DDL復制
本文介紹全球數(shù)據(jù)庫網(wǎng)絡(luò)(Global Database Network,簡稱GDN)的DDL復制操作。
通過高效的DML復制,可以實現(xiàn)GDN上下游集群之間數(shù)據(jù)表內(nèi)容的一致性,而DDL復制,則是保證GDN主從集群之間Schema一致性的核心能力。GDN主從集群之間Schema的一致性不僅僅局限于表結(jié)構(gòu)的一致,而且體現(xiàn)在所有數(shù)據(jù)庫對象之間的一致,這樣才能保證在發(fā)生主從切換時從集群有能力承載應(yīng)用的流量。否則,即使丟失一個索引,也可能引發(fā)嚴重的性能問題。
DDL類型
PolarDB-X支持多種類型的數(shù)據(jù)庫對象,包括常見的兼容MySQL的表、列、索引、視圖、函數(shù)等,以及TableGroup、Sequence、全局二級索引(GSI)、列存索引(CCI)、自定義函數(shù)等各種自定義的對象類型。此外,還提供了許多自定義的擴展語法,如TTL、Locality、無鎖變更列類型(OMC)、本地索引(Local index)等。無論是在兼容性還是分布式場景的復雜性方面,DDL復制都是一個相當具有挑戰(zhàn)性的能力。因此,PolarDB-X提供了內(nèi)置的DDL復制能力,簡單、可靠且易于使用。
DDL類型支持情況說明:
類別 | 類型 | 是否支持 | 說明 |
DATABASE | CREATE_DATABASE | 是 | 請參見:數(shù)據(jù)庫。 說明 ALTER DATABASE目前不支持修改字符集,因此在復制場景下無法實現(xiàn)支持。 |
DROP_DATABASE | 是 | ||
ALTER_DATABASE | 否 | ||
MOVE_DATABASE | 否 | ||
TABLE | CREATE_TABLE | 是 | 請參見:數(shù)據(jù)表。 |
ALTER_TABLE | 是 | ||
DROP_TABLE | 是 | ||
TRUNCATE_TABLE | 是 | ||
RENAME_TABLE | 是 | ||
ANALYZE_TABLE | 是 | ||
PARTITION | 分區(qū)分裂 | 是 | 請參見:分區(qū)變更語法。 說明 暫不支持分區(qū)遷移,請參見限制一。 |
熱點分區(qū)分裂 | 是 | ||
分區(qū)合并 | 是 | ||
分區(qū)遷移 | 否 | ||
重命名分區(qū) | 是 | ||
增加分區(qū) | 是 | ||
刪除分區(qū) | 是 | ||
修改分區(qū) | 是 | ||
重組分區(qū) | 是 | ||
清空分區(qū) | 是 | ||
TABLEGROUP | CREATE_TABLEGROUP | 是 | 請參見:表組。 |
DROP_TABLEGROUP | 是 | ||
ALTER_TABLEGROUP | 是 | ||
MERGE_TABLEGROUP | 是 | ||
ALTER_TABLEGROUP_ADD_TABLE | 是 | ||
ALTER_TABLE_SET_TABLEGROUP | 是 | ||
JOINGROUP | CREATE_JOINGROUP | 是 | |
ALTER_JOINGROUP | 是 | ||
DROP_JOINGROUP | 是 | ||
INDEX | CREATE_INDEX | 是 | 請參見:索引。 |
DROP_INDEX | 是 | ||
ALTER_INDEX | 是 | ||
ALTER_INDEX_VISIBILITY | 是 | ||
SEQUENCE | CREATE_SEQUENCE | 是 | 請參見:Sequence。 |
DROP_SEQUENCE | 是 | ||
ALTER_SEQUENCE | 是 | ||
RENAME_SEQUENCE | 是 | ||
CONVERT_ALL_SEQUENCES | 是 | ||
FUNCTION | CREATE_FUNCTION | 是 | 請參見:自定義函數(shù)。 |
DROP_FUNCTION | 是 | ||
ALTER_FUNCTION | 是 | ||
CREATE_JAVA_FUNCTION | 是 | ||
ALTER_JAVA_FUNCTION | 是 | ||
DROP_JAVA_FUNCTION | 是 | ||
PROCEDURE | CREATE_PROCEDURE | 是 | 請參見:存儲過程。 |
ALTER_PROCEDURE | 是 | ||
DROP_PROCEDURE | 是 | ||
VIEW | CREATE_VIEW | 是 | 請參見:視圖。 |
DROP_VIEW | 是 | ||
ALTER_VIEW | 是 | ||
CREATE_MATERIALIZED_VIEW | 是 | ||
DROP_MATERIALIZED_VIEW | 是 | ||
USER | CREATE_USER | 是 | 請參見:賬號權(quán)限管理。 |
DROP_USER | 是 | ||
SET_PASSWORD | 是 | ||
GRANT_PRIVILEGE_TO_USER | 是 | ||
REVOKE_PRIVILEGE_FROM_USER | 是 | ||
ROLE | CREATE_ROLE | 是 | 請參見:角色權(quán)限管理。 |
DROP_ROLE | 是 | ||
GRANT_PRIVILEGE_TO_ROLE | 是 | ||
GRANT_ROLE_TO_USER | 是 | ||
SQL_SET_DEFAULT_ROLE | 是 | ||
REVOKE_PRIVILEGE_FROM_ROLE | 是 | ||
REVOKE_ROLE_FROM_USER | 是 | ||
SET | SET GLOBAL ... | 否 | PolarDB-X采取了和MySQL相同的策略,在主從復制鏈路中并未進行同步,這并非Schema變更。如需進行調(diào)整,請在主集群和從集群分別進行操作。 |
SQL限流 | * | 否 | SQL限流通常是一種臨時性操作,GDN不支持將限流規(guī)則復制到從集群,如果需要,請在主集群和從集群分別進行操作。 |
目前不支持與列存索引相關(guān)的DDL復制(CREATE/DROP/ALTER COLUMNAR INDEX)。
表組類型
PolarDB-X支持兩種類型的表組:顯式表組和隱式表組。
顯式表組允許用戶自定義,可以通過
CREATE TABLEGROUP進行創(chuàng)建,通過DROP TABLEGROUP進行刪除,通過ALTER TABLEGROUP進行變更,具體操作可參考表組。隱式表組由PolarDB-X隱式創(chuàng)建,當創(chuàng)建分區(qū)表、刪除分區(qū)表、變更表的分區(qū)類型時,可能會涉及隱式表組的創(chuàng)建、變更或刪除。隱式表組不支持通過
CREATE TABLEGROUP和DROP TABLEGROUP進行管理,但支持通過ALTER TABLEGROUP進行變更。隱式表組的名稱通過維護一個序列號生成,如tg1、tg2、tg3...,以此類推。該序列號的生成具有不確定性,例如并行創(chuàng)建兩張不同的分區(qū)表T1和T2,這兩張表對應(yīng)的隱式表組的序號大小是隨機的;此外,序號還可能被跳過,例如對序號加1后生成了表組名稱,但DDL任務(wù)流出現(xiàn)了回滾,則該序號被作廢。
隱式表組對PolarDB-X的主從復制帶來了挑戰(zhàn)。如果讓主集群和從集群按照默認的規(guī)則各自生成自己的隱式表組,可能會導致主從集群中相同表的隱式表組名稱不一致,甚至可能出現(xiàn)所有隱式表組名稱完全混亂的情況。在GDN數(shù)據(jù)復制場景下,隱式表組的復制是通過擴展DDL SQL語法來實現(xiàn)的。當DDL操作涉及隱式表組的變更時,主集群記錄到Binlog中的DDL都是經(jīng)過擴展的DDL SQL。
示例一
提交的建表SQL:
create table if not exists tb1 (
a int PRIMARY KEY,
b int,
c int,
d varchar(10) UNIQUE,
INDEX b(b),
INDEX b_2(b),
KEY b_3 (b),
KEY b_4 (b),
UNIQUE KEY b_5 (b),
UNIQUE KEY b_6 (b),
UNIQUE INDEX b_7 (b),
UNIQUE INDEX b_8 (b),
INDEX g1(b),
KEY g2 (b),
UNIQUE KEY g3 (b),
UNIQUE INDEX g4 (b)
) DEFAULT CHARACTER SET = utf8mb4 DEFAULT COLLATE = utf8mb4_general_ci;示例二
提交的變更分區(qū)的SQL:
ALTER TABLE tb1 MERGE PARTITIONS p1, p2 TO p12;記錄到Binlog中經(jīng)過擴展后的SQL:
ALTER TABLE tb1 MERGE PARTITIONS p1, p2 TO p12 WITH TABLEGROUP=tg29 IMPLICIT;多流復制
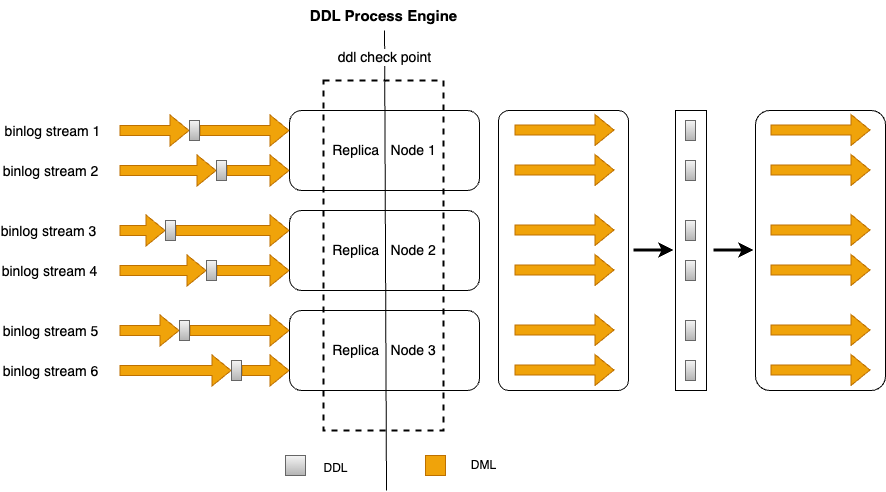
在單流復制場景下,只需按照Binlog中的順序逐條執(zhí)行復制主集群的DDL SQL到從集群。然而,在多流復制場景下,在進行DDL復制時,則需要考慮不同復制鏈路之間的協(xié)調(diào)一致。每條復制鏈路在收到某條DDL SQL后必須等待其它復制鏈路,只有當所有鏈路都收到該DDL SQL之后,才可以將DDL操作復制給從集群,否則將導致DML流量和Schema之間的不一致,引發(fā)異常或數(shù)據(jù)錯誤。
針對多流復制,GDN提供了分布式DDL復制引擎(Distributed DDL Replication Engine),通過高效的多路協(xié)調(diào)算法,實現(xiàn)分布式場景下DDL復制的一致性。
使用限制
限制一
PolarDB-X提供了支持通過LOCALITY指定存儲位置。該特性允許在DDL SQL中包含DN節(jié)點的實例id。然而,由于GDN目前暫不支持主從集群間DN節(jié)點之間的關(guān)聯(lián)映射,因此在將包含此類SQL的DDL復制到下游時,系統(tǒng)將會剔除SQL中涉及DN的相關(guān)內(nèi)容。針對這一情況,您可登錄從集群并手動進行分區(qū)分布的調(diào)整。
示例一
// 主集群執(zhí)行SQL: CREATE TABLE test_pg3 ( id int ) DEFAULT CHARSET = utf8mb4 DEFAULT COLLATE = utf8mb4_general_ci PARTITION BY RANGE (id) ( PARTITION p0 VALUES LESS THAN (1000) LOCALITY 'dn=xdevelop-240524092100-31ef-bngl-dn-1', PARTITION p1 VALUES LESS THAN (2000) LOCALITY 'dn=xdevelop-240524092100-31ef-bngl-dn-1' ) // 復制到從集群的SQL: create table test_pg3 ( id int ) DEFAULT CHARACTER SET = utf8mb4 DEFAULT COLLATE = utf8mb4_general_ci PARTITION BY RANGE (id) ( PARTITION p0 VALUES LESS THAN (1000), PARTITION p1 VALUES LESS THAN (2000) ) WITH TABLEGROUP = tg3778 IMPLICIT示例二
// 主集群執(zhí)行SQL: ALTER TABLE special_dml_test1 MOVE PARTITIONS (p2, p4, p6, p8) TO 'xdevelop-240524092100-31ef-bngl-dn-0'; // 復制到從集群的SQL: ALTER TABLE special_dml_test1;
限制二
PolarDB-X提供了SET PARTITION_HINT命令,可以指定SQL語句在特定分區(qū)上執(zhí)行。在GDN主從集群復制場景下,目前不支持將該命令透傳到從集群,也就是說,在主集群通過該命令顯式將數(shù)據(jù)寫入指定分區(qū)后,GDN無法保證這些數(shù)據(jù)也會被寫入到從集群的相同分區(qū)。