本文介紹了什么是AUTO模式數據庫與DRDS模式數據庫,以及這兩者模式的區別。
PolarDB-X數據庫模式概述
從PolarDB-X 5.4.13版本開始,新增支持AUTO模式的數據庫(也稱為自動分區數據庫)。AUTO模式的數據庫支持自動分區,即創建表時無需指定分區鍵,數據即可自動在集群內均勻分布;同時也支持使用標準的MySQL分區表語法,對表進行手動分區。可以讓您便捷地享受到分布式數據庫的透明式分布、彈性伸縮和分區管理等諸多紅利。
PolarDB-X 5.4.13版本之前的數據庫稱為DRDS模式的數據庫。這種模式的數據庫不支持自動分區,創建表時需使用DRDS專用的分庫分表語法,指定分庫分表鍵,否則創建的是一張單表。
AUTO模式數據庫和DRDS模式數據庫在5.4.13及以上版本都支持,并且可以共存在一個實例中。
注意事項
創建AUTO模式數據庫必須在
CREATE DATABASE語法中顯式指定MODE='AUTO'。如果在
CREATE DATABASE語法中不指定MODE參數的值,默認創建DRDS模式的數據庫。AUTO模式數據庫下不支持使用DRDS分庫分表的語法創建表,僅支持創建分區表。
DRDS模式數據庫下不支持使用分區表的語法創建表,僅支持創建分庫分表。
標準版集群不支持創建AUTO模式數據庫。
通過MODE參數指定數據庫模式
PolarDB-X在創建數據庫時引入了MODE參數,以決定創建的數據庫是AUTO模式還是DRDS模式。關于MODE參數的作用及其描述,如下表所示:
數據庫創建完成后,MODE不允許修改。
參數 | 取值類型 | 作用 | 建庫語法 | 建表語法 |
MODE | 'AUTO' | 創建的數據庫為AUTO模式。 | 示例: 詳情請參見CREATE DATABASE。 | AUTO模式數據庫下創建的表稱為分區表,采用MySQL標準語法,詳情請參見MySQL分區表語法。 |
'DRDS'(默認值) 說明 若不指定MODE參數,則默認創建DRDS模式數據庫。 | 創建的數據庫為DRDS模式。 | 示例:
詳情請參見CREATE DATABASE。 | DRDS模式數據庫下創建的表稱為分庫分表,詳情請參見DRDS分庫分表語法。 |
自動分區與手動分區
自動分區
自動分區,指創建表時不指定任何分區定義(如分區鍵、分區策略等),PolarDB-X能夠自動選擇分區鍵并對表及其索引進行水平分區的功能。AUTO模式數據庫支持自動分區,而DRDS模式數據庫不支持。
示例如下:
使用標準的MySQL語法創建tb表,語法上不包含任何分區定義:
CREATE TABLE tb(a INT, b INT, PRIMARY KEY(a));上述DDL在DRDS模式數據庫中創建出來的表是一張單表(如下圖所示,默認不分區):
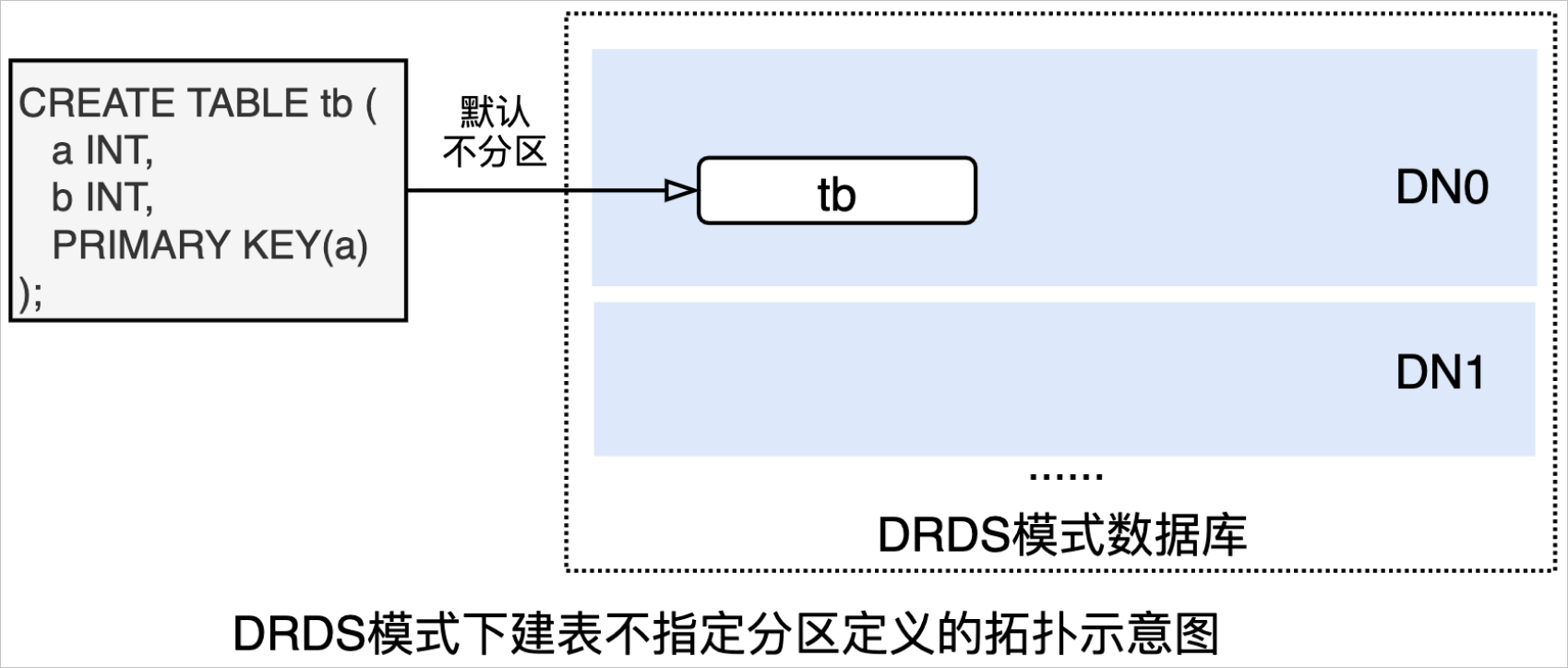
執行
SHOW語句,查看完整建表語句:SHOW FULL CREATE TABLE tb \G *************************** 1. row *************************** Table: tb Create Table: CREATE TABLE `tb` ( `a` int(11) NOT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`a`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 1 row in set (0.02 sec)上述DDL在AUTO模式數據庫建來的表將是一分區表(如下圖所示,默認按主鍵自動分區):
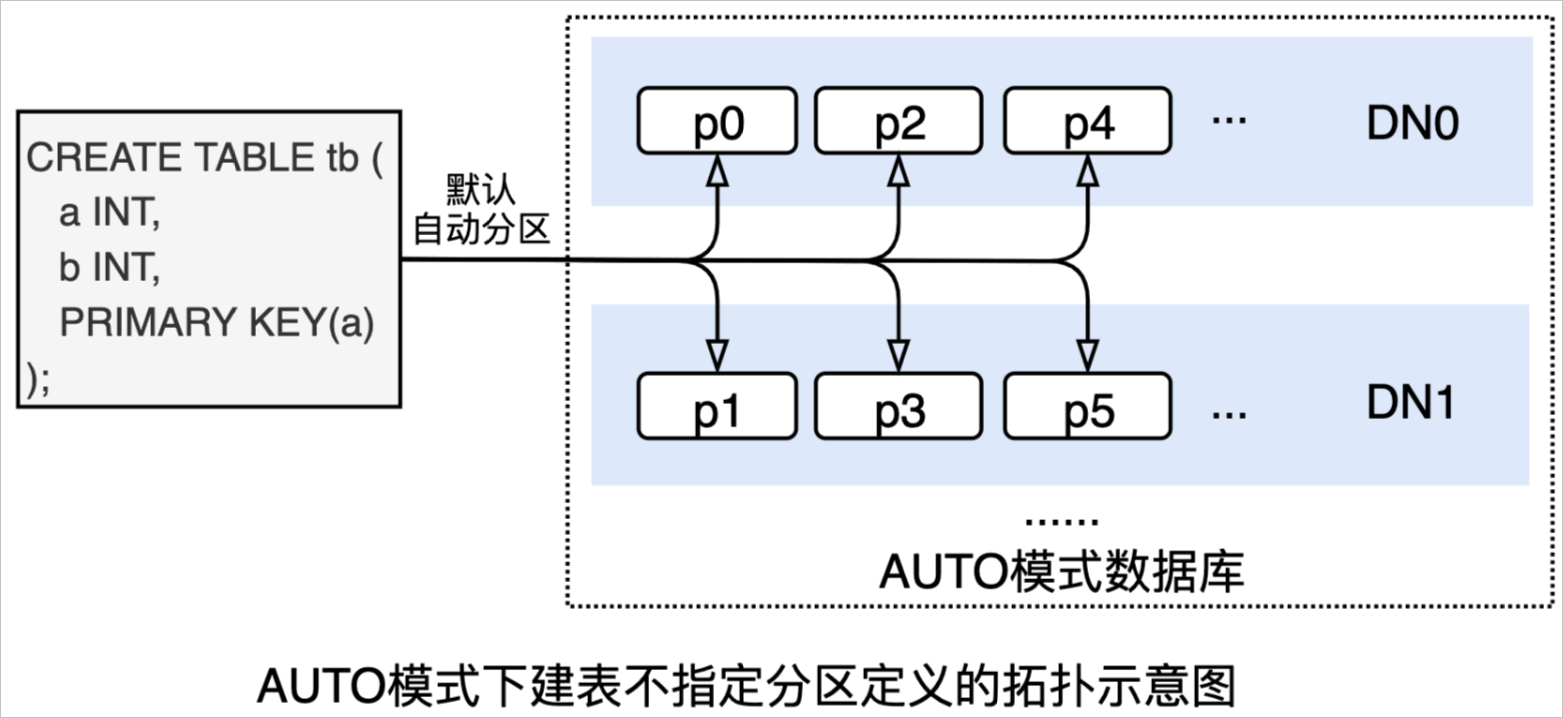 執行
執行SHOW語句,查看完整建表語句:SHOW FULL CREATE TABLE tb \G *************************** 1. row *************************** TABLE: tb CREATE TABLE: CREATE PARTITION TABLE `tb` ( `a` int(11) NOT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`a`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 PARTITION BY KEY(`a`) PARTITIONS 16 1 row in set (0.01 sec)
因此,在AUTO模式數據庫下,只需要使用標準的MySQL建表語法(包括建索引語法等)創建表,PolarDB-X的自動分區功能可以讓應用便捷地享受到分布式數據庫所帶來的彈性伸縮、分區管理等諸多紅利。
手動分區
手動分區,即創建表時顯式指定分區定義(如分區鍵、分區策略等)。AUTO模式數據庫與DRDS模式數據庫采用手動分區時的建表語法不同。
AUTO模式數據庫:創建表使用標準的MySQL分區表語法,并支持HASH、RANGE、LIST等多種分區策略。
如下示例,創建tb表時使用
PARTITION BY HASH(a)語法,指定了分區鍵a列及HASH的分區策略:CREATE TABLE tb (a INT, b INT, PRIMARY KEY(a)) -> PARTITION by HASH(a) PARTITIONS 4; Query OK, 0 rows affected (0.83 sec) SHOW FULL CREATE TABLE tb\G *************************** 1. row *************************** TABLE: tb CREATE TABLE: CREATE TABLE `tb` ( `a` int(11) NOT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`a`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 PARTITION BY KEY(`a`) PARTITIONS 4 1 row in set (0.02 sec)DRDS模式數據庫:創建表使用DRDS專用的分庫分表語法,僅支持使用HASH策略。
如下示例,創建tb表時使用
DBPARTITION BY HASH(a) TBPARTITION BY HASH(a)語法,指定分庫分表鍵為a列:CREATE TABLE tb (a INT, b INT, PRIMARY KEY(a)) -> DBPARTITION by HASH(a) -> TBPARTITION by HASH(a) -> TBPARTITIONS 4; Query OK, 0 rows affected (1.16 sec) SHOW FULL CREATE TABLE tb\G *************************** 1. row *************************** Table: tb Create Table: CREATE TABLE `tb` ( `a` int(11) NOT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`a`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 dbpartition by hash(`a`) tbpartition by hash(`a`) tbpartitions 4 1 row in set (0.02 sec)
分區表和分庫分表的路由算法對比
分區表與分庫分表最重要的區別,是它們的分區會使用完全不同的路由算法。如下圖所示:
分庫分表的路由算法是HASH值按物理分表數目取模,如果要變更分區數目(例如分表數目由4個變成5個),所有數據都需要進行rehash,因此,DRDS模式的分庫分表無法提供分區級的變更能力;
分區表的默認路由算法是基于range的一致性HASH算法,這種算法天然支持通過分裂、合并操作等變更分區,并且無須rehash所有數據,因此,AUTO模式的分區表具備分區級的變更能力。
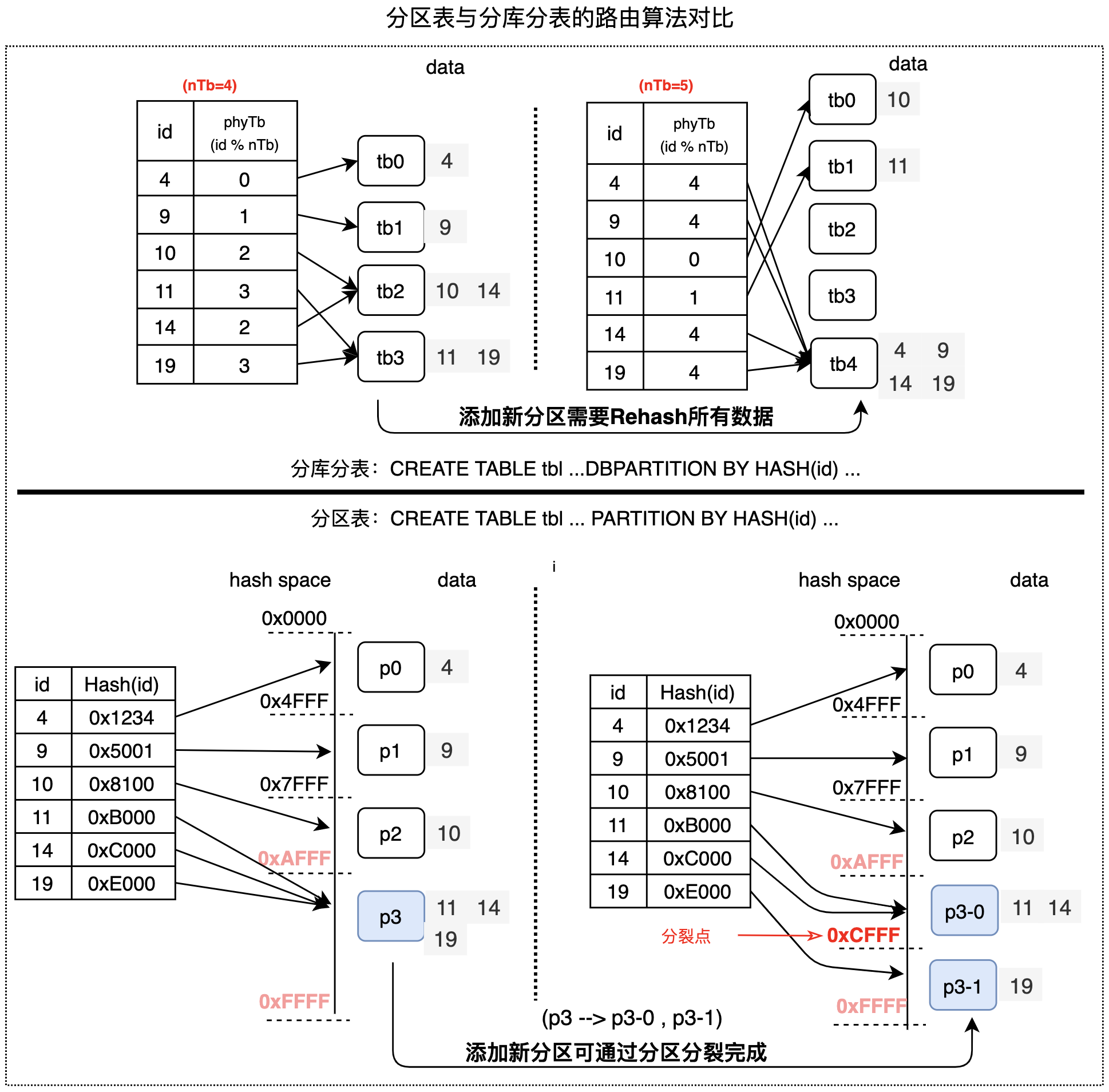
功能對比
與DRDS模式數據庫相比,AUTO模式數據庫新增了自動分區、熱點分裂、分區調度和TTL表等新特性,并在很多其它方面(如分區管理、拆分變更等)做了大量工作以優化分布式體驗。
AUTO模式數據庫與DRDS模式數據庫主要功能對比:
功能項 | AUTO模式數據庫 | DRDS模式數據庫 | |
透明分布式 | 默認主鍵分區 | 支持。若建表時不指定分區定義,將自動按主鍵進行分區。 | 不支持。 |
默認全局二級索引 | 支持。索引不指定分區列時,將自動索引列分區。 | 不支持。 | |
負載均衡調度 | 支持。 | 不支持。 | |
熱點散列能力 | 支持。 | 不支持。 | |
分區策略 | Hash分區 & Key分區 | 支持。采用一致性哈希的路由算法,并支持熱點散列。 | 支持采用按分區數取模的路由算法,不支持熱點散列。 |
Range分區 & Range Columns分區 | 支持,支持熱點散列。 | 不支持。 | |
List分區 & List Columns分區 | 支持。 | 不支持。 | |
向量分區鍵(使用多個列作為分區鍵) | 支持。分區鍵支持按向量分區,例如 | 不支持。 | |
分區鍵字符校驗集 | 支持。 | 不支持。 | |
單表 & 廣播表 | 支持。 | 支持。 | |
分區管理 | 創建、刪除、修改分區 | 支持。 | 不支持。 |
分裂、合并分區 | 支持。 | 不支持。 | |
遷移分區 | 支持。 | 不支持。 | |
截斷分區 | 支持。 | 不支持。 | |
分區透視 | 即將上線將支持自動分析熱點分區。 | 不支持。 | |
拆分變更 | 調整表類型(單表、廣播表與分區表互轉) | 支持。 | 支持。 |
調整分區定義(包括分區數目、分區鍵類型、分區策略等) | 支持。 | 支持。 | |
彈性擴(縮)容 | 是否有停寫階段 | 否。 | 是(短暫的停寫)。 |
是否允許其他DDL | 是。 | 否。 | |
Locality | 靜態隔離 | 支持,創建庫、表和分區時指定物理存儲資源。 | 支持,創建庫、表時指定物理存儲資源。 |
動態隔離 | 支持,動態調整庫表所在的物理存儲資源。 | 不支持。 | |
是否與擴縮容兼容 | 是。 | 否。 | |
分區裁剪 | 前綴分區裁剪 | 支持。 例如,按 | 不支持。 |
計算表達式常量折疊 | 支持。 例如,對含計算表達式的條件 | 不支持。分區鍵條件要求必須是常量(如pk = 123);如果分區鍵是計算表達式如 | |
分區路由大小寫敏感及忽略行尾空格 | 支持。 支持通過指定分區鍵的字符校驗集(Collation)來決定分區路由是否需要區分大小寫以及是否需要忽略行尾空格。 | 不支持。分區列不支持使用Collation,Hash算法只支持大小寫敏感,不支持忽略行尾空格。 | |
JOIN計算下推 | 支持。 支持在分區的分裂、合并與遷移等操作期間,JOIN計算下推不受影響。 | 支持。 | |
分區選擇 | 支持。 支持分區選擇語法查詢特定分區,例如 | 不支持。 | |
TTL(分區的生命周期管理) | 支持。 | 不支持。 | |
AUTO_INCREMENT | 支持。保證全局唯一性、單調遞增和連續性。 | 支持。保證全局唯一性,不保證單調遞增和連續性。 | |
性能對比
由于DRDS模式分庫分表與AUTO模式分區表使用了不同的路由算法,為了評估這兩種路由算法的性能差異,將使用Sysbench對PolarDB-X進行基準測試,觀察它們在不同的Sysbench測試場景下的吞吐(單位:QPS)差異。
測試環境
PolarDB-X實例規格:polarx.x4.2xlarge.2e
CN (16C64G) × 2
DN (16C64G) × 2
版本:5.4.13-16415631
分區表和分庫分表配置:
分區表:
32個分區
分區語句:partition by hash(id) partitions 32
表數據總量:16000W
分庫分表:
32個物理分表
分庫分表語句:dbpartition by hash(id) tbpartition by hash(id) tbpartition 2
表數據總量:16000W
測試場景
Sysbench細分場景說明:
oltp_point_select:僅含分區鍵的單點等值查詢。
oltp_read_only:事務中同時混合分區鍵的單點查詢與小范圍查詢(例如Between)。
oltp_read_write:事務中同時混合分區鍵的單點與小范圍的查詢與寫入。
測試結果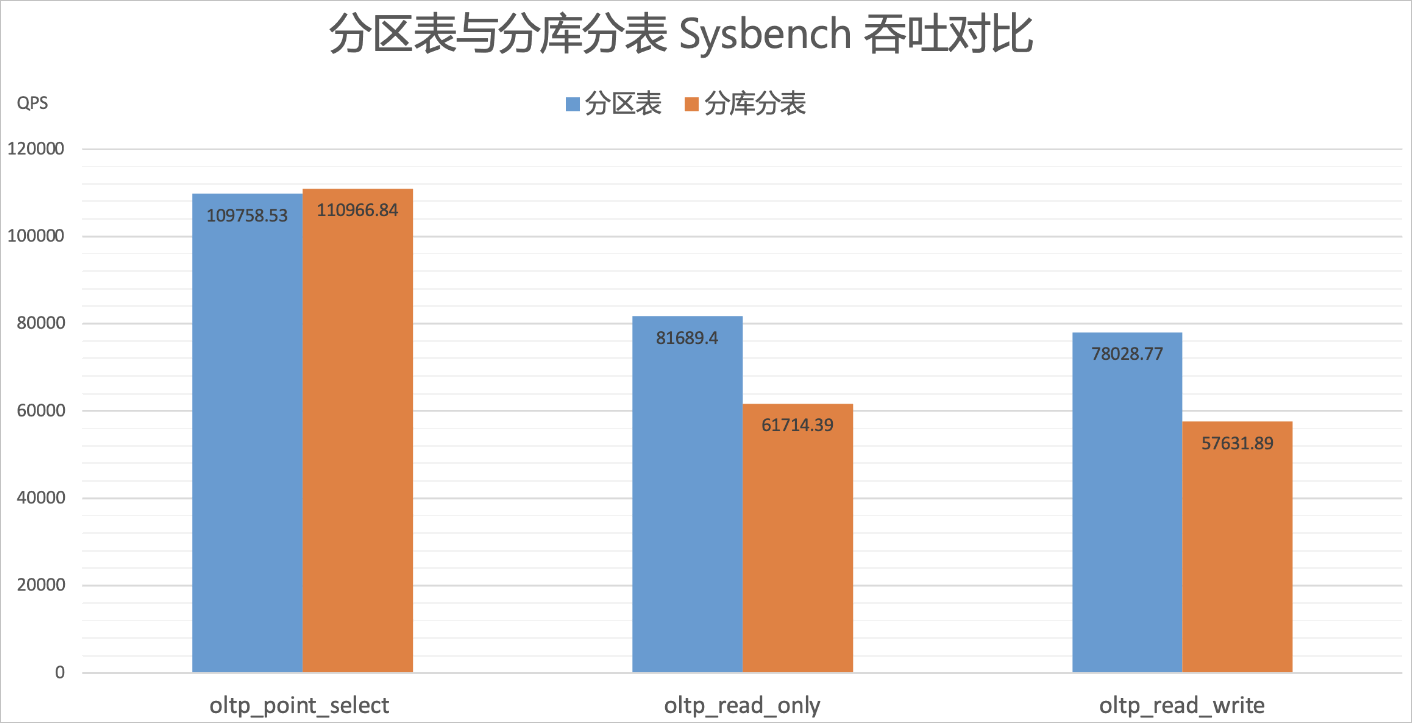
分析以上測試結果,可以得出以下結論:
分區表使用的一致性HASH路由算法雖然比原來分庫分表中按HASH取模的路由算法更為復雜,但在oltp_point_select場景中吞吐并沒有下降太多,基本與原來的持平。
在oltp_read_only&oltp_read_write場景中,由于這些場景會出現小范圍的查詢,SQL的查詢條件表達式會比oltp_point_select復雜,得益于分區表的裁剪優化,整體吞吐比原來提升約33%。
FAQ
Q1:建庫時,AUTO模式與DRDS模式應該如何選擇?
A:從5.4.13及以上版本開始,從PolarDB-X 1.0遷移過來的或者全新的應用,均推薦使用AUTO模式。
Q2:在AUTO模式下,建表時自動分區與手動分區應該如何選擇?
A:在測試階段可以完全用自動分區的方式,當發現業務需要調優的時候,可以通過DDL(
ALTER PARTITION)語句變更表的分區方式。如果非常了解業務的具體SQL,知道具體的表與表之間的關聯關系,可以按照手動分區的方式建表。Q3:DRDS模式的數據庫如何切換到AUTO模式?
A:內核5.4.16及以上版本可以采用下列任意方式;低于5.4.16的版本,僅支持方法二和方法三。關于如何查看實例版本,請參見查看實例版本。
方法一:從5.4.16版本開始,內核提供了
create database like/as語法,可以一鍵將DRDS模式數據庫切換為AUTO模式,使用方法請參見將DRDS模式數據庫轉換為AUTO模式數據庫;方法二:在目標實例創建對應的AUTO模式數據庫,在AUTO模式數據庫下將表創建好,然后通過DTS服務,將原DRDS模式的庫同步到AUTO模式的庫。
方法三:通過
mysqldump命令將原來的DRDS模式數據庫的數據文件dump下來(不含建表語句),然后創建對應的AUTO模式數據庫,在AUTO模式數據庫下將表創建好,然后將dump下來的數據文件通過source命令導入目標AUTO模式數據庫。
Q4:AUTO模式自動分區的默認分區數是多少?
A:AUTO模式的自動分區數目=實例創建時的節點數目×8 。 例如,實例創建時使用2個節點,則默認的自動分區數目=2×8=16。 分區數在實例完成創建后將一直保持不變(它不會受實例擴縮容的影響),除非手動調整對應的參數值。
Q5:是否支持手動調整自動分區的默認分區數?
A:支持。默認分區數對應的參數名稱是AUTO_PARTITION_PARTITIONS,參數的生效級別是實例級。因此,該參數被調整后,實例中所有的AUTO模式數據庫下新創建的表的自動分區數都將發生改變。需要注意的是,如果新創建的表的分區數與原來已創建的表的分區數不一致,將會導致它們之間的JOIN計算下推失效,影響執行效率,建議手動調整分區數,詳情請參見變更表級分區(AUTO模式)。