本文介紹基于Tair Vector和CLIP實現實時高性能圖文多模態檢索的解決方案。
背景信息
在互聯網中,大量信息(例如圖片、文本等)通常以非結構化的形式存在。達摩院的CLIP開源模型內置了Text transformer、ResNet等模型,支持對圖片、文本等非結構化數據進行特征提取,并解析成結構化數據。
您可以先通過CLIP模型將圖片、文檔等數據預處理,然后將CLIP的預處理結果存入Tair中,根據Vector提供的近鄰檢索功能,實現高效的圖文多模態檢索。更多關于Tair Vector的信息,請參見Vector。
方案概述
下載圖片數據。
本示例使用的測試數據:
圖片:為開源的寵物圖片數據集,包含7000多張各種形態的寵物圖片。
文本:“狗”、“白色的狗”和“奔跑的白色的狗”。
連接Tair實例,具體實現可參見示例代碼中的
get_tair函數。在Tair中分別為圖片(Images)和文字(Texts)創建向量索引,具體實現可參見示例代碼中的
create_index函數。寫入圖片和文本數據。
通過CLIP模型對圖片、文本數據進行預處理,并通過Vector的TVS.HSET命令,將其名稱和其特征信息存入Tair中。具體實現可參見示例代碼中的
insert_images函數(寫入圖片)和upsert_text函數(寫入文本)。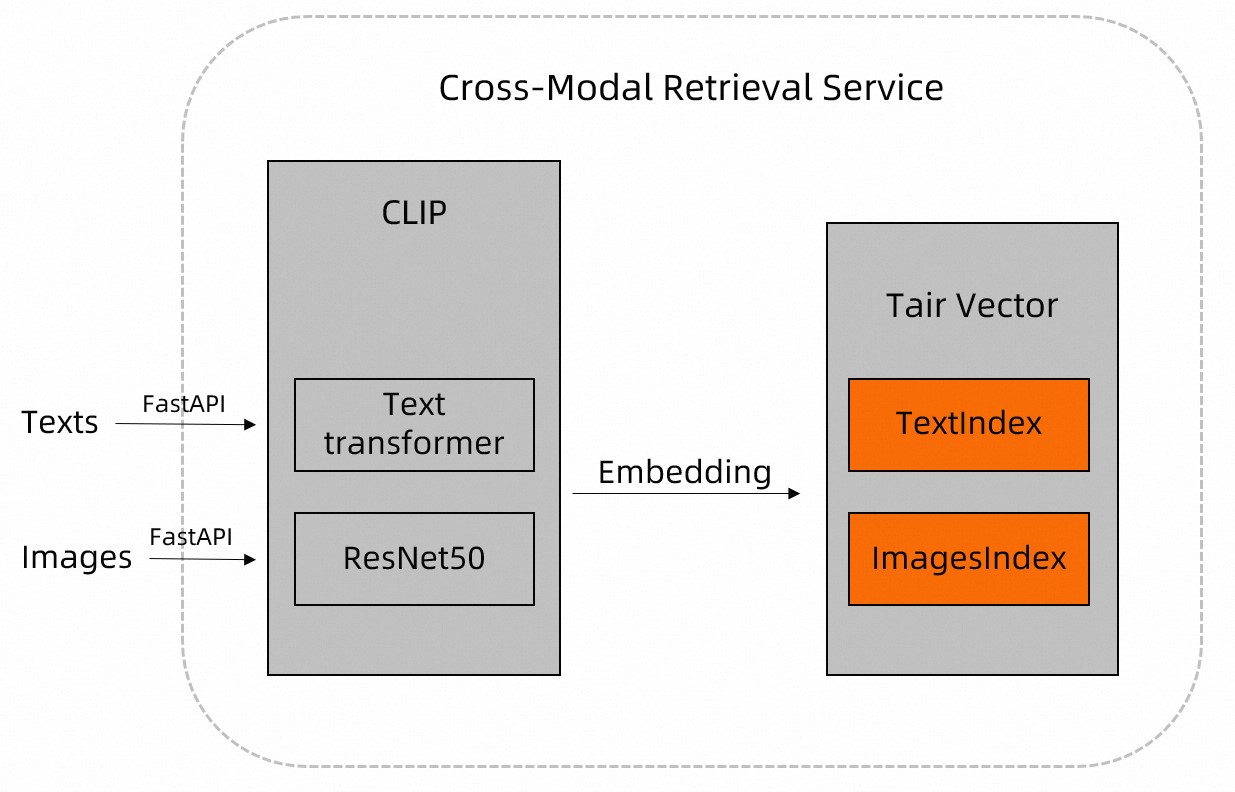
進行多模態查詢。
以文搜圖
通過CLIP模型將待查詢的文本內容進行預處理,然后通過Vector的TVS.KNNSEARCH命令,查詢Tair數據庫與該文本描述最為相似的圖片。具體實現可參見示例代碼中的
query_images_by_text函數。以圖搜文
通過CLIP模型將待查詢的圖片內容進行預處理,然后通過Vector的TVS.KNNSEARCH命令,查詢Tair數據庫中與該圖片最為吻合的文本。具體實現可參見示例代碼中的
query_texts_by_image函數。
說明查詢的文本或圖片無需存入TairVector中。
TVS.KNNSEARCH支持指定返回的結果數量(
topK),返回的相似距離(distance)越小,表示相似度越高。
示例代碼
本示例的Python版本為3.8,且需安裝Tair-py、torch、Image、pylab、plt、CLIP等依賴,其中Tair-py的快捷安裝命令為:pip3 install tair。
# -*- coding: utf-8 -*-
# !/usr/bin/env python
from tair import Tair
from tair.tairvector import DistanceMetric
from tair import ResponseError
from typing import List
import torch
from PIL import Image
import pylab
from matplotlib import pyplot as plt
import os
import cn_clip.clip as clip
from cn_clip.clip import available_models
def get_tair() -> Tair:
"""
該方法用于連接Tair實例。
* host:Tair實例連接地址。
* port:Tair實例的端口號,默認為6379。
* password:Tair實例的密碼(默認賬號)。若通過自定義賬號連接,則密碼格式為“username:password”。
"""
tair: Tair = Tair(
host="r-8vbehg90y9rlk9****pd.redis.rds.aliyuncs.com",
port=6379,
db=0,
password="D******3",
decode_responses=True
)
return tair
def create_index():
"""
創建存儲圖片、文本向量的Vector索引:
* 圖片Key名稱為"index_images"、文本Key名稱為"index_texts"。
* 向量維度為1024。
* 計算向量距離函數為IP。
* 索引算法為HNSW。
"""
ret = tair.tvs_get_index("index_images")
if ret is None:
tair.tvs_create_index("index_images", 1024, distance_type="IP",
index_type="HNSW")
ret = tair.tvs_get_index("index_texts")
if ret is None:
tair.tvs_create_index("index_texts", 1024, distance_type="IP",
index_type="HNSW")
def insert_images(image_dir):
"""
您需要輸入圖片的路徑,該方法會自動遍歷路徑下的圖片文件。
同時,該方法會調用extract_image_features方法(通過CLIP模型對圖片文件進行預處理,并返回圖片的特征信息),并行將返回的特征信息存入TairVector中。
存入Tair的格式為:
* 向量索引名稱為“index_images”(固定)。
* Key為圖片路徑及其文件名,例如“test/images/boxer_18.jpg”。
* 特征信息為1024維向量。
"""
file_names = [f for f in os.listdir(image_dir) if (f.endswith('.jpg') or f.endswith('.jpeg'))]
for file_name in file_names:
image_feature = extract_image_features(image_dir + "/" + file_name)
tair.tvs_hset("index_images", image_dir + "/" + file_name, image_feature)
def extract_image_features(img_name):
"""
該方法將通過CLIP模型對圖片文件進行預處理,并返回圖片的特征信息(1024維向量)。
"""
image_data = Image.open(img_name).convert("RGB")
infer_data = preprocess(image_data)
infer_data = infer_data.unsqueeze(0).to("cuda")
with torch.no_grad():
image_features = model.encode_image(infer_data)
image_features /= image_features.norm(dim=-1, keepdim=True)
return image_features.cpu().numpy()[0] # [1, 1024]
def upsert_text(text):
"""
您需要輸入需存儲的文本,該方法會調用extract_text_features方法(通過CLIP模型對文本進行預處理,并返回文本的特征信息),并行將返回的特征信息存入TairVector中。
存入Tair的格式為:
* 向量索引名稱為“index_texts”(固定)。
* Key為文本內容,例如“奔跑的狗”。
* 特征信息為1024維向量。
"""
text_features = extract_text_features(text)
tair.tvs_hset("index_texts", text, text_features)
def extract_text_features(text):
"""
該方法將通過CLIP模型對文本進行預處理,并返回文本的特征信息(1024維向量)。
"""
text_data = clip.tokenize([text]).to("cuda")
with torch.no_grad():
text_features = model.encode_text(text_data)
text_features /= text_features.norm(dim=-1, keepdim=True)
return text_features.cpu().numpy()[0] # [1, 1024]
def query_images_by_text(text, topK):
"""
該方法將用于以文搜圖。
您需要輸入待搜索的文本內容(text)和返回的結果數量(topK)。
該方法會通過CLIP 模型將待查詢的文本內容進行預處理,然后通過Vector的TVS.KNNSEARCH命令,查詢Tair數據庫中與該文本描述最為相似的圖片。
將返回目標圖片的Key名稱和相似距離(distance),其中相似距離(distance)越小,表示相似度越高。
"""
text_feature = extract_text_features(text)
result = tair.tvs_knnsearch("index_images", topK, text_feature)
for k, s in result:
print(f'key : {k}, distance : {s}')
img = Image.open(k.decode('utf-8'))
plt.imshow(img)
pylab.show()
def query_texts_by_image(image_path, topK=3):
"""
該方法將用于以圖搜文。
您需要輸入待查詢圖片的路徑和返回的結果數量(topK)。
該方法會通過CLIP 模型將待查詢的圖片內容進行預處理,然后通過Vector的TVS.KNNSEARCH命令,查詢Tair數據庫中與該圖片最為吻合的文本。
將返回目標文本的Key名稱和相似距離(distance),其中相似距離(distance)越小,表示相似度越高。
"""
image_feature = extract_image_features(image_path)
result = tair.tvs_knnsearch("index_texts", topK, image_feature)
for k, s in result:
print(f'text : {k}, distance : {s}')
if __name__ == "__main__":
# 連接Tair數據庫,并分別創建存儲圖片和文本的向量索引。
tair = get_tair()
create_index()
# 加載Chinese-CLIP模型。
model, preprocess = clip.load_from_name("RN50", device="cuda", download_root="./")
model.eval()
# 例如寵物圖片數據集的路徑為“/home/CLIP_Demo”,寫入圖片數據。
insert_images("/home/CLIP_Demo")
# 寫入文本示例數據("狗"、"白色的狗"、"奔跑的白色的狗")。
upsert_text("狗")
upsert_text("白色的狗")
upsert_text("奔跑的白色的狗")
# 以文搜圖,查詢最符合文本"奔跑的狗"的三張圖。
query_images_by_text("奔跑的狗", 3)
# 以圖搜文,指定圖片路徑,查詢比較符合圖片描述的文本。
query_texts_by_image("/home/CLIP_Demo/boxer_18.jpg",3)結果展示
以文搜圖,查詢最符合文本"奔跑的狗"的三張圖,結果如下。
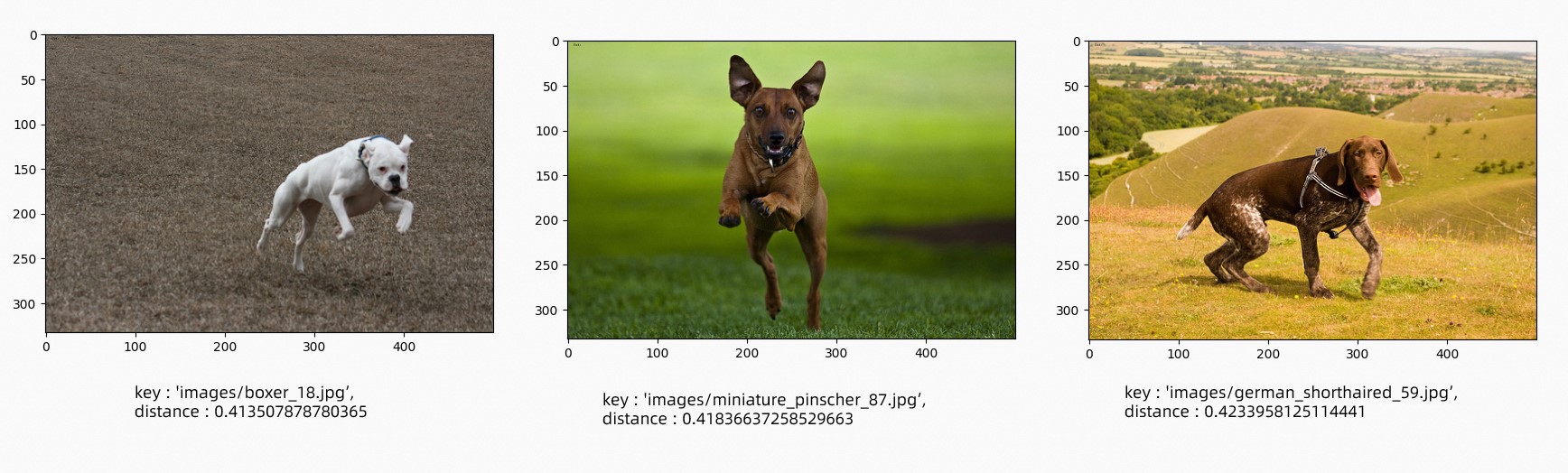
以圖搜文,指定查詢圖片如下。

查詢結果如下。
{ "results":[ { "text":"奔跑的白色的狗", "distance": "0.4052203893661499" }, { "text":"白色的狗", "distance": "0.44666868448257446" }, { "text":"狗", "distance": "0.4553511142730713" } ] }
總結
Tair作為純內存數據庫,內置了HNSW等索引算法加快了檢索的速度。
采用CLIP與Tair Vector進行多模態檢索,既可以進行以文搜圖(例如商品推薦場景),也可以進行以圖搜文(例如寫作場景)。同時,您也可以采用其他的模型取代CLIP模型,實現以文本搜索視頻、音頻等更多模態的檢索功能。