如果需要使用MaxCompute備份表格存儲數據或者遷移表格存儲數據到MaxCompute中使用,您可以通過在DataWorks數據集成控制臺新建和配置離線同步任務來實現全量數據導出。全量數據導出到MaxCompute后,您可以使用DataWorks數據分析功能查看和分析導出到MaxCompute中的數據。
注意事項
表格存儲的字段名稱大小寫敏感,請確保MaxComputer中的字段名稱與表格存儲中的字段名稱一致。
步驟一:新增表格存儲數據源
將表格存儲數據庫添加為數據源,具體步驟如下:
進入數據集成頁面。
以項目管理員身份登錄DataWorks控制臺。
在左側導航欄,單擊工作空間列表后,選擇地域。
在工作空間列表頁面,在目標工作空間操作列選擇快速進入>數據集成。
在左側導航欄,單擊數據源。
在數據源頁面,單擊新增數據源。
在新增數據源對話框,找到Tablestore區塊,單擊Tablestore。
在新增OTS數據源對話框,根據下表配置數據源參數。
參數
說明
數據源名稱
數據源名稱必須以字母、數字、下劃線(_)組合,且不能以數字和下劃線(_)開頭。
數據源描述
對數據源進行簡單描述,不得超過80個字符。
Endpoint
Tablestore實例的服務地址。更多信息,請參見服務地址。
如果Tablestore實例和目標數據源的資源在同一個地域,填寫VPC地址;如果Tablestore實例和目標數據源的資源不在同一個地域,填寫公網地址。
Table Store實例名稱
Tablestore實例的名稱。更多信息,請參見實例。
AccessKey ID
阿里云賬號或者RAM用戶的AccessKey ID和AccessKey Secret。獲取方式請參見創建AccessKey。
AccessKey Secret
測試資源組連通性。
創建數據源時,您需要測試資源組的連通性,以保證同步任務使用的資源組能夠與數據源連通,否則將無法正常執行數據同步任務。
重要數據同步時,一個任務只能使用一種資源組。資源組列表默認顯示僅數據集成公共資源組。為確保數據同步的穩定性和性能要求,推薦使用獨享數據集成資源組。
單擊前往購買進行全新創建或單擊綁定已購資源組綁定已有資源組。具體操作,請參見新增和使用獨享數據集成資源組。
單擊相應資源組操作列的測試連通性。
當連通狀態顯示為可連通時,表示連通成功。
測試連通性通過后,單擊完成。
在數據源列表中,可以查看新建的數據源。
步驟二:新增MaxCompute數據源
具體操作與步驟一類似,將MaxCompute添加為數據源。
在數據源列表頁面,單擊新增數據源。
在新增數據源對話框,找到MaxCompute區塊,單擊MaxCompute。
在新增MaxCompute數據源對話框中配置參數,并測試資源組連通性,再單擊完成。具體操作,請參見創建MaxCompute數據源。
重要數據同步時,一個任務只能使用一種資源組。資源組列表默認僅顯示獨享數據集成資源組,為確保數據同步的穩定性和性能要求,推薦使用獨享數據集成資源組。
如果未創建資源組,請單擊新建獨享數據集成資源組進行創建。具體操作,請參見新增和使用獨享數據集成資源組。
步驟三:新建同步任務節點
進入數據開發頁面。
以項目管理員身份登錄DataWorks控制臺。
選擇地域,在左側導航欄,單擊工作空間列表。
在工作空間列表頁面,在目標工作空間操作列選擇快速進入>數據開發。
在DataStudio控制臺的數據開發頁面,單擊業務流程節點下的目標業務流程。
如果需要新建業務流程,請參見創建業務流程。
在數據集成節點上右鍵選擇新建節點 > 離線同步。
在新建節點對話框,選擇路徑并填寫節點名稱。
單擊確認。
在數據集成節點下會顯示新建的離線同步節點。
步驟四:配置離線同步任務并啟動
配置表格存儲到MaxCompute的同步任務,具體步驟如下:
在數據集成節點下,雙擊打開新建的離線同步任務節點。
配置同步網絡鏈接。
選擇離線同步任務的數據來源、數據去向以及用于執行同步任務的資源組,并測試連通性。
重要數據同步任務的執行必須經過資源組來實現,請選擇資源組并保證資源組與讀寫兩端的數據源能聯通訪問。
在網絡與資源配置步驟,選擇數據來源為Tablestore,并選擇數據源名稱為步驟一:新增表格存儲數據源中新增的源數據源。
選擇資源組。
選擇資源組后,系統會顯示資源組的地域、規格等信息以及自動測試資源組與所選數據源之間連通性。
重要請與新增數據源時選擇的資源組保持一致。
選擇數據去向為MaxCompute(ODPS),并選擇數據源名稱為步驟二:新增MaxCompute數據源中新增的目的數據源。
系統會自動測試資源組與所選數據源之間連通性。
測試可連通后,單擊下一步。
配置任務。
您可以通過向導模式或者腳本模式配置任務,請根據實際需要選擇。
(推薦)向導模式
在配置任務步驟的配置數據來源與去向區域,根據實際配置數據來源和數據去向。
數據來源配置
參數
說明
表
表格存儲中的數據表名稱。
主鍵區間分布(起始)
數據讀取的起始主鍵和結束主鍵,格式為JSON數組。
起始主鍵和結束主鍵需要是有效的主鍵或者是由INF_MIN和INF_MAX類型組成的虛擬點,虛擬點的列數必須與主鍵相同。
其中INF_MIN表示無限小,任何類型的值都比它大;INF_MAX表示無限大,任何類型的值都比它小。
數據表中的行按主鍵從小到大排序,讀取范圍是一個左閉右開的區間,返回的是大于等于起始主鍵且小于結束主鍵的所有的行。
假設表包含pk1(String類型)和pk2(Integer類型)兩個主鍵列。
如果需要導出全表數據,則配置示例如下:
主鍵區間分布(起始)的配置示例
[ { "type": "INF_MIN" }, { "type": "INF_MIN" } ]主鍵區間分布(結束)的配置示例
[ { "type": "INF_MAX" }, { "type": "INF_MAX" } ]
如果需要導出
pk1="tablestore"的行,則配置示例如下:主鍵區間分布(起始)的配置示例
[ { "type": "STRING", "value": "tablestore" }, { "type": "INF_MIN" } ]主鍵區間分布(結束)的配置示例
[ { "type": "STRING", "value": "tablestore" }, { "type": "INF_MAX" } ]
主鍵區間分布(結束)
切分配置信息
自定義切分配置信息,普通情況下不建議配置。當Tablestore數據存儲發生熱點,且使用Tablestore Reader自動切分的策略不能生效時,建議使用自定義的切分規則。切分指定的是在主鍵起始和結束區間內的切分點,僅配置切分鍵,無需指定全部的主鍵。格式為JSON數組。
數據去向配置
參數
說明
Tunnel資源組
即Tunnel Quota,默認選擇“公共傳輸資源”,即MC的免費quota。
MaxCompute的數據傳輸資源選擇,具體請購買與使用獨享數據傳輸服務資源組。
說明如果獨享tunnel quota因欠費或到期不可用,任務在運行中將會自動切換為“公共傳輸資源”。
表
MaxCompute中的表名稱。
分區信息
如果您每日增量數據限定在對應日期的分區中,可以使用分區做每日增量,比如配置分區pt值為${bizdate}
寫入模式
數據寫入表中的模式。取值范圍如下:
寫入前保留已有數據(Insert Into):直接向表或靜態分區中插入數據。
寫入前清理已有數據(Insert Overwrite):先清空表中的原有數據,再向表或靜態分區中插入數據。
空字符串轉為Null寫入
如果源頭數據為空字符串,在向目標MaxCompute列寫入時是否轉為Null值寫入。
同步完成才可見
單擊高級配置后才會顯示該參數。
同步到MaxCompute中的數據是否在同步完成后才能被查詢到。
在字段映射區域,分別單擊來源字段和目標字段后的
 圖標,手動編輯來源字段和目標字段。重要
圖標,手動編輯來源字段和目標字段。重要請確保來源字段和目標字段的數量和類型相匹配。
來源字段中的字段需要以JSON格式表示,例如
{"name":"id","type":"STRING"}。目標字段中的字段直接填寫字段名稱即可。一行表示一個字段,字段映射按照同行映射執行。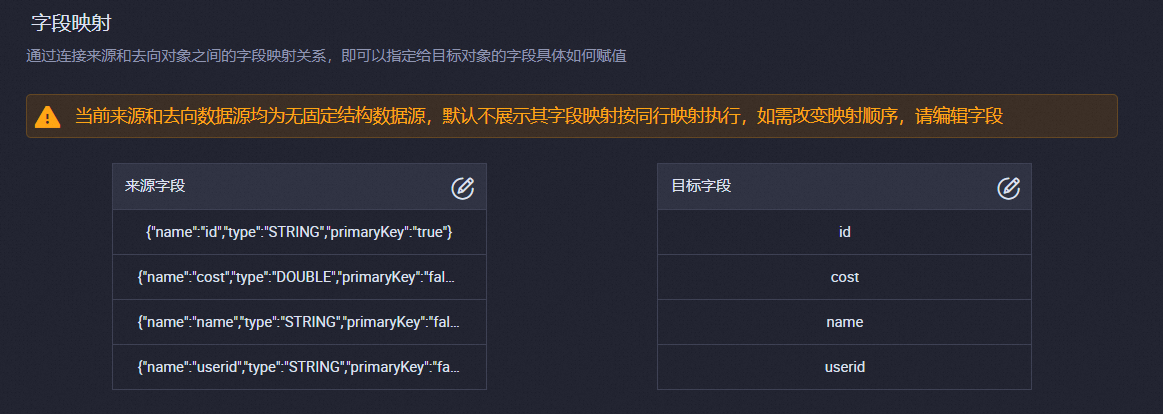
在通道控制區域,配置任務運行參數,例如任務期望最大并發數、同步速率、臟數據同步策略、分布式處理能力等。關于參數配置的更多信息,請參見配置通道。
單擊
 圖標,保存配置。說明
圖標,保存配置。說明執行后續操作時,如果未保存配置,則系統會出現保存確認的提示,單擊確認即可。
腳本模式
全量數據的同步需要使用到Tablestore(OTS) Reader和MaxCompute Writer插件。腳本配置規則請參見Tablestore數據源和MaxCompute數據源。
重要任務轉為腳本模式后,將無法轉為向導模式,請謹慎操作。
在配置任務步驟,單擊
 圖標,然后在彈出的對話框中單擊確認。
圖標,然后在彈出的對話框中單擊確認。在腳本配置頁面,請根據如下示例完成配置。
重要由于全量導出一般是一次性的,所以無需配置自動調度參數。如果需要配置調度參數,請參見同步增量數據到MaxCompute中的調度參數配置。
如果在腳本配置中存在變量,例如存在
${date},則需要在運行同步任務時設置變量的具體值。為了便于理解,在配置示例中增加了注釋內容,實際使用腳本時請刪除所有注釋內容。
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "ots", #插件名稱,不能修改。 "parameter": { "datasource": "", #表格存儲數據源名稱,請根據實際填寫。 "column": [ #需要導出的表格存儲列名。 { "name": "column1" }, { "name": "column2" }, { "name": "column3" }, { "name": "column4" }, { "name": "column5" } ], "range": { "split": [ #用于配置Tablestore的數據表的分區信息,可以加速導出。一般情況下無需配置。 { "type": "INF_MIN" }, { "type": "STRING", "value": "splitPoint1" }, { "type": "STRING", "value": "splitPoint2" }, { "type": "STRING", "value": "splitPoint3" }, { "type": "INF_MAX" } ], "end": [ { "type": "INF_MAX" #Tablestore中第一列主鍵的結束位置。如果需要導出全量數據,此處請配置為INF_MAX;如果只需導出部分數據,則按需配置。當數據表存在多個主鍵列時,此處end中需要配置對應主鍵列信息。 }, { "type": "INF_MAX" }, { "type": "STRING", "value": "end1" }, { "type": "INT", "value": "100" } ], "begin": [ { "type": "INF_MIN" #Tablestore中第一列主鍵的起始位置。如果需要導出全量數據,此處請配置為INF_MIN;如果只需導出部分數據,則按需配置。當數據表存在多個主鍵列時,此處begin中需要配置對應主鍵列信息。 }, { "type": "INF_MIN" }, { "type": "STRING", "value": "begin1" }, { "type": "INT", "value": "0" } ] }, "table": "" #Tablestore中的數據表名稱。 }, "name": "Reader", "category": "reader" }, { "stepType": "odps", #插件名稱,不能修改。 "parameter": { "partition": "", #如果表為分區表,則必填。如果表為非分區表,則不能填寫。需要寫入數據表的分區信息,必須指定到最后一級分區。 "truncate": true, #是否清空之前的數據。 "datasource": "", #MaxCompute數據源名稱,請根據實際填寫。 "column": [ #MaxCompute中的列名,列名順序必須對應TableStore中的列名順序。 "*" ], "table": "" #MaxCompute中的表名,請提前創建完成,否則任務執行會失敗。 }, "name": "Writer", "category": "writer" }, { "name": "Processor", "stepType": null, "category": "processor", "parameter": {} } ], "setting": { "executeMode": null, "errorLimit": { "record": "0" #當錯誤個數超過record個數時,導入任務會失敗。 }, "speed": { "throttle":true, #當throttle值為false時,mbps參數不生效,表示不限流;當throttle值為true時,表示限流。 "concurrent":1 #作業并發數。 "mbps":"12" #限流。 } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }您可以通過begin和end來配置導出的數據范圍,假設表包含pk1(String類型)和pk2(Integer類型)兩個主鍵列。
如果需要導出全表數據,則配置示例如下:
"begin": [ # 需要導出數據的起始位置。 { "type": "INF_MIN" }, { "type": "INF_MIN" } ], "end": [ # 需要導出數據的結束位置。 { "type": "INF_MAX" }, { "type": "INF_MAX" } ],如果需要導出
pk1="tablestore"的行,則配置示例如下:"begin": [ # 導出數據的起始位置。 { "type": "STRING", "value": "tablestore" }, { "type": "INF_MIN" } ], "end": [ # 導出數據的結束位置。 { "type": "STRING", "value": "tablestore" }, { "type": "INF_MAX" } ],
單擊
圖標,保存配置。說明執行后續操作時,如果未保存腳本,則系統會出現保存確認的提示,單擊確認即可。
執行同步任務。
重要全量數據一般只需要同步一次,無需配置調度屬性。
單擊
 圖標。
圖標。在參數對話框,選擇運行資源組的名稱。
單擊運行。
運行結束后,在同步任務的運行日志頁簽,單擊Detail log url對應的鏈接后。在任務的詳細運行日志頁面,查看
Current task status對應的狀態。當
Current task status的值為FINISH時,表示任務運行完成。
步驟五:查看導入到MaxCompute中的數據
您可使用開發ODPS SQL任務或創建臨時查詢功能,通過表操作查詢MaxCompute表的數據。