本文主要介紹如何使用JOIN和子查詢。JOIN是將多個(gè)表以某個(gè)或某些列為條件,進(jìn)行連接操作而檢索出關(guān)聯(lián)數(shù)據(jù)的過程,多個(gè)表之間以共同列而關(guān)聯(lián)在一起。子查詢是指在父查詢的WHERE子句或HAVING子句中嵌套另一個(gè)SELECT語句的查詢。
基本概念
JOIN是SQL查詢中常見的操作,邏輯上說,它的語義等價(jià)于將兩張表做笛卡爾積,然后根據(jù)過濾條件保留滿足條件的數(shù)據(jù)。多數(shù)情況下是依賴等值條件做JOIN,即Equi-Join,用來根據(jù)某個(gè)特定列的值連接兩張表的數(shù)據(jù)。
子查詢是指嵌套在SQL內(nèi)部的查詢塊,子查詢的結(jié)果作為輸入,填入到外層查詢中,從而用于計(jì)算外層查詢的結(jié)果。子查詢可以出現(xiàn)在SQL語句的很多地方,例如在SELECT子句中作為輸出的數(shù)據(jù),在FROM子句中作為輸入的一個(gè)視圖,在WHERE子句中作為過濾條件等。
本文討論的均為不下推,在計(jì)算層執(zhí)行的JOIN算子。如果JOIN被下推到LogicalView中,其執(zhí)行方式由存儲(chǔ)層MySQL自行選擇。
JOIN類型
PolarDB-X 1.0支持Inner Join,Left Outer Join和Right Outer Join這3種常見的JOIN類型。
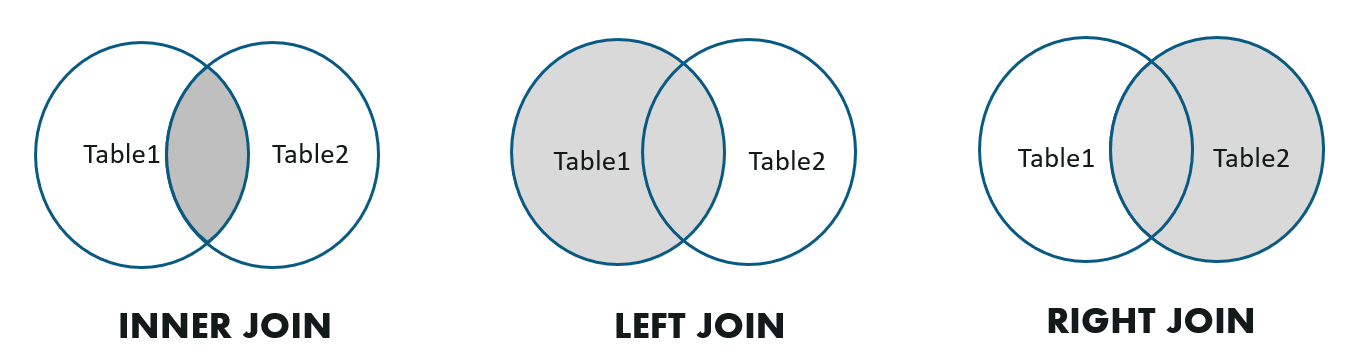
下面是幾種不同類型JOIN的例子:
/* Inner Join */
SELECT * FROM A, B WHERE A.key = B.key;
/* Left Outer Join */
SELECT * FROM A LEFT JOIN B ON A.key = B.key;
/* Right Outer Join */
SELECT * FROM A RIGHT OUTER JOIN B ON A.key = B.key;此外,PolarDB-X 1.0還支持Semi-Join和Anti-Join。Semi Join和Anti Join無法直接用SQL語句來表示,通常由包含關(guān)聯(lián)項(xiàng)的EXISTS或IN子查詢轉(zhuǎn)換得到。
下面是幾個(gè)Semi-Join和Anti-Join的例子:
/* Semi Join - 1 */
SELECT * FROM Emp WHERE Emp.DeptName IN (
SELECT DeptName FROM Dept
)
/* Semi Join - 2 */
SELECT * FROM Emp WHERE EXISTS (
SELECT * FROM Dept WHERE Emp.DeptName = Dept.DeptName
)
/* Anti Join - 1 */
SELECT * FROM Emp WHERE Emp.DeptName NOT IN (
SELECT DeptName FROM Dept
)
/* Anti Join - 2 */
SELECT * FROM Emp WHERE NOT EXISTS (
SELECT * FROM Dept WHERE Emp.DeptName = Dept.DeptName
)JOIN算法
目前,PolarDB-X 1.0支持Nested-Loop Join、Hash Join、Sort-Merge Join和Lookup Join(BKAJoin)等JOIN算法。
Nested-Loop Join (NLJoin)Nested-Loop Join通常用于非等值的JOIN。它的工作方式如下:
- 拉取內(nèi)表(右表,通常是數(shù)據(jù)量較小的一邊)的全部數(shù)據(jù),緩存到內(nèi)存中。
- 遍歷外表數(shù)據(jù),針對(duì)外表中的每一行數(shù)據(jù),和內(nèi)表做比較,構(gòu)造結(jié)果行,檢查是否滿足JOIN條件,如果滿足條件則輸出。
如下是一個(gè)Nested-Loop Join的例子:
> EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey < s_suppkey;
NlJoin(condition="ps_suppkey < s_suppkey", type="inner")
Gather(concurrent=true)
LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp`")
Gather(concurrent=true)
LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier`")通常來說,Nested-Loop Join是效率最低的JOIN操作,一般只有在JOIN條件不含等值(例如上面的例子)或者內(nèi)表數(shù)據(jù)量極小的情況下才會(huì)使用。
通過如下Hint可以強(qiáng)制PolarDB-X 1.0使用Nested-Loop Join以及確定JOIN順序:
/*+TDDL:NL_JOIN(outer_table, inner_table)*/ SELECT ...其中inner_table和outer_table也可以是多張表的JOIN結(jié)果,例如:
/*+TDDL:NL_JOIN((outer_table_a, outer_table_b), (inner_table_c, inner_table_d))*/ SELECT ...下面其他的Hint也一樣。
Hash JoinHash Join是等值JOIN最常用的算法之一。它的原理如下所示:
- 拉取內(nèi)表(右表,通常是數(shù)據(jù)量較小的一邊)的全部數(shù)據(jù),寫進(jìn)內(nèi)存中的哈希表。
- 遍歷外表數(shù)據(jù),對(duì)于外表的每行:
- 根據(jù)等值條件JOIN Key查詢哈希表,取出0-N匹配的行(JOIN Key相同)。
- 構(gòu)造結(jié)果行,并檢查是否滿足JOIN條件,如果滿足條件則輸出。
以下是一個(gè)Hash Join的例子:
EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey;
HashJoin(condition="ps_suppkey = s_suppkey", type="inner")
Gather(concurrent=true)
LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp`")
Gather(concurrent=true)
LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier`")Hash Join常出現(xiàn)在JOIN數(shù)據(jù)量較大的復(fù)雜查詢、且無法通過索引Lookup來改善,這種情況下Hash Join是最優(yōu)的選擇。例如上面的例子中,partsupp表和supplier表均為全表掃描,數(shù)據(jù)量較大,適合使用HashJoin。
由于Hash Join的內(nèi)表需要用于構(gòu)造內(nèi)存中的哈希表,內(nèi)表的數(shù)據(jù)量一般小于外表。通常優(yōu)化器可以自動(dòng)選擇出最優(yōu)的JOIN順序。如果需要手動(dòng)控制,通過如下Hint可以強(qiáng)制PolarDB-X 1.0使用Hash Join以及確定JOIN順序:
/*+TDDL:HASH_JOIN(table_outer, table_inner)*/ SELECT ...Lookup Join是另一種常用的等值JOIN算法,常用于數(shù)據(jù)量較小的情況。它的原理如下:
- 遍歷外表(左表,通常是數(shù)據(jù)量較小的一邊)數(shù)據(jù)。
- 對(duì)于外表中的每批(例如1000行)數(shù)據(jù),將這一批數(shù)據(jù)的JOIN Key拼成一個(gè)
IN (....)條件,加到內(nèi)表的查詢中。 - 執(zhí)行內(nèi)表查詢,得到JOIN匹配的行。
- 借助哈希表,為外表的每行找到匹配的內(nèi)表行,組合并輸出。
以下是一個(gè)Lookup Join (BKAJoin)的例子:
EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey AND ps_partkey = 123;
BKAJoin(condition="ps_suppkey = s_suppkey", type="inner")
LogicalView(tables="partsupp_3", sql="SELECT * FROM `partsupp` AS `partsupp` WHERE (`ps_partkey` = ?)")
Gather(concurrent=true)
LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier` WHERE (`s_suppkey` IN ('?'))")Lookup Join通常用于外表數(shù)據(jù)量較小的情況,例如上面的例子中,左表partsupp由于存在ps_partkey = 123的過濾條件,僅有幾行數(shù)據(jù)。此外,右表的s_suppkey IN ( ... )查詢命中了主鍵索引,這也使得Lookup Join的查詢代價(jià)進(jìn)一步降低。
通過如下Hint可以強(qiáng)制PolarDB-X 1.0使用LookupJoin以及確定JOIN順序:
/*+TDDL:BKA_JOIN(table_outer, table_inner)*/ SELECT ...Sort-Merge Join是另一種等值JOIN算法,它依賴左右兩邊輸入的順序,必須按JOIN Key排序。它的原理如下:
以下是一個(gè)Sort-Merge Join的例子:
EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey ORDER BY s_suppkey;
SortMergeJoin(condition="ps_suppkey = s_suppkey", type="inner")
MergeSort(sort="ps_suppkey ASC")
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp` ORDER BY `ps_suppkey`")
MergeSort(sort="s_suppkey ASC")
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier` ORDER BY `s_suppkey`")注意上面執(zhí)行計(jì)劃中的 MergeSort算子以及下推的ORDER BY,這保證了Sort-Merge Join兩邊的輸入按JOIN Key即s_suppkey (ps_suppkey)排序。
Sort-Merge Join由于需要額外的排序步驟,通常Sort-Merge Join并不是最優(yōu)的。但是,某些情況下客戶端查詢恰好也需要按JOIN Key排序(上面的例子),這時(shí)候使用Sort-Merge Join是較優(yōu)的選擇。
通過如下Hint可以強(qiáng)制PolarDB-X 1.0使用Sort-Merge Join:
/*+TDDL:SORT_MERGE_JOIN(table_a, table_b)*/ SELECT ...JOIN順序
在多表連接的場(chǎng)景中,優(yōu)化器的一個(gè)很重要的任務(wù)是決定各個(gè)表之間的連接順序,因?yàn)椴煌倪B接順序會(huì)影響中間結(jié)果集的大小,進(jìn)而影響到計(jì)劃整體的執(zhí)行代價(jià)。
例如,對(duì)于4張表JOIN(暫不考慮下推的情形),JOIN Tree可以有如下3種形式,同時(shí)表的排列又有4! = 24種,一共有72種可能的JOIN順序。
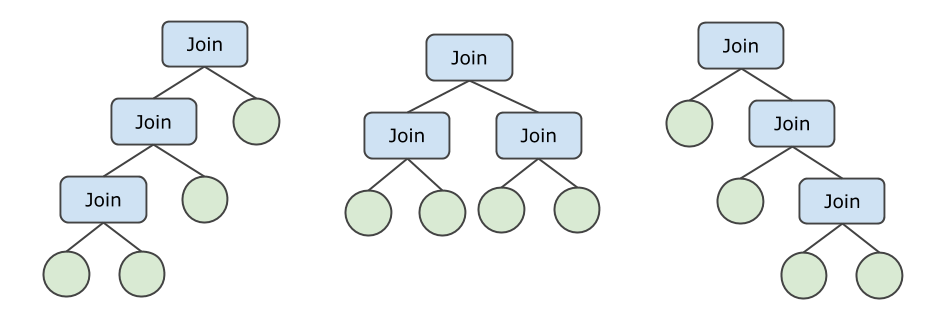
給定N個(gè)表的JOIN,PolarDB-X 1.0采用自適應(yīng)的策略生成最佳JOIN計(jì)劃:
- 當(dāng)(未下推的)N較小時(shí),采取Bushy枚舉策略,會(huì)在所有JOIN順序中選出最優(yōu)的計(jì)劃。
- 當(dāng)(未下推的)表的數(shù)量較多時(shí),采取Zig-Zag(鋸齒狀)或Left-Deep(左深樹)的枚舉策略,選出最優(yōu)的Zig-Zag或Left-Deep執(zhí)行計(jì)劃,以減少枚舉的次數(shù)和代價(jià)。
PolarDB-X 1.0使用基于代價(jià)的優(yōu)化器(Cost-based Optimizer,CBO)選擇出總代價(jià)最低的JOIN 順序。詳情參見查詢優(yōu)化器介紹。
此外,各個(gè)JOIN算法對(duì)左右輸入也有不同的偏好,例如,Hash Join中右表作為內(nèi)表用于構(gòu)建哈希表,因此應(yīng)當(dāng)將較小的表置于右側(cè)。這些也同樣會(huì)在CBO中被考慮到。
子查詢
根據(jù)是否存在關(guān)聯(lián)項(xiàng),子查詢可以分為非關(guān)聯(lián)子查詢和關(guān)聯(lián)子查詢。非關(guān)聯(lián)子查詢是指該子查詢的執(zhí)行不依賴外部查詢的變量,這種子查詢一般只需要計(jì)算一次;而關(guān)聯(lián)子查詢中存在引用自外層查詢的變量,邏輯上,這種子查詢需要每次帶入相應(yīng)的變量、計(jì)算多次。
/* 例子:非關(guān)聯(lián)子查詢 */
SELECT * FROM lineitem WHERE l_partkey IN (SELECT p_partkey FROM part);
/* 例子:關(guān)聯(lián)子查詢(l_suppkey 是關(guān)聯(lián)項(xiàng)) */
SELECT * FROM lineitem WHERE l_partkey IN (SELECT ps_partkey FROM partsupp WHERE ps_suppkey = l_suppkey);PolarDB-X 1.0子查詢支持絕大多數(shù)的子查詢寫法,具體參見SQL使用限制。
對(duì)于多數(shù)常見的子查詢形式,PolarDB-X 1.0可以將其改寫為高效的SemiJoin或類似的基于JOIN的計(jì)算方式。這樣做的好處是顯而易見的。當(dāng)數(shù)據(jù)量較大時(shí),無需真正帶入不同參數(shù)循環(huán)迭代,大大降低了執(zhí)行代價(jià)。這種查詢改寫技術(shù)稱為子查詢的去關(guān)聯(lián)化(Unnesting)。
下面是一個(gè)子查詢?nèi)リP(guān)聯(lián)化的例子,可以看到執(zhí)行計(jì)劃中使用JOIN代替了子查詢。
EXPLAIN SELECT p_partkey, (
SELECT COUNT(ps_partkey) FROM partsupp WHERE ps_suppkey = p_partkey
) supplier_count FROM part;
Project(p_partkey="p_partkey", supplier_count="CASE(IS NULL($10), 0, $9)", cor=[$cor0])
HashJoin(condition="p_partkey = ps_suppkey", type="left")
Gather(concurrent=true)
LogicalView(tables="part_[0-7]", shardCount=8, sql="SELECT * FROM `part` AS `part`")
Project(count(ps_partkey)="count(ps_partkey)", ps_suppkey="ps_suppkey", count(ps_partkey)2="count(ps_partkey)")
HashAgg(group="ps_suppkey", count(ps_partkey)="SUM(count(ps_partkey))")
Gather(concurrent=true)
LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT `ps_suppkey`, COUNT(`ps_partkey`) AS `count(ps_partkey)` FROM `partsupp` AS `partsupp` GROUP BY `ps_suppkey`")某些少見情形下,PolarDB-X 1.0無法將子查詢進(jìn)行去關(guān)聯(lián)化,這時(shí)候會(huì)采用迭代執(zhí)行的方式。如果外層查詢數(shù)據(jù)量很大,迭代執(zhí)行可能會(huì)非常慢。
下面這個(gè)例子中,由于OR l_partkey < 50的存在,導(dǎo)致子查詢無法被去關(guān)聯(lián)化,因而采用了迭代執(zhí)行:
EXPLAIN SELECT * FROM lineitem WHERE l_partkey IN (SELECT ps_partkey FROM partsupp WHERE ps_suppkey = l_suppkey) OR l_partkey IS NOT
Filter(condition="IS(in,[$1])[29612489] OR l_partkey < ?0")
Gather(concurrent=true)
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.lineitem_[0-7]", shardCount=8, sql="SELECT * FROM `lineitem` AS `lineitem`")
>> individual correlate subquery : 29612489
Gather(concurrent=true)
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.partsupp_[0-7]", shardCount=8, sql="SELECT * FROM (SELECT `ps_partkey` FROM `partsupp` AS `partsupp` WHERE (`ps_suppkey` = `l_suppkey`)) AS `t0` WHERE (((`l_partkey` = `ps_partkey`) OR (`l_partkey` IS NULL)) OR (`ps_partkey` IS NULL))")這種情形下,建議改寫SQL去掉子查詢的OR條件。