本文介紹存儲資源池的設計思路與使用方法。
版本限制
實例內核版本需在5.4.18-17066805以上。
邏輯庫的分區類型需為Auto模式。
如何查看實例版本,請參見查看實例版本。
背景介紹
在平臺類應用和系統(如電商CRM平臺、倉庫訂單平臺等)中通常需要服務多個用戶,服務模型往往是圍繞用戶維度(用戶維度可以是一個賣家或品牌,可以是一個倉庫)展開的,為了支持業務系統的水平擴展性,業務數據庫通常是按用戶維度進行水平切分。
隨著業務不斷演進,平臺中的部分用戶往往會有隨著服務請求量增多成為熱點用戶,或者要求單獨服務質量作為VIP用戶。除平臺業務應用層需要對此類需求進行適配外,業務數據庫也需要提供相應的能力,確保來自不同租戶的數據存儲和計算做到服務分級和資源隔離。
就業務系統對數據庫的切分方式而言,常見的租戶方案有兩種:
Schema級多租戶。多個租戶對應的數據分布在不同的數據庫上,不同租戶需要獨立Schema運行。
Partition級多租戶。多個租戶對應的數據分布在同一張邏輯表的不同分區上,不同的租戶需要共享Schema。
|
|

從隔離程度來看, Schema 級多租戶比 Partition 級多租戶要隔離得更徹底,但前者因為要維護眾多的Schema,會比后者會帶來更高的運維成本及查詢分析成本。Partition 級多租戶通常要依賴中間件分庫分表或分布式數據庫分區功能(否則單機數據庫無法做到資源隔離)才能運作,而Schema 級 SaaS 多租戶則不需要,用戶可基于幾個單機RDS實例搭建應用,準入門檻更低。
傳統的多租戶解決方案存在以下問題:
跨機分布式事務問題:絕大部分分布式中間件無法提供強一致的分布式事務能力,業務需要進行額外的應用改造。
數據運維問題:基于中間件的方案,無論是Schema級還是Partition級租戶,用戶均須自行處理數據運維問題,如加減列或者索引、增刪表等。
租戶資源變更管理問題:當多個租戶的資源級別定義發生變動時,如平臺需要給某一租戶分配單獨資源時,數據遷移必須依賴外部同步工具構建同步鏈路,帶來昂貴的運維成本。
PolarDB具備完善的分區定義、分區變更等等分區管理能力以及分布式事務、分布式DDL能力。基于以上基礎能力,PolarDB在內核集成了原生的存儲池功能,提供了面向SaaS用戶的資源劃分、資源重組、數據庫對象(數據庫級與分區級)資源綁定、數據庫對象資源重定義能力,可有效解決多租戶平臺應用在跨機分布式事務、數據運維、租戶資源管理等等方面的問題。
基本設計
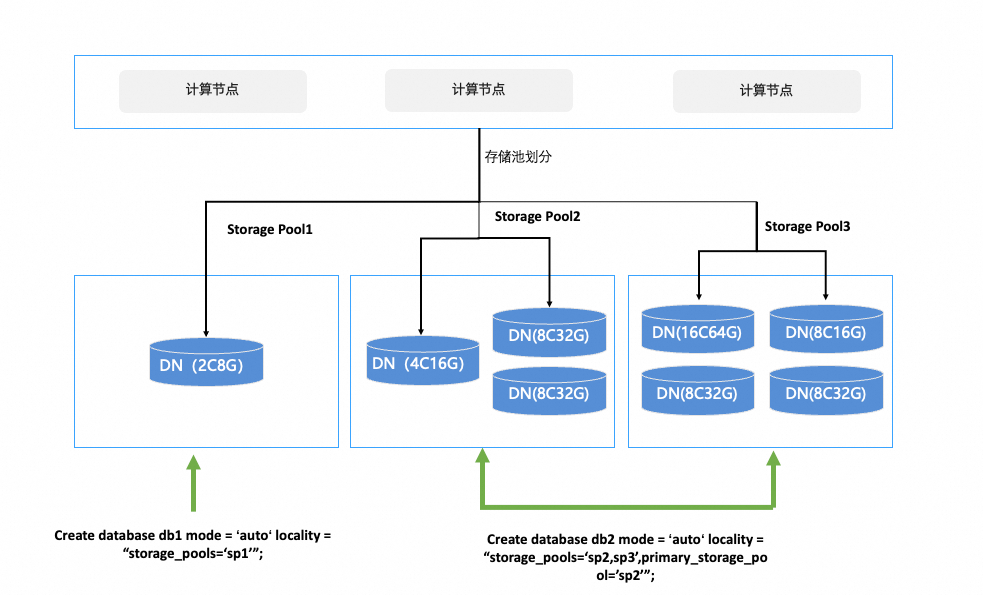
存儲資源池將存儲節點劃分為若干資源池,數據庫中的對象(數據庫、表、分區)通過關聯到不同的資源池隔離存儲資源:
對存儲資源提供全局完整的劃分,并基于已有的劃分方式提供完整的數據庫對象綁定語義。
在實例變更過程中遵守自定義的劃分方式,提供合理的變更和負載均衡功能。
用戶可以根據PolarDB分布式存儲節點(以下簡稱DN節點)的規格、可用區、機房位置等性質對存儲節點進行人工分組,并將數據庫對象綁定到不同的資源池中,從而實現為多租戶提供服務隔離的目標。
存儲資源池具備以下功能:
支持將實例中的存儲節點劃分為若干互不相交的資源池。
支持在定義數據庫對象時指定資源池屬性:允許定義數據庫對象時指定資源池,在選擇目標拓撲時必須滿足用戶指定的資源池。
支持變更數據庫對象的資源池屬性:允許變更表組和分區組的資源池屬性,并自動觸發分區遷移操作。
支持變更資源池具備的存儲節點集合:允許變更存儲資源池關聯的節點集合,并自動觸發分區遷移操作。
語義與接口
定義存儲資源池
通過information_schema.storage_pool_info視圖可以查看存儲池的定義。
系統中默認具有兩個基本存儲池:_default和_recycle存儲池,前者包含當前的所有節點,后者包含有存儲池中刪除但仍屬于本實例的節點。
mysql > select * from information_schema.storage_pool_info;
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+
| ID | NAME | DN_ID_LIST | IDLE_DN_ID_LIST | UNDELETABLE_DN_ID | EXTRAS | GMT_CREATED | GMT_MODIFIED |
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+
| 1 | _default | dn0,dn1,dn2,dn3,dn4,dn5,dn6,dn7,dn8,dn9 | | dn0 | NULL | 2024-04-15 19:46:05 | 2024-04-15 19:46:05 |
| 2 | _recycle | | | | NULL | 2024-04-15 19:46:05 | 2024-04-15 19:46:05 |
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+對_default存儲池縮容后,可將dn節點放入_recycle存儲池中(數據遷移是異步的):
mysql > alter storage pool _default drain node 'dn1,dn2,dn3,dn4,dn5,dn6,dn7,dn8,dn9';
Query OK, 0 rows affected (1.52 sec)
mysql > select * from information_schema.storage_pool_info;
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+
| ID | NAME | DN_ID_LIST | IDLE_DN_ID_LIST | UNDELETABLE_DN_ID | EXTRAS | GMT_CREATED | GMT_MODIFIED |
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+
| 1 | _default | dn0, | | dn0 | NULL | 2024-04-15 19:46:05 | 2024-04-15 19:46:05 |
| 2 | _recycle | dn1,dn2,dn3,dn4,dn5,dn6,dn7,dn8,dn9 | | | NULL | 2024-04-15 19:46:05 | 2024-04-15 19:46:05 |
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+用戶可自定義存儲資源池,要求:
每一個存儲資源池至少包含一個DN,且有一個DN作為undeletable DN不允許被縮容。
在定義存儲資源池時要求指定的DN上必須不包含任何數據庫對象。
不同資源池的DN之間必須互不交叉。
同一個存儲資源池內允許包含不同規格的DN節點。
create storage pool pool1 dn_list = "dn1,dn2,dn3" undeletable_dn="dn1";
create storage pool pool2 dn_list = "dn4,dn5,dn6" undeletable_dn="dn5";
create storage pool pool3 dn_list = "dn7,dn8,dn9" undeletable_dn="dn7";對于數據庫和表,允許指定多個存儲資源池(storage_pools),并單獨指定一個默認存儲資源池列表(primary_storage_pool),一個完整的存儲池綁定聲明如下:
LOCALITY = 'storage_pools=pool1,pool2,...;primary_storage_pool=pool1'數據庫(表)中的表(分區)默認只使用默認資源池,但是數據庫中的廣播表將會建立在所有DN上。僅當用戶手工指定下一級對象的存儲資源池為非默認資源池時,數據庫對象才會分布在非默認資源池上。
表(分區)的存儲資源池,必須從屬于上一級對象,即數據庫(表)所具備的存儲資源池(storage_pools)。
create database d1 locality = "storage_pools=pool1";
use d1;
-- valid operation!
create table t1(a int) single locality = "storage_pools=pool1";
-- invalid operation, because t2 locality storage_pools not in d1 storage_pools
create table t2(a int) single locality = "storage_pools=pool3";
create database d2 locality = "storage_pools=pool1,pool2,pool3;primary_storage_pool=pool1,pool2";
use d2;
-- valid operation!
create table t1(a int) locality = "storage_pools=pool1";
create table t2(a int) locality = "storage_pools=pool3";
create table t3(a int) locality = "storage_pools=pool2";
create table t4(a int) locality = "storage_pools=pool2";
-- all the logical table locate on storage pool pool1,pool2 defaultly;
-- while broadcast table locate on all the storage pool變更存儲資源池
對于已有的存儲資源池,支持刪除其節點,刪除節點的存儲池變更為_recycle存儲池,但undeletable DN無法被刪除。
對于已有的存儲資源池,支持增加其節點,要求增加的節點必須不包含已有的。
-- valid operation
alter storage pool pool1 remove node "dn3";
-- invalid operation, because dn1 is the undeletable storage pool for pool1.
alter storage pool pool1 remove node "dn1";
-- valid operation, because dn4 is in _recycle storage pool
-- and no physical db locate on dn4.
alter storage pool pool2 append node "dn3";
-- invalid operation, because dn3 is hold by pool1.
alter storage pool pool2 append node "dn2";對存儲池的變更將會觸發數據自動遷移到合法定義的節點上,可在select * from information_schema.ddl_plan中查看對應的遷移計劃。
變更數據庫對象關聯的存儲資源池
對于數據庫、表或者分區,允許直接變更存儲資源池。
如果對對象關聯的存儲資源池進行追加,除擴增廣播表的節點范圍外,不作任何操作。
如果對對象關聯的存儲資源池進行刪減,則消除該對象及子對象在被刪除資源池上全部對象的存儲資源池定義,并將其遷移。
如果對對象關聯的存儲資源池完全清除,等同于該對象關聯的資源池變更為默認資源池。
alter database d1 set locality = "storage_pools=sp1;primary_storage_pool=sp1";
alter database d2 set locality = "storage_pools=sp1,sp2;primary_storage_pool=sp1"
use d1;
alter table t1 single locality = "storage_pools=sp1";場景示例
場景一:庫級租戶
以一個電商平臺(以下簡稱X公司)為例,其系統需要維護多個賣家的訂單,其中包含有若干流水顯著較高的大賣家和大部分小賣家,X公司對于大小賣家的資源劃分要求如下:
大賣家需要使用單獨的存儲資源存儲數據,確保在線流量穩定,同時需要提供單獨的跑批數據分析能力。
小賣家需要共享一組存儲資源,并且小賣家占用的資源需要盡可能在該組資源中保持均衡。
部分小賣家隨著時間演進可能演變為大賣家,部分大賣家可能遷移到其他平臺或者從其他平臺遷入。
租戶定義
X公司的需求可以通過庫級資源隔離實現,然后按大賣家的需求,將已有的存儲節點劃分為若干存儲池,對于小賣家的共享庫,可直接建在默認存儲池之上:
CREATE STORAGE POOL sp1 dn_list="dn4,dn5,dn6" undeletable_dn="dn4";
CREATE STORAGE POOL sp2 dn_list="dn7,dn8,dn9" undeletable_dn="dn7";
CREATE DATABASE orders_comm MODE = "auto"
LOCALITY= "storage_pools='_default'"; /* 小賣家共享_default存儲池(dn1, dn2, dn3 */
CREATE DATABASE orders_seller1 MODE = "auto"
LOCALITY= "storage_pools='sp1'"; /* 大賣家1使用sp1存儲池(dn4, dn5, dn6) */
CREATE DATABASE orders_seller2 MODE = "auto"
LOCALITY= "storage_pools='sp2'"; /* 大賣家2使用sp2存儲池(dn7, dn8, dn9) */
...通過上述建庫語句,應用可獲得以下效果:
大賣家之間、大賣家與小賣家之間各自使用單獨存儲資源存儲,存儲資源完全隔離。
小賣家之間共享默認存儲池的資源dn1~dn3。
大小賣家之間的建表語句可以完全獨立,可以自行決定每個賣家的表結構定義以及存儲資源。
資源均衡
小賣家的庫內部可以使用Locality的單表打散模式全部建成單表,也可以建成分區表。當小賣家之間也存在數據分布的差異,需要在小賣家內部均衡資源分配時,只需直接調用存儲池級別的資源均衡語句。
REBALANCE TENANT "_default" POLICY="data_balance";REBALANCE將會自動按照存儲池內的對象屬性定義均衡相應的單表和分區分布,與實例級別的擴縮容一樣,該操作將自動滿足資源約束,并且盡可能均衡所有單表和所有分區在dn1~dn3上的分布。
租戶遷入及遷出
當平臺遷入新的大賣家時,可在實例中加入新的存儲節點(默認加入到_recycle存儲池),然后使用該節點單獨建立存儲池,并新建大賣家相關的庫使之獨占新的存儲池。
CREATE STORAGE POOL spn dn_list = "dn10,dn11,dn12" undeletable_dn="dn10";
/* 新定義存儲池spn (dn10, dn11, dn12) */
CREATE DATABASE orders_sellern MODE = "auto"
LOCALITY="storage_pools='spn'";
/* 大賣家N使用spn存儲池 */如果大賣家遷出,可刪除相應庫并且釋放相應資源。
DROP DATABASE orders_sellern;
DELETE STORAGE POOL spn;/* 刪除存儲池,相應的節點將會自動進入_recycle存儲池 */
ALTER STORAGE POOL _recycle DRAIN NODE "dn7, dn8, dn9"; /* 在集群中釋放相應的節點 */在新增以及刪除上述存儲池和庫時,已有的業務不會受到影響,對應用幾乎是透明無感的。
場景二:分區級租戶
對于場景一中X公司的需求,也可以通過分區級資源隔離實現,相比于庫級租戶,分區級租戶可以提供完全一致的資源隔離能力,并且具備更多優勢:
所有分區共享邏輯表的定義,加減列、加減索引等數據運維操作以及廣播表的下推關系均由數據庫自動維護。
通過分區分裂、分區合并等已有的分區管理能力,可以獲得更加靈活的資源變更能力,如將部分租戶升級到VIP服務、合并部分租戶的資源等等。
租戶定義
首先將存儲節點劃分為相應的存儲池,然后使用全部存儲池建立一個公共庫。
CREATE DATABASE orders_db MODE = "auto"
LOCALITY = "storage_pools='_default,sp1,sp2,...',primary_storage_pool='_default'"
USE orders_db;
CREATE TABLE commodity(
commodity_id int,
commodity_name varchar(64)
) BROADCAST;
/*commodity作為一張廣播表,將會在所有的存儲池上建立分表,因此可與orders_sellers的任何一個分區進行join下推。*/
CREATE TABLE orders_sellers(
order_id int AUTO_INCREMENT primary key,
customer_id int,
commodity_id int,
country varchar(64),
seller_id int,
order_time datetime not null)
partition BY list(seller_id)
(
partition p1 VALUES IN (1, 2, 3, 4),
partition p2 VALUES IN (5, 6, 7, 8),
/*orders_seller的分區p1, p2默認會使用_default存儲池中的節點進行存儲,共享_default存儲池中的資源。*/
...
partition pn VALUES IN (k) LOCALITY = "storage_pools='sp1'",
partition pn+1 VALUES IN (k+1, k+2) LOCALITY = "storage_pools='sp2'",
/*orders_seller的分區pn, pn+1會分別使用sp1, sp2存儲池中的節點進行存儲,分別獨自占用相應存儲節點的資源。*/
...
) LOCALITY = "storage_pools='_default,sp1,sp2,...'";庫的定義中包含了全部存儲池,但是同時定義了primary_storage_pool為_default存儲池,因而orders_sellers中的分區默認會使用_default存儲池作為存儲節點列表,而廣播表會自動分布在所有存儲池節點上。
不同分區的定義包含不同的租戶集合,并且可以自行指定分區的存儲資源。
租戶遷入和遷出
對于新增的小租戶,可以直接添加分區,默認不遷移數據,只產生新分區。
ALTER TABLE orders_sellers ADD PARTITION
(PARTITION p3 values in (32, 33));對于新增的大租戶,可向已有的存儲節點中添加節點,并且加入到分區路由直接添加分區,同時指定其占用的存儲池。
CREATE STORAGE POOL spn dn_list = "dn10,dn11,dn12" undeletable_dn="dn10";
/*向實例中新增了一個存儲池spn.*/
ALTER DATABASE orders_db SET LOCALITY =
"storage_pools='_default,sp1,sp2,...,spn',primary_storage_pool='_default'"
/*向orders_db的存儲池列表中添加spn, 這一修改將會自動觸發廣播表遷移到新的存儲池節點之上。*/
ALTER TABLE orders_sellers ADD PARTITION
(PARTITION p4 values in (34) LOCALITY="storage_pools='spn');
/*在orders_sellers中新增一個租戶分區,并且該分區分布在自定義的存儲池spn上。*/同樣,對于租戶遷出,可直接刪除相應分區并釋放存儲池資源。
ALTER TABLE orders_sellers DROP PARTITION p4;或者變更相應的分區定義,在分區內部刪除小賣家。
ALTER TABLE orders_sellers MODIFY PARTITION p1 DROP VALUES (4, 5);對分區級租戶而言,所有分區共享邏輯表的定義,因而數據模式變更可由數據庫統一維護。上述分區變更語句均為online操作,僅影響實際操作涉及的分區,對其他分區的已有業務均無影響。
租戶服務級別變更
當小賣家的服務級別需要升級為VIP級別時,可修改分區定義,將其單獨分配到一個存儲池上:
ALTER TABLE orders_sellers SPLIT PARTITION p2 INTO
(PARTITION p2 VALUES in (6, 7, 8) ,
PARTITION `pn+2` VALUES in (5) LOCALITY = "storage_pools='spn+3'");同樣,可以根據對大賣家的服務級別進行降級。
ALTER TABLE orders_sellers MERGE PARTITION p1, pn TO p1 LOCALITY="";上述操作的效果將直接合并p1和pn分區的數據,并且新分區仍然存儲于默認存儲池之上。
在保留庫級租戶資源隔離的能力的基礎上,分區級租戶通過完善的分區管理接口提供了更加靈活的租戶資源變更和控制能力。
資源均衡
當租戶間在分區級別出現負載不均時,同樣可以通過存儲池級別的REBALANCE操作在公共存儲池中進行負載均衡。
REBALANCE TENANT "_default" POLICY="data_balance";場景三:單機到分布式的遷移演進
以一個從單機關系型數據庫到分布式數據庫的遷移過程為例,在遷移初期,用戶希望盡可能復用原有的使用模式,在享有分布式數據庫scale out能力的同時,盡可能做到無痛改造;隨著業務逐步發展,以表為單位逐步推動部分業務負載較大的單表進一步演進到分布式表,同時確保盡可能不影響已有業務的庫表模型和資源占用。
通過存儲池定義不同表的存儲資源,即可實現單表與分布式表共存的集中分布式一體化使用模式,幫助用戶平滑演進到分布式數據庫。
建庫建表
除少數具有廣播表語義的表外,用戶可使用單表打散模式在PolarDB-X中復用原有的單機建表語句,從而實現存量業務的一鍵遷移改造。
CREATE DATABASE orders_db MODE = "auto" DEFAULT_SINGLE=on
LOCALITY = "storage_pools='_default',primary_storage_pool='_default'";
use orders_db;
CREATE TABLE orders_region1(
order_id int AUTO_INCREMENT primary key,
customer_id int,
country varchar(64),
city int,
order_time datetime not null);
CREATE TABLE orders_region2(
order_id int AUTO_INCREMENT primary key,
customer_id int,
country varchar(64),
city int,
order_time datetime not null);
CREATE TABLE orders_region3(
order_id int AUTO_INCREMENT primary key,
customer_id int,
country varchar(64),
city int,
order_time datetime not null);
CREATE TABLE commodity(
commodity_id int,
commodity_name varchar(64)
) BROADCAST;上述建庫和建表語句實現了兩個效果:
所有應用單機建表語句的單表將會自動按照數據量和表的數量自動在_default存儲池中均衡。
廣播表將在_default存儲池的所有節點上建立分表。
隔離部分單表
部分單表承載的數據量和訪問量過大,可以在實例中添加新的存儲節點,并將負載過大的單表單獨隔離到新的節點上:
ALTER DATABASE orders_db set LOCALITY = "storage_pools='_default,sp1',primary_storage_pool='_default'";
/* 對數據庫的變更將會自動處理廣播表的分表擴張行為。 */
ALTER TABLE orders_region_single1 single LOCALITY = "storage_pools='sp1'";
/* 將業務負載較大的單表隔離到sp1存儲池的節點上。*/分布式改造
隨著業務演進,用戶可將超出單個物理表負載限制的表改造為分布式表,并且指定其所使用的存儲節點:
ALTER DATABASE orders_db set LOCALITY = "storage_pools='_default,sp1,sp2,sp3',primary_storage_pool='_default'";
ALTER TABLE orders_region_single2 partition by hash(order_id) partitions 16
LOCALITY = "storage_pools='sp2'";
/* orders_region_single2 使用存儲池sp2 */
ALTER TABLE orders_region_single3 partition by hash(order_id) partitions 16
LOCALITY = "storage_pools='sp3'";
/* orders_region_single3 使用存儲池sp3 */拆分變更允許用戶以online執行的方式自定義目標表的分區方式和存儲資源,從而做到表級別的業務模型改造,幫助用戶無痛實現從單表到分布式表的演進。
操作步驟
如何創建自定義存儲池并管理存儲池內的數據節點,請參見數據節點管理。