PolarDB PostgreSQL版實現(xiàn)了彈性跨機并行查詢(ePQ)特性,能夠幫助您解決原先的PolarDB PostgreSQL版在處理復雜的AP查詢時會遇到的問題。
前提條件
支持的PolarDB PostgreSQL版的版本如下:
PostgreSQL 11(內核小版本1.1.28及以上)
您可通過如下語句查看PolarDB PostgreSQL版的內核小版本的版本號:
show polar_version;背景信息
很多PolarDB PostgreSQL版的用戶都有TP(Transactional Processing)和AP(Analytical Processing)共用的需求。他們期望數(shù)據庫在白天處理高并發(fā)的TP請求,在夜間TP流量下降、機器負載空閑時進行AP的報表分析。但是即使這樣,依然沒有最大化利用空閑機器的資源。原先的PolarDB PostgreSQL版在處理復雜的AP查詢時會遇到兩大挑戰(zhàn):
單條SQL在原生PostgreSQL執(zhí)行引擎下只能在單個節(jié)點上執(zhí)行,無論是單機串行還是單機并行,都無法利用其他節(jié)點的CPU、內存等計算資源,只能縱向Scale Up,不能橫向Scale Out。
PolarDB PostgreSQL版底層是存儲池,理論上I/O吞吐是無限大的。而單條SQL在原生PostgreSQL執(zhí)行引擎下只能在單個節(jié)點上執(zhí)行,受限于單節(jié)點CPU和內存的瓶頸,無法充分發(fā)揮存儲側大I/O帶寬的優(yōu)勢。
如圖所示: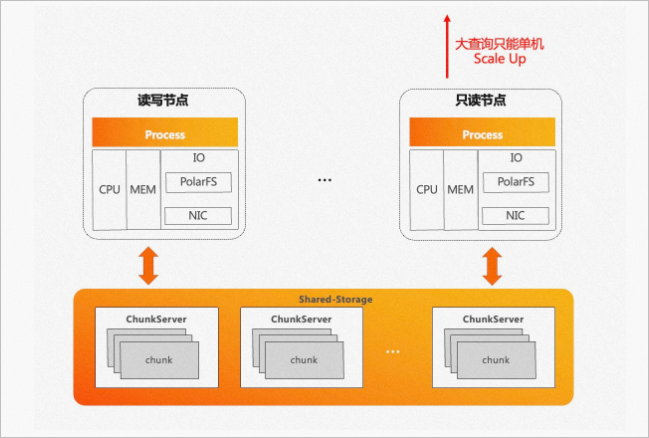
為了解決用戶實際使用中的痛點,PolarDB PostgreSQL版實現(xiàn)了ePQ特性。當前業(yè)界HTAP的解決方案主要有以下三種:
TP和AP在存儲和計算上完全分離。
優(yōu)勢:兩種業(yè)務負載互不影響。
劣勢:
時效性:TP的數(shù)據需要導入到AP系統(tǒng)中,存在一定的延遲。
成本/運維難度:增加了一套冗余的AP系統(tǒng)。
TP和AP在存儲和計算上完全共享。
優(yōu)勢:成本最小化、資源利用最大化。
劣勢:
計算共享會導致AP查詢和TP查詢同時運行時會存在相互影響。
擴展計算節(jié)點存儲時,數(shù)據需要重分布,無法快速彈性Scale Out。
TP和AP在存儲上共享,在計算上分離。
說明本身的存儲計算分離架構天然支持此方案。
HTAP特性原理
架構特性。
基于PolarDB PostgreSQL版的存儲計算分離架構,推出了分布式ePQ執(zhí)行引擎,提供了跨機并行執(zhí)行、彈性計算、彈性擴展的保證,使得PolarDB PostgreSQL版初步具備了HTAP的能力。其優(yōu)勢如下:
一體化存儲:毫秒級數(shù)據新鮮度。
TP/AP共享一套存儲數(shù)據,減少存儲成本,提高查詢時效。
TP/AP物理隔離:杜絕CPU/內存的相互影響。
單機執(zhí)行引擎:在RW/RO節(jié)點,處理高并發(fā)的TP查詢。
分布式ePQ執(zhí)行引擎:在RO節(jié)點,處理高復雜度的AP查詢。
Serverless彈性擴展:任何一個RO節(jié)點均可發(fā)起ePQ查詢。
Scale Out:彈性調整ePQ的執(zhí)行節(jié)點范圍。
Scale Up:彈性調整ePQ的單機并行度。
消除數(shù)據傾斜、計算傾斜,充分考慮PolarDB PostgreSQL版的Buffer Pool親和性。
如圖所示:
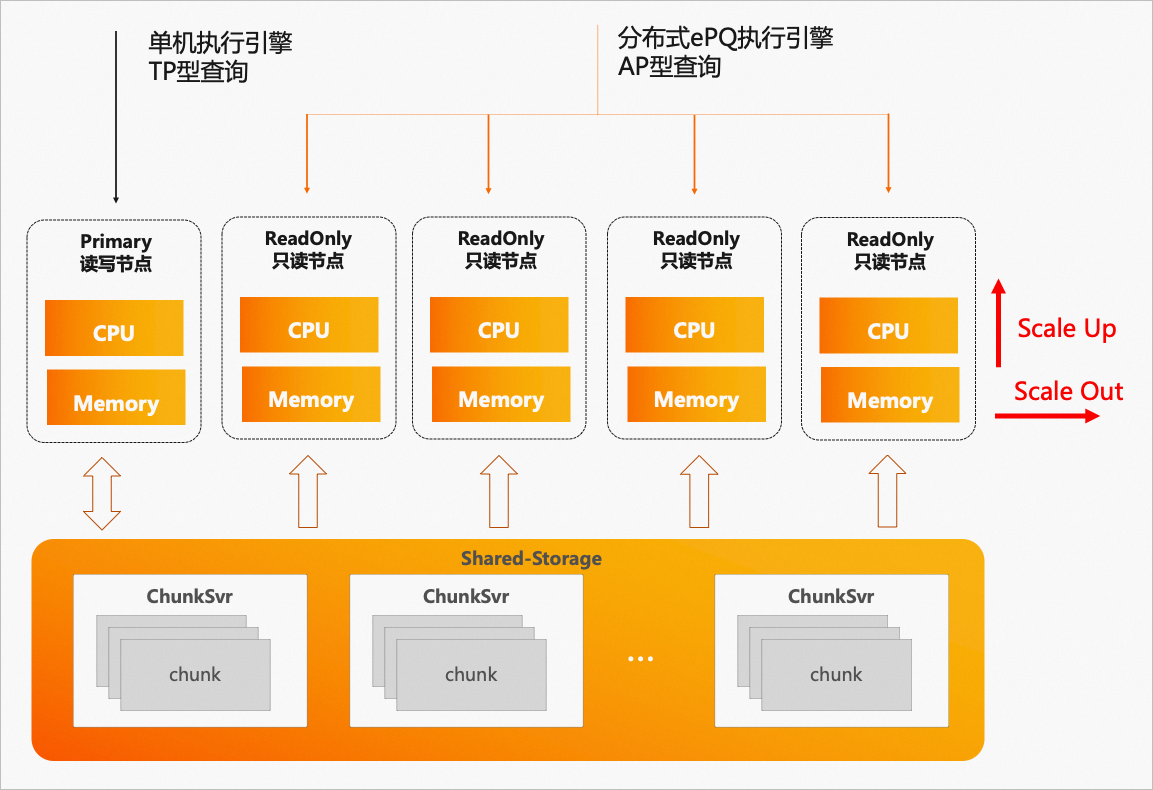
分布式ePQ執(zhí)行引擎。
PolarDB PostgreSQL版ePQ的核心是分布式ePQ執(zhí)行引擎,是典型的火山模型引擎。A、B兩張表先做join再做聚合輸出,這也是PostgreSQL單機執(zhí)行引擎的執(zhí)行流程。執(zhí)行流程如下所示:
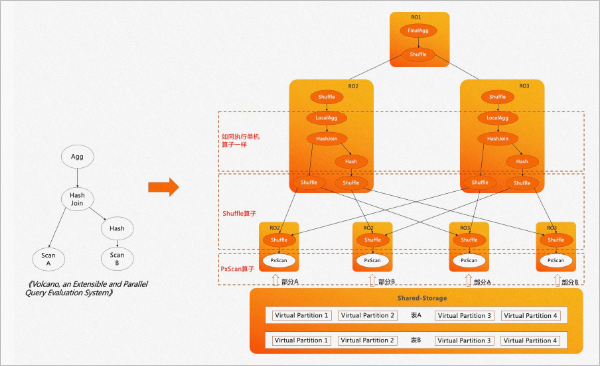
在傳統(tǒng)的mpp執(zhí)行引擎中,數(shù)據被打散到不同的節(jié)點上,不同節(jié)點上的數(shù)據可能具有不同的分布屬性,例如哈希分布、隨機分布、復制分布等。傳統(tǒng)的mpp執(zhí)行引擎會針對不同表的數(shù)據分布特點,在執(zhí)行計劃中插入算子來保證上層算子對數(shù)據的分布屬性無感知。
不同的是,PolarDB PostgreSQL版是共享存儲架構,存儲上的數(shù)據可以被所有計算節(jié)點全量訪問。如果使用傳統(tǒng)的mpp執(zhí)行引擎,每個計算節(jié)點Worker都會掃描全量數(shù)據,從而得到重復的數(shù)據。同時,也沒有起到掃描時分治加速的效果,并不能稱得上是真正意義上的mpp引擎。
因此,在分布式ePQ執(zhí)行引擎中,我們借鑒了火山模型論文中的思想,對所有掃描算子進行并發(fā)處理,引入了PxScan算子來屏蔽共享存儲。PxScan算子將shared-storage的數(shù)據映射為shared-nothing的數(shù)據,通過Worker之間的協(xié)調,將目標表劃分為多個虛擬分區(qū)數(shù)據塊,每個Worker掃描各自的虛擬分區(qū)數(shù)據塊,從而實現(xiàn)了跨機分布式并行掃描。
PxScan算子掃描出來的數(shù)據會通過Shuffle算子來重分布。重分布后的數(shù)據在每個Worker上如同單機執(zhí)行一樣,按照火山模型來執(zhí)行。
Serverless彈性擴展。
傳統(tǒng)mpp只能在指定節(jié)點發(fā)起mpp查詢,因此每個節(jié)點上都只能有單個Worker掃描一張表。為了支持云原生下Serverless彈性擴展的需求,我們引入了分布式事務一致性保障。如圖所示:
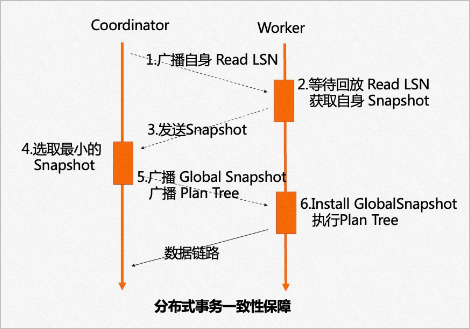
任意選擇一個節(jié)點作為Coordinator節(jié)點,它的ReadLSN會作為約定的LSN,從所有ePQ節(jié)點的快照版本號中選擇最小的版本號作為全局約定的快照版本號。通過LSN的回放等待和Global Snapshot同步機制,確保在任何一個節(jié)點發(fā)起ePQ查詢時,數(shù)據和快照均能達到一致可用的狀態(tài)。如圖所示:
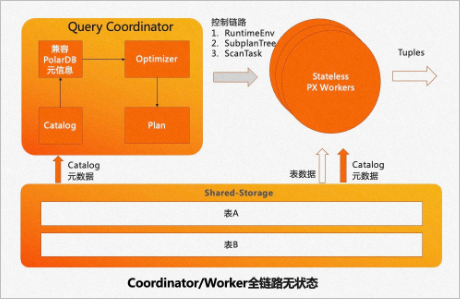
為了實現(xiàn)Serverless的彈性擴展,PolarDB PostgreSQL版從共享存儲的特點出發(fā),將Coordinator節(jié)點全鏈路上各個模塊需要的外部依賴全部放至共享存儲上。各個Worker節(jié)點運行時需要的參數(shù)也會通過控制鏈路從Coordinator節(jié)點同步過來,從而使Coordinator節(jié)點和Worker節(jié)點全鏈路無狀態(tài)化(Stateless)。
基于以上兩點設計,PolarDB PostgreSQL版的彈性擴展具備了以下幾大優(yōu)勢:
任何節(jié)點都可以成為Coordinator節(jié)點,解決了傳統(tǒng)mpp數(shù)據庫Coordinator節(jié)點的單點問題。
PolarDB PostgreSQL版可以橫向Scale Out(計算節(jié)點數(shù)量),也可以縱向Scale Up(單節(jié)點并行度),且彈性擴展即時生效,不需要重新分布數(shù)據。
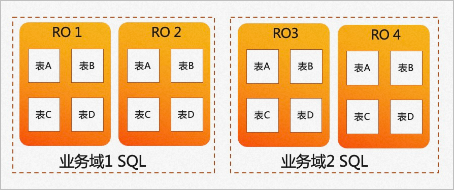
允許業(yè)務有更多的彈性調度策略,不同的業(yè)務域可以運行在不同的節(jié)點集合上。業(yè)務域1的SQL可以選擇RO1和RO2節(jié)點來執(zhí)行AP查詢,業(yè)務域2的SQL可以選擇使用RO3和RO4節(jié)點來執(zhí)行AP查詢,兩個業(yè)務域使用的計算節(jié)點可以實現(xiàn)彈性調度。
消除傾斜。
傾斜是傳統(tǒng)mpp固有的問題,其根本原因主要是數(shù)據分布傾斜和數(shù)據計算傾斜。
數(shù)據分布傾斜通常由數(shù)據打散不均衡導致,在PostgreSQL中還會由于大對象Toast表存儲引入一些不可避免的數(shù)據分布不均衡問題。
計算傾斜通常由于不同節(jié)點上并發(fā)的事務、Buffer Pool、網絡、I/O抖動導致。
傾斜會導致傳統(tǒng)mpp在執(zhí)行時出現(xiàn)木桶效應,執(zhí)行完成時間受制于執(zhí)行最慢的子任務。
PolarDB PostgreSQL版設計并實現(xiàn)了自適應掃描機制。如下圖所示,采用Coordinator節(jié)點來協(xié)調Worker節(jié)點的工作模式。在掃描數(shù)據時,Coordinator節(jié)點會在內存中創(chuàng)建一個任務管理器,根據掃描任務對Worker節(jié)點進行調度。Coordinator節(jié)點內部分為兩個線程。
Data線程主要負責服務數(shù)據鏈路、收集匯總元組。
Control線程負責服務控制鏈路、控制每一個掃描算子的掃描進度。
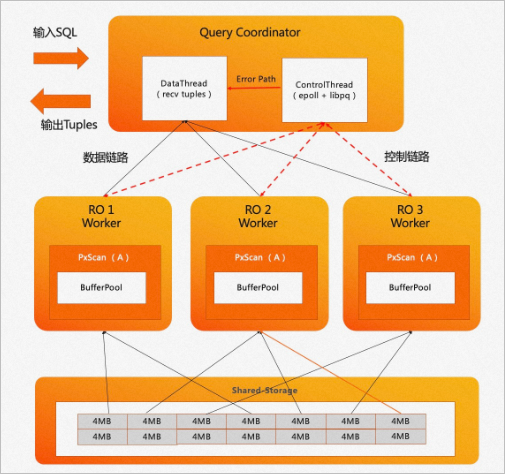
掃描進度較快的Worker能夠掃描多個數(shù)據塊。如上圖中RO1與RO3的Worker各自掃描了4個數(shù)據塊, RO2由于計算傾斜可以掃描更多數(shù)據塊,因此它最終掃描了6個數(shù)據塊。
PolarDB PostgreSQL版ePQ的自適應掃描機制還充分考慮了PostgreSQL的Buffer Pool親和性,保證每個Worker盡可能掃描固定的數(shù)據塊,從而最大化命中Buffer Pool的概率,降低I/O開銷。
TPC-H性能對比
單機并行與分布式ePQ對比。
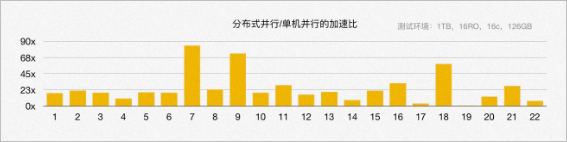
使用256 GB內存的16個PolarDB PostgreSQL版集群作為RO節(jié)點,搭建1 TB的TPC-H環(huán)境進行對比測試。相較于單機并行,分布式ePQ并行充分利用了所有RO節(jié)點的計算資源和底層共享存儲的I/O帶寬,從根本上解決了前文提及的HTAP諸多挑戰(zhàn)。在TPC-H的22條SQL中,有3條SQL加速了60多倍,19條SQL加速了10多倍,平均加速23倍。如圖所示:
測試彈性擴展計算資源帶來的性能變化。通過增加CPU的總核心數(shù),從16核增加到128核,TPC-H的總運行時間線性提升,每條SQL的執(zhí)行速度也呈線性提升,這也驗證了PolarDB PostgreSQL版ePQ Serverless彈性擴展的特點。如圖所示:
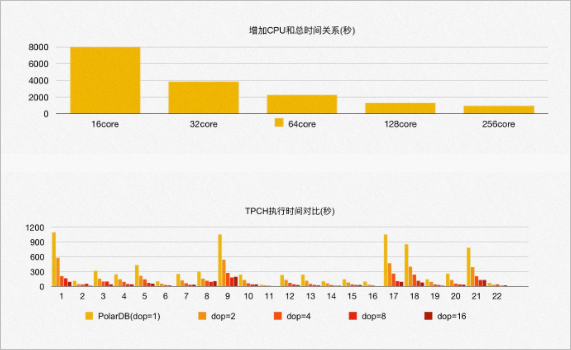
在測試中發(fā)現(xiàn),當CPU的總核數(shù)增加到256核時,性能提升不再明顯。原因是此時PolarDB PostgreSQL版共享存儲的I/O帶寬已經達到100%,成為了瓶頸。
PolarDB與傳統(tǒng)mpp數(shù)據庫對比。
同樣使用256 GB內存的16個節(jié)點,將PolarDB PostgreSQL版的分布式ePQ執(zhí)行引擎與傳統(tǒng)數(shù)據庫的mpp執(zhí)行引擎進行對比。
在1 TB的TPC-H數(shù)據上,當保持與傳統(tǒng)mpp數(shù)據庫相同單機并行度的情況下(多機單進程),PolarDB PostgreSQL版的性能是傳統(tǒng)mpp數(shù)據庫的90%。其中最本質的原因是傳統(tǒng)mpp數(shù)據庫的數(shù)據默認是哈希分布的,當兩張表的join key是各自的分布鍵時,可以不用shuffle直接進行本地的Wise Join。而PolarDB PostgreSQL版的底層是共享存儲池,PxScan算子并行掃描出來的數(shù)據等價于隨機分布,必須進行shuffle重分布以后才能像傳統(tǒng)mpp數(shù)據庫一樣進行后續(xù)的處理。因此,TPC-H涉及到表連接時,PolarDB PostgreSQL版相比傳統(tǒng)mpp數(shù)據庫多了一次網絡shuffle的開銷。如圖所示:
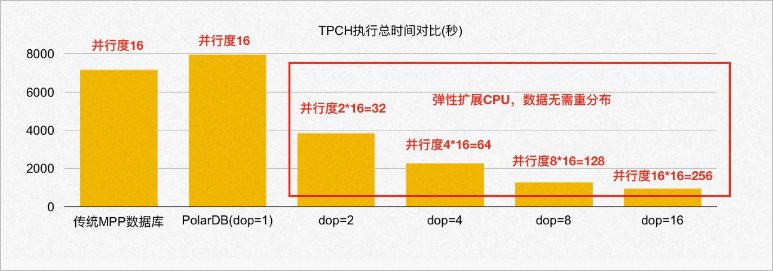

PolarDB PostgreSQL版分布式ePQ執(zhí)行引擎能夠進行彈性擴展,數(shù)據無需重分布。因此,在有限的16臺機器上執(zhí)行ePQ時,PolarDB PostgreSQL版還可以繼續(xù)擴展單機并行度,充分利用每臺機器的資源。當PolarDB PostgreSQL版的單機并行度為8時,它的性能是傳統(tǒng)mpp數(shù)據庫的5-6倍;當PolarDB PostgreSQL版的單機并行度呈線性增加時,PolarDB PostgreSQL版的總體性能也呈線性增加。只需要修改配置參數(shù),就可以即時生效。
功能特性
Parallel Query并行查詢。
經過持續(xù)迭代的研發(fā),目前PolarDB PostgreSQL版ePQ在Parallel Query上支持的功能特性主要有五大部分:
基礎算子全支持:掃描/連接/聚合/子查詢等算子。
共享存儲算子優(yōu)化:包括Shuffle算子共享、SharedSeqScan共享、SharedIndexScan算子等。其中SharedSeqScan共享、SharedIndexScan共享是指,在大表join小表時,小表采用類似于復制表的機制來減少廣播開銷,進而提升性能。
分區(qū)表支持:不僅包括對Hash/Range/List三種分區(qū)方式的完整支持,還包括對多級分區(qū)靜態(tài)裁剪、分區(qū)動態(tài)裁剪的支持。除此之外,PolarDB PostgreSQL版分布式ePQ執(zhí)行引擎還支持分區(qū)表的Partition Wise Join。
并行度彈性控制:包括全局級別、表級別、會話級別、查詢級別的并行度控制。
Serverless彈性擴展:不僅包括任意節(jié)點發(fā)起ePQ、ePQ節(jié)點范圍內的任意組合,還包括集群拓撲信息的自動維護以及支持共享存儲模式、主備庫模式和三節(jié)點模式。
Parallel DML。
基于PolarDB PostgreSQL版讀寫分離架構和ePQ Serverless彈性擴展的設計, PolarDB PostgreSQL版Parallel DML支持一寫多讀、多寫多讀兩種特性。
一寫多讀:在RO節(jié)點上有多個讀Worker,在RW節(jié)點上只有一個寫Worker。
多寫多讀:在RO節(jié)點上有多個讀Worker,在RW節(jié)點上也有多個寫Worker。多寫多讀場景下,讀寫的并發(fā)度完全解耦。
不同的特性適用不同的場景,用戶可以根據自己的業(yè)務特點來選擇不同的Parallel DML功能特性。
索引構建加速。
PolarDB PostgreSQL版分布式ePQ執(zhí)行引擎,不僅可以用于只讀查詢和DML,還可以用于索引構建加速。OLTP業(yè)務中有大量的索引,而B-Tree索引創(chuàng)建的過程大約有80%的時間消耗在排序和構建索引頁上,20%消耗在寫入索引頁上。如下圖所示:
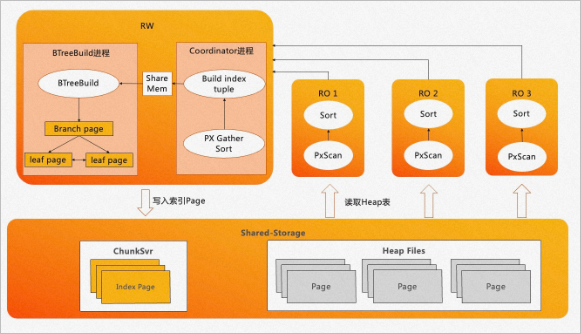 PolarDB PostgreSQL版利用RO節(jié)點對數(shù)據進行分布式ePQ加速排序,采用流水化的技術來構建索引頁,同時使用批量寫入技術來提升索引頁的寫入速度。說明
PolarDB PostgreSQL版利用RO節(jié)點對數(shù)據進行分布式ePQ加速排序,采用流水化的技術來構建索引頁,同時使用批量寫入技術來提升索引頁的寫入速度。說明在目前索引構建加速這一特性中,PolarDB PostgreSQL版已經支持了B-Tree索引的普通創(chuàng)建以及B-Tree索引的在線創(chuàng)建(Concurrently)兩種功能。
使用指南
PolarDB PostgreSQL版ePQ適用于日常業(yè)務中的輕分析類業(yè)務,例如:對賬業(yè)務,報表業(yè)務。
使用ePQ進行分析型查詢。
PolarDB PostgreSQL版默認不開啟ePQ功能。若您需要使用此功能,請使用如下參數(shù):
參數(shù)
說明
polar_enable_px
指定是否開啟ePQ功能。
on:開啟ePQ功能。
off:(默認值)不開啟ePQ功能。
polar_px_max_workers_number
設置單個節(jié)點上的最大ePQ Worker進程數(shù),默認為30,取值范圍為0~2147483647。該參數(shù)限制了單個節(jié)點上的最大并行度。
說明節(jié)點上所有會話的ePQ workers進程數(shù)不能超過該參數(shù)大小。
polar_px_dop_per_node
設置當前會話并行查詢的并行度,默認為1,推薦值為當前CPU 總核數(shù),取值范圍為1~128。若設置該參數(shù)為N,則一個會話在每個節(jié)點上將會啟用N個ePQ Worker進程,用于處理當前的ePQ邏輯。
polar_px_nodes
指定參與ePQ的只讀節(jié)點。默認為空,表示所有只讀節(jié)點都參與。可配置為指定節(jié)點參與ePQ,以逗號分隔。
px_worker
指定ePQ是否對特定表生效。默認不生效。ePQ功能比較消耗集群計算節(jié)點的資源,因此只有對設置了px_workers的表才使用該功能。例如:
ALTER TABLE t1 SET(px_workers=1):表示t1表允許ePQ。
ALTER TABLE t1 SET(px_workers=-1):表示t1表禁止ePQ。
ALTER TABLE t1 SET(px_workers=0):表示t1表忽略ePQ(默認狀態(tài))。
以簡單的單表查詢操作,來描述ePQ的功能是否有效。
創(chuàng)建test表并插入基礎數(shù)據。
CREATE TABLE test(id int); INSERT INTO test SELECT generate_series(1,1000000);查詢執(zhí)行計劃。
EXPLAIN SELECT * FROM test;執(zhí)行結果如下:
QUERY PLAN -------------------------------------------------------- Seq Scan on test (cost=0.00..35.50 rows=2550 width=4) (1 row)說明默認情況下ePQ功能不開啟,單表查詢執(zhí)行計劃為PG原生的Seq Scan。
開啟并使用ePQ功能。
ALTER TABLE test SET (px_workers=1); SET polar_enable_px = on; EXPLAIN SELECT * FROM test;結果如下:
QUERY PLAN ------------------------------------------------------------------------------- PX Coordinator 2:1 (slice1; segments: 2) (cost=0.00..431.00 rows=1 width=4) -> Seq Scan on test (scan partial) (cost=0.00..431.00 rows=1 width=4) Optimizer: PolarDB PX Optimizer (3 rows)配置參與ePQ的計算節(jié)點范圍。
查詢當前所有只讀節(jié)點的名稱。
CREATE EXTENSION polar_monitor; SELECT name,host,port FROM polar_cluster_info WHERE px_node='t';結果如下:
name | host | port -------+-----------+------ node1 | 127.0.0.1 | 5433 node2 | 127.0.0.1 | 5434 (2 rows)說明當前集群有2個只讀節(jié)點,名稱分別為:node1,node2。
指定node1只讀節(jié)點參與ePQ。
SET polar_px_nodes = 'node1';查詢參與并行查詢的節(jié)點。
SHOW polar_px_nodes;結果如下:
polar_px_nodes ---------------- node1 (1 row)說明參與并行查詢的節(jié)點是node1。
查詢test表中所有數(shù)據。
EXPLAIN SELECT * FROM test;結果如下:
QUERY PLAN ------------------------------------------------------------------------------- PX Coordinator 1:1 (slice1; segments: 1) (cost=0.00..431.00 rows=1 width=4) -> Partial Seq Scan on test (cost=0.00..431.00 rows=1 width=4) Optimizer: PolarDB PX Optimizer (3 rows) QUERY PLAN
使用ePQ進行分區(qū)表查詢。
開啟ePQ功能。
SET polar_enable_px = ON;開啟分區(qū)表ePQ功能。
SET polar_px_enable_partition = true;說明分區(qū)表ePQ功能默認關閉。
開啟多級分區(qū)表ePQ功能。
SET polar_px_optimizer_multilevel_partitioning = true;
當前ePQ對分區(qū)表支持的功能如下所示:
支持Range分區(qū)的并行查詢。
支持List分區(qū)的并行查詢。
支持單列Hash分區(qū)的并行查詢。
支持分區(qū)裁剪。
支持帶有索引的分區(qū)表并行查詢。
支持分區(qū)表連接查詢。
支持多級分區(qū)的并行查詢。
使用ePQ加速索引創(chuàng)建。
開啟使用ePQ加速創(chuàng)建索引功能。
SET polar_px_enable_btbuild = on;創(chuàng)建索引。
CREATE INDEX t ON test(id) WITH(px_build = ON);查詢表結構。
\d test結果如下:
Table "public.test" Column | Type | Collation | Nullable | Default --------+---------+-----------+----------+--------- id | integer | | | id2 | integer | | | Indexes: "t" btree (id) WITH (px_build=finish)
說明當前僅支持對B-Tree索引的構建,且暫不支持INCLUDE等索引構建語法,暫不支持表達式等索引列類型。
如果需要使用ePQ功能加速創(chuàng)建索引,請使用如下參數(shù):
參數(shù)
說明
polar_px_dop_per_node
指定通過ePQ加速構建索引的并行度。默認為1,取值范圍為1~128。
polar_px_enable_replay_wait
當使用ePQ加速索引構建時,當前會話內無需手動開啟該參數(shù),該參數(shù)將自動生效。以保證最近更新的數(shù)據表項可以被創(chuàng)建到索引中,保證索引表的完整性。索引創(chuàng)建完成后,該參數(shù)將會被重置為數(shù)據庫默認值。
polar_px_enable_btbuild
是否開啟使用ePQ加速創(chuàng)建索引。取值為OFF時不開啟(默認),取值為ON時開啟。
polar_bt_write_page_buffer_size
指定索引構建過程中的寫I/O策略。該參數(shù)默認值為0(不開啟),單位為塊,最大值可設置為8192。推薦設置為4096。
參數(shù)值為0:該參數(shù)設置為不開啟,在索引創(chuàng)建的過程中,對于索引頁寫滿后的寫盤方式是block-by-block的單個塊寫盤。
參數(shù)值不為0:該參數(shù)設置為開啟,內核中將緩存一個polar_bt_write_page_buffer_size大小的buffer,對于需要寫盤的索引頁,會通過該buffer進行I/O合并再統(tǒng)一寫盤,避免了頻繁調度I/O帶來的性能開銷。該參數(shù)會額外提升20%的索引創(chuàng)建性能。