Hive
本文主要介紹如何使用DLA Spark訪問用戶VPC中的Hive集群。
云原生數(shù)據(jù)湖分析(DLA)產(chǎn)品已退市,云原生數(shù)據(jù)倉庫 AnalyticDB MySQL 版湖倉版支持DLA已有功能,并提供更多的功能和更好的性能。AnalyticDB for MySQL相關(guān)使用文檔,請(qǐng)參見訪問Hive數(shù)據(jù)源。
前提條件
您已開通數(shù)據(jù)湖分析DLA(Data Lake Analytics)服務(wù),如何開通,請(qǐng)參見開通云原生數(shù)據(jù)湖分析服務(wù)。
您已登錄云原生數(shù)據(jù)庫分析DLA控制臺(tái),在云原生數(shù)據(jù)湖分析DLA控制臺(tái)上創(chuàng)建了Spark虛擬集群。

您已開通對(duì)象存儲(chǔ)OSS(Object Storage Service)服務(wù)。如何開通,請(qǐng)參見開通OSS服務(wù)
準(zhǔn)備創(chuàng)建Spark計(jì)算節(jié)點(diǎn)所需要的交換機(jī)ID和安全組ID,可以選擇已有的交換機(jī)和安全組,也可以新建交換機(jī)和安全組。交換機(jī)和安全組需要滿足以下條件:
交換機(jī)需要與您的Hive服務(wù)集群在同一VPC下。可使用您Hive集群控制臺(tái)上的交換機(jī)ID。
安全組需要與您的Hive服務(wù)集群在同一VPC下。您可以前往ECS管理控制臺(tái)-網(wǎng)絡(luò)與安全-安全組按照專有網(wǎng)絡(luò)(VPC)ID搜索該VPC下的安全組,任意選擇一個(gè)安全組ID即可。
如果您的Hive服務(wù)有白名單控制,需要您將交換機(jī)網(wǎng)段加入到您Hive服務(wù)的白名單中。
操作步驟
如果您的Hive元數(shù)據(jù)使用的是獨(dú)立的RDS且表數(shù)據(jù)存放在OSS中,則可以使用下列配置并跳過后續(xù)步驟,否則請(qǐng)您從第二步開始配置。
{ "name": "spark-on-hive", "className": "com.aliyun.spark.SparkHive", #連接Hive的測試代碼,按需修改名稱 "jars": [ "oss://path/to/mysql-connector-java-5.1.47.jar" ], "conf": { "spark.dla.eni.vswitch.id": "<交換機(jī)ID>", "spark.dla.eni.security.group.id": "<安全組ID>", "spark.dla.eni.enable": "true", "spark.driver.resourceSpec": "medium", "spark.dla.connectors": "oss", "spark.executor.instances": 1, "spark.sql.catalogImplementation": "hive", "spark.executor.resourceSpec": "medium", "spark.hadoop.javax.jdo.option.ConnectionDriverName": "com.mysql.jdbc.Driver", "spark.hadoop.javax.jdo.option.ConnectionUserName": "<hive_user_name>", #Hive RDS的用戶名 "spark.hadoop.javax.jdo.option.ConnectionPassword": "<your_pass_word>", #Hive RDS的密碼 "spark.hadoop.javax.jdo.option.ConnectionURL": "<jdbc連接>", #Hive RDS 的jdbc鏈接 "spark.dla.job.log.oss.uri": "<日志目錄路徑>" }, "file": "<oss://主資源Jar包路徑>" }說明jars中指定的Jar包是MySQL的jdbc連接器,可從官方Maven倉庫,并上傳到oss。
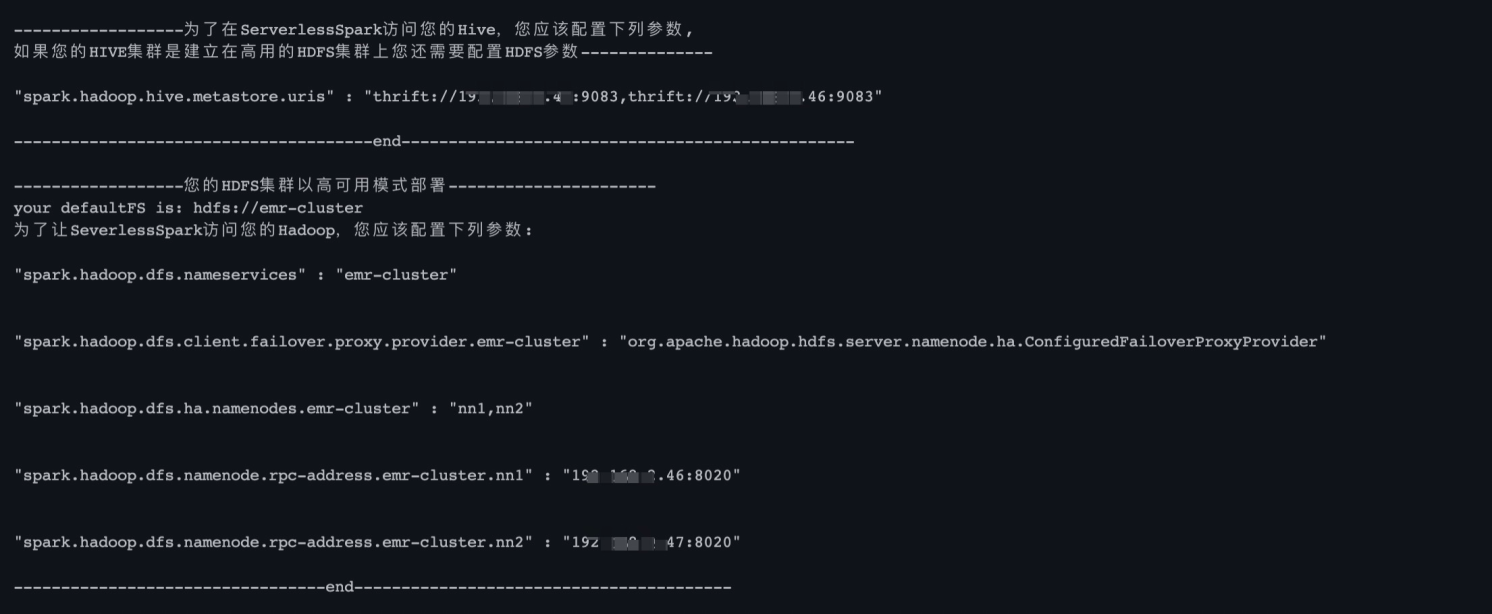
獲取需要在DLA Spark配置的Hive相關(guān)參數(shù)。
說明如果您無法在您的Hive服務(wù)所在的集群中執(zhí)行spark作業(yè),可以跳過這步。
我們提供了工具來讀取你Hive服務(wù)所在的集群的配置,您可以按照下面的地址下載
spark-examples-0.0.1-SNAPSHOT-shaded.jar并上傳至OSS, 然后提交Spark作業(yè)到您的Hive服務(wù)所在集群上執(zhí)行,即可在作業(yè)輸出中獲得訪問您Hive集群所需的配置。wget https://dla003.oss-cn-hangzhou.aliyuncs.com/GetSparkConf/spark-examples-0.0.1-SNAPSHOT-shaded.jarEMR集群用戶將Jar包上傳至OSS后,可以通過以下命令提交作業(yè)到EMR集群獲取配置作業(yè):
--class com.aliyun.spark.util.GetConfForServerlessSpark --deploy-mode client ossref://{path/to}/spark-examples-0.0.1-SNAPSHOT-shaded.jar get hive hadoop作業(yè)運(yùn)行完畢后,可以通過SparkUI查看driver的stdout輸出或者從作業(yè)詳情中的提交日志中查看輸出的配置。
云Hbase-Spark用戶可以將Jar包上傳至資源管理目錄后,用以下命令提交獲取配置作業(yè):
--class com.aliyun.spark.util.GetConfForServerlessSpark /{path/to}/spark-examples-0.0.1-SNAPSHOT-shaded.jar get hive hadoop等待作業(yè)完成后,通過SparkUI的driver中的stdout查看輸出配置。
其他Hive集群,如果您在集群上未設(shè)置
HIVE_CONF_DIR環(huán)境變量,則需要手動(dòng)輸入HIVE_CONF_DIR路徑。--class com.aliyun.spark.util.GetConfForServerlessSpark --deploy-mode client /{path/to}/spark-examples-0.0.1-SNAPSHOT-shaded.jar get --hive-conf-dir </path/to/your/hive/conf/dir> hive hadoop
編寫訪問Hive的SparkApplication。
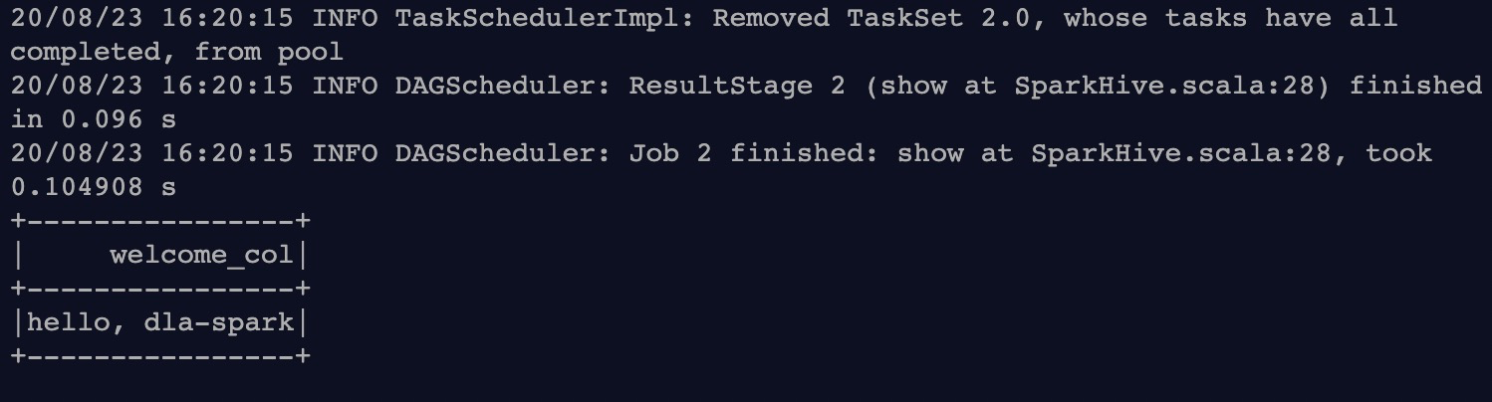
以下示例代碼可以首先根據(jù)用戶傳入的表名,在用戶
default namespace創(chuàng)建一個(gè)表,該表只有一列字符串類型的數(shù)據(jù),內(nèi)容為hello, dla-spark,然后從該表讀出這一列數(shù)據(jù),并打印到stdout:package com.aliyun.spark import org.apache.spark.sql.SparkSession object SparkHive { def main(args: Array[String]): Unit = { val sparkSession = SparkSession .builder() .appName("Spark HIVE TEST") .enableHiveSupport() .getOrCreate() val welcome = "hello, dla-spark" //Hive表名 val tableName = args(0) import sparkSession.implicits._ //將只有一行一列數(shù)據(jù)的DataFrame: df 存入到Hive, 表名為用戶傳進(jìn)來的tableName, 列名為welcome_col val df = Seq(welcome).toDF("welcome_col") df.write.format("hive").mode("overwrite").saveAsTable(tableName) //從Hive中讀取表 tableName val dfFromHive = sparkSession.sql( s""" |select * from $tableName |""".stripMargin) dfFromHive.show(10) } }將SparkApplication Jar包和依賴上傳至OSS中。
詳情請(qǐng)參見控制臺(tái)上傳文件。
說明OSS所在的region和Serverless Spark所在的region需要保持一致。
在DLA Spark中提交作業(yè)并進(jìn)行計(jì)算。
訪問Hive,如果您集群中的HDFS是以高可用部署(即您的集群有一個(gè)以上Master節(jié)點(diǎn)/NameNode),詳情請(qǐng)參見創(chuàng)建和執(zhí)行Spark作業(yè)和作業(yè)配置指南。
{ "args": [ "hello_dla" ], "name": "spark-on-hive", "className": "com.aliyun.spark.SparkHive", "conf": { "spark.sql.catalogImplementation":"hive", "spark.dla.eni.vswitch.id": "{您的交換機(jī)ID}", "spark.dla.eni.security.group.id": "{您的安全組ID}", "spark.dla.eni.enable": "true", "spark.driver.resourceSpec": "medium", "spark.executor.instances": 1, "spark.executor.resourceSpec": "medium", "spark.dla.job.log.oss.uri": "oss://<指定您存放SparkUI日志的目錄/>", "spark.hadoop.hive.metastore.uris":"thrift://${ip}:${port},thrift://${ip}:${port}", "spark.hadoop.dfs.nameservices":"{您的nameservices名稱}", "spark.hadoop.dfs.client.failover.proxy.provider.${nameservices}":"{您的failover proxy provider實(shí)現(xiàn)類全路徑名稱}", "spark.hadoop.dfs.ha.namenodes.${nameservices}":"{您的nameservices所屬namenode列表}", "spark.hadoop.dfs.namenode.rpc-address.${nameservices}.${nn1}":"namenode0所屬的ip:port", "spark.hadoop.dfs.namenode.rpc-address.${nameservices}.${nn2}":"namenode1所屬的ip:port" }, "file": "oss://{您的Jar包所屬的oss路徑}" }參數(shù)說明如下:
參數(shù)
說明
備注
spark.hadoop.hive.metastore.uris
配置訪問HiveMetaStore的Uri,對(duì)應(yīng)${HIVE_CONF_DIR}/hive-site.xml中的hive.metastore.uris配置項(xiàng)。注意,一般該配置項(xiàng)的值都是域名:端口的形式,用戶在serverless spark中配置參數(shù)的時(shí)候需要將它替換為對(duì)應(yīng)IP+端口的形式。
域名和IP的映射關(guān)系,一般可以登錄集群的master節(jié)點(diǎn)查看本機(jī)的/etc/hosts,或者在master節(jié)點(diǎn),直接使用ping+域名的方式獲取,您也可以采用步驟2獲取對(duì)應(yīng)的配置參數(shù)。
spark.dla.eni.vswitch.id
您的交換機(jī)ID。
無
spark.dla.eni.security.group.id
您的安全組ID。
無
spark.dla.eni.enable
控制開啟或關(guān)閉ENI。
無
spark.hadoop.dfs.nameservices
對(duì)應(yīng)hdfs-site.xml中的dfs.nameservices
無
spark.dla.job.log.oss.uri
指定您存放SparkUI日志的OSS目錄
無
spark.hadoop.dfs.client.failover.proxy.provider.${nameservices}
對(duì)應(yīng)hdfs-site.xml中的dfs.client.failover.proxy.provider.${nameservices}
無
spark.hadoop.dfs.ha.namenodes.${nameservices}
對(duì)應(yīng)hdfs-site.xml中的dfs.ha.namenodes.${nameservices}
無
spark.hadoop.dfs.namenode.rpc-address.${nameservices}.${nn1/nn2}
對(duì)應(yīng)hdfs-site.xml中的dfs.namenode.rpc-address.${nameservices}.${nn1/nn2}
注意該配置項(xiàng)應(yīng)該寫成IP:端口的形式,用戶可以通過用戶集群master節(jié)點(diǎn)中的/etc/hosts文件查看域名和IP的對(duì)應(yīng)關(guān)系或者在master節(jié)點(diǎn),直接使用ping+域名的方式獲取,您也可以采用步驟2獲取對(duì)應(yīng)的配置參數(shù)。
作業(yè)運(yùn)行成功后,單擊,查看作業(yè)日志。
訪問Hive, 如果您集群中的HDFS是以非高可用部署的(即只有一個(gè)Master節(jié)點(diǎn)/NameNode)。
{ "args": [ "hello_dla" ], "name": "spark-on-hive", "className": "com.aliyun.spark.SparkHive", "conf": { "spark.sql.catalogImplementation":"hive", "spark.dla.eni.vswitch.id": "{您的交換機(jī)ID}", "spark.dla.eni.security.group.id": "{您的安全組ID}", "spark.dla.eni.enable": "true", "spark.driver.resourceSpec": "medium", "spark.executor.instances": 1, "spark.executor.resourceSpec": "medium", "spark.dla.job.log.oss.uri": "oss://<指定您存放SparkUI日志的目錄/>"," "spark.hadoop.hive.metastore.uris":"thrift://${ip}:${port},thrift://${ip}:${port}", "spark.dla.eni.extra.hosts":"${ip0} ${hostname_0} ${hostname_1} ${hostname_n}" }, "file": "oss://{您的Jar包所屬的oss路徑}" }參數(shù)
說明
備注
spark.hadoop.hive.metastore.uris
配置訪問HiveMetaStore的Uri,對(duì)應(yīng)${HIVE_CONF_DIR}/hive-site.xml中的hive.metastore.uris配置項(xiàng)。注意,一般該配置項(xiàng)的值都是域名+端口的形式,用戶在serverless spark中配置參數(shù)的時(shí)候需要將它替換為對(duì)應(yīng)ip:端口的形式。
域名和IP的映射關(guān)系,一般可以登錄集群的master節(jié)點(diǎn)查看本機(jī)的/etc/hosts, 或者在master節(jié)點(diǎn),直接使用ping + 域名的方式獲取,用戶也可以采用步驟1獲取對(duì)應(yīng)的配置參數(shù)。
spark.dla.job.log.oss.uri
指定您存放SparkUI日志的OSS目錄
無
spark.dla.eni.vswitch.id
您的交換機(jī)ID
無
spark.dla.eni.security.group.id
您的安全組ID
無
spark.dla.eni.enable
控制開啟或關(guān)閉ENI
無
spark.dla.eni.extra.hosts
Spark解析Hive表位置時(shí),需要額外傳入IP和表格存儲(chǔ)節(jié)點(diǎn)host的映射關(guān)系,以便Spark能正確解析位置的域名信息。
重要IP和域名之間用空格隔開。多個(gè)IP 和域名用逗號(hào)隔開,如 "ip0 master0, ip1 master1"
該值可從用戶集群${Hive_CONF_DIR}/core-site.xml的fs.defaultFS獲取。示例用戶fs.defaultFs的值為: "hdfs://master-1:9000", 則需要配置spark.dla.eni.extra.hosts的值為:"${master-1的ip} master-1"。IP和域名的對(duì)應(yīng)關(guān)系,您可以登錄自建集群的master節(jié)點(diǎn),從/etc/hosts中查看IP和域名的對(duì)應(yīng)關(guān)系。您也可以從步驟2中獲取相關(guān)參數(shù)。