投放、人臉支付、圖像識別、語音識別等場景。數據被嵌入至高維度向量,然后通過向量檢索技術來查找相關的項目。
PASE(PostgreSQL ANN search extension)是一款為PostgreSQL數據庫研發的高性能向量檢索索引插件,使用業界中成熟穩定且高效的ANN(Approximate nearest neighbor)檢索算法,包括IVFFlat和HNSW算法,通過這兩種算法,可以在PG數據庫中實現極高速向量查詢。PASE暫時不支持特征向量的抽取與產出,您需要自己檢索實體的特征向量,PASE負責的工作是根據已產出的海量級別的向量進行相似向量的檢索。
目標讀者
限于篇幅,本文不會對機器學習領域的相關名詞做詳細解釋,所以閱讀本文需要您有機器學習、搜索推薦相關知識基礎。
注意事項
- 索引會有膨脹,大約的膨脹率可以通過
select pg_relation_size('index名稱');查詢,當膨脹遠大于數據的大小,并且查詢有明顯變慢時,需要重建索引。 - 數據頻繁更新后索引會不精確,如果要求絕對準確,需要定期重建索引。
- IVFFlat索引如果使用內部中心點(clustering_type=1),需要先在表中插入一定數據,再創建索引。
- 請使用高權限賬號執行本文SQL示例。
使用限制
跨機并行查詢僅支持順序檢索高維向量。
PASE算法簡述
- IVFFlat算法 IVFFlat是IVFADC的簡化版本,適合于召回精度要求高,但對查詢耗時要求不嚴格(100ms級別)的場景。相比其他算法,IVFFlat算法具有以下優點:
- 如果查詢向量是候選數據集中的一員,那么IVFFlat可以達到100%的召回率。
- 算法簡單,因此索引構建更快,存儲空間更小。
- 聚類中心點可以由使用者指定,通過簡單的參數調節就可以控制召回精度。
- 算法參數可解釋性強,用戶能夠完全地控制算法的準確性。
IVFFlat的算法原理參見下圖。
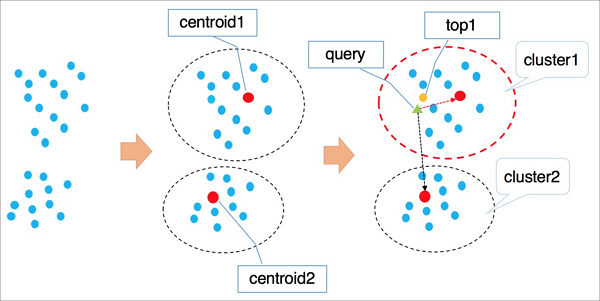
算法流程說明:
- 高維空間中的點基于隱形的聚類屬性,按照kmeans等聚類算法對向量進行聚類處理,使得每個類簇有一個中心點。
- 檢索向量時首先遍歷計算所有類簇的中心點,找到與目標向量最近的n個類簇中心。
- 遍歷計算n個類簇中心所在聚類中的所有元素,經過全局排序得到距離最近的k個向量。
說明- 在查詢類簇中心點時,會自動排除遠離的類簇,加速查詢過程,但是無法保證最優的前k個向量全部在這n個類簇中,因此會有精度損失。您可以通過類簇個數n來控制IVFFlat算法的準確性,n值越大,算法精度越高,但計算量會越大。
- IVFFlat和IVFADC的第一階段完全一樣,主要區別是第二階段計算。IVFADC通過積量化來避免遍歷計算,但是會導致精度損失,而IVFFlat是暴力計算,避免精度損失,并且計算量可控。
- HNSW算法
HNSW(Hierarchical Navigable Small World)算法適合超大規模的向量數據集(千萬級別以上),并且對查詢延時有嚴格要求(10ms級別)的場景。
HNSW基于近鄰圖的算法,通過在近鄰圖快速迭代查找得到可能的相近點。在大數據量的情況下,使用HNSW算法的性能提升相比其他算法更加明顯,但鄰居點的存儲會占用一部分存儲空間,同時召回精度達到一定水平后難以通過簡單的參數控制來提升。
HNSW的算法原理參見下圖。
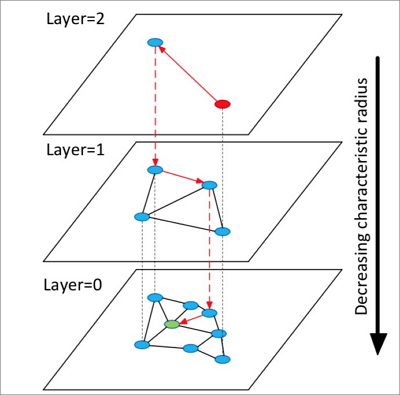
算法流程說明:
- 構造多層圖,每層圖都是下層圖的一個縮略,同時構成下層圖的跳表,類似高速公路。
- 從頂層隨機選中一個點開始查詢。
- 第一次搜索其鄰居點,把它們按距離目標的遠近順序存儲在定長的動態列表中,以后每一次查找,依次取出動態列表中的點,搜索其鄰居點,再把這些新探索的鄰居點插入動態列表,每次插入動態列表需要重新排序,保留前k個。如果列表有變化則繼續查找,不斷迭代直至達到穩態,然后以動態列表中的第一個點作為下一層的入口點,進入下一層。
- 循環執行第3步,直到進入最底層。
說明 HNSW算法是在NSW算法的單層構圖的基礎上構造多層圖,在圖中進行最近鄰查找,可以實現比聚類算法更高的查詢加速比。
兩種算法都有特定的適用業務場景,例如IVFFlat適合高精圖像對比場景,HNSW適合搜索推薦的召回場景。后續會陸續集成業界領先的算法實現到PASE中。
使用PASE
- 創建PASE插件。命令如下:
CREATE EXTENSION pase; - 計算向量相似度。您可以通過以下兩種構造方式計算向量相似度:
- 采用PASE數據類型構造方式計算
示例
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[]) AS distance; SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0) AS distance; SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0, 1) AS distance;說明- <?>是PASE類型的操作符,表示計算左右兩個向量的相似度。左邊向量數據類型必須為float4[],右邊向量數據類型必須為pase。
- pase類型為插件內定義的數據類型,最多包括三個構造函數。以示例第三條的
float4[], 0, 1部分進行說明:第一個參數為float4[],代表右向量數據類型;第二個參數在此處沒有特殊作用,可以填入0;第三個參數表示相似度計算方式,0表示歐氏距離,1表示點積(內積)。 - 左右向量的維度必須相等,否則計算會報錯。
- 采用字符串構造方式計算
示例
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1'::pase AS distance; SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1:0'::pase AS distance; SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1:0:1'::pase AS distance;說明 采用字符串構造方式和采用PASE數據類型構造方式都是計算兩個向量相似度,區別是字符串構造方式通過英文冒號(:)分隔。以示例第三條的3,1,1:0:1部分進行說明:第一個參數表示右向量;第二個參數在此處沒有特殊作用,可以填入0;第三個參數表示相似度計算方式,0表示歐氏距離,1表示點積(內積)。
- 采用PASE數據類型構造方式計算
- 創建索引。您可以使用兩種算法創建索引: 說明 對于要使用PASE向量索引的用戶,如果采用歐氏距離作為向量相似度計算公式,原始向量不需要做任何處理,但如果采用內積或余弦作為向量相似度計算公式,需要對向量進行歸一化處理,如原始向量為
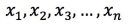 ,則需要滿足:
,則需要滿足: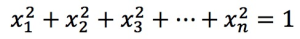 ,此時內積和余弦值相同。
,此時內積和余弦值相同。- IVFFlat算法創建索引
示例
CREATE INDEX ivfflat_idx ON vectors_table USING pase_ivfflat(vector) WITH (clustering_type = 1, distance_type = 0, dimension = 256, base64_encoded = 0, clustering_params = "10,100");參數說明如下。
參數 說明 clustering_type IVFFlat算法對向量數據進行的聚類操作類型。必填項。取值: - 0:外部聚類,加載外部提供的中心點文件,由參數clustering_params控制。
- 1:內部聚類,即構建索引過程首先會在內部進行聚類操作,采用kmeans算法,由參數clustering_params控制。
對于初級用戶,建議使用內部聚類方式。
distance_type 相似度計算方式。默認值為0。取值: - 0:歐式距離。
- 1:點積(內積)。使用此方式需要進行向量歸一化,此時點積(內積)值的序和歐氏距離的序是反序關系。
當前僅支持歐式距離,點積(內積)需要向量歸一化后,采用附錄中提供的方法計算。
dimension 向量維度。必填項,最大支持512。 base64_encoded 數據是否采用base64編碼。默認為0。取值: - 0:采用float4[]表示向量類型。
- 1:采用float[]的base64編碼字符串表示向量類型。
clustering_params 對于外部聚類,該參數配置為中心點文件路徑;對于內部聚類,該參數配置為聚類參數。格式為:
clustering_sample_ratio,k。必填項。- clustering_sample_ratio:以1000為分母的聚類采樣比例。取值范圍為(0,1000]內的整數,例如值為1,表示對表中的數據按照千分之一的比例采樣后進行kmeans聚類。值越大查詢準確率越高,但創建索引的時間越長,建議采樣的數據總量不要超過10萬條。
- k:聚類中心數,值越大查詢準確率越高,但創建索引時間越長,建議取值范圍為[100,1000]。
- HNSW算法創建索引
示例
CREATE INDEX hnsw_idx ON vectors_table USING pase_hnsw(vector) WITH (dim = 256, base_nb_num = 16, ef_build = 40, ef_search = 200, base64_encoded = 0);參數說明如下。
參數 說明 dim 向量維度。必填項,最大支持512。 base_nb_num 圖中節點的鄰居數。必填項。值越大查詢準確率越高,但建索引時間越慢,同時索引量占空間越大,建議取值范圍[16-128]。 ef_build 創建索引過程中的堆長度。必填項。越長效果越好,但創建索引越慢,建議取值范圍[40,400]。 ef_search 查詢過程中的堆長度。必填項。越長效果越好,但查詢性能越差,可在查詢時指定,該處為默認值:200。 base64_encoded 數據是否采用base64編碼。默認值0。取值: - 0:采用float4[]表示向量類型。
- 1:采用float[]的base64編碼字符串表示向量類型。
- IVFFlat算法創建索引
- 查詢。您可以使用兩種索引查詢:
- 使用IVFFlat索引查詢
示例
SELECT id, vector <#> '1,1,1'::pase as distance FROM vectors_ivfflat ORDER BY vector <#> '1,1,1:10:0'::pase ASC LIMIT 10;說明- <#>為IVFFlat算法索引的操作符。
- 向量索引通過ORDER BY語句生效,支持ASC升序排序。
- PASE數據類型為三段式,通過英文冒號(:)分隔。以示例的
1,1,1:10:0進行說明:第一段為查詢向量;第二段為IVFFlat的查詢效果參數,取值范圍為(0,1000],值越大查詢準確率越高,但查詢性能越差,建議根據實際數據進行調試確定;第三段為查詢時相似度計算方式,0表示歐式距離,1表示點積(內積)。使用點積(內積)方式需要進行向量歸一化,此時點積(內積)值的序和歐氏距離的序是反序關系。
- 使用HNSW索引查詢
示例
SELECT id, vector <?> '1,1,1'::pase as distance FROM vectors_ivfflat ORDER BY vector <?> '1,1,1:100:0'::pase ASC LIMIT 10;說明- <?>為HNSW算法索引的操作符。
- 向量索引通過ORDER BY語句生效,支持ASC升序排序。
- PASE數據類型為三段式,通過英文冒號(:)分隔。以示例的
1,1,1:10:0進行說明:第一段為查詢向量;第二段為HNSW的查詢效果參數,取值范圍為(0,∞),值越大查詢準確率越高,但查詢性能越差,建議根據實際數據進行調試確定,初始值建議從40開始;第三段為查詢時相似度計算方式,0表示歐式距離,1表示點積(內積)。使用點積(內積)方式需要進行向量歸一化,此時點積(內積)值的序和歐氏距離的序是反序關系。
- 使用IVFFlat索引查詢
附錄
- 點積(內積)方式計算示例
示例采用HNSW算法索引,創建FUNCTION示例如下:
CREATE OR REPLACE FUNCTION inner_product_search(query_vector text, ef integer, k integer, table_name text) RETURNS TABLE (id integer, uid text, distance float4) AS $$ BEGIN RETURN QUERY EXECUTE format(' select a.id, a.vector <?> pase(ARRAY[%s], %s, 1) AS distance from (SELECT id, vector FROM %s ORDER BY vector <?> pase(ARRAY[%s], %s, 0) ASC LIMIT %s) a ORDER BY distance DESC;', query_vector, ef, table_name, query_vector, ef, k); END $$ LANGUAGE plpgsql;說明 對于歸一化的向量,內積=余弦,所以余弦值也可以用上述方式計算。 - IVFFlat索引自定義中心點文件
此功能為高級功能,需要在服務器上指定路徑上傳中心點文件,并作為索引參數構建索引。詳細參數請參見IVFFlat索引參數描述。文件格式如下:
向量維度|中心點個數|中心點向量集合示例
3|2|1,1,1,2,2,2
相關文檔
- Product Quantization for Nearest Neighbor Search
Herve J ?egou, Matthijs Douze, Cordelia Schmid. Product quantization for nearest neighbor search.
- Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs
Yu.A.Malkov, D.A.Yashunin. Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs.