在相同業務場景下,架構設計和庫表索引設計會影響查詢性能,良好的設計可以提高查詢性能,反之會出現很多慢SQL(執行時間很長的SQL語句)。本文介紹導致慢SQL的原因和解決方案。
查看慢SQL
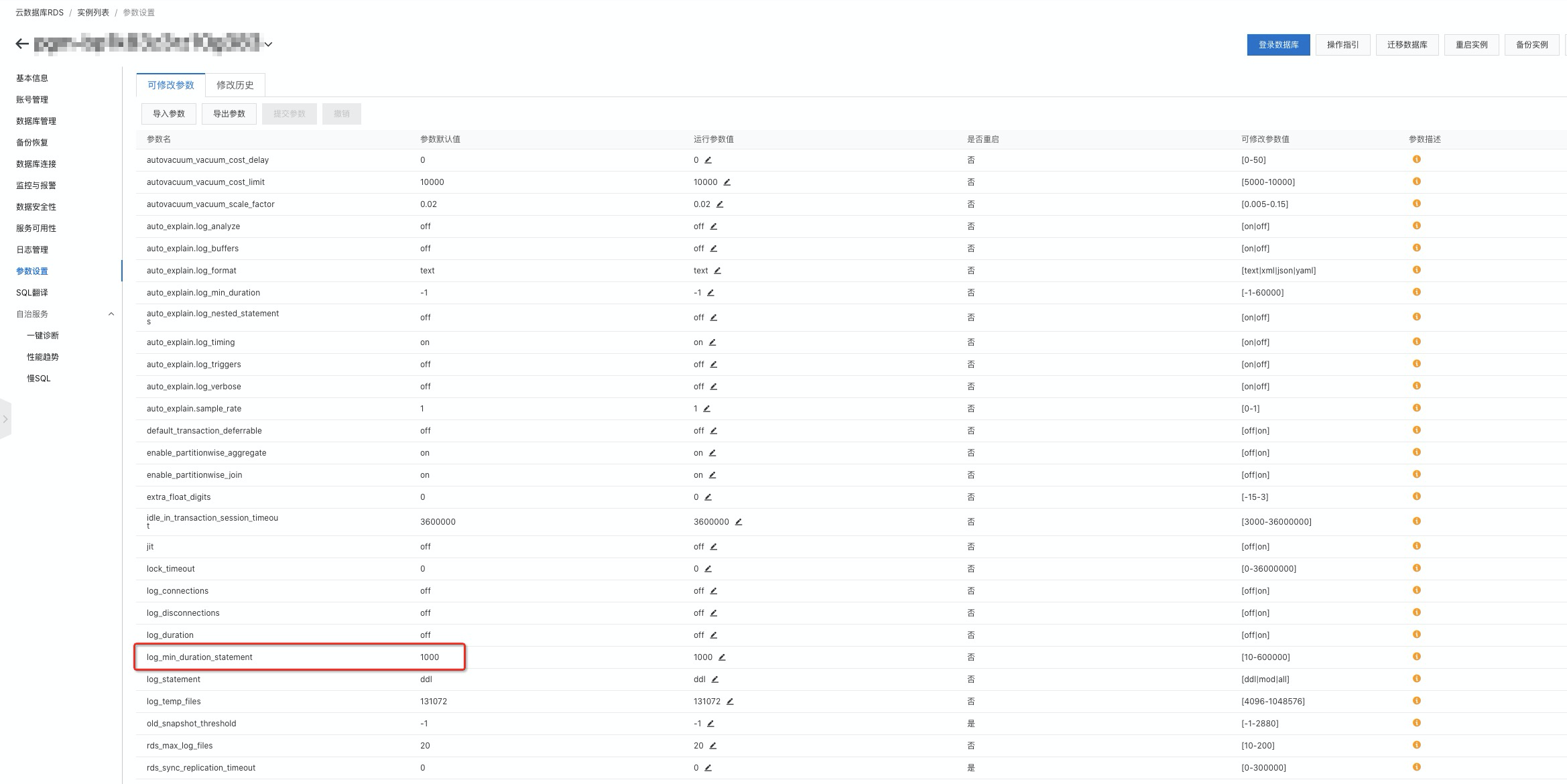
控制臺的參數設置中,可以找到名為log_min_duration_statement的參數,該參數的作用是設置慢日志判定的閾值,單位為ms。默認值為1000,即響應時間超過1秒的SQL會被記錄到慢SQL日志中。
 通過查看控制臺的日志管理中的慢日志明細頁簽,可以查看當前系統中存在的慢SQL。
通過查看控制臺的日志管理中的慢日志明細頁簽,可以查看當前系統中存在的慢SQL。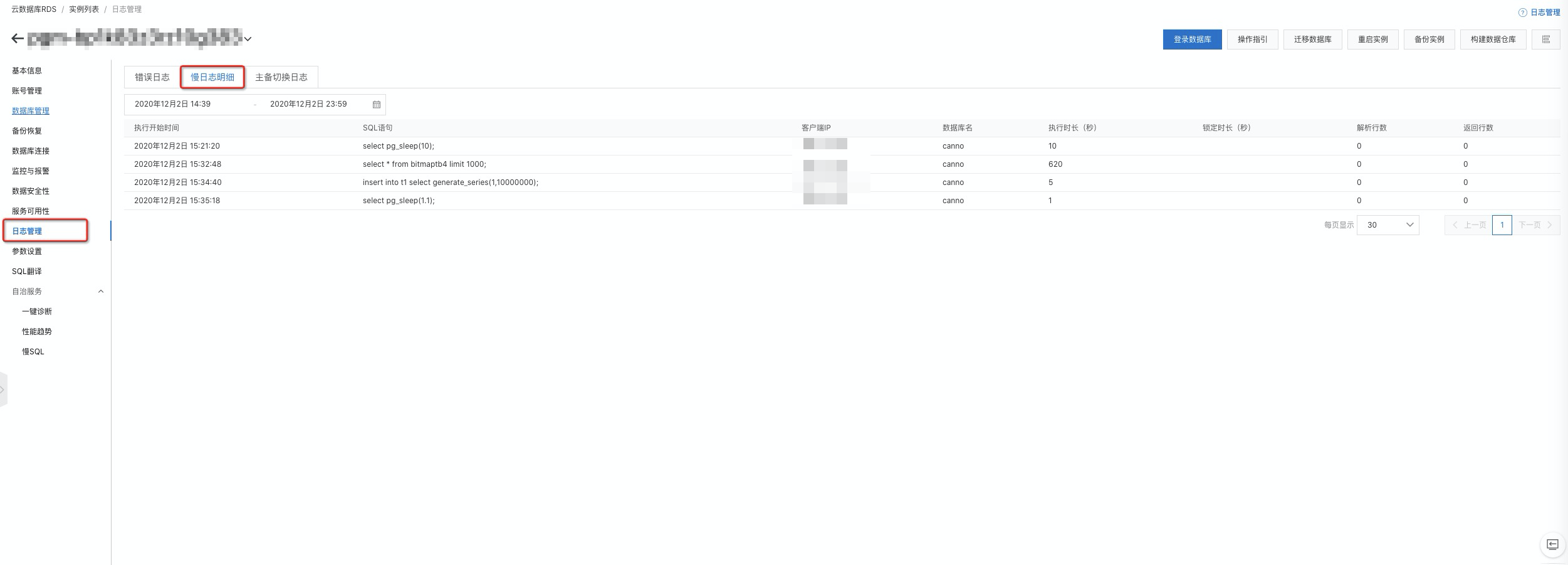 您只需在參數設置中開啟auto_explain.log_analyze、auto_explain.log_buffers、auto_explain.log_min_duration三個參數,即可在慢日志明細中查看慢SQL的執行計劃。
您只需在參數設置中開啟auto_explain.log_analyze、auto_explain.log_buffers、auto_explain.log_min_duration三個參數,即可在慢日志明細中查看慢SQL的執行計劃。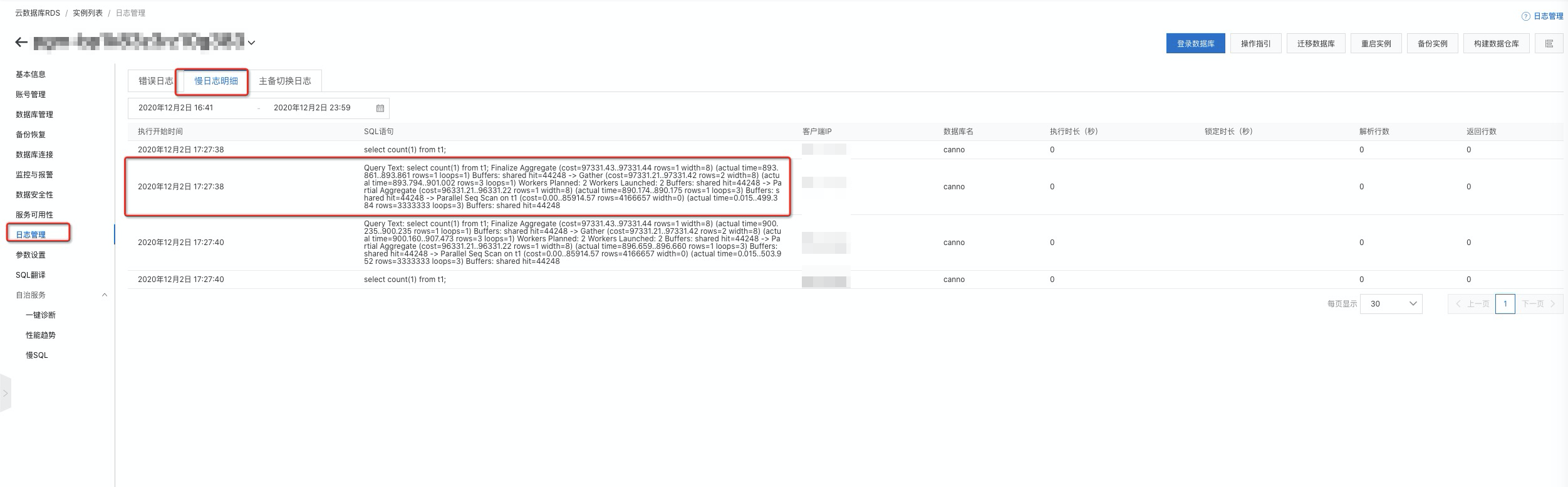
EXPLAIN命令
定位到慢SQL之后,可以通過EXPLAIN命令查詢該SQL的執行計劃,幫助您深入了解目標SQL的啟動代價。
EXPLAIN [ ( option [, ...] ) ] statement上面EXPLAIN命令中的option可選參數的說明如下:
ANALYZE [ boolean ]:執行SQL語句并返回實際運行時間。默認值:
FALSE。VERBOSE [ boolean ]:顯示關于計劃的額外信息。默認值:
FALSE。COST [ boolean ]:顯示執行計劃中每一個計劃節點的啟動時間、總執行代價、預估行數以及每行的寬度。默認值:
TRUE。BUFFERS [ boolean ]:緩沖區使用的信息。例如:共享塊命中、讀取、標記為臟和寫入的次數、本地塊命中、讀取、標記為臟和寫入的次數、臨時塊讀取和寫入的次數。默認值:
FALSE。TIMING [ boolean ]:顯示實際啟動時間以及在每個計劃節點中花費的時間。僅當ANALYZE為
TRUE時可用。默認值:TRUE。SUMMARY [ boolean ]:在查詢計劃后面包含摘要信息(例如共計花費多長時間)。當ANALYZE為
TRUE時自動開啟。默認值:FALSE。FORMAT { TEXT | XML | JSON | YAML }:指定輸出格式。默認值:
TEXT。
例如,執行EXPLAIN SELECT * from test;返回的結果如下:
QUERY PLAN
----------------------------------------------------
Seq Scan on test (cost=0.00..1.01 rows=1 width=4)
(1 row)上面的返回結果中,cost=0.00..1.01 rows=1 width=4為估算出的SQL預計執行代價,其中0.00為啟動SQL語句到返回第一行數據所需的啟動代價,1.01為返回所有行所需的總代價。
EXPLAIN (ANALYZE) DML-SQL 注意事項
EXPLAIN (ANALYZE) 語句的工作方式類似于EXPLAIN,主要區別在于EXPLAIN (ANALYZE) 語句實際會執行SQL。如果SQL涉及數據變更,即DML SQL(UPDATE、INSERT或DELETE),務必在事務中執行EXPLAIN (ANALYZE),查看完成后再進行回滾。
命令示例:
BEGIN;
EXPLAIN (ANALYZE) <DML(UPDATE/INSERT/DELETE) SQL>;
ROLLBACK;如何閱讀執行計劃
EXPLAIN命令的輸出可以看作是一個樹狀結構,即查詢計劃樹。樹的每一個節點包含節點類型、作用對象及其他屬性信息。其中節點類型分如下幾大類:
控制節點(Control Node)
掃描節點(ScanNode)
物化節點(Materialization Node)
連接節點(Join Node)
其中掃描節點又包含多種掃描方式,本文列舉常用的幾個進行詳細介紹:
Seq Scan:
順序掃描全表,一般用在查詢沒有索引的表,例如
explain(ANALYZE,VERBOSE,BUFFERS) select * from class where st_no=2;命令的返回結果如下:QUERY PLAN -------------------------------------------------------------------------------------------------- Seq Scan on public.class (cost=0.00..26.00 rows=1 width=35) (actual time=0.136..0.141 rows=1 loops=1) //Seq Scan on public.class表示這個節點的類型和作用對象,即在class表上進行全表掃描。 //(cost=0.00..26.00 rows=1 width=35)表示該節點的代價估計,0.00是節點啟動成本,26.00為該節點的代價,rows是該節點輸出行的估計值,width是該節點輸出行的平均寬度。 //(actual time=0.136..0.141 rows=1 loops=1) 表示該節點的真實執行信息,0.136表示該節點啟動時間,單位為ms。0.141表示該節點耗時,單位為ms。rows代表實際輸出行。loops代表節點循環次數。 Output: st_no, name //代表SQL輸出結果集的各個列,僅在EXPLAIN命令中的VERBOSE選項為on時才會顯示。 Filter: (class.st_no = 2) //表示Seq Scan節點中Filter操作,即全表掃描時對每行記錄進行過濾操作,過濾條件為class.st_no = 2。 Rows Removed by Filter: 1199 //表示過濾了多少行記錄,屬于Seq Scan節點的VERBOSE信息,僅在EXPLAIN命令中的VERBOSE選項為on時才會顯示。 Buffers: shared hit=11 //表示在共享緩存中命中了11個數據塊,屬于Seq Scan節點的BUFFERS信息,僅在EXPLAIN命令中的BUFFERS選項為on時才會顯示。 Planning time: 0.066 ms //表示生成查詢計劃的用時。 Execution time: 0.160 ms //表示實際的SQL執行用時,不包括生成查詢計劃的用時。Index Scan:
索引掃描,主要用在WHERE條件中存在索引列的情況,例如,假設
st_no列中存在索引,則explain(ANALYZE,VERBOSE,BUFFERS) select * from class where st_no=2;命令的返回結果如下:QUERY PLAN -------------------------------------------------------------------------------------------------- Index Scan using no_index on public.class (cost=0.28..8.29 rows=1 width=35) (actual time=0.022..0.023 rows=1 loops=1) //表示使用public.class表的no_index索引對表進行索引掃描。 Output: st_no, name Index Cond: (class.st_no = 2) //表示索引掃描的條件為class.st_no = 2。 Buffers: shared hit=3 Planning time: 0.119 ms Execution time: 0.060 ms (6 rows)從上述結果可以看出,使用索引之后,在相同條件下對同一張表的掃描速度變快了。需要掃描的數據塊少了之后,需要的代價變小了,速度也更快了。
Index Only Scan:
覆蓋索引掃描,僅返回指定的索引列,例如
explain(ANALYZE,VERBOSE,BUFFERS) select st_no from class where st_no=2;命令的返回結果如下:QUERY PLAN -------------------------------------------------------------------------------------------------- Index Only Scan using no_index on public.class (cost=0.28..4.29 rows=1 width=4) (actual time=0.015..0.016 rows=1 loops=1) //表示使用public.class表的no_index索引對表進行覆蓋索引掃描。 Output: st_no Index Cond: (class.st_no = 2) Heap Fetches: 0 //表示需要掃描的數據塊的個數。 Buffers: shared hit=3 Planning time: 0.058 ms Execution time: 0.036 ms (7 rows)Bitmap Index Scan:
利用Bitmap結構掃描。Bitmap Index Scan與Index Scan都是基于索引的掃描,但Bitmap Index Scan節點返回的是一個位圖而不是一個元組,位圖中每位代表了一個掃描到的數據塊。
Bitmap Heap Scan:
Bitmap Heap Scan一般作為Bitmap Index Scan的父節點,將Bitmap Index Scan返回的位圖轉換為對應的元組。相比Index Scan,Bitmap Index Scan將隨機讀轉換成了按照數據塊的物理順序讀取,這在數據量比較大的時候會極大地提升掃描性能。例如
explain(ANALYZE,VERBOSE,BUFFERS) select * from class where st_no=2;命令的返回結果如下:QUERY PLAN -------------------------------------------------------------------------------------------------- Bitmap Heap Scan on public.class (cost=4.29..8.30 rows=1 width=35) (actual time=0.025..0.025 rows=1 loops=1) Output: st_no, name //表示對public.class表進行Bitmap Heap掃描。 Recheck Cond: (class.st_no = 2) //表示Bitmap Heap Scan的Recheck操作的條件是class.st_no = 2。 Heap Blocks: exact=1 //表示準確掃描到的數據塊個數是1。 Buffers: shared hit=3 -> Bitmap Index Scan on no_index (cost=0.00..4.29 rows=1 width=0) (actual time=0.019..0.019 rows=1 loops=1) //表示使用no_index索引進行位圖索引掃描。 Index Cond: (class.st_no = 2) //表示位圖索引的條件為class.st_no = 2。 Buffers: shared hit=2 Planning time: 0.088 ms Execution time: 0.063 ms (10 rows)說明在大多數情況下,Index Scan要比Seq Scan快。
如果獲取的結果集在所有數據中占比很大時,Index Scan因為要先掃描索引再讀表數據,所以反而會比Seq Scan慢。
如果獲取的結果集的占比比較小,但是元組數很多時,Bitmap Index Scan的性能要比Index Scan好。
如果獲取的結果集能夠被索引覆蓋,則Index Only Scan因為僅需掃描索引,正常情況下性能最好。如果存在可見性映射表(Virtual Map)未生成等特殊情況,性能則會下降。
SQL優化示例
本節列舉兩個示例,分別使用EXPLAIN命令對SQL優化前后的表進行分析,對比一下前后的差距。
無索引表的優化
SQL優化前:對無索引的表T1執行
explain analyze select * from t1 where id =1;命令的返回結果如下。QUERY PLAN ------------------------------------------------------------------------------------------------------------------- Gather (cost=1000.00..97331.31 rows=1 width=4) (actual time=0.217..302.316 rows=1 loops=1) Workers Planned: 2 Workers Launched: 2 -> Parallel Seq Scan on t1 (cost=0.00..96331.21 rows=1 width=4) (actual time=191.208..289.240 rows=0 loops=3) Filter: (id = 1) Rows Removed by Filter: 3333333 Planning Time: 0.030 ms Execution Time: 302.381 ms (8 rows)通過計劃可以看出,
SELECT針對T1表進行了全表掃描,過濾條件為id=1,總執行時間為302.381ms,效率不是很理想。SQL優化后:通過
create index on t1(id)給T1表中的id列創建索引,重新執行explain analyze select * from t1 where id =1;命令,返回結果如下。QUERY PLAN ------------------------------------------------------------------------------------------------------------------- Index Only Scan using t1_id_idx on t1 (cost=0.43..2.45 rows=1 width=4) (actual time=0.035..0.036 rows=1 loops=1) Index Cond: (id = 1) Heap Fetches: 1 Planning Time: 0.134 ms Execution Time: 0.052 ms (5 rows)總執行時間縮短至
0.052ms,相比優化前的302.381ms提升了數千倍。
非最佳索引表的優化
創建一張名為T2的表,插入100萬條隨機數據,并對id列創建索引。
create table t2(id int,name int);
insert into t2 select random()*(id/100),random()*(id/100) from generate_series(1,1000000) t(id);
create index on t2(id)SQL優化前:執行
explain analyze select * from t2 where id=10 and name=13;命令的返回結果如下。QUERY PLAN ---------------------------------------------------------------------------------------------------------------- Index Scan using t2_id_idx on t2 (cost=0.42..12.12 rows=1 width=8) (actual time=0.098..2.631 rows=88 loops=1) Index Cond: (id = 10) Filter: (name = 13) Rows Removed by Filter: 4461 Planning Time: 0.081 ms Execution Time: 2.655 ms (6 rows)通過計劃可以看出已經做了索引掃描,但是還存在
name列的條件過濾,還有優化的空間。SQL優化后:通過
create index on t2(id,name);給T2表中的id列和name列各增加一個索引。重新執行explain analyze select * from t2 where id=10 and name=13;命令,返回結果如下。QUERY PLAN --------------------------------------------------------------------------------------------------------------------------- Index Only Scan using t2_id_name_idx on t2 (cost=0.42..15.48 rows=18 width=8) (actual time=0.028..0.134 rows=88 loops=1) Index Cond: ((id = 10) AND (name = 13)) Heap Fetches: 88 Planning Time: 0.198 ms Execution Time: 0.157 ms (5 rows)總執行時間縮短至
0.157ms,優化成功。