本文以網絡質量分析器數據查詢分析、儀表盤、告警為例,幫助您快速上手網絡質量分析器操作。
前提條件
創建端應用并設置網絡探測規則。具體操作,請參見新建接入端應用和設置網絡探測規則。
背景信息
阿里云日志服務網絡質量分析器是一款能夠幫助用戶對網絡質量進行實時分析和監控的工具。用戶需要對通過網絡質量分析器收集到的數據進行分析、查看,并設置告警。本文檔將幫助用戶自定義配置儀表盤、告警和查看分析數據,以更好地滿足其需求。
步驟一:查找存儲探測數據的Logstore
登錄日志服務控制臺。
在日志應用區域,單擊網絡質量分析器。
單擊頁面右上角的接入端管理。
在接入端管理頁面的應用列表中,單擊目標接入端應用對應的
 圖標。
圖標。在應用詳情面板中,單擊目標Logstore。
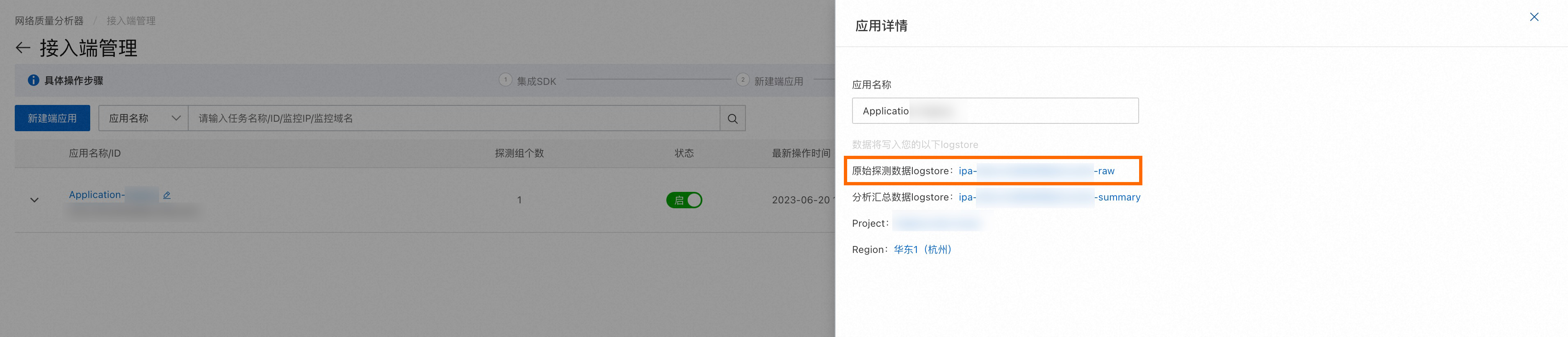
在目標Logstore中,查看網絡探測數據。
網絡探測數據字段的詳細說明,請參見網絡探測字段說明。
說明您也可以通過接入應用的Project下查找名稱為ipa-${應用ID}-raw的Logstore,查看原始探測數據。
步驟二:自定義查詢與分析
所有數據已預先設置索引,您可以通過json_extract_scalar函數提取attribute.net.origin中的字段。
示例1
查詢需求:查看PING探測方式下每秒鐘的總探測次數。
查詢語句:
* and attribute.net.origin: ping | select date_trunc('second', __time__) as time, sum(cast(json_extract_scalar("attribute.net.origin",'$.count') as bigint)) as total group by time order by time asc limit 10000000查詢結果:
示例2
查詢需求:統計所有探測方式不同的設備號。
查詢語句:
* | select DISTINCT json_extract_scalar("attribute.net.origin",'$.deviceId')查詢結果:
示例3
查詢需求:查看TCPPING探測方式,每分鐘平均丟包率。
查詢語句:
* and attribute.net.origin: tcpping | select date_trunc('minute', __time__) as time, avg(cast(json_extract_scalar("attribute.net.origin",'$.loss') as double)) as total group by time order by time asc limit 10000000查詢結果:
更多函數,請參見函數概覽。
步驟三:添加儀表盤
在查詢結果生成的統計圖表頁簽中,單擊添加到儀表盤。
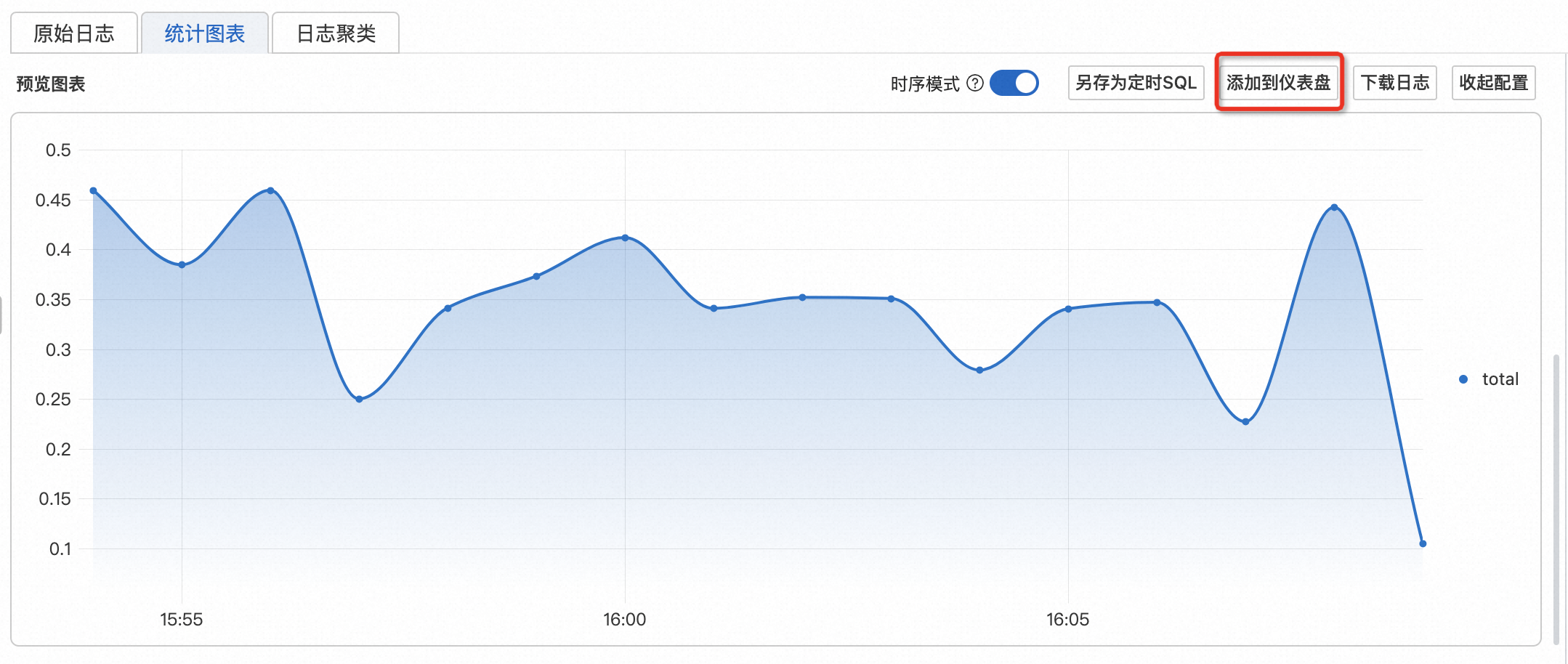
在儀表盤中查看自定義網絡質量分析器報表。
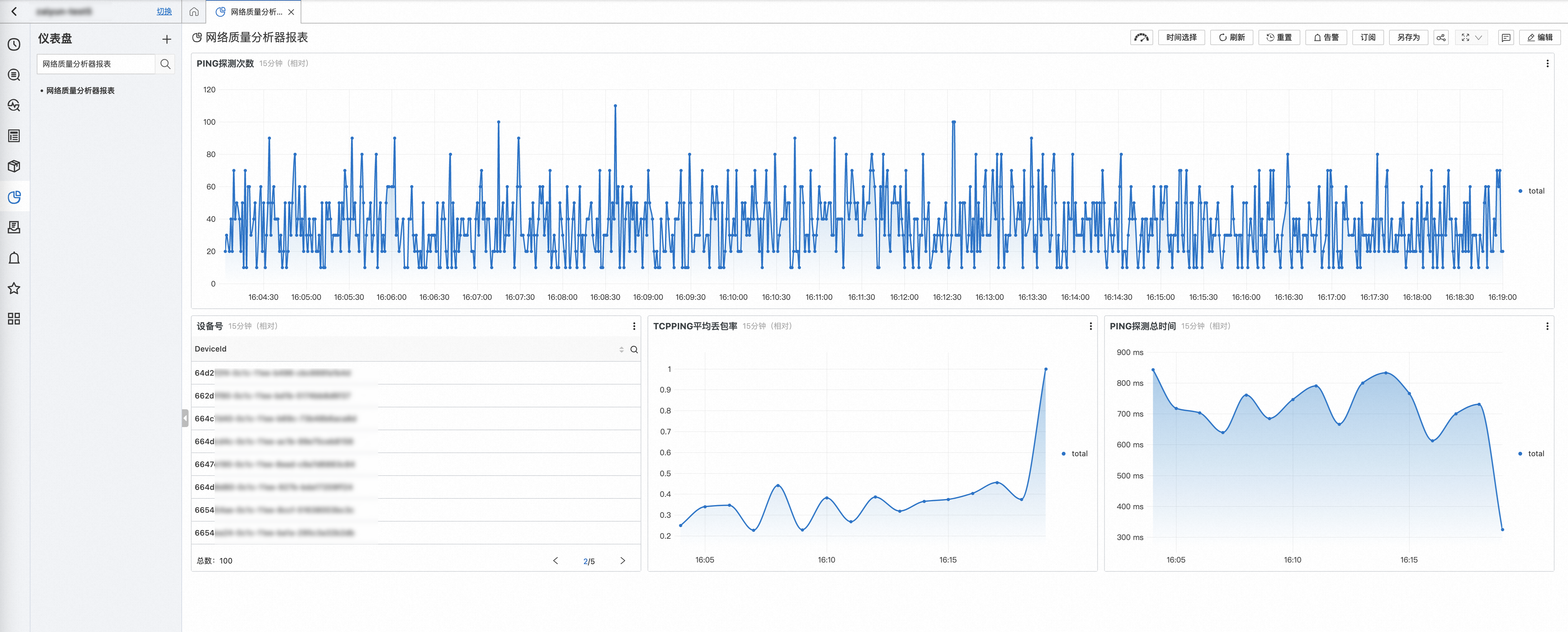
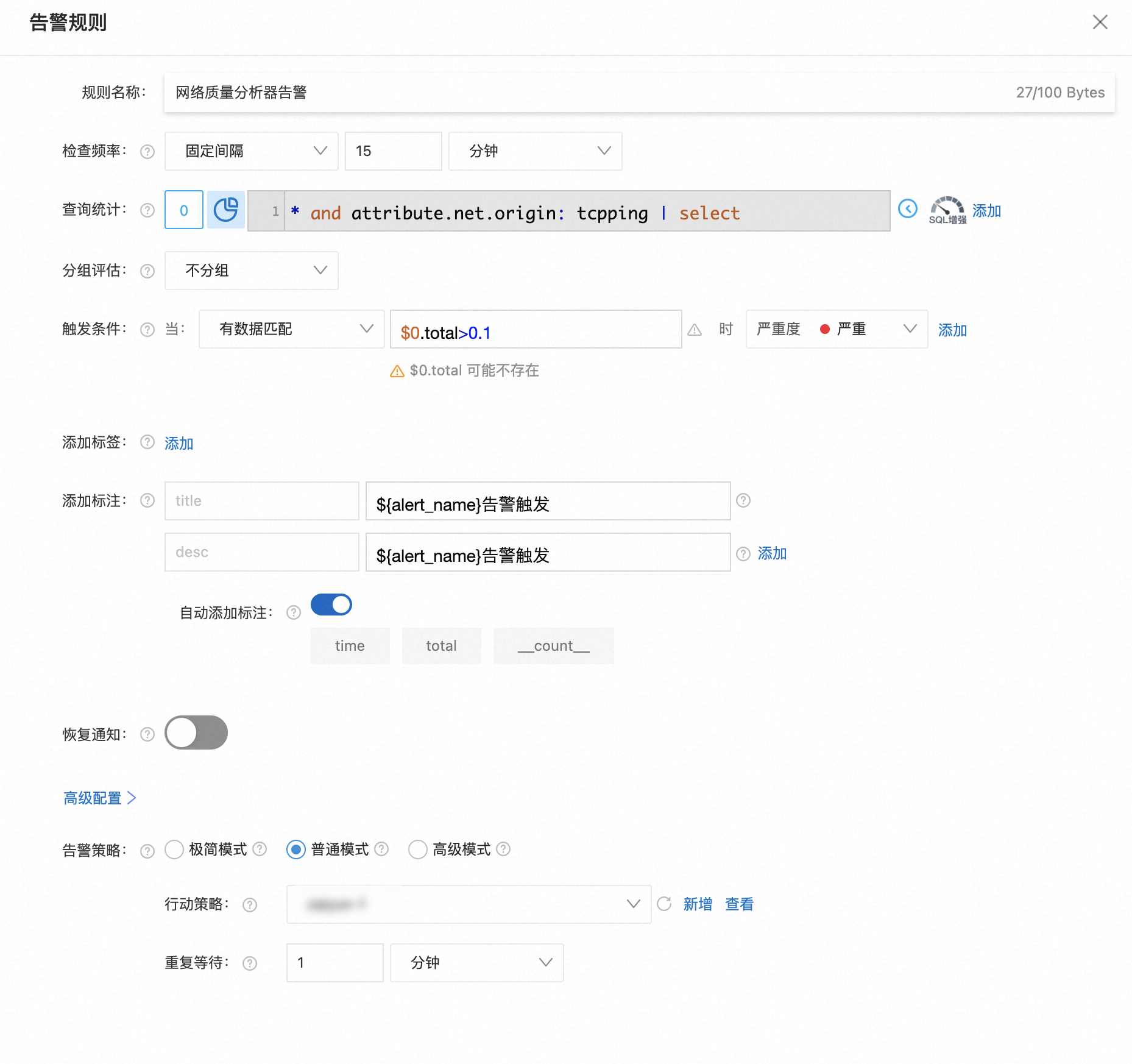
步驟四:設置告警
在儀表盤界面中,選擇右上角告警 > 創建新版告警。此處以設置tcpping丟包率>0.1告警為例。
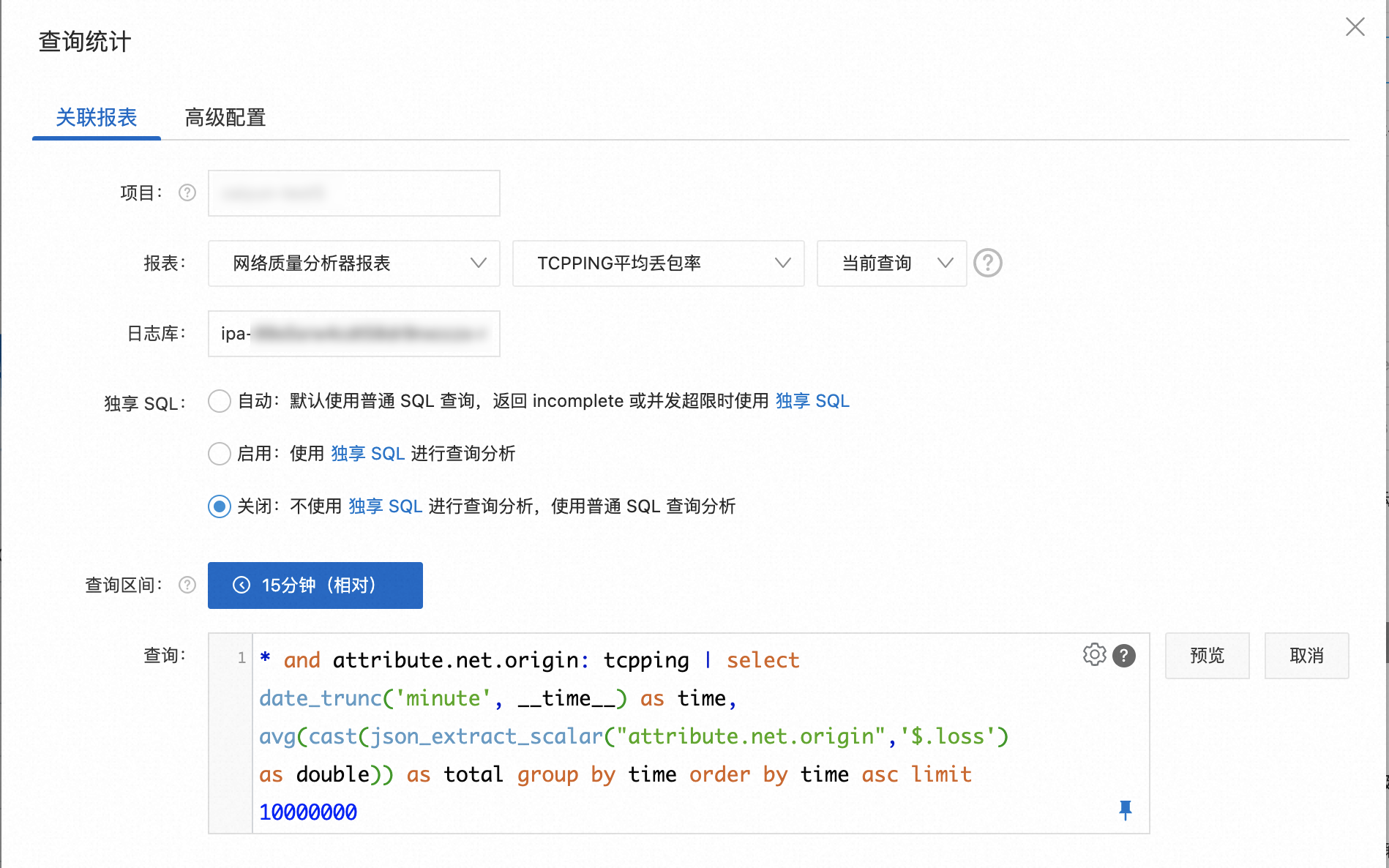
在告警規則配置頁面中,單擊添加查詢統計。
選擇關聯報表為網絡質量分析器報表或單擊高級配置自定義查詢統計配置。具體操作,請參見創建日志告警監控規則。
在告警規則配置界面中,單擊確定。
配置生效后,當丟包率異常時,將收到告警通知。