購買ECS實例之前,您需要結合性能、價格、工作負載等因素,做出性價比與穩定性最優的決策。本文主要介紹如何結合實際業務場景選購阿里云云服務器ECS。
了解實例規格族
實例規格清單:實例規格族。
實例規格族分類說明:
企業級?共享型?彈性裸金屬服務器?高性能計算?異構計算?
企業級實例是阿里云2016年9月開始推出的一系列實例規格族的總稱,具有高性能、穩定計算能力和平衡網絡性能的特點。因為具有獨享且穩定的計算、存儲、網絡資源,這些實例規格族非常適合對業務穩定性具有高要求的企業場景。
共享型實例是一系列面向一般中小網站或個人開發者的實例規格(族)總稱。與企業級實例相比,共享型實例在資源利用上更多強調資源性能的共享,所以無法保證實例計算性能的穩定,但成本相對來說也更低。
彈性裸金屬服務器融合了物理機與云服務器的優勢,實現超強、超穩的計算能力。通過阿里云自主研發的虛擬化2.0技術,您的業務應用可以直接訪問彈性裸金屬服務器的處理器和內存,無任何虛擬化開銷。彈性裸金屬服務器具備物理機級別的完整處理器特性(例如Intel VT-x),以及物理機級別的資源隔離優勢,特別適合上云部署傳統非虛擬化場景的應用。
高性能計算將計算能力積聚,用并行計算方式解決更大規模的科學、工程和商業問題。
異構計算(Heterogeneous Computing)是指使用不同類型指令集和體系架構的計算單元組成系統的計算方式,能夠讓最適合的專用硬件去服務最適合的業務場景,在特定場景下,異構計算產品比普通的云服務器高出一個甚至更多數量級的性價比和效率。
實例規格命名規則
實例規格族名稱格式為ecs.<規格族>,實例規格名稱為ecs.<規格族>.<nx>large。具體命名規則說明如下所示:
ecs:云服務器ECS的產品代號。
<規格族>:由規格族主體+規格族后綴組成。
說明以下示例僅展示實例規格族的部分常見規格的名稱含義。
x86計算規格族和ARM計算規格族
命名組成
說明
命名示例含義
規格族主體
由小寫字母+數字組成。
小寫字母:為某個單詞的縮寫,標志著實例規格族的性能領域。
數字:一般用于區分同類型規格族間的發布時間。
更大的數字代表新一代規格族,擁有更高的性價比,價格低、性能好。
c:表示計算型(computational)
處理器與內存配比為1:2,適用于數據庫、Web服務器、高性能科學和工程應用、游戲服務器、數據分析、批量計算、視頻編碼、機器學習等場景。
g:表示通用型(general)
處理器與內存配比為1:4,適用于通用互聯網應用、數據庫、Web網站、Java應用服務、游戲服務、搜索推廣、安全可信計算等場景。
u:表示通用算力型(universal)
處理器與內存配比為1:1、1:2、1:4、1:8,適用于對價格敏感的企業級客戶,主要應用于中小型和大型企業級應用、網站和應用服務器,中小型數據庫系統、緩存、搜索集群等場景。
r:表示內存型(ram)
處理器與內存配比為1:8(部分規格不為1:8),適用于內存數據庫、數據分析與挖掘、分布式內存緩存(Redis)、大數據類應用(Kafka、ElasticSearch等),以及對內存容量要求較高的通用企業級應用(Java)等場景。
re:表示內存增強型(ram enhanced)
hf(c/g/r):表示高主頻型(high frequency)
處理器與內存配比為1:2、1:4、1:8,適用于大型多人在線游戲、HPC等高性能科學計算場景,以及中大型數據庫系統等。
i:表示本地SSD型(instance family with local SSDs)
處理器與內存配比為1:4、1:8,適用于OLTP、高性能關系型數據庫、NoSQL數據庫(例如Cassandra、MongoDB等)、Elasticsearch等搜索場景以及EMR大數據存算分離場景。
d:表示大數據型(big data)
處理器與內存配比為1:4,適用于Hadoop MapReduce、HDFS、Hive、HBase等大數據計算和存儲業務場景,以及Elasticsearch、Kafka等搜索和日志數據處理場景。
s:表示共享型(share)
t:表示突發型(burst)
e:表示經濟型(economy)
例如,ecs.g6.2xlarge表示通用型g6規格族中的一個實例規格,擁有8個vCPU核。相比于g5規格族,g6為新一代通用型實例規格族。
規格族后綴
由小寫字母組成。
y:表示采用阿里云自研倚天710 ARM架構CPU(Yitian)
a:表示采用AMD CPU
ae:表示AMD增強型(AMD enhanced)
i:表示采用intel CPU
h:表示采用海光處理器
re:表示RDMA增強型(RDMA enhanced)
se:表示存儲增強型(storage enhanced)
ne:表示網絡增強型(network enhanced)
t:表示安全增強型(tpm)
p:表示持久內存型(persistent ram)
異構計算規格族、彈性裸金屬服務器、超級計算集群(SCC)實例規格族
異構計算規格族、彈性裸金屬服務器和超級計算集群(SCC)實例規格族一般采用自主命名方式,由小寫字母和數字混合組成。
命名組成
說明
命名示例含義
規格族主體
由小寫字母組成。
gn:表示搭載NVIDIA GPU的計算型實例
vgn:表示采用NVIDIA GRID vGPU加速的獨享型實例
sgn:表示采用NVIDIA GRID vGPU加速的共享型實例
gi:表示搭載Intel GPU的計算型實例
f:表示FPGA計算型實例
ebm(c/g/r/gn/hf):表示彈性裸金屬服務器(elastic bare metal)
scc(c/g/h/gn/hf):表示超級計算集群(super computing cluster)
規格族后綴
由數字或小寫字母+數字組成。
6v:6表示采用Volta/Turing架構;v表示GPU類型為V100且GPU顯存為16 GB。
例如,gn6v表示采用Volta/Turing架構,顯存為16 GB,且搭載NVIDIA V100 GPU的計算型實例。
6e:6表示采用Volta/Turing架構;e(extend)表示第2代GPU類型為V100且顯存為32 GB。
例如,gn6e表示采用Volta/Turing架構,顯存為32 GB,且搭載NVIDIA V100 GPU的計算型實例。
6i:6表示采用Volta/Turing架構;i(inference)表示GPU類型為T4。
例如,gn6i表示采用Volta/Turing架構且搭載NVIDIA的T4 GPU計算型實例。
6s:6表示采用Volta/Turing架構;s表示第6代SG-1。
例如,ebmgi6s表示采用Intel?Server GPU卡和第6代SG-1芯片的視覺計算型實例。
7:表示采用Ampere架構。
7i:7表示采用Ampere架構;i(inference)表示GPU類型為A10且顯存為24 GB。
7e:7表示采用Ampere架構。
7s:7表示采用Ampere架構;s表示用于第7代A30 GPU。
<nx>large:large表示vCPU核數,<nx>中的n越大,表示vCPU核數越多。其中,xlarge代表4核,2xlarge代表8核,3xlarge代表12核等等,以此類推。
支持變配的實例規格:請參見支持變配的實例規格。
查看實例可購買地域:各個地域下可供售賣的實例規格可能存在差異,實例的可購情況,您可以前往ECS實例可購買地域查看。
實例適用場景
企業級實例

異構計算實例

根據預裝軟件選型
根據您使用的應用,并參考選型原則,選擇對應的實例規格族。
應用類型 | 常用應用 | 選型原則 | 推薦實例規格族 |
負載均衡 | Nginx | 應用特點:需要支持高頻率的新建連接操作。
| c8i、c7、c7nex、g5ne |
RPC產品 |
| 應用特點:網絡鏈接密集型;進程運行時需要消耗較高的內存。 | g8a、g7nex、g8i、g7 |
緩存 |
|
| r8i、r8a、r7、r7a |
配置中心 | ZooKeeper | 在應用啟動協商時會有大量I/O讀寫操作。
| c8a、c7、c8i、u1 |
消息隊列 |
| 從消息完整性方面考慮,存儲優先選用云盤。
| c8a、c7、c8i、u1 |
容器編排 | Kubernetes | 通過彈性裸金屬服務器和容器的組合,可以最大限度地挖掘計算潛能。 | ebmc6e、ebmg6e、ebmc6、ebmg6、ebmc6a、ebmc7a、ebmg6a、ebmg7a系列 |
大表存儲 | HBase |
| d3c、d3s、i4 |
數據庫 |
|
| g8a、g7、g8i、i4, |
SQLServer |
| g8a、g7、r7、r8i、g8i | |
文本搜索 | Elasticsearch |
| i4、i4r、i3、i2 |
實時計算 |
| 基于存儲量可以選擇ECS通用規格和云盤,也可以選擇d系列。 | i4g、i4、d3c |
離線計算 |
| 優先選擇d系列。 | d3s、d3c |
視頻轉碼 |
|
| c8y、hfc8i |
大數據 |
|
| g8y、r8y |
根據細分業務場景選型
通用應用、游戲服務、視頻直播場景推薦
在該類場景中,性能需求表現為CPU計算密集型,您需要相對均衡的處理器與內存資源配比,通常選用CPU與內存配比1:2、系統盤選用高效云盤、數據盤選用SSD云盤或者ESSD云盤。如果業務需要更強的網絡性能,如視頻彈幕等,您可以選用同系列中更高規格的實例規格,提高網絡收發包能力(PPS)。
場景分類 | 場景細分 | 推薦規格族 | 性能需求 | 處理器與內存比 |
通用應用 | 均衡性能應用,后臺應用 | g系列,如g7 | 中主頻,計算密集型 | 1:4 |
高網絡收發包應用 | g系列,如g7 | 高網絡PPS,計算密集型 | 1:4 | |
高性能計算 | hfc系列,如hfc7 | 高主頻,計算密集型 | 1:2 | |
游戲應用 | 高性能端游 | hfc系列,如hfc7 | 高主頻 | 1:2 |
手游、頁游 | g系列,如g6e | 中主頻 | 1:4 | |
視頻直播 | 視頻轉發 | g系列,如g7 | 中主頻,計算密集型 | 1:4 |
直播彈幕 | g系列,如g7 | 高網絡PPS,計算密集型 | 1:4 |
Hadoop、Spark、Kafka大數據場景推薦
在該類場景中,由于涉及不同的節點,性能需求表現較為復雜,您需要均衡各個節點的性能表現,包括計算、存儲吞吐量、網絡性能等。
管理節點:當作通用場景處理,請參見根據細分業務場景選型。
計算節點:當作通用場景處理,請參見根據細分業務場景選型。根據集群規模的不同,需要選擇的實例規格不同。例如100個節點以下可以選用ecs.g7.4xlage,100個節點以上可以選用ecs.g7.8xlage。
緩存節點:用于存儲熱數據或部署RSS,側重磁盤和網絡IO性能,推薦使用i4g、i2g。
計算緩存節點:用于計算和緩存,兼備計算性能和IO性能、磁盤容量,推薦使用i4、i4r、d3c。
說明計算節點在計費模式上可以采用搶占式實例,實現性價比最優化。更多信息,請參見什么是搶占式實例。
數據節點:需要高存儲吞吐、高網絡吞吐、均衡的處理器與內存配比,推薦您使用大數據型(d系列)規格族。例如MapReduce/Hive可選擇ecs.d2s.5xlarge、ecs.d3s.4xlarge等,Spark/Mlib可選擇ecs.d2s.10xlarge。
數據庫、緩存、搜索場景推薦
在該類場景中,實例規格的處理器與內存配比一般要求高于1:4,部分軟件對存儲I/O讀寫能力及時延性能較為敏感,建議您選用單位內存性價比較高的規格族。
場景分類 | 場景細分 | 推薦規格族 | 處理器與內存比 | 數據盤 |
關系型數據庫 | 高性能,依賴應用層高可用 | i系列 | 1:4 | 本地SSD存儲、高效云盤、SSD云盤 |
中小型數據庫 | g系列,或其他內存占比為1:4的規格族 | 1:4 | 高效云盤、SSD云盤 | |
高性能數據庫 | i、r系列 | 1:8 | 高效云盤、SSD云盤 | |
分布式緩存 | 中內存消耗場景 | g系列,或其他內存占比為1:4的規格族 | 1:4 | 高效云盤、SSD云盤 |
高內存消耗場景 | r系列、i系列 | 1:8 | 高效云盤、SSD云盤 | |
NoSQL數據庫 | 高性能,應用層高可用 | i系列 | 1:4 | 本地SSD存儲、高效云盤、SSD云盤 |
中小型數據庫 | g系列,或其他內存占比為1:4的規格族 | 1:4 | 高效云盤、SSD云盤 | |
高性能數據庫 | i4、i4r系列 | 1:8 | 高效云盤、SSD云盤、本地SSD存儲 | |
ElasticSearch | 小集群,靠云盤保證數據高可用 | g系列,或其他內存占比為1:4的規格族 | 1:4 | 高效云盤、SSD云盤 |
大集群,高可用 | d系列 | 1:4 | 本地SSD存儲、高效云盤、SSD云盤 |
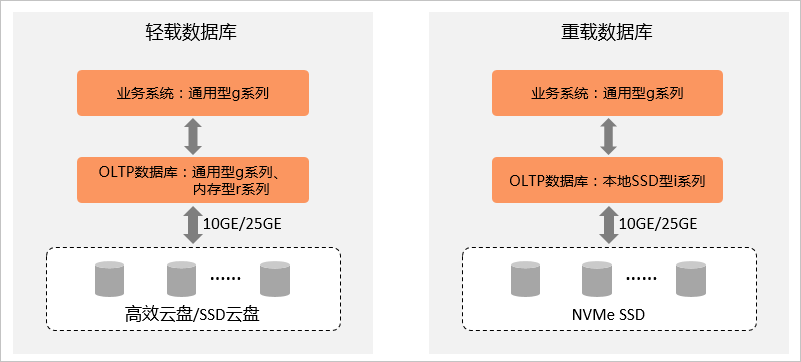
以數據庫為例,在傳統方式中,業務系統直接對接OLTP數據庫,數據冗余大多通過RAID磁盤陣列實現。選擇云服務器ECS,您的輕載、重載數據庫都能實現靈活部署。
輕載數據庫:采用i4r、i4g系列實例搭配云盤使用,性價比更高。
重載數據庫:需要高存儲IOPS和低讀寫延時,推薦您使用本地SSD型i系列實例規格族(搭配了高I/O型本地NVMeSSD本地盤),滿足大型重載數據庫的要求。
深度學習、圖像處理場景推薦
在該類場景中,應用需要高性能的GPU加速器,在GPU和CPU配比方面有如下建議。
深度學習訓練:GPU與CPU比例推薦為1:8到1:12之間。
通用深度學習:GPU與CPU比例推薦為1:4到1:48之間。
圖像識別推理:GPU與CPU比例推薦為1:4到1:12之間。
語音識別與合成推理:GPU與CPU比例推薦為1:16到1:48之間。
常見場景的GPU選型推薦如下圖所示。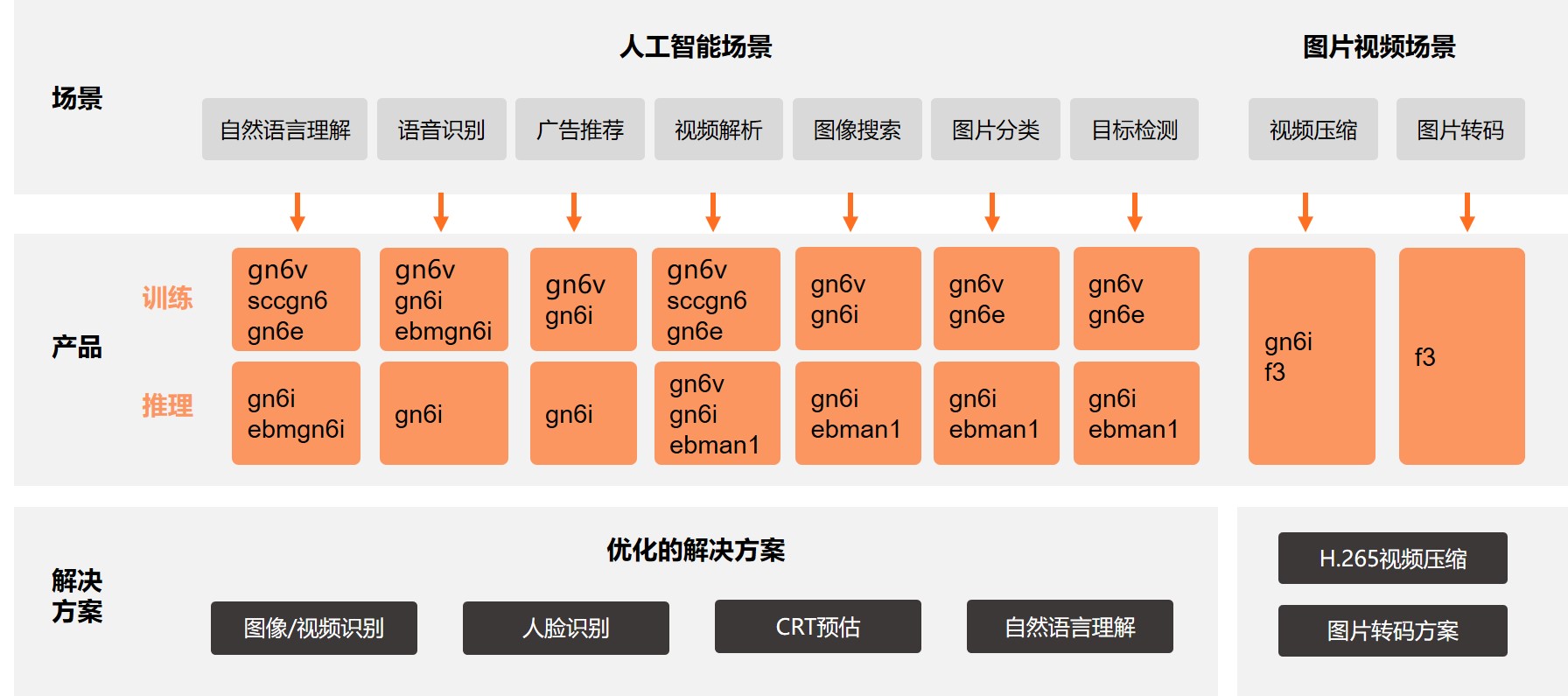
驗證與調整
當您完成選型并開始使用云服務器ECS實例后,建議您根據一段時間的性能監控信息,驗證所選實例規格是否合適。
假設您選擇了ecs.g8i.xlarge,通過監控發現實例CPU使用率一直較低,建議您登錄實例檢查內存占用率是否較高,如果內存占用較高,您可以調整為處理器與內存資源配比更合適的規格族。更多信息,請參見以下文檔:
使用云服務器ECS的過程中,如果發生地域庫存不足、實例規格族停售、修改為更高性價比規格族、升級配置等情況,您可以根據實例規格族的特點進行變配。更多信息,請參見升降配方式概述與支持變配的實例規格。