云原生數據庫PolarDB基于Cloud Native設計理念,既融合了商業數據庫穩定可靠、高性能、可擴展的特征,又具有開源云數據庫簡單開放、快速迭代的優勢。本文將介紹PolarDB的產品架構及特點。
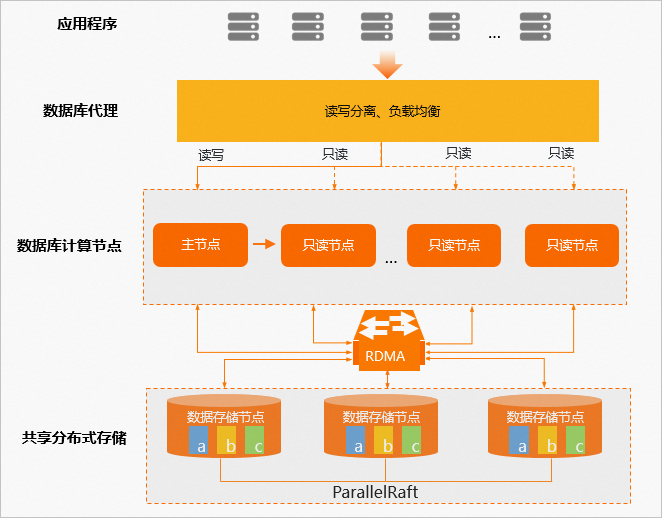
一寫多讀
PolarDB采用分布式集群架構,一個集群版集群包含一個主節點和最多15個只讀節點(至少一個,用于保障高可用)。主節點處理讀寫請求,只讀節點僅處理讀請求。主節點和只讀節點之間采用Active-Active的Failover方式,提供數據庫的高可用服務。
計算與存儲分離
PolarDB采用計算與存儲分離的設計理念,滿足公共云計算環境下根據業務發展彈性擴展集群的剛性需求。數據庫的計算節點(Database Engine Server)僅存儲元數據,而將數據文件、Redo Log等存儲于遠端的存儲節點(Database Storage Server)。各計算節點之間僅需同步Redo Log相關的元數據信息,極大降低了主節點和只讀節點間的復制延遲,而且在主節點故障時,只讀節點可以快速切換為主節點。
讀寫分離
讀寫分離是PolarDB集群版默認免費提供的一個透明、高可用、自適應的負載均衡能力。通過集群地址,SQL請求自動轉發到PolarDB集群版的各個節點,提供聚合、高吞吐的并發SQL處理能力。請參見讀寫分離。
高速鏈路互聯
數據庫的計算節點和存儲節點之間采用高速網絡互聯,并通過RDMA協議進行數據傳輸,使I/O性能不再成為瓶頸。
共享分布式存儲
多個計算節點共享一份數據,而不是每個計算節點都存儲一份數據,極大降低了用戶的存儲成本。基于全新打造的分布式塊存儲(Distributed Storage)和文件系統(Distributed Filesystem),存儲容量可以在線平滑擴展,不會受到單個數據庫服務器的存儲容量限制,可應對上百TB級別的數據規模。
數據多副本、Parallel-Raft協議
數據庫存儲節點的數據采用多副本形式,確保數據的可靠性,并通過Parallel-Raft協議保證數據的一致性。