RDS SQL Server提供了增量備份上云的解決方案。您需要先將全量備份文件上傳至阿里云的對象存儲服務(OSS),并通過RDS控制臺將全量備份數據恢復至指定的RDS SQL Server數據庫中。然后通過RDS控制臺將差異備份或日志備份文件導入該RDS SQL Server數據庫中,以實現增量備份上云的效果。該方案能夠將業務中斷時間控制在分鐘級別,從而有效縮短業務中斷時間。
適用場景
RDS SQL Server增量數據上云適用于以下場景:
基于備份文件物理遷移至RDS SQL Server,而不是邏輯遷移。
說明物理遷移是指基于文件的遷移,邏輯遷移是指將數據生成DML語句寫入RDS SQL Server。
物理遷移可做到數據庫遷移后和本地環境100%一致。邏輯遷移無法做到100%一致,例如索引碎片率、統計信息等。
對業務停止時間敏感,需要將業務中斷時間控制在分鐘級別。
說明如果您對業務停止時間不是非常敏感(例如可以接受2小時的中斷),當數據庫小于100 GB時,建議您通過全量備份文件上云。具體操作,請參見全量備份數據上云(SQL Server 2008 R2云盤、2012及以上版本)。
前提條件
RDS SQL Server實例版本為2008 R2云盤、2012及以上,且實例中沒有與待上云數據庫名稱相同的數據庫。如需創建實例,請參見創建RDS SQL Server實例。
說明RDS SQL Server 2008 R2云盤實例已停止新售,詳情請參見【停售/下線】2023年07月14日起RDS SQL Server 2008 R2云盤實例停止售賣。
RDS SQL Server實例擁有足夠的存儲空間。如果空間不足,請提前升級實例空間。具體操作,請參見變更配置。
RDS SQL Server實例已創建高權限賬號。具體操作,請參見創建數據庫和賬號。
本地SQL Server數據庫的恢復模式需要設置為
FULL模式。說明在進行增量備份數據上云時,需要進行事務日志備份,而Simple模式下不允許進行事務日志備份。
如果差異備份文件很大,可能會導致增量備份上云的時間變長。
在本地數據庫環境中執行
DBCC CHECKDB語句,以確保數據庫中沒有任何的allocation errors和consistency errors。正常執行結果如下:... CHECKDB found 0 allocation errors and 0 consistency errors in database 'xxx'. DBCC execution completed. If DBCC printed error messages, contact your system administrator.已開通OSS服務。具體操作,請參見開通OSS服務。
OSS Bucket與RDS SQL Server實例需要處于相同地域。相關操作,請參見步驟二:上傳備份文件到OSS。
如果通過RAM用戶登錄,則必須滿足以下條件:
RAM賬號具備AliyunOSSFullAccess權限和AliyunRDSFullAccess權限。如何為RAM用戶授權,請參見通過RAM對OSS進行權限管理和通過RAM對RDS進行權限管理。
阿里云賬號(主賬號)已授權RDS官方服務賬號可以訪問您OSS的權限。
所在阿里云賬號(主賬號)需手動創建權限策略,然后將權限添加到RAM賬號中。如何創建權限策略,請參見通過腳本編輯模式創建自定義權限策略。
策略內容如下:
{ "Version": "1", "Statement": [ { "Action": [ "ram:GetRole" ], "Resource": "acs:ram:*:*:role/AliyunRDSImportRole", "Effect": "Allow" } ] }
注意事項
本方案遷移的級別為數據庫,即每次只能遷移一個數據庫上云。如果需要遷移多個或所有數據庫,建議采用實例級的遷移上云方案。具體操作,請參見SQL Server實例級別遷移上云。
不支持高版本的備份文件往低版本做遷移,例如從SQL Server 2016遷移到SQL Server 2012。
備份文件名不能包含@、|等特殊字符,否則會導致上云失敗。
授予RDS服務賬號訪問OSS的權限以后,系統會在訪問控制RAM的角色管理中創建名為AliyunRDSImportRole的角色,請勿修改或刪除這個角色,否則會導致上云任務無法下載備份文件而失敗。如果修改或刪除了這個角色,您需要通過數據上云向導重新授權。
本方案遷移上云后,無法使用原有的賬號,需要在RDS控制臺重新創建賬號。
在OSS備份數據恢復上云任務沒有完成之前,請不要刪除OSS上的備份文件,否則會導致上云任務失敗。
支持的上云備份文件后綴格式為
.bak(全量備份)、.diff(差異備份)、.trn或.log(事務日志備份)。說明實際使用時,并非嚴格要求每種備份類型必須對應其格式后綴,例如
.bak可代表全量備份、差異備份或事務日志備份。如果備份文件不是上述提到的文件后綴,系統可能無法正確識別該文件的類型并影響后續操作。
對于通過RDS控制臺下載的SQL Server日志備份文件(而非本文步驟一官方腳本生成的
.bak備份文件),該文件默認格式為.zip.log,格式處理后可直接用于增量上云。處理方法:先將文件擴展改為
.zip以解壓,再將解壓得到的database_name.lbak重命名為.bak格式,最后上傳此.bak文件到OSS中作為增量日志備份進行上云。
操作流程舉例
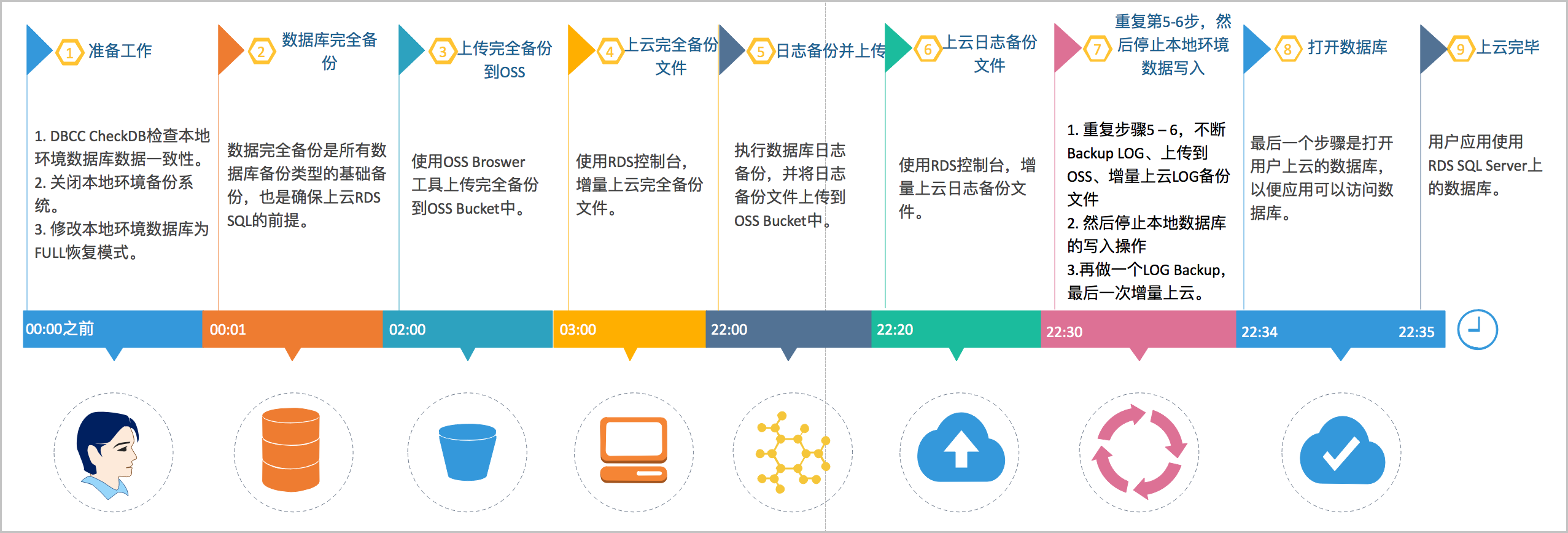
根據上圖增量上云案例,按時間維度,解釋如下。
上云階段 | 步驟 | 說明 |
全量階段 | Step1. 00:00之前 | 完成準備工作,包括:
|
Step2. 00:01 | 開始對線下數據庫做FULL Backup,耗時近1小時。 | |
Step3. 02:00 | 上傳備份文件到OSS Bucket,耗時近1小時。 | |
Step4. 03:00 | 開始在RDS控制臺恢復FULL Backup文件,耗時19小時。 | |
增量階段 | Step5. 22:00 | 開始數據庫增量LOG備份上云,完成LOG備份并上傳至OSS,耗時約20分鐘。 |
Step6. 22:20 | 完成LOG Backup上云,耗時約10分鐘。 | |
Step6. 22:30 |
| |
打開數據庫 | Step8. 22:34 | 完成了最后一個LOG Backup文件增量上云操作,耗時4分鐘,開始將數據庫上線。 |
Step9. 22:35 | 數據庫上線完畢,如果選擇異步執行DBCC操作,上線速度快,耗時1分鐘。 |
從整個的動作流程和時間軸來看,用戶需要停止應用的時間非常的短,僅在最后一個LOG Backup之前停止應用寫入即可。在本例中整個應用停止的時間控制在5分鐘內。
步驟一:備份本地數據庫
下載備份腳本,用SSMS打開備份腳本。
修改如下參數。
配置項
說明
@backup_databases_list
需要備份的數據庫,多個數據庫以分號或者逗號分隔。
@backup_type
備份類型。參數值如下:
FULL:全量備份
DIFF:差異備份
LOG:日志備份
@backup_folder
備份文件所在的本地目錄。如不存在,會自動創建。
@is_run
是否執行備份。參數值如下:
1:執行備份。
0:只做檢查,不執行備份。
執行備份腳本。
無論指定何種備份類型,本腳本均默認生成
.bak格式文件。
步驟二:上傳備份文件到OSS
創建存儲空間Bucket。
登錄OSS管理控制臺。
單擊Bucket列表,然后單擊創建Bucket。
配置如下關鍵參數,其他參數可以保持默認。
重要創建的存儲空間僅用于本次數據上云,且上云后不再使用,因此只需配置關鍵參數即可,為避免數據泄露及產生相關費用,上云完成后請及時刪除。
創建Bucket時請勿開啟數據加密。更多詳情,請參見數據加密。
參數
說明
取值示例
Bucket 名稱
存儲空間名稱,全局唯一,設置后無法修改。
命名規則:
只能包括小寫字母、數字和短劃線(-)。
必須以小寫字母或者數字開頭和結尾。
長度必須在3~63字符之間。
migratetest
地域
Bucket所屬的地域,如果您通過ECS內網上傳數據至Bucket中,且通過內網將數據恢復至RDS中,則需要三者地域保持一致。
華東1(杭州)
存儲類型
選擇標準存儲。本文上云操作不支持其他存儲類型的Bucket。
標準存儲
上傳備份文件到OSS。
說明當RDS實例和OSS的Bucket在同一地域時,二者可以通過內網互通,且數據上傳速度更快,并且不會產生外網流量費用。因此,在上傳備份文件時,建議將文件上傳至與目標RDS實例在同一地域的Bucket上。
本地數據庫備份完成后,需要將備份文件上傳到您的OSS Bucket中,您可以采用如下方法之一:
下載ossbrowser。
以Windows x64操作系統為例,解壓下載的
oss-browser-win32-x64.zip壓縮包,雙擊運行oss-browser.exe應用程序。使用AK登錄方式,配置參數AccessKeyId和AccessKeySecret,其他參數保持默認,然后單擊登入。
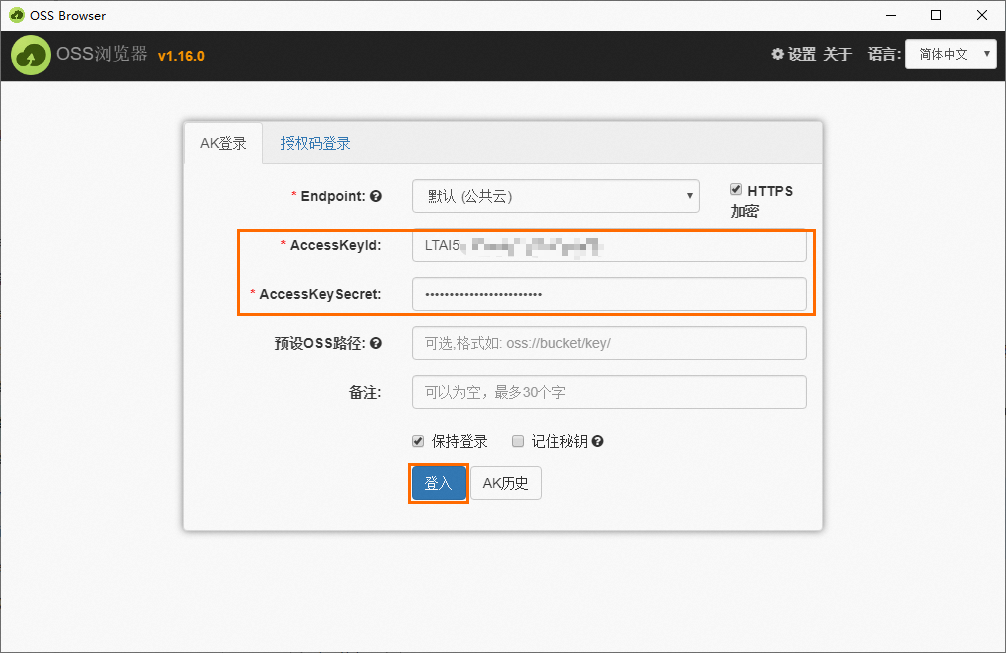 說明
說明AccessKey用于身份驗證,確保數據安全,請妥善保管,如何創建及獲取,請參見創建AccessKey。
單擊目標Bucket,進入存儲空間。

單擊
 ,選擇需要上傳的備份文件,然后單擊打開,即可將本地文件上傳至OSS中。
,選擇需要上傳的備份文件,然后單擊打開,即可將本地文件上傳至OSS中。
說明如果備份文件小于5 GB,建議您直接通過OSS控制臺上傳備份文件。
登錄OSS管理控制臺。
單擊Bucket列表,然后單擊目標Bucket名稱。
在文件列表中,單擊上傳文件。
您可以將備份文件拖拽至待上傳文件區域,也可以單擊掃描文件,選擇需要上傳的備份文件。
單擊頁面下方的上傳文件,即可將本地備份文件上傳至OSS中。
說明如果備份文件大于5 GB,建議您調用OSS API采用分片上傳的方式將備份文件上傳到OSS Bucket中。
本示例以Java項目為例,從環境變量中獲取訪問憑證代碼。運行本代碼示例之前,請先配置環境變量。如何配置訪問憑證,請參見配置訪問憑證。更多示例,請參見分片上傳。
import com.aliyun.oss.ClientException; import com.aliyun.oss.OSS; import com.aliyun.oss.common.auth.*; import com.aliyun.oss.OSSClientBuilder; import com.aliyun.oss.OSSException; import com.aliyun.oss.internal.Mimetypes; import com.aliyun.oss.model.*; import java.io.File; import java.io.FileInputStream; import java.io.InputStream; import java.util.ArrayList; import java.util.List; public class Demo { public static void main(String[] args) throws Exception { // Endpoint以華東1(杭州)為例,其它Region請按實際情況填寫。 String endpoint = "https://oss-cn-hangzhou.aliyuncs.com"; // 從環境變量中獲取訪問憑證。運行本代碼示例之前,請確保已設置環境變量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。 EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider(); // 填寫Bucket名稱,例如examplebucket。 String bucketName = "examplebucket"; // 填寫Object完整路徑,例如exampledir/exampleobject.txt。Object完整路徑中不能包含Bucket名稱。 String objectName = "exampledir/exampleobject.txt"; // 待上傳本地文件路徑。 String filePath = "D:\\localpath\\examplefile.txt"; // 創建OSSClient實例。 OSS ossClient = new OSSClientBuilder().build(endpoint, credentialsProvider); try { // 創建InitiateMultipartUploadRequest對象。 InitiateMultipartUploadRequest request = new InitiateMultipartUploadRequest(bucketName, objectName); // 如果需要在初始化分片時設置請求頭,請參考以下示例代碼。 ObjectMetadata metadata = new ObjectMetadata(); // metadata.setHeader(OSSHeaders.OSS_STORAGE_CLASS, StorageClass.Standard.toString()); // 指定該Object的網頁緩存行為。 // metadata.setCacheControl("no-cache"); // 指定該Object被下載時的名稱。 // metadata.setContentDisposition("attachment;filename=oss_MultipartUpload.txt"); // 指定該Object的內容編碼格式。 // metadata.setContentEncoding(OSSConstants.DEFAULT_CHARSET_NAME); // 指定初始化分片上傳時是否覆蓋同名Object。此處設置為true,表示禁止覆蓋同名Object。 // metadata.setHeader("x-oss-forbid-overwrite", "true"); // 指定上傳該Object的每個part時使用的服務器端加密方式。 // metadata.setHeader(OSSHeaders.OSS_SERVER_SIDE_ENCRYPTION, ObjectMetadata.KMS_SERVER_SIDE_ENCRYPTION); // 指定Object的加密算法。如果未指定此選項,表明Object使用AES256加密算法。 // metadata.setHeader(OSSHeaders.OSS_SERVER_SIDE_DATA_ENCRYPTION, ObjectMetadata.KMS_SERVER_SIDE_ENCRYPTION); // 指定KMS托管的用戶主密鑰。 // metadata.setHeader(OSSHeaders.OSS_SERVER_SIDE_ENCRYPTION_KEY_ID, "9468da86-3509-4f8d-a61e-6eab1eac****"); // 指定Object的存儲類型。 // metadata.setHeader(OSSHeaders.OSS_STORAGE_CLASS, StorageClass.Standard); // 指定Object的對象標簽,可同時設置多個標簽。 // metadata.setHeader(OSSHeaders.OSS_TAGGING, "a:1"); // request.setObjectMetadata(metadata); // 根據文件自動設置ContentType。如果不設置,ContentType默認值為application/oct-srream。 if (metadata.getContentType() == null) { metadata.setContentType(Mimetypes.getInstance().getMimetype(new File(filePath), objectName)); } // 初始化分片。 InitiateMultipartUploadResult upresult = ossClient.initiateMultipartUpload(request); // 返回uploadId。 String uploadId = upresult.getUploadId(); // 根據uploadId執行取消分片上傳事件或者列舉已上傳分片的操作。 // 如果您需要根據uploadId執行取消分片上傳事件的操作,您需要在調用InitiateMultipartUpload完成初始化分片之后獲取uploadId。 // 如果您需要根據uploadId執行列舉已上傳分片的操作,您需要在調用InitiateMultipartUpload完成初始化分片之后,且在調用CompleteMultipartUpload完成分片上傳之前獲取uploadId。 // System.out.println(uploadId); // partETags是PartETag的集合。PartETag由分片的ETag和分片號組成。 List<PartETag> partETags = new ArrayList<PartETag>(); // 每個分片的大小,用于計算文件有多少個分片。單位為字節。 final long partSize = 1 * 1024 * 1024L; //1 MB。 // 根據上傳的數據大小計算分片數。以本地文件為例,說明如何通過File.length()獲取上傳數據的大小。 final File sampleFile = new File(filePath); long fileLength = sampleFile.length(); int partCount = (int) (fileLength / partSize); if (fileLength % partSize != 0) { partCount++; } // 遍歷分片上傳。 for (int i = 0; i < partCount; i++) { long startPos = i * partSize; long curPartSize = (i + 1 == partCount) ? (fileLength - startPos) : partSize; UploadPartRequest uploadPartRequest = new UploadPartRequest(); uploadPartRequest.setBucketName(bucketName); uploadPartRequest.setKey(objectName); uploadPartRequest.setUploadId(uploadId); // 設置上傳的分片流。 // 以本地文件為例說明如何創建FIleInputstream,并通過InputStream.skip()方法跳過指定數據。 InputStream instream = new FileInputStream(sampleFile); instream.skip(startPos); uploadPartRequest.setInputStream(instream); // 設置分片大小。除了最后一個分片沒有大小限制,其他的分片最小為100 KB。 uploadPartRequest.setPartSize(curPartSize); // 設置分片號。每一個上傳的分片都有一個分片號,取值范圍是1~10000,如果超出此范圍,OSS將返回InvalidArgument錯誤碼。 uploadPartRequest.setPartNumber( i + 1); // 每個分片不需要按順序上傳,甚至可以在不同客戶端上傳,OSS會按照分片號排序組成完整的文件。 UploadPartResult uploadPartResult = ossClient.uploadPart(uploadPartRequest); // 每次上傳分片之后,OSS的返回結果包含PartETag。PartETag將被保存在partETags中。 partETags.add(uploadPartResult.getPartETag()); } // 創建CompleteMultipartUploadRequest對象。 // 在執行完成分片上傳操作時,需要提供所有有效的partETags。OSS收到提交的partETags后,會逐一驗證每個分片的有效性。當所有的數據分片驗證通過后,OSS將把這些分片組合成一個完整的文件。 CompleteMultipartUploadRequest completeMultipartUploadRequest = new CompleteMultipartUploadRequest(bucketName, objectName, uploadId, partETags); // 如果需要在完成分片上傳的同時設置文件訪問權限,請參考以下示例代碼。 // completeMultipartUploadRequest.setObjectACL(CannedAccessControlList.Private); // 指定是否列舉當前UploadId已上傳的所有Part。僅在Java SDK為3.14.0及以上版本時,支持通過服務端List分片數據來合并完整文件時,將CompleteMultipartUploadRequest中的partETags設置為null。 // Map<String, String> headers = new HashMap<String, String>(); // 如果指定了x-oss-complete-all:yes,則OSS會列舉當前UploadId已上傳的所有Part,然后按照PartNumber的序號排序并執行CompleteMultipartUpload操作。 // 如果指定了x-oss-complete-all:yes,則不允許繼續指定body,否則報錯。 // headers.put("x-oss-complete-all","yes"); // completeMultipartUploadRequest.setHeaders(headers); // 完成分片上傳。 CompleteMultipartUploadResult completeMultipartUploadResult = ossClient.completeMultipartUpload(completeMultipartUploadRequest); System.out.println(completeMultipartUploadResult.getETag()); } catch (OSSException oe) { System.out.println("Caught an OSSException, which means your request made it to OSS, " + "but was rejected with an error response for some reason."); System.out.println("Error Message:" + oe.getErrorMessage()); System.out.println("Error Code:" + oe.getErrorCode()); System.out.println("Request ID:" + oe.getRequestId()); System.out.println("Host ID:" + oe.getHostId()); } catch (ClientException ce) { System.out.println("Caught an ClientException, which means the client encountered " + "a serious internal problem while trying to communicate with OSS, " + "such as not being able to access the network."); System.out.println("Error Message:" + ce.getMessage()); } finally { if (ossClient != null) { ossClient.shutdown(); } } } }
步驟三:創建數據上云任務
- 訪問RDS實例列表,在上方選擇地域,然后單擊目標實例ID。
在左側菜單欄中選擇備份恢復。
單擊頁面上方的OSS備份數據恢復上云。
在數據導入向導頁面,單擊兩次下一步,進入數據導入步驟。
說明如果您是第一次使用OSS備份數據恢復上云功能,需要給RDS官方服務賬號授予訪問OSS的權限,請單擊授權地址并同意授權,否則會因權限問題導致OSS Bucket下拉列表為空。
設置如下參數,單擊確定。
請耐心等待上云任務完成,您可以單擊刷新查看數據上云任務最新狀態。
配置項
說明
數據庫名
備份數據導入目標RDS實例上的數據庫名,名稱需要符合SQL Server官方限制。
重要進行上云操作前,請確保目標實例上不存在與備份文件指定要還原的數據庫名稱相同的數據庫,也不存在相同名稱的未附加數據庫文件。若都不存在,則可以使用備份集中同名數據庫文件名稱還原數據庫。
如果目標實例上存在與備份文件指定要還原的數據庫名稱相同的數據庫,或者存在同名的未附加數據庫文件,上云操作將失敗。
OSS Bucket
選擇備份文件所在的OSS Bucket。
OSS子文件夾名
備份文件所在的子文件夾名。
OSS文件列表
單擊右側放大鏡按鈕,可以按照備份文件名前綴模糊查找,會展示文件名、文件大小和更新時間。請選擇需要上云的備份文件。
上云方案
選擇不打開數據庫。
打開數據庫(只有一個全量備份文件):全量上云,適合僅有一個完全備份文件上云的場景。此時CreateMigrateTask中的
BackupMode = FULL并且IsOnlineDB = True。不打開數據庫(還有差異備份或日志文件):增量上云,適合有完全備份文件加上日志備份(或者差異備份文件)上云的場景,此時CreateMigrateTask 中的
BackupMode = UPDF并且IsOnlineDB = False。
步驟四:導入差異或日志備份文件
SQL Server本地數據庫全量備份上云完成后,接下來需要導入差異備份或者日志備份文件。
- 訪問RDS實例列表,在上方選擇地域,然后單擊目標實例ID。
在左側菜單欄中選擇備份恢復,單擊備份數據上云記錄頁簽。
在任務列表中找到待導入備份文件的記錄,在右側單擊上傳增量文件,選擇增量文件后單擊確認。
說明如果您有多個日志備份文件,請使用同樣的方法逐個生成上云任務。
請在上傳增量文件時,盡量保證最后一個備份文件的大小不超過500MB,以此來縮短增量上云的時間開銷。
在最后一個日志備份文件生成前,請停止本地數據庫所有的寫入操作,以保證線下數據庫和RDS SQL Server上的數據庫數據一致。
步驟五:打開數據庫
導入文件后RDS SQL Server中的數據庫會處于In Recovery或者Restoring狀態。高可用系列會是In Recovery狀態,單機版會是Restoring狀態,此時的數據庫還無法進行讀寫操作,需要打開數據庫。
- 訪問RDS實例列表,在上方選擇地域,然后單擊目標實例ID。
在左側菜單欄中選擇備份恢復,單擊備份數據上云記錄頁簽。
在任務列表中找到待導入備份文件的記錄,在右側單擊打開數據庫。
選擇數據庫的打開方式,單擊確定。
說明打開數據庫一致性檢查有以下兩種方式:
異步執行DBCC:在打開數據庫的時候系統不做DBCC CheckDB,會在打開數據庫任務結束以后,異步執行DBCC CheckDB操作,以此來節約打開數據庫操作的時間開銷(數據庫比較大,DBCC CheckDB非常耗時),減少您的業務停機時間。如果您對業務停機時間要求非常敏感,且不關心DBCC CheckDB結果,建議使用異步執行DBCC。此時CreateMigrateTask 中的
CheckDBMode = AsyncExecuteDBCheck。同步執行DBCC:相對于異步執行DBCC,有的用戶非常關心DBCC CheckDB的結果,以此來找出用戶線下數據庫數據一致性錯誤。此時,建議您選擇同步執行DBCC,影響是會拉長打開數據庫的時間。此時CreateMigrateTask 中的
CheckDBMode = SyncExecuteDBCheck。
步驟六:查看上云任務備份文件詳情
您可以在備份恢復頁面備份數據上云記錄頁簽內查看備份上云記錄,單擊對應任務最右側的查看文件詳情,將展示對應任務所有關聯的備份文件詳情。
常見錯誤
全量備份數據上云中常見錯誤,請參見全量備份數據上云(SQL Server 2008 R2云盤、2012及以上版本)-常見錯誤。
用戶在增量上云過程中,還有可能會遇到下面的錯誤:
數據庫打開失敗
錯誤信息:Failed to open database xxx.
錯誤原因:線下SQL Server數據庫啟用了一些高級功能,如果用戶選擇的RDS SQL版本不支持這些高級功能,會導致數據庫打開失敗。例如本地SQL Server數據庫是企業版,啟用了數據壓縮(Data Compression)或者分區(Partition),OSS上云到RDS SQL Server Web版,就會報告這個錯誤。
解決方法:
在本地SQL Server實例上禁用高級功能,重新備份后,再使用OSS上云功能。
購買與線下SQL Server實例相同版本的RDS SQL Server。
數據庫備份鏈中LSN無法對接
錯誤信息:The log in this backup set begins at LSN XXX, which is too recent to apply to the database.RESTORE LOG is terminating abnormally.
錯誤原因:在SQL Server數據庫中,差異備份或者日志備份能夠成功還原的前提是,差異或者日志備份的LSN必須與上一次還原的備份文件LSN能夠對接上,否則就會報告這個錯誤。
解決方法:請選擇對應的LSN備份文件進行增量備份文件上云,您可以按照備份文件備份操作時間先后順序進行增量上云操作。
異步DBCC Checkdb失敗
錯誤信息:asynchronously DBCC checkdb failed: CHECKDB found 0 allocation errors and 2 consistency errors in table 'XXX' (object ID XXX).
錯誤原因:備份文件還原到RDS SQL Server上,上云任務系統會異步做DBCC CheckDB檢查,如果檢查不通過,說明本地數據庫中已經有錯誤發生。
解決方法:
在RDS SQL Server上執行:
DBCC CHECKDB (DBName,REPAIR_ALLOW_DATA_LOSS)說明使用該命令修復錯誤的過程,可能會導致數據丟失。
在本地使用如下命令修復錯誤后重新進行增量上云。
DBCC CHECKDB (DBName,REPAIR_ALLOW_DATA_LOSS)
完全備份文件類型
錯誤信息:Backup set (xxx) is a Database FULL backup, we only accept transaction log or differential backup.
錯誤原因:在增量上云RDS SQL Server過程中,全量備份文件還原完畢后,就只能再接受日志備份文件或者是差異備份文件。如果用戶再次選擇了全量備份文件,就會報告這個錯誤。
解決方法:選擇日志備份文件或者差異備份文件。
數據庫個數超出最大限制數
錯誤信息:The database (xxx) migration failed due to databases count limitation.
錯誤原因:當數據庫達到數量限制以后再做上云操作,任務會失敗報告這個錯誤。
解決方法:遷移上云數據庫到其他的RDS SQL Server,或者刪除不必要的數據庫。
RAM賬號操作權限不足
Q:步驟三:創建數據上云任務的步驟5中,各配置項參數均已填寫完整,但確定按鈕為灰色無法單擊?
A:無法單擊的原因可能是您為RAM用戶,您的賬號權限不足。請參見本文前提條件,確保相應權限已授予。
相關API
API | 描述 |
將OSS上的備份文件還原到RDS SQL Server實例,創建數據上云任務。 | |
打開RDS SQL Server備份數據上云任務的數據庫。 | |
查詢RDS SQL Server實例備份數據上云任務列表。 | |
查詢RDS SQL Server備份數據上云任務的文件詳情。 |