自動分區(qū)
使用效果
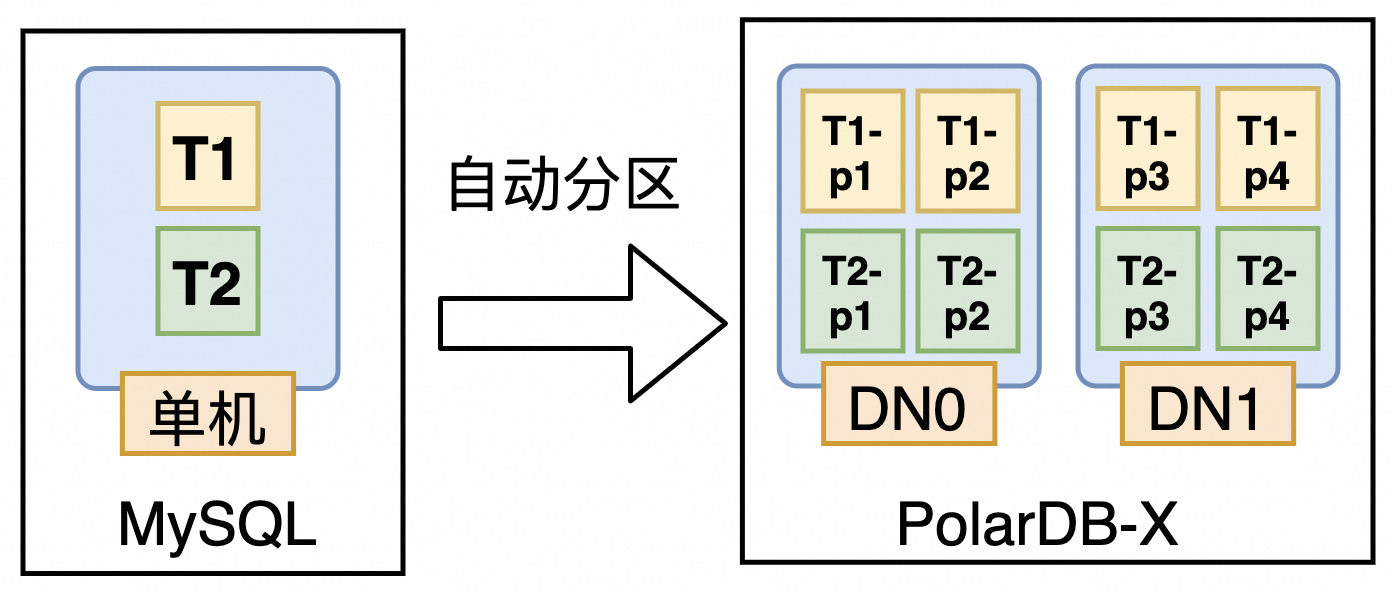
PolarDB-X透明分布式的自動分區(qū)的工作模式,就是將一個邏輯庫內(nèi)的所有 MySQL單表(沒有顯式使用MySQL分區(qū)語法的表),默認(rèn)按如下方式?jīng)Q定分區(qū)方案(如下圖所示):
自動使用表的主鍵進(jìn)行水平分區(qū);
表的所有索引自動使用全局索引,并按索引列進(jìn)行水平分區(qū)。
適用場景
由于該工作模式會對原有業(yè)務(wù)的所有MySQL單表實(shí)施自動分區(qū),所以這種透明分布式的工作模式更適合于對性能要求不高的基于MySQL單機(jī)數(shù)據(jù)庫開發(fā)的應(yīng)用(比如,一些新開發(fā)的需要快速上線的應(yīng)用)。通常,這類型而業(yè)務(wù)的庫表數(shù)目不多,應(yīng)用的查詢場景相對簡單(比如按表主鍵點(diǎn)查)。
在實(shí)際應(yīng)用的過程中,關(guān)于透明分布式的自動分區(qū)工作模式的適用場景的細(xì)節(jié),可以參考最佳實(shí)踐。
使用示例
創(chuàng)建使用自動分區(qū)的數(shù)據(jù)庫
在PolarDB-X中,要使用透明分布式的自動分區(qū)工作模式,可以使用以下的建庫 SQL:
CREATE DATABASE autodb2 MODE='auto' DEFAULT_SINGLE='off';目前AUTO庫透明分布式的默認(rèn)工作模式是自動分區(qū),所以也可以直接使用以下的建庫SQL:
CREATE DATABASE autodb2 MODE='auto';創(chuàng)建多張MySQL單表并自動分區(qū)
可嘗試使用以下的建表SQL,在my_autodb內(nèi)創(chuàng)建多張單表:
CREATE TABLE auto_t1(
id bigint not null auto_increment,
bid int,
name varchar(30),
birthday datetime,
primary key(id),
index idx_name(name)
);查看自動分區(qū)表的完整建表SQL
mysql> CREATE TABLE auto_t1(
-> id bigint not null auto_increment,
-> bid int,
-> name varchar(30),
-> birthday datetime,
-> primary key(id),
-> index idx_name(name)
-> );
Query OK, 0 rows affected (2.44 sec)
mysql>
mysql> show full create table auto_t1\G
*************************** 1. row ***************************
Table: auto_t1
Create Table: CREATE PARTITION TABLE `auto_t1` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`bid` int(11) DEFAULT NULL,
`name` varchar(30) DEFAULT NULL,
`birthday` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
GLOBAL INDEX /* idx_name_$6425 */ `idx_name` (`name`)
PARTITION BY KEY(`name`,`id`)
PARTITIONS 3,
LOCAL KEY `_local_idx_name` (`name`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4
PARTITION BY KEY(`id`)
PARTITIONS 3
/* tablegroup = `tg3741` */
1 row in set (0.03 sec)
可見,原MySQL單表在PolarDB-X下自動分區(qū),索引自動變成全局索引。
注意事項(xiàng)
必須是AUTO庫才支持透明分布式自動分區(qū)模式(DRDS 庫不支持),即建庫 SQL 時必須指定 MODE='AUTO' ;
自動分區(qū)后,部分表的寫入性能可能變會大,這是部分表原來的索引變成全局索引表,導(dǎo)致寫入操作需要通過分布式事務(wù)維護(hù)全局索引表與主表的一致性。