本文主要以釘釘(DingTalk)的功能為參照,詳細說明如何基于表格存儲的Timeline模型實現釘釘的IM功能。
以下內容按照聊天系統的消息存儲、關系維護、即時感知、多端同步四個功能模塊分塊,分別介紹每一部分的功能、方案介紹、表設計以及實現代碼等。
功能模塊
功能:消息存儲
消息系統中,消息存儲是最基本的功能。對于消息存儲(提供消息的讀、寫、持久化),一方面需要持久化寫入,保證消息數據的不丟失;另一方面,適合用戶的快速和高效查詢。在IM場景中,寫入方式通常是單行和批量寫入,而讀取需要按照消息隊列范圍讀取。有時用戶還有對歷史消息的模糊查詢需求,此時就需要使用多維檢索和全文檢索的能力。
消息的存儲都是基于Timeline模型。關于模型的更多信息,請參見Tablestore發布Timeline 2.0模型。
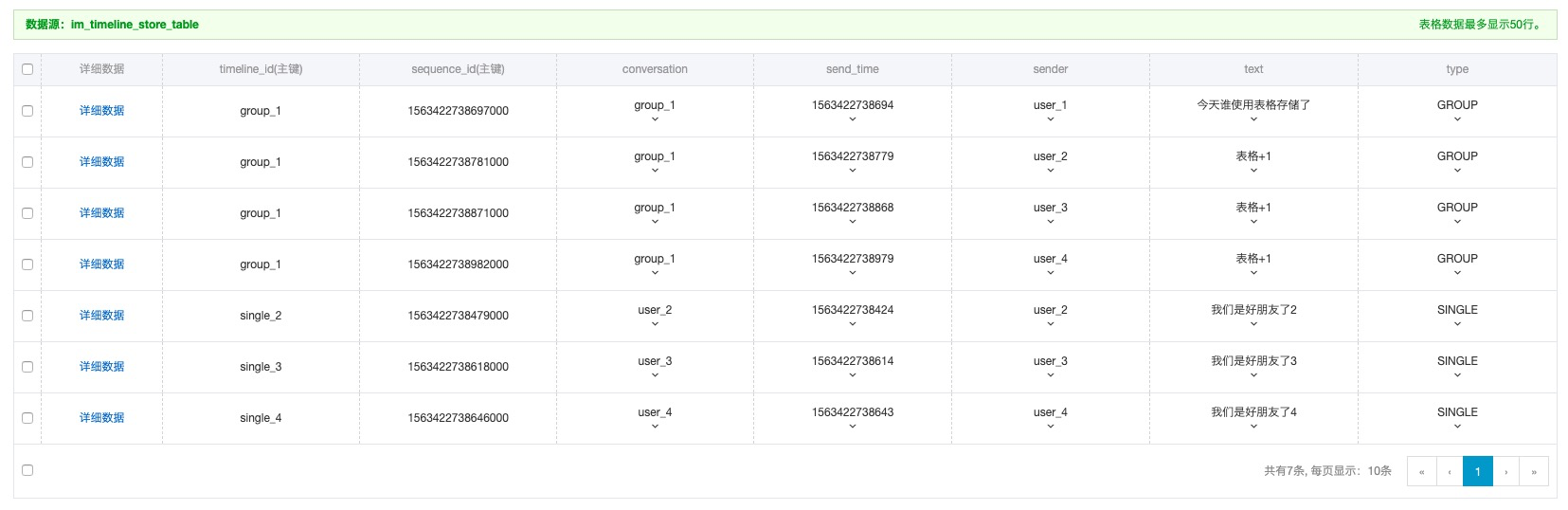
表設計:表名為im_timeline_store_table,表結構如下圖所示。
存儲庫
功能:會話窗口消息展示
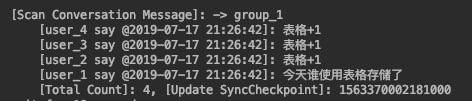
存儲庫是聊天會話消息所對應的存儲表,消息以會話分類存儲,每個會話是一個消息隊列。單個消息隊列(TimelineQueue)通過timelineId唯一標識,所有消息基于sequenceId有序排列。消息體中含有發送人、消息ID(消息去重)、消息發送時間、消息體內容、消息類型(消息類型包含圖片、文件、普通文本等,本文僅適用普通文本)。
如上圖所示,當用戶單擊某一個會話時,窗口會展示相應會話的最新一頁消息。圖中的消息均從存儲庫拉取,通過timelineId獲取該會話的Queue實例,然后調用Queue的scan接口與ScanParam參數(sequenceId范圍+倒序)拉取最新的一頁消息。當用戶向上滾動,展示完該頁消息后,客戶端會基于第一次請求的最小sequenceId發起第二次請求,獲取第二頁消息記錄,單頁消息數通常選擇20~30條。會話的消息可以選擇在客戶端持久化,然后在感知到新消息之后更新本地消息,增加緩存減少網絡IO。
存儲庫的消息需要永久保存,是整個應用的全量消息存儲。存儲庫的數據過期時間(TTL)需要設置為-1。
核心代碼
public List<AppMessage> fetchConversationMessage(String timelineId, long sequenceId) {
TimelineStore store = timelineV2.getTimelineStoreTableInstance();
TimelineIdentifier identifier = new TimelineIdentifier.Builder()
.addField("timeline_id", timelineId)
.build();
ScanParameter parameter = new ScanParameter()
.scanBackward(sequenceId)
.maxCount(30);
Iterator<TimelineEntry> iterator = store.createTimelineQueue(identifier).scan(parameter);
List<AppMessage> appMessages = new LinkedList<AppMessage>();
int counter = 0;
while (iterator.hasNext() && counter++ <= 30) {
TimelineEntry timelineEntry = iterator.next();
AppMessage appMessage = new AppMessage(timelineId, timelineEntry);
appMessages.add(appMessage);
}
return appMessages;
} 功能:多維組合、全文檢索
功能:多維組合、全文檢索
全文檢索能力是對存儲庫的消息內容進行模糊查詢,因而需要對存儲庫的數據建立多元索引。具體索引字段需要根據設計需求設計,例如釘釘公開群的檢索需要對群ID、消息發送人、消息類型、消息內容以及時間建立索引,其中消息內容需要使用分詞字符串(TEXT)類型,從而提供模糊查詢的能力。
 核心代碼
核心代碼
public List<AppMessage> searchMessage(String timelineId, String content) {
TimelineStore store = timelineV2.getTimelineStoreTableInstance();
TermQuery termQuery = new TermQuery();
termQuery.setFieldName("timeline_id");
termQuery.setTerm(ColumnValue.fromString(timelineId));
MatchPhraseQuery matchPhraseQuery = new MatchPhraseQuery();
matchPhraseQuery.setFieldName("text");
matchPhraseQuery.setText(content);
BoolQuery boolQuery = new BoolQuery();
boolQuery.setMustQueries(Arrays.asList(termQuery, matchPhraseQuery));
SearchQuery searchQuery = new SearchQuery();
searchQuery.setQuery(boolQuery);
searchQuery.setLimit(30);
List<SearchResult.Entry<TimelineEntry>> entryList = store.search(searchQuery).getEntries();
List<AppMessage> appMessages = new LinkedList<AppMessage>();
for (SearchResult.Entry<TimelineEntry> resultEntry : entryList) {
String tId = resultEntry.getIdentifier().getField(0).getValue().toString();
TimelineEntry timelineEntry = resultEntry.getData();
AppMessage appMessage = new AppMessage(tId, timelineEntry);
appMessages.add(appMessage);
}
return appMessages;
}
另外,為了做消息的權限管理,僅允許用戶檢索自己有權限查看的消息。您可以通過在消息體字段中擴展接收人ID數組來實現消息內容的權限限制,當對所有群做檢索時,增加接收人字段為自己的用戶ID即可。 樣例中未實現此功能,用戶可根據需求自行增加和修改。
同步庫
功能:新消息即時統計
當客戶端在線時,應用的系統服務會維護客戶端的長連接,因而可以感知客戶端在線。當用戶的同步庫有新消息寫入時(即有新消息),應用會發出信號通知客戶端有新消息,然后客戶端會基于同步庫checkpoint點,拉取同步庫中該sequenceId之后的所有新消息,統計各會話的新消息數,并更新checkpoint點。
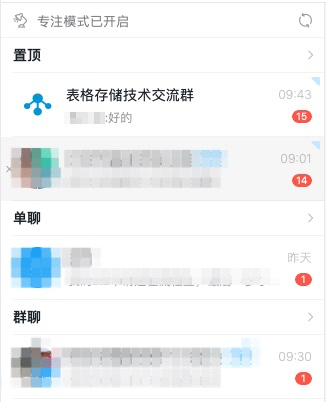
如上圖所示,對于一個在線客戶端,每個會話都會維護一個未讀消息的計數(小紅點),也會有一個總未讀數的計數,這個數量一般會存儲在客戶端本地或者通過Redis持久化。未讀消息是指通過同步庫拉取并統計過,但是還未被用戶點開的消息數量。在拉取到新消息列表后,客戶端(或應用層)會遍歷所有新消息,然后將新消息所對應會話的未讀計數累加1,這樣實現了未讀消息的即時感知與更新。只有當用戶點開會話后,會話的未讀計數才會清零。
在更新未讀數的同時,會話列表中還會有最新消息的簡短摘要信息以及最新消息的發送時間等。這些可以在遍歷新消息列表時不斷更新。統計、摘要都是依托同步庫實現的,而非存儲庫。
核心代碼
public List<AppMessage> fetchSyncMessage(String userId, long lastSequenceId) {
TimelineStore sync = timelineV2.getTimelineSyncTableInstance();
TimelineIdentifier identifier = new TimelineIdentifier.Builder()
.addField("timeline_id", userId)
.build();
ScanParameter parameter = new ScanParameter()
.scanForward(lastSequenceId)
.maxCount(30);
Iterator<TimelineEntry> iterator = sync.createTimelineQueue(identifier).scan(parameter);
List<AppMessage> appMessages = new LinkedList<AppMessage>();
int counter = 0;
while (iterator.hasNext() && counter++ <= 30) {
AppMessage appMessage = new AppMessage(userId, iterator.next());
appMessages.add(appMessage);
}
return appMessages;
}在統計到會話列表中不存在的會話時,客戶端會做一次額外請求。通過timelineID獲取會話的基本描述信息,例如群頭像或好友的頭像、群名稱等,并初始化未讀數計時器0,然后累加新消息數、更新最新消息摘要等。
同步庫對于IM場景下的新消息即時感知統計這一核心功能,就是通過寫入冗余的方式,提升新消息讀取統計的效率與速度。對于IM場景沒有收件箱的概念,因而同步庫中冗余消息并沒有永久保存的價值,提供7天過期時間已經足夠保證功能正常。用戶可以根據自身需求,調整同步庫的數據過期時間(TTL)。
功能:異步寫擴散
在本文的樣例中,單聊會話的消息在寫完存儲庫后同時寫入了同步庫,只有兩行的寫入開銷很小。但是對于群會話,寫完存儲庫后要獲取群用戶列表,然后依次寫入相應用戶的同步庫。這種方式在群少和用戶少時不會有問題,但隨著用戶體量和活躍度的增加,同步寫的方式會面臨性能問題,因此建議用戶對群寫擴散使用異步任務實現。
用戶可以基于表格存儲實現一個任務隊列,將寫擴散任務寫入隊列中后直接返回,然后由其他進程保證任務隊列的執行。任務隊列保存了群ID、消息的完整信息,消費進程不斷輪詢讀取新任務,獲取任務后,才會從群關系表中獲取完整的群成員列表,并做相應的寫擴散。
任務隊列可以直接基于Tablestore實現,表設計為兩列主鍵,第一列為topic,第二列為自增列,一個topic對應一個隊列,任務會被有序寫入單個隊列中。當并發量持續膨脹后,可對任務做hash分桶,隨機寫入多個topic。這樣可以增加消費者數量(消費并發量),提升寫擴散效率。對應任務隊列消費,用戶只需要維護每個topic的checkpoint點。checkpoint點之前的為已完成任務,通過getRange的方式順序獲取checkpoint點之后未執行的新任務,保證任務的執行。失敗的任務可以重新寫入任務隊列來提升容錯,并增加重試計數。出現多次失敗后放棄重寫,然后將該任務寫入特殊的問題隊列,方便應用的開發者們查詢、定位問題。
功能:元數據管理
元數據是指描述數據的數據,此處主要體現為用戶元數據和會話元數據兩類。此處群的元數據信息包括群ID(復用群的timelineId)、群名稱、創建時間等信息,可以直接基于timelineMeta的管理表完成實現,所有Group類型的TimelineMeta可以映射為一個Group。但是用戶的元數據卻不能復用TimelineMeta,所以需要單獨的表實現。
用戶元數據
用戶元數據即用戶的屬性信息,通過用戶ID識別特定用戶。在上文提到的用戶關系中,通過用戶的標識ID確認用戶身份,但用戶的屬性信息(例如性別、簽名、頭像等)還是需要單獨維護。
表設計:表名為im_user_table,表結構如下圖所示。
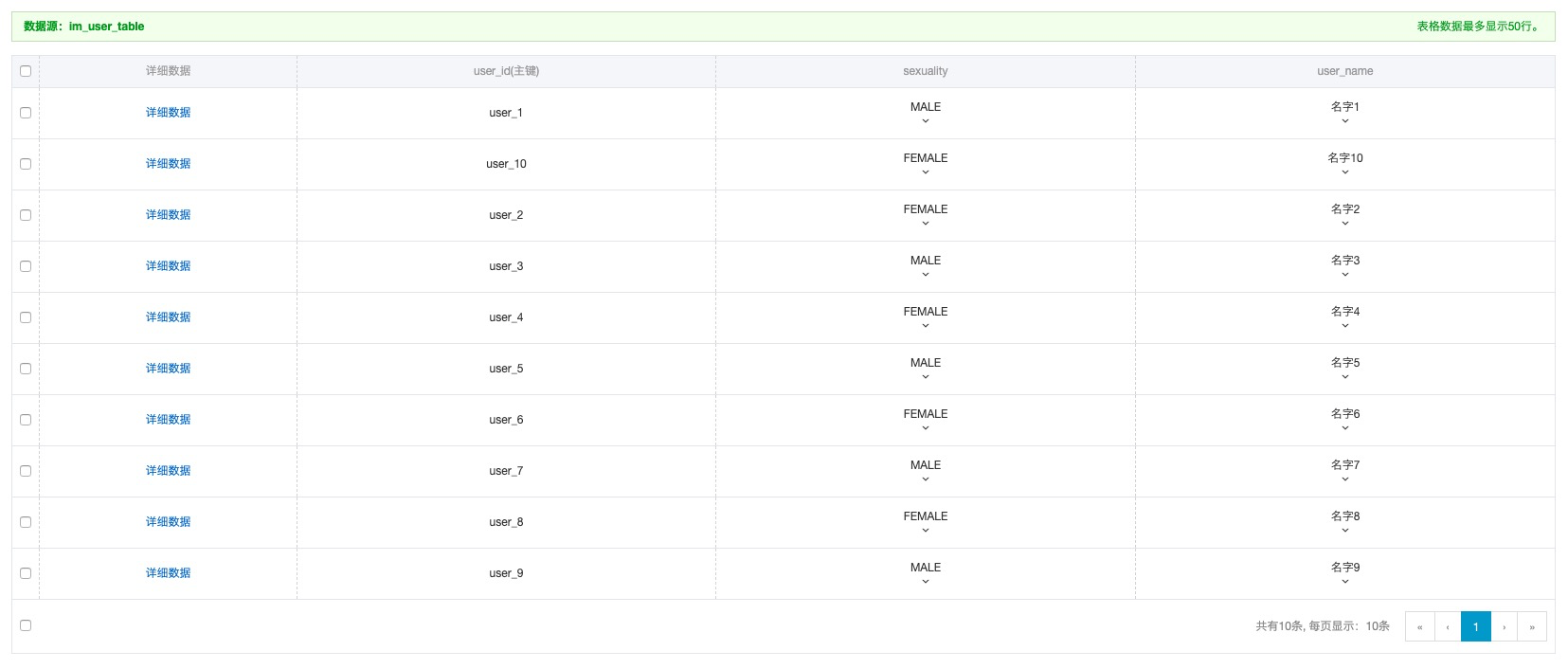
用戶元數據以user_id為標識,與同步庫中的timeline_id一一對應。用戶同步新消息時,只會拉取同步庫中自己對應的單個消息隊列(TimelineQueue)。因此為了唯一ID的方便管理,您可以選擇user_id與用戶同步庫的timeline_id使用同一個值。因此在消息寫擴散時,只需知道群內用戶的user_id列表和好友user_id,即可以完成寫擴散。
功能:用戶檢索
對于用戶,添加好友的需求有很多種,本樣例中您只需要維護用戶表,并且創建多元索引,即可輕松實現。樣例中未實現,您可以根據自己需求配置不同的索引字段設置。此處僅簡單分析一下需求。
通過用戶ID:主鍵查詢
二維碼(含用戶ID信息):主鍵查詢
用戶姓名:多元索引,用戶名字段設置為分詞字符串類型
用戶標簽:多元索引,數組字符串索引提供標簽檢索,嵌套索引提供多標簽打分檢索排序
附近的人:多元索引,GEO索引查詢附近、特定地理圍欄的人
關于多元索引的更多信息,請參見多元索引簡介。
會話元數據
會話元數據即會話的屬性信息,通過唯一會話ID識別特定會話,屬性信息包括會話類別(群、單聊、公眾號等)、群名稱、公告、創建時間等。同時,通過群名稱模糊查找群也是會話元數需要的重要能力。
在Timeline模型中,提供了Timeline Meta的管理能力,只需通過相應的接口即可實現會話元數據的管理。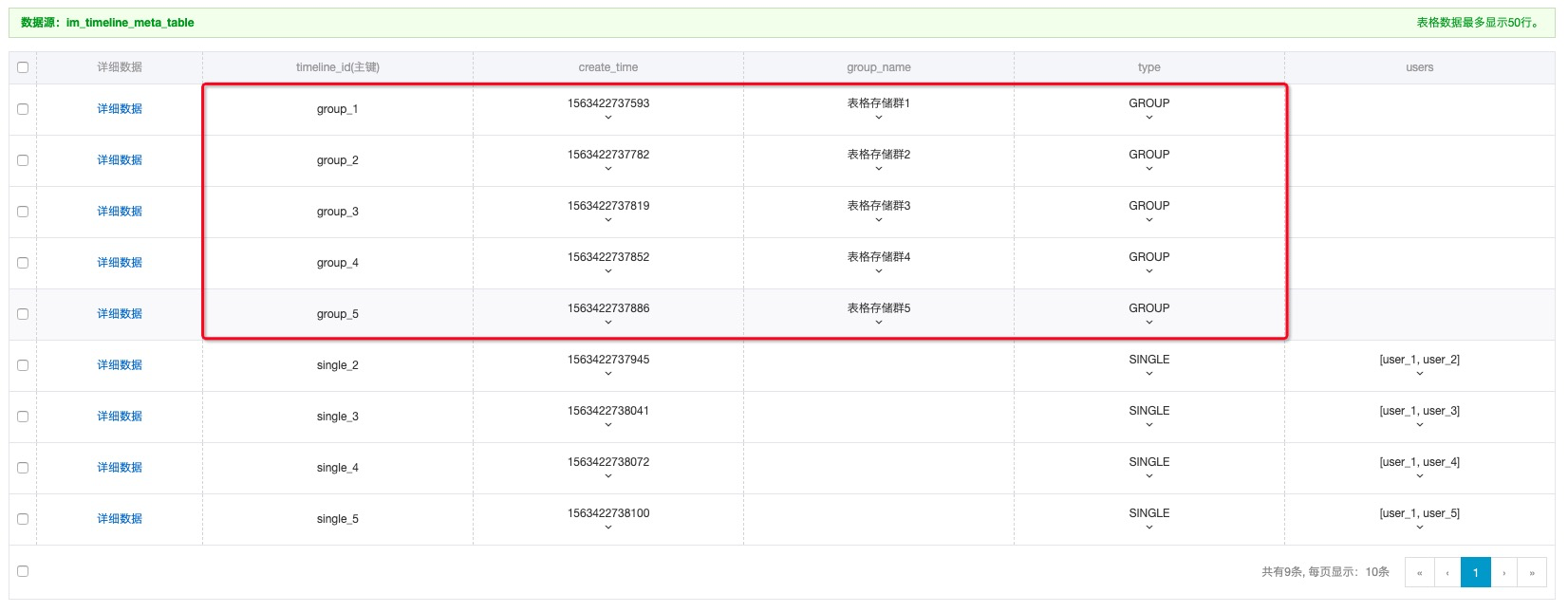
存儲庫中管理的是會話的消息隊列(TimelineQueue),此處與會話元數據中的行一一對應。客戶端用戶選中特定會話后,應用從相應的消息隊列倒序批量拉取消息展示到客戶端,群聊單聊的使用方式一樣,因而并不做會話類型的區分。
功能:群檢索
用戶如果有加入群的需求,首先需要查詢到特定的群。查詢群的方式與用戶查詢方式類似,功能也可以做相同的實現。用戶可以根據自己需求定制不同的索引字段設置,需求實現方式如下:
群ID:主鍵查詢
二維碼(含用戶ID信息):主鍵查詢
群名:多元索引,用戶名字段設置為分詞字符串類型
群標簽:多元索引,數組字符串索引提供標簽檢索,嵌套索引提供多標簽打分檢索排序
會話元數據可以直接維護單聊會話與人的映射關系。對于單聊的meta增加一列users字段用于存放兩個用戶ID,這樣不用額外維護關系表(基于單聊關系表im_user_relation_table創建timeline_id為第一列主鍵的二級索引)。
關系維護
完成了元數據管理以及用戶和群的檢索,剩下的就是如何添加好友以及加入群聊了。此處就涉及到IM系統中另一個重要的功能點關系維護。關系維護包含人與人的關系、人與群的關系以及人與會話的關系。以下介紹如何基于Tablestore解決關系維護的需求。
單聊關系
功能:人與單聊會話的關系
單聊場景下,參與者僅有兩個人,同時不考慮順序。無論是我聯系小明或是小明聯系我,對應的會話必須有且僅有一個。如果使用表格存儲維護該關系,建議使用如下設計方式。
第一列為主用戶ID、第二列為次用戶ID,在兩個人成為好友后,關系表中需要插入兩行數據,分別以自己的用戶ID為main_user,以好友的用戶ID為sub_user,然后將共同的會話timline_id作為屬性列,并且可以維護相互之間不同的昵稱、顯示。
表設計:表名為im_user_relation_table,表結構如下圖所示。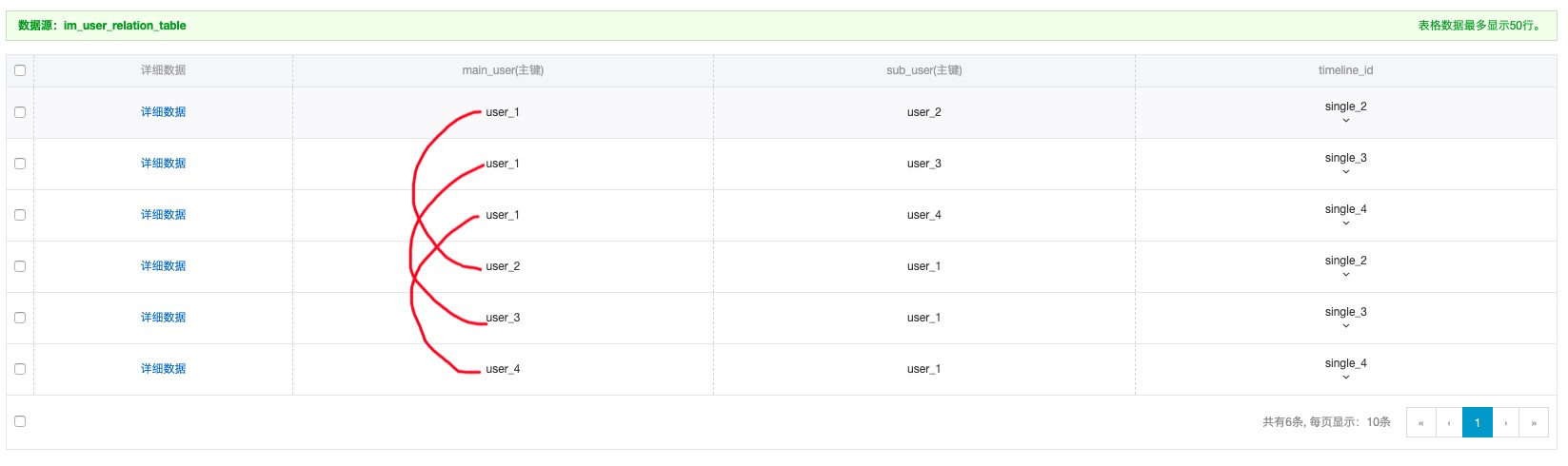
基于該單聊關系表,還可以建立多元索引,方便用戶好友列表的獲取,同時支持根據添加好友時間排序、昵稱排序等功能。如果考慮到延時和費用等因素,直接通過getRange接口也可以快速拉、高效的獲取自己所有好友列表,實現好友關系的維護與查詢。
功能:人與人的關系
基于上表im_user_relation_table,人與人的關系可以很簡單實現,例如判斷我與小明的好友關系,直接通過單行查詢即可知道好友關系是否存在,如果存在就不會展示加好友按鈕。而如果非好友,待完成好友添加后,寫入兩行不同主鍵順序行,并生成一個唯一的timelineId即可。如此設計的好處在于用戶可以直接通過自己的ID與好友的ID快速獲取會話信息。只要用戶在寫入兩行時做好一致性維護。
如果好友關系一旦解除,可以直接拼出關系表中兩行主鍵對用戶關系,通過做物理刪除(刪除行)或邏輯刪除(屬性列狀態修改)結束兩個人的好友關系即可。
核心代碼
public void establishFriendship(String userA, String userB, String timelineId) {
PrimaryKey primaryKeyA = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userA))
.addPrimaryKeyColumn("sub_user", PrimaryKeyValue.fromString(userB))
.build();
RowPutChange rowPutChangeA = new RowPutChange(userRelationTable, primaryKeyA);
rowPutChangeA.addColumn("timeline_id", ColumnValue.fromString(timelineId));
PrimaryKey primaryKeyB = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userB))
.addPrimaryKeyColumn("sub_user", PrimaryKeyValue.fromString(userA))
.build();
RowPutChange rowPutChangeB = new RowPutChange(userRelationTable, primaryKeyB);
rowPutChangeB.addColumn("timeline_id", ColumnValue.fromString(timelineId));
BatchWriteRowRequest request = new BatchWriteRowRequest();
request.addRowChange(rowPutChangeA);
request.addRowChange(rowPutChangeB);
syncClient.batchWriteRow(request);
}
public void breakupFriendship(String userA, String userB) {
PrimaryKey primaryKeyA = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userA))
.addPrimaryKeyColumn("sub_user", PrimaryKeyValue.fromString(userB))
.build();
RowDeleteChange rowPutChangeA = new RowDeleteChange(userRelationTable, primaryKeyA);
PrimaryKey primaryKeyB = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userB))
.addPrimaryKeyColumn("sub_user", PrimaryKeyValue.fromString(userA))
.build();
RowDeleteChange rowPutChangeB = new RowDeleteChange(userRelationTable, primaryKeyB);
BatchWriteRowRequest request = new BatchWriteRowRequest();
request.addRowChange(rowPutChangeA);
request.addRowChange(rowPutChangeB);
syncClient.batchWriteRow(request);
}
群聊關系
功能:群聊會話與人的關系
群聊時,主要的查詢需求還是獲取當前群內用戶的列表。一方面方便群屬性的展示,另一方面為應用做寫擴散提供快速獲取收件人列表的查詢。因而在表設計上,我們會建議用戶使用兩列主鍵:第一列為群ID,第二列為用戶ID。通過這樣的設計,可以直接給予getRange接口拉取群所有用戶的信息。
群聊關系表解決了群到用戶的映射關系,但我們還需要用戶到群的映射關系。如果為了查詢用戶所在群的列表而新建一張表,冗余成本、一致性維護成本就很高。這里可以使用兩種索引來解決反向的映射關系。樣例中,我們使用了二級索引,將用戶ID字段作為索引主鍵,從而可以直接基于索引查詢單用戶的群列表。同步實時性更好,成本更低。當然用戶也可以使用多元索引:對群、用戶、入群時間做索引,可以查詢到某用戶的所有在群列表,并且基于入群時間排序。
表設計:im_group_relation_table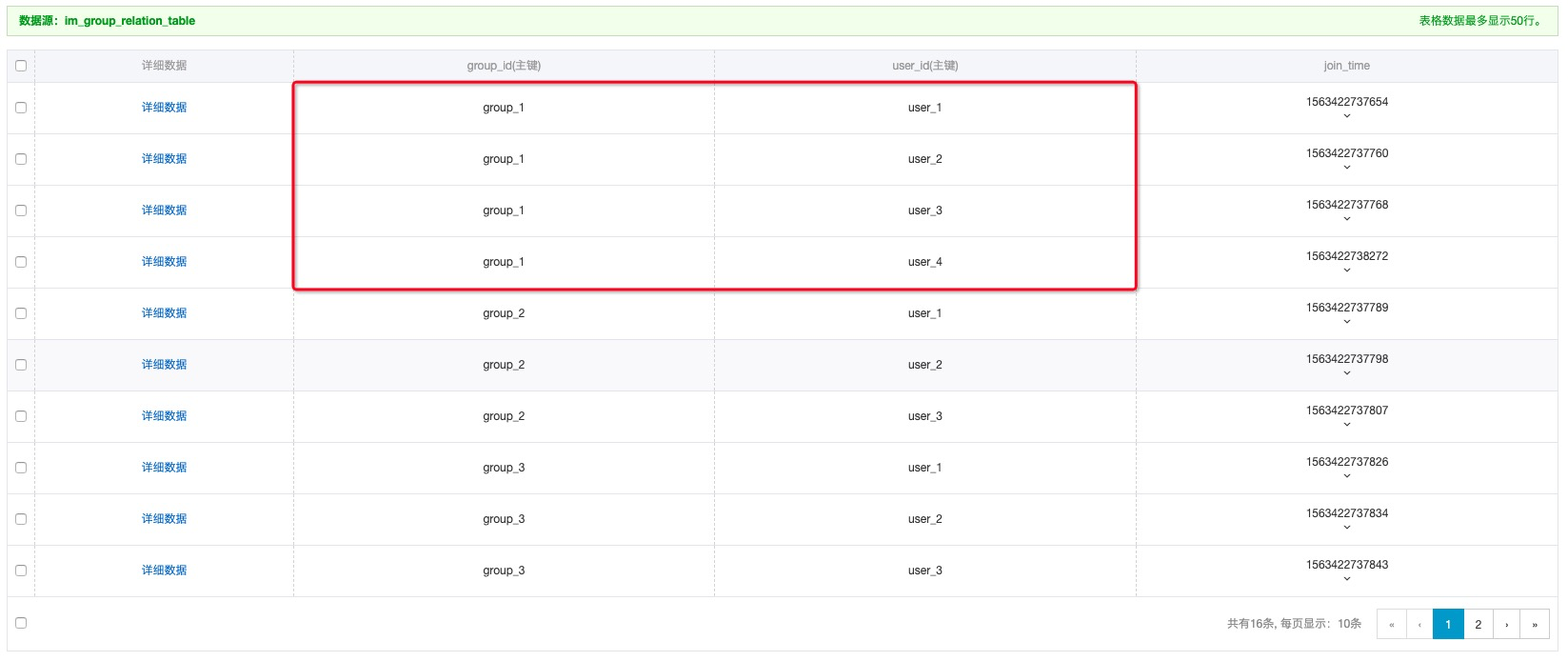
基于群關系表,可以直接基于關系主表通過getRange的方式獲取單個群內所有的用戶。在做寫擴散時,可以直接獲取群內用戶ID列表,提升寫擴散的效率。同時,也方便展示群內用戶列表。
核心代碼
public List<Conversation> listMySingleConversations(String userId) {
PrimaryKey start = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userId))
.addPrimaryKeyColumn("sub_user", PrimaryKeyValue.INF_MIN)
.build();
PrimaryKey end = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userId))
.addPrimaryKeyColumn("sub_user", PrimaryKeyValue.INF_MAX)
.build();
RangeRowQueryCriteria criteria = new RangeRowQueryCriteria(userRelationTable);
criteria.setInclusiveStartPrimaryKey(start);
criteria.setExclusiveEndPrimaryKey(end);
criteria.setMaxVersions(1);
criteria.setLimit(100);
criteria.setDirection(Direction.FORWARD);
criteria.addColumnsToGet(new String[] {"timeline_id"});
GetRangeRequest request = new GetRangeRequest(criteria);
GetRangeResponse response = syncClient.getRange(request);
List<Conversation> singleConversations = new ArrayList<Conversation>(response.getRows().size());
for (Row row : response.getRows()) {
String timelineId = row.getColumn("timeline_id").get(0).getValue().asString();
String subUserId = row.getPrimaryKey().getPrimaryKeyColumn("sub_user").getValue().asString();
User friend = describeUser(subUserId);
Conversation conversation = new Conversation(timelineId, friend);
singleConversations.add(conversation);
}
return singleConversations;
} 功能:人與群聊會話的關系
功能:人與群聊會話的關系
獲取單用戶所有加入群列表,可以基于主表創建二級索引,將用戶字段設為索引的第一列主鍵。索引的數據結構見下圖。這樣基于二級索引,可以直接通過getRange的方式獲取單用戶加入的群的TimlineId列表。
二級索引:im_group_relation_global_index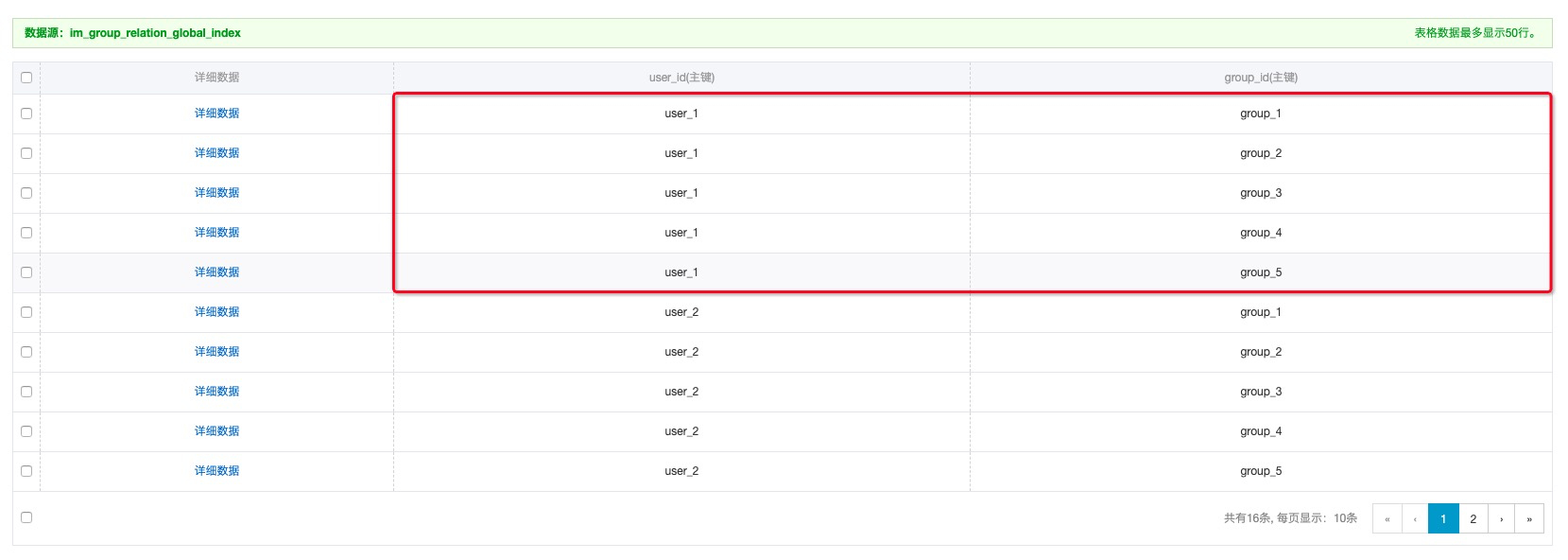
核心代碼
public List<Conversation> listMyGroupConversations(String userId) {
PrimaryKey start = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("user_id", PrimaryKeyValue.fromString(userId))
.addPrimaryKeyColumn("group_id", PrimaryKeyValue.INF_MIN)
.build();
PrimaryKey end = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("user_id", PrimaryKeyValue.fromString(userId))
.addPrimaryKeyColumn("group_id", PrimaryKeyValue.INF_MAX)
.build();
RangeRowQueryCriteria criteria = new RangeRowQueryCriteria(groupRelationGlobalIndex);
criteria.setInclusiveStartPrimaryKey(start);
criteria.setExclusiveEndPrimaryKey(end);
criteria.setMaxVersions(1);
criteria.setLimit(100);
criteria.setDirection(Direction.FORWARD);
criteria.addColumnsToGet(new String[] {"group_id"});
GetRangeRequest request = new GetRangeRequest(criteria);
GetRangeResponse response = syncClient.getRange(request);
List<Conversation> groupConversations = new ArrayList<Conversation>(response.getRows().size());
for (Row row : response.getRows()) {
String timelineId = row.getPrimaryKey().getPrimaryKeyColumn("group_id").getValue().asString();
Group group = describeGroup(timelineId);
Conversation conversation = new Conversation(timelineId, group);
groupConversations.add(conversation);
}
return groupConversations;
} 即時感知
即時感知
讓客戶端即時感知消息的實現方案,請參見Feed流設計總綱中會話池的維護方式,此處僅做簡要描述,不會在樣例中實現。
會話池方案
即時感知新消息正是IM(Instant Message)場景下核心所在。讓客戶端及時感知到新信息的到來,然后客戶端接收到通知后才會從同步庫中拉取更新的消息,讓用戶更快速、更及時地提醒用戶閱讀新消息。可是,接受者如何才能快速感知到自己有了新消息呢?
讓在線的客戶端周期性的刷新拉取?這樣的方式毫無疑問可以滿足需求,但伴隨而來的是大量無效的網絡資源浪費。同時應用的壓力也會隨著用戶量的不斷增長變得更沉重。而當白天大量非活躍用戶在線時,壓力更為明顯。面對這一問題,應用通常會維護一個推送會話池。會話池記錄了在線客戶端與用戶信息,當在線用戶有新的消息寫入,通過推送池獲取該用戶的會話,然后通知客戶端拉取同步庫新消息。這樣同步消息的壓力只會隨著真實消息量而增長,避免了大量不必要的同步庫查詢請求。
實現會話推送池的方案很多,可以使用內存型數據庫,也可以直接使用表格存儲,同時保證會話推送池的持久化。
在即時感知上,最直觀的就是會話表中變動的未讀消息數統計了。統計新消息的實現方式上,已在本文的【消息存儲 > 第二類:同步庫 > 新消息即時統計】部分做了詳盡描述,不理解的可返回去重新看一下。持久化未讀消息數是很必要的,否則在更換設備或重新登錄后。未讀消息數被清零,將會忽略很多新消息提醒,這是我們不能接受的。
多端同步
實現了以上功能,IM系統的基本需求已經完成。但實現多端數據同步上,還有兩個注意事項。
其一,我們對于單客戶端情況下,用戶同步庫做了一個checkpoint點的持久化,對應的概念是:“已讀最新消息的sequenceId”。此時,checkpoint點無客戶端的區分,如果使用本地做持久化,多端同步時就會出現問題,不同客戶端統計的未讀消息數就會不一致。這是需要通過應用服務端維護checkpoint點,同時會話的未讀消息數也需要在應用服務側維護,這樣才能保證多端統計數一致。同時,當有未讀消息的會話被點擊,會話未讀數清0時,要讓服務有感知,然后通知到其他在線端,維護實時一致性。
其二,多端情況下,自己在一個客戶端發送了新消息,其他客戶端在沒有其他新消息時,是無法感知并刷新自己的發送消息,這在多端同步中也是要解決的小問題。這時,簡單的解決方案就是將自己發送的消息,也寫入自己的同步庫。只要在統計未讀信息時,對自己的信息不計數,但在最新消息摘要中需要做更新。這樣,多端同步問題很容易實現。
添加好友、入群申請
添加好友或入群,不是主動發起請求就會直接完成的,這里需要主動方申請后,審核方完成同意才會真實完成。因而只有在審核方才會有權限發起關系的創建。
那如何讓被添加用戶或群主感知到申請?當然是借助同步庫,作為一種新的消息類型或者特殊的會話,讓用戶即時感知到新申請,盡早完成審批。申請列表如果需要持久化,也可單獨建表維護,只要保證用戶新申請的即時感知即可。
樣例實操
本文為了與用戶一起梳理IM系統應用的功能點,基于Tablestore實現的樣例簡單功能,完整的樣例代碼已完成開源,代碼地址源碼鏈接。用戶可以結合文章、代碼一起閱讀。代碼在本地運行,使用前請確保您已經完成了以下操作:
已開通表格存儲服務并創建實例
獲取AccessKey
設置樣例配置文件
實例支持二級索引
樣例配置
在home目錄下創建tablestoreCong.json文件,填寫相應參數如下:
# mac或linux系統下:/home/userhome/tablestoreCong.json
# windows系統下: C:\Documents and Settings\%用戶名%\tablestoreCong.json
{
"endpoint": "http://instanceName.cn-hangzhou.ots.aliyuncs.com",
"accessId": "***********",
"accessKey": "***********************",
"instanceName": "instanceName"
}endpoint:實例的接入地址,可在表格存儲管理控制臺實例詳情頁獲取。
accessId:AccessKey ID。具體操作,請參見如何獲取AccessKey。
accessKey:AccessKey的密碼。具體操作,請參見如何獲取AccessKey。
instanceName:使用的實例名稱。
樣例入口
樣例中總共有三個入口,用戶需要根據先后順序執行,使用后及時釋放資源,避免不必要的費用開銷。
入口 | 入口類名 | 功能 |
初始化 | InitChartRoomExample | 創建所有需要的表,同時根據配置創建相應的多元索引與二級索引。 |
模擬調用 | ClientRequestExample | 應用的接口使用,樣例未做前后端聯調調用,您可以通過接口返回數據的打印了解使用方式。 |
資源釋放 | ReleaseChartRoomExample | 釋放所有資源,先釋放索引后刪除表。 |
項目結構
技術支持
表格存儲為您提供專業的免費的技術咨詢服務,歡迎通過釘釘加入相應交流群。
為互聯網應用、大數據、社交應用等開發者提供的最新技術交流群有36165029092(
表格存儲技術交流群-3)。說明表格存儲用戶群11789671(
表格存儲技術交流群)和23307953(表格存儲技術交流群-2)已滿,暫時無法加入。
為物聯網和時序模型開發者提供的技術交流群有44327024(
物聯網存儲 IoTstore 開發者交流群)。