Lindorm寬表支持Tabular模型下的二級索引功能,此功能在非主鍵匹配的查詢場景下,可以降低應用的開發復雜性、保證數據的一致性和提高寫入效率。本文介紹Lindorm Tabular模型下二級索引的基本特性和使用示例。
背景信息
對于Lindorm Tabular模型,Lindorm寬表有表結構且表對應的列有類型預定義的。Lindorm原生二級索引功能在阿里云應用多年,經歷了多次雙11的考驗,更加適用于解決海量數據的全局索引。Lindorm與Phoenix在索引場景下的性能對比如下圖所示。
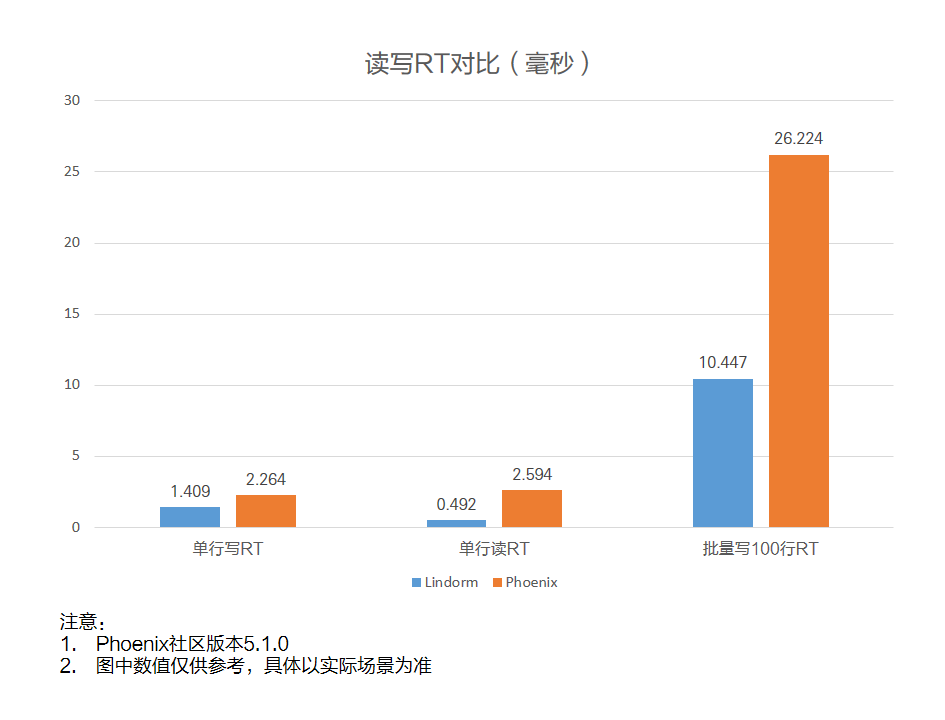
讀寫RT對比
產品
單行寫RT
單行讀RT
批量寫100行RT
Lindorm
1.409
0.492
10.447
開源Phoenix
2.264
2.594
26.224
可以看出,在索引場景下Lindorm進行讀寫操作耗時更少。單行寫RT用時約為開源Phoenix的62%,單行讀RT用時約為開源Phoenix的19%,批量寫100行RT約為開源Phoenix的40%。
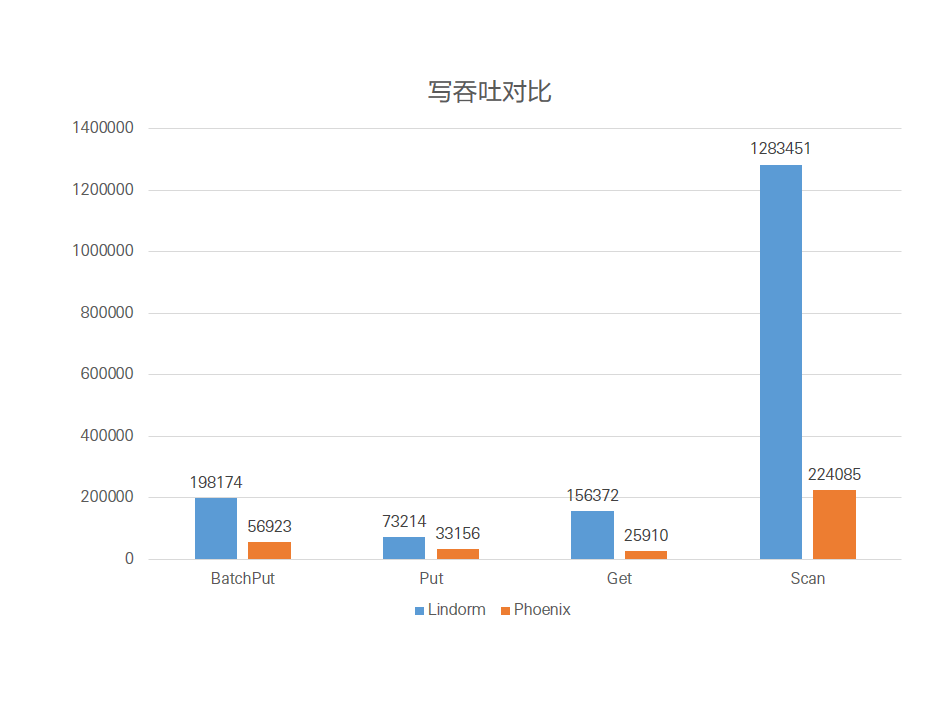
寫吞吐對比
產品
BatchPut
Put
Get
Scan
Lindorm
198174
73214
156372
1283451
開源Phoenix
56923
33156
25910
224085
可以看出,在索引場景下Lindorm的BatchPut約為開源Phoenix的3.5倍,Put約為開源Phoenix的2.2倍,Get約為開源Phoenix的6倍,Scan約為開源Phoenix的5.7倍。
特性介紹
Lindorm二級索引支持為單表建多個索引,每個索引在物理上映射為一張數據表,與主表相互獨立,每個索引有不同的存儲策略(如采用不同的壓縮算法、冷熱分離策略)等屬性。寫主表時,Lindorm會自動更新所有索引表,并確保主表和索引表數據的一致性。讀數據時,您只需針對主表發起查詢,Lindorm會根據WHERE條件和SCHEMA自動選擇合適的索引(包括主表)執行查詢操作(支持HINT來干預優化器行為)。Lindorm二級索引的基本特性如下。
支持單個主表建多個索引。
支持組合索引(單列和多列)。
支持冗余索引,全冗余索引可自動冗余主表新增的列。
查詢優化:根據WHERE語句自動選擇索引,支持HINT來干預優化器的選擇。
Online Schema Change:索引變更不影響主表的正常讀寫,可以隨時新增、刪除、更新索引。
支持數據有效期(簡稱:TTL):索引表自動繼承主表的TTL設置,主表和索引表數據同時過期。
支持動態列:支持寫入動態列和冗余動態列。
支持自定義數據版本:自定義時間戳后自動寫入數據。
使用要求
服務器:使用Lindorm實例。
客戶端:更多信息,請參見通過Lindorm寬表SQL使用寬表引擎。
Lindorm-Cli客戶端:更多信息,請參見通過Lindorm-cli連接并使用寬表引擎。
基本概念
強一致性:是指主表和索引表的數據一致性。為了滿足數據一致性的需求,最大程度減少二級索引的額外開銷,提升高吞吐的寫入能力,Lindorm二級索引在強一致性中具有如下約束。
不支持快照隔離性。在數據寫入過程中不保證同時可見,但是返回客戶端寫入成功后主表和索引表數據可見。
在返回客戶端超時或IO出錯情況下,該數據在主表和索引表中不保證可見,但最終主表和索引表數據會保持一致。
可選的索引組織成本:在主表有一個索引的情況下,寫放大有四次操作(讀主表,刪除索引老數據,寫索引,寫主表),會大大增加維護索引的成本。但不是所有場景都會產生寫放大,比如日志場景只有數據插入沒有更新操作,此時索引表不存在老數據,只需要做寫索引和寫主表操作。所以Lindorm提出了Mutability的概念。Mutability是指對主表的寫入模式進行分類,并以此組織索引數據,針對不同的需求實現最低的索引組織成本。Mutability分類和描述如下表所示。Mutability屬性需要在創建表或修改表時通過Table_Options參數進行設置,具體操作,請參見CREATE TABLE語法介紹。
Mutability分類
約束
操作成本
操作說明
無索引
無。
1
沒有索引的情況下,直接寫主表,為1次操作。
IMMUTABLE
整行寫入,不可更新或刪除。
2
寫主表,寫索引表。所有場景中成本最低,性能最好。
IMMUTABLE_ROWS
整行寫入,整行刪除,不可更新。
2~3
正常寫入時:寫主表,寫索引表。在刪除場景下需額外讀一次主表。性能僅次于IMMUTABLE。
MUTABLE_LATEST
可更新,可刪除。
4
讀主表,刪索引,寫索引,寫主表。
MUTABLE_ALL
無限制,可使用自定義時間戳寫入。
4
讀主表,刪索引,寫索引,寫主表。
說明IMMUTABLE和IMMUTABLE_ROWS不涉及數據更新,無寫放大問題,成本最低。適合高吞吐寫的場景,如日志、監控等。
IMMUTABLE不涉及刪除,所以可充分利用Lindorm的多IDC部署,實現多活的數據訪問。
選擇兩類IMMUTABLE可以有效降低索引場景下的寫時延,提高整體吞吐。實際的業務中,如果不滿足IMMUTABLE場景,可以通過數據冗余來改造成IMMUTABLE場景。
更新自定義時間戳的索引:Lindorm支持自定義時間戳進行寫入,可以在任意時間戳進行數據更新,由系統來判斷只有時間戳最大的數據生效。自定義時間戳特性在控制數據有效期、亂序、冪等等場景中發揮著重要的作用,在HBase中有廣泛的應用。Lindorm支持列級時間戳,主表支持自定義時間戳寫入數據。但在支持二級索引和時間戳的NoSQL系統中,支持自定義時間戳索引更新的,就比較罕見了。因為時間戳亂序寫入很難有效維護索引數據的更新和刪除。Lindorm全局二級索引解決了這個問題,支持列級別自定義時間戳更新。下面是兩個使用自定義時間戳的實際業務場景。
導入與實時并存:在需要同時實時更新和歷史數據導入的場景下,實時更新可以使用當前時間,而歷史數據導入可以使用昨天23:59:59這個時間。所以當天未更新過的數據可以通過導入操作而更新,已更新過的數據也不會被導入覆蓋。
追消息:業務系統通過消息來觸發一系列處理邏輯,在消息出現積壓時,系統可以跳過積壓的消息,直接處理當前消息,并在事后通過追消息來處理之前積壓的任務。或者,當業務邏輯有問題時,系統也可以跳過一部分消息來規避問題,在業務修復后重新處理。此時,業務可以通過使用消息本身的時間來寫入數據,以此來保證追的消息和正常消息的準確覆蓋關系。
全冗余索引:為了避免查詢索引之后再回查主表,通常會在索引表中冗余一部分主表列,也稱為冗余索引或覆蓋索引。全冗余索引是比較常用的冗余方案。Lindorm支持三種冗余模式,可以在主表Schema變化以及動態列場景下簡單的實現全冗余索引。
冗余指定的列:顯式指定要冗余主表的哪些列。
冗余主表Schema中的所有列:當您需要全冗余索引時,不需要在CREATE INDEX中將主表的每一列都顯式添加進來,而是通過一個常量來描述冗余所有列,當主表新增列時,全冗余索引表會自動冗余這個新增列,無需重建索引。也無需擔心新增列的查詢會導致回查主表了。
冗余動態列:Lindorm支持固定Schema和松散Schema(即動態列)。通過DYNAMIC冗余模式,索引表能夠自動冗余主表中的所有動態列,也會冗余主表Schema中的所有列。
語法參考
二級索引的語法詳細說明,請參見以下文檔:
創建二級索引:CREATE INDEX。
修改二級索引:ALTER INDEX。
查看二級索引:SHOW INDEX。
構建二級索引:BUILD INDEX。
刪除二級索引:DROP INDEX
創建二級索引
創建完Lindorm主表后,可以為主表的相應列創建二級索引。以下是創建二級索引的示例。
-- 創建主表
CREATE TABLE test (
p1 VARCHAR NOT NULL,
p2 INTEGER NOT NULL,
c1 BIGINT,
c2 DOUBLE,
c3 VARCHAR,
c5 GEOMETRY(POINT),
PRIMARY KEY(p1, p2)
) WITH (CONSISTENCY = 'strong', MUTABILITY='MUTABLE_LATEST');
-- 對c3列創建二級索引,冗余所有列
CREATE INDEX idx1 ON test(c3 desc) WITH (INDEX_COVERED_TYPE ='COVERED_ALL_COLUMNS_IN_SCHEMA');
-- 基于索引表進行查詢,因為對c3構建索引,當指定c3進行查詢會對應命中索引表
SELECT * FROM test WHERE c3 = 'data'; 創建索引有同步創建和異步創建兩種方式,在存量數據不大的情況下,可以使用同步創建。其他情況下可以使用異步創建。具體的語法請參見CREATE INDEX。
在已有數據的表中添加新的索引時,CREATE INDEX命令會同時將主表的歷史數據同步到索引表中,如果主表很大時,CREATE INDEX會非常耗時間(數據同步任務是在服務端執行的,即使刪除Lindorm Shell進程也不會影響數據同步任務)。
查看二級索引
通過Lindorm寬表SQL可以查看創建的二級索引狀態。以下是查看二級索引的示例。
SHOW INDEX FROM test;通過示例可以展示出test主表下創建的索引名和索引類型。
修改二級索引狀態
創建完二級索引后,如果主表有存量數據,需要手動對索引進行一次Rebuild操作,具體語法請參見BUILD INDEX;若主表沒有存量數據,則可以直接使用修改二級索引語法來修改二級索引表狀態。以下是修改二級索引狀態的示例:
ALTER INDEX IF EXISTS idx1 ON test ACTIVE;
ALTER INDEX idx1 ON test DISABLED;當二級索引狀態為DISABLED時,直接修改為ACTIVE狀態會導致數據缺失,因此修改前需要進行一次Rebuild操作。
刪除二級索引
通過以下示例刪除對應主表中的相關二級索引。
DROP INDEX IF EXISTS idx1 ON test;刪除索引操作需要您有Trash權限。
查詢優化
Lindorm依據RBO(Rule Based Optimization)策略進行二級索引選擇。根據查詢條件匹配索引表的前綴,選擇匹配程度最高的索引表作為本次查詢使用的索引。通過以下示例可以更好的理解。
-- 主表和索引表如下
CREATE TABLE dt (rowkey varchar, c1 varchar, c2 varchar, c3 varchar, c4 varchar, c5 varchar, PRIMARY KEY(rowkey));
CREATE INDEX idx1 ON dt (c1);
CREATE INDEX idx2 ON dt(c2,c3,c4);
CREATE INDEX idx3 ON dt(c3) INCLUDE(c1,c2,c4);
CREATE INDEX idx4 ON dt(c5 desc) WITH (INDEX_COVERED_TYPE ='COVERED_ALL_COLUMNS_IN_SCHEMA');
-- 查詢優化如下
SELECT rowkey FROM dt WHERE c1 = 'a';
SELECT rowkey FROM dt WHERE c2 = 'b' AND c4 = 'd';
SELECT * FROM dt WHERE c2 = 'b' AND c3 >= 'c' AND c3 < 'f';
SELECT * FROM dt WHERE c5 = 'c';SELECT rowkey FROM dt WHERE c1 = 'a';表示選擇索引表idx1。SELECT rowkey FROM dt WHERE c2 = 'b' AND c4 = 'd';表示選擇索引表idx2,從中查找所有滿足c2=b條件的行,然后逐行按c4=d進行過濾。雖然c4是索引列之一,但因WHERE條件中缺少c3列,無法匹配idx2的前綴。SELECT * FROM dt WHERE c2 = 'b' AND c3 >= 'c' AND c3 < 'f';表示選擇索引表idx2,由于是select *,而索引表里并未包含主表的所有列,因此在查詢索引之后,還要回查一次主表。回查主表時,回查的Rowkey可能散布在主表的各個地方,因此,可能會消耗多次RPC。回查的數據量越大,RT越長。SELECT * FROM dt WHERE c5 = 'c';表示選擇索引表idx4,idx4是全冗余索引,所以select *不需要回查主表。
使用限制
不同主表可以有同名索引,如dt表有索引Idx1,foo表也有索引Idx1,但同一主表下不允許有同名索引。
只能為Version為1的表建索引,不支持為多版本的表建索引。
對有TTL的主表建索引,不能單獨為索引表設置TTL,索引表會自動繼承主表的TTL。
索引列最多不超過3個。
索引列和主表主鍵,總長度不能超過30 KB。不建議使用大于100字節的列作為索引列。
單個主表的索引表個數最多不超過5個,過多索引會造成存儲成本過高,以及寫入耗時過長。
一次查詢最多能命中一個索引,不支持多索引聯合查詢(Index Merge Query)。
創建索引時會將主表的數據同步到索引中,對數據多的表建索引會導致Create_Index命令耗時過長。
二級索引不支持batch increase功能。
命中二級索引的排序與主表不一樣。
僅支持為通過SQL或API寫入的數據構建二級索引,不支持為Bulkload(批量導入)至Lindorm的數據構建二級索引。
問題答疑(批量導入)至
對于索引使用上的任何問題,您可以通過釘釘聯系云Lindorm答疑或工單咨詢,具體操作,請參見技術支持。