動(dòng)態(tài)資源超賣
ack-koordinator提供動(dòng)態(tài)資源超賣功能,通過對(duì)節(jié)點(diǎn)負(fù)載數(shù)據(jù)的實(shí)時(shí)收集,可以充分挖掘集群中已分配但未使用的資源量,以實(shí)現(xiàn)對(duì)集群資源的動(dòng)態(tài)超賣。本文主要介紹如何使用動(dòng)態(tài)資源超賣功能。
前提條件
僅支持ACK Pro版集群。具體操作,請(qǐng)參見創(chuàng)建ACK Pro版集群。
已安裝ack-koordinator(原ack-slo-manager)。具體操作,請(qǐng)參見ack-koordinator。
費(fèi)用說明
ack-koordinator組件本身的安裝和使用是免費(fèi)的,不過需要注意的是,在以下場(chǎng)景中可能產(chǎn)生額外的費(fèi)用:
ack-koordinator是非托管組件,安裝后將占用Worker節(jié)點(diǎn)資源。您可以在安裝組件時(shí)配置各模塊的資源申請(qǐng)量。
ack-koordinator默認(rèn)會(huì)將資源畫像、精細(xì)化調(diào)度等功能的監(jiān)控指標(biāo)以Prometheus的格式對(duì)外透出。若您配置組件時(shí)開啟了ACK-Koordinator開啟Prometheus監(jiān)控指標(biāo)選項(xiàng)并使用了阿里云Prometheus服務(wù),這些指標(biāo)將被視為自定義指標(biāo)并產(chǎn)生相應(yīng)費(fèi)用。具體費(fèi)用取決于您的集群規(guī)模和應(yīng)用數(shù)量等因素。建議您在啟用此功能前,仔細(xì)閱讀阿里云Prometheus計(jì)費(fèi)說明,了解自定義指標(biāo)的免費(fèi)額度和收費(fèi)策略。您可以通過賬單和用量查詢,監(jiān)控和管理您的資源使用情況。
背景信息
在Kubernetes系統(tǒng)中,Kubelet通過參考Pod的QoS等級(jí)來管理單機(jī)容器的資源質(zhì)量,例如OOM(Out of Memory)優(yōu)先級(jí)控制等。Pod的QoS級(jí)別分為Guaranteed、Burstable和BestEffort。QoS級(jí)別并不是顯式定義,而是取決于Pod配置的Request和Limit(CPU、內(nèi)存)。
為了提高穩(wěn)定性,應(yīng)用管理員在提交Guaranteed和Burstable這兩類Pod時(shí)會(huì)預(yù)留相當(dāng)數(shù)量的資源Buffer來應(yīng)對(duì)上下游鏈路的負(fù)載波動(dòng),在大部分時(shí)間段,容器的Request會(huì)遠(yuǎn)高于實(shí)際的資源利用率。為了提升集群資源利用率,應(yīng)用管理員會(huì)提交一些QoS為BestEffort的低優(yōu)任務(wù),來充分使用那些已分配但未使用的資源,實(shí)現(xiàn)對(duì)集群資源的超賣,其缺點(diǎn)如下:
節(jié)點(diǎn)可容納低優(yōu)任務(wù)的資源量沒有任何參考,即使節(jié)點(diǎn)實(shí)際負(fù)載已經(jīng)很高,由于BestEffort任務(wù)在資源規(guī)格上缺少容量約束,仍然會(huì)被調(diào)度到節(jié)點(diǎn)上運(yùn)行。
BestEffort任務(wù)間缺乏公平性保證,任務(wù)資源規(guī)格存在區(qū)別,但無法在Pod描述上體現(xiàn)。
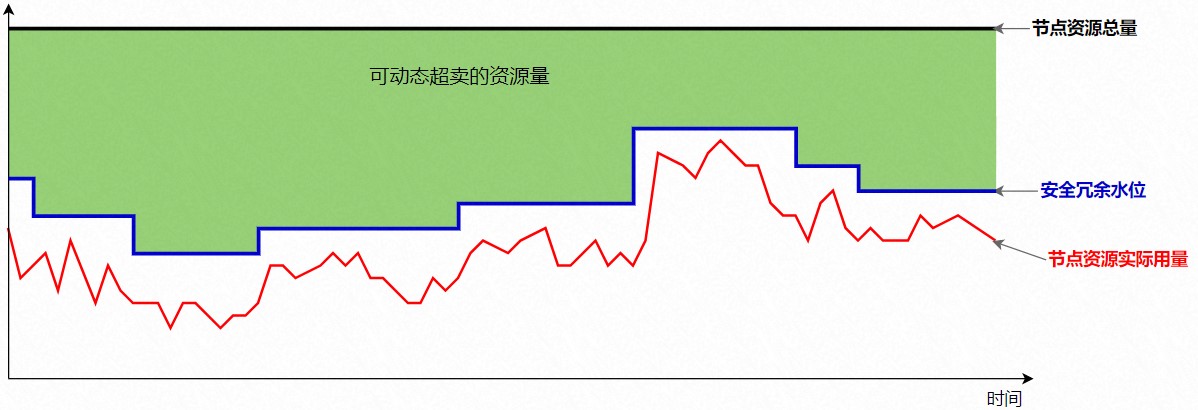
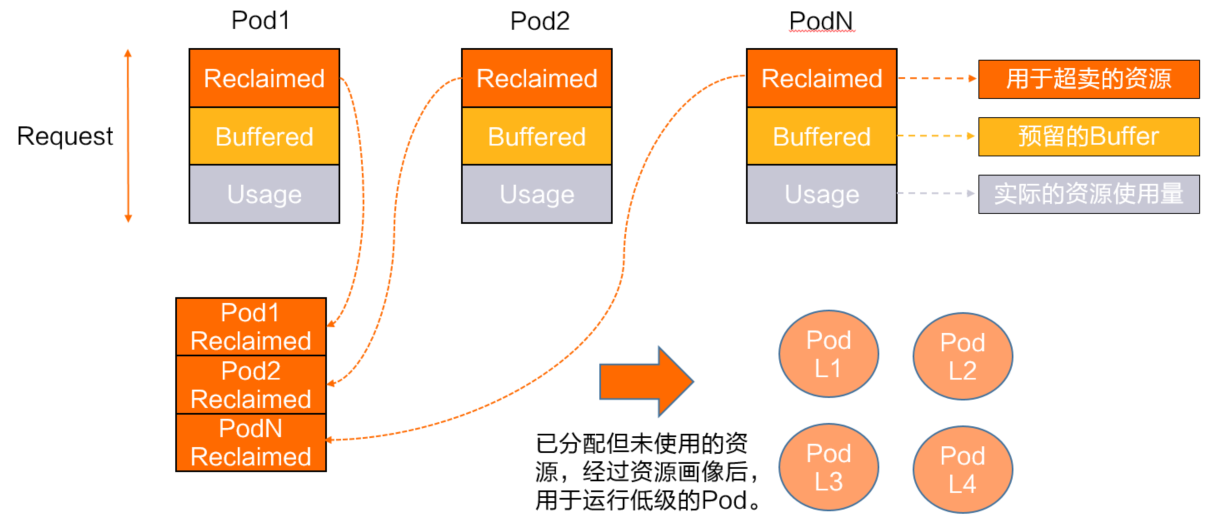
針對(duì)以上問題,ACK的差異化SLO(Service Level Objectives)提供了將這部分資源量化的能力。將上圖中的紅線定義為Usage,藍(lán)線到紅線預(yù)留部分資源定義為Buffered,綠色覆蓋部分定義為Reclaimed。
如下圖所示,Reclaimed資源代表可動(dòng)態(tài)超賣的資源量。ack-koordinator會(huì)根據(jù)節(jié)點(diǎn)真實(shí)負(fù)載情況動(dòng)態(tài)更新,并以標(biāo)準(zhǔn)擴(kuò)展資源的形式實(shí)時(shí)更新到K8s的Node元信息中。低優(yōu)的BestEffort任務(wù)可以通過在Request和Limit中定義的Reclaimed資源配置來使用這部分資源,這部分配置同時(shí)也會(huì)體現(xiàn)在節(jié)點(diǎn)側(cè)的資源限制參數(shù)上,保證BestEffort作業(yè)之間的公平性。
為體現(xiàn)與原生資源類型的差異性,ack-koordinator使用“Batch”優(yōu)先級(jí)的概念描述該部分超賣資源,以下簡(jiǎn)稱batch-cpu和batch-memory。
使用限制
組件 | 版本要求 |
Kubernetes | ≥v1.18 |
≥0.8.0 | |
Helm版本 | ≥v3.0 |
操作步驟
使用以下命令,查看當(dāng)前Batch資源總量。
查看前請(qǐng)確保對(duì)應(yīng)配置已經(jīng)開啟,詳見步驟3中的描述。
# 將$nodeName替換為要查詢的目標(biāo)節(jié)點(diǎn)名稱。 kubectl get node $nodeName -o yaml預(yù)期輸出:
#Node status: allocatable: # 單位為千分之一核,以下表示50核。 kubernetes.io/batch-cpu: 50000 # 單位為字節(jié),以下表示50 GB。 kubernetes.io/batch-memory: 53687091200創(chuàng)建Pod并申請(qǐng)Batch資源。在Label中指定QoS等級(jí),并在Request和Limit中添加對(duì)應(yīng)的Batch資源配置,即可讓Pod使用動(dòng)態(tài)超賣資源,具體示例如下。
#Pod metadata: labels: # 必填,標(biāo)記為低優(yōu)先級(jí)Pod。 koordinator.sh/qosClass: "BE" spec: containers: - resources: requests: # 單位為千分之一核,如下表示1核。 kubernetes.io/batch-cpu: "1k" # 單位為字節(jié),如下表示1 GB。 kubernetes.io/batch-memory: "1Gi" limits: kubernetes.io/batch-cpu: "1k" kubernetes.io/batch-memory: "1Gi"申請(qǐng)Batch資源需注意:
若您通過Deployment或其它類型工作負(fù)載提交Pod,只需在對(duì)應(yīng)的模板字段中參照上述示例,采用相同格式填寫即可。同一個(gè)Pod不能同時(shí)申請(qǐng)Batch資源和普通的CPU或Memory資源。
由于節(jié)點(diǎn)的Batch資源總量根據(jù)當(dāng)前實(shí)際負(fù)載動(dòng)態(tài)計(jì)算得到,在邊界情況下可能會(huì)因Kubelet未及時(shí)同步而被拒絕,此時(shí)您可以直接將被拒絕的Pod進(jìn)行刪除。
受K8s的約束,擴(kuò)展資源必須以整數(shù)形式表達(dá),因此
batch-cpu資源需要以千分之一核為單位進(jìn)行配置。
管理動(dòng)態(tài)超賣資源。
節(jié)點(diǎn)的Batch容量根據(jù)實(shí)際的資源利用率情況動(dòng)態(tài)計(jì)算得到,CPU和內(nèi)存維度默認(rèn)的計(jì)算過程可以按如下公式簡(jiǎn)單推導(dǎo):
nodeBatchAllocatable = nodeAllocatable * thresholdPercent - podUsage(non-BE) - systemUsage計(jì)算公式中各因子的含義如下:
nodeAllocatable:節(jié)點(diǎn)可分配資源總量。
thresholdPercent:預(yù)留水位比例。
podUsage(non-BE):高優(yōu)先級(jí)Pod的資源用量,即非BE類型Pod的資源使用量。
systemUsage:節(jié)點(diǎn)系統(tǒng)資源真實(shí)用量。
同時(shí),對(duì)于內(nèi)存維度的資源超賣,ack-koordinator還支持按請(qǐng)求量(Request)計(jì)算,具體配置參考后文有關(guān)memoryCalculatePolicy的描述,公式如下。其中
podRequest(non-BE)表示高優(yōu)先級(jí)Pod的資源請(qǐng)求量,即非BE類型Pod的資源請(qǐng)求量(Request)之和。nodeBatchAllocatable = nodeAllocatable * thresholdPercent - podRequest(non-BE) - systemUsage公式中的thresholdPercent為可配置參數(shù),通過修改ConfigMap中的配置項(xiàng)可以實(shí)現(xiàn)對(duì)資源的靈活管理,配置示例及詳細(xì)說明如下。
apiVersion: v1 kind: ConfigMap metadata: name: ack-slo-config namespace: kube-system data: colocation-config: | { "enable": true, "metricAggregateDurationSeconds": 60, "cpuReclaimThresholdPercent": 60, "memoryReclaimThresholdPercent": 70, "memoryCalculatePolicy": "usage" }字段名稱
格式
含義
enableBoolean
表示是否開啟節(jié)點(diǎn)Batch資源的動(dòng)態(tài)更新,關(guān)閉時(shí)Batch資源量會(huì)被重置為
0。默認(rèn)值為false。metricAggregateDurationSecondsInt
Batch資源最小更新頻率,單位為秒。通常建議保持為1分鐘不必修改。
cpuReclaimThresholdPercentInt
計(jì)算節(jié)點(diǎn)
batch-cpu資源容量時(shí)的預(yù)留系數(shù)。默認(rèn)值為65,單位為百分比。memoryReclaimThresholdPercentInt
計(jì)算節(jié)點(diǎn)
batch-memory資源容量時(shí)的預(yù)留系數(shù)。默認(rèn)值為65,單位為百分比。memoryCalculatePolicyString
計(jì)算節(jié)點(diǎn)batch-memory資源容量時(shí)的策略。
"usage":默認(rèn)值,表示batch-memory內(nèi)存資源按照高優(yōu)先級(jí)Pod的內(nèi)存真實(shí)用量計(jì)算,包括了節(jié)點(diǎn)未申請(qǐng)的資源,以及已申請(qǐng)但未使用的資源量。"request":表示batch-memory內(nèi)存資源按照高優(yōu)先級(jí)Pod的內(nèi)存請(qǐng)求量計(jì)算,僅包括節(jié)點(diǎn)未申請(qǐng)的資源。
說明ack-koordinator在單機(jī)端提供了針對(duì)Batch資源的壓制和驅(qū)逐能力,包括彈性資源限制、容器內(nèi)存QoS和容器L3 Cache及內(nèi)存帶寬隔離,能夠有效避免低優(yōu)的BestEffort容器帶來的干擾問題。
查看命名空間
kube-system下是否存在ConfigMapack-slo-config。若存在ConfigMap
ack-slo-config,請(qǐng)使用PATCH方式進(jìn)行更新,避免干擾ConfigMap中其他配置項(xiàng)。kubectl patch cm -n kube-system ack-slo-config --patch "$(cat configmap.yaml)"若不存在ConfigMap
ack-slo-config,請(qǐng)執(zhí)行以下命令進(jìn)行創(chuàng)建Configmap。kubectl apply -f configmap.yaml
(可選)通過Prometheus查看Batch資源使用情況。
如果您首次使用該功能的大盤,請(qǐng)確保動(dòng)態(tài)資源超賣大盤已經(jīng)升級(jí)到最新版本。關(guān)于升級(jí)的具體操作,請(qǐng)參見相關(guān)操作。
通過ACK控制臺(tái)Prometheus監(jiān)控查看Batch資源使用情況的具體操作如下:
登錄容器服務(wù)管理控制臺(tái),在左側(cè)導(dǎo)航欄選擇集群。
在集群列表頁(yè)面,單擊目標(biāo)集群名稱,然后在左側(cè)導(dǎo)航欄,選擇。
在Prometheus監(jiān)控頁(yè)面,單擊成本分析/資源優(yōu)化頁(yè)簽,然后單擊在離線混部頁(yè)簽。
您可以在在離線混部頁(yè)簽查看詳細(xì)數(shù)據(jù),包括集群以及單個(gè)節(jié)點(diǎn)的Batch總量和已申請(qǐng)量。更多信息,請(qǐng)參見基礎(chǔ)監(jiān)控。
# 節(jié)點(diǎn)batch-cpu可分配總量。 koordlet_node_resource_allocatable{resource="kubernetes.io/batch-cpu",node="$node"} # 節(jié)點(diǎn)batch-cpu已分配量。 koordlet_container_resource_requests{resource="kubernetes.io/batch-cpu",node="$node"} # 節(jié)點(diǎn)batch-memory可分配總量。 kube_node_status_allocatable{resource="kubernetes.io/batch-memory",node="$node"} # 節(jié)點(diǎn)batch-memory已分配量。 koordlet_container_resource_requests{resource="kubernetes.io/batch-memory",node="$node"}
使用樣例
使用以下命令,查看節(jié)點(diǎn)Reclaimed資源總量。
查看前請(qǐng)確保對(duì)應(yīng)配置已經(jīng)開啟,詳見步驟3中的描述。
kubectl get node $nodeName -o yaml預(yù)期輸出:
#Node信息 status: allocatable: # 單位為千分之一核,以下表示50核。 kubernetes.io/batch-cpu: 50000 # 單位為字節(jié),以下表示50 GB。 kubernetes.io/batch-memory: 53687091200使用以下YAML內(nèi)容,創(chuàng)建名為be-pod-demo.yaml文件。
apiVersion: v1 kind: Pod metadata: lables: koordinator.sh/qosClass: "BE" name: be-demo spec: containers: - command: - "sleep" - "100h" image: polinux/stress imagePullPolicy: Always name: be-demo resources: limits: kubernetes.io/batch-cpu: "50k" kubernetes.io/batch-memory: "10Gi" requests: kubernetes.io/batch-cpu: "50k" kubernetes.io/batch-memory: "10Gi" schedulerName: default-scheduler使用以下命令,部署be-pod-demo作為目標(biāo)評(píng)測(cè)應(yīng)用。
kubectl apply -f be-pod-demo.yaml在單機(jī)端的cgroup分組中查看BE Pod資源限制的生效情況。
使用以下命令,查看CPU資源限制參數(shù)。
cat /sys/fs/cgroup/cpu,cpuacct/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-pod4b6e96c8_042d_471c_b6ef_b7e0686a****.slice/cri-containerd-11111c202adfefdd63d7d002ccde8907d08291e706671438c4ccedfecba5****.scope/cpu.cfs_quota_us預(yù)期輸出:
#容器對(duì)應(yīng)的CPU Cgroup為50核。 5000000使用以下命令,查看Memory資源限制參數(shù)。
cat /sys/fs/cgroup/memory/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-pod4b6e96c8_042d_471c_b6ef_b7e0686a****.slice/cri-containerd-11111c202adfefdd63d7d002ccde8907d08291e706671438c4ccedfecba5****.scope/memory.limit_in_bytes預(yù)期輸出:
#容器對(duì)應(yīng)的Memory Cgroup為10 GB。 10737418240
常見問題
當(dāng)前已通過ack-slo-manager的舊版本協(xié)議使用了動(dòng)態(tài)資源超賣功能,升級(jí)為ack-koordinator后是否繼續(xù)支持?
舊版本的動(dòng)態(tài)資源超賣協(xié)議包括兩部分:
在Pod的Annotation中填寫的
alibabacloud.com/qosClass。在Pod的Request和Limit中填寫的
alibabacloud.com/reclaimed。
ack-koordinator兼容以上舊版本協(xié)議,并在ACK Pro調(diào)度器中統(tǒng)一計(jì)算新舊版本協(xié)議的資源申請(qǐng)量和可用量。您可將組件無縫升級(jí)至ack-koordinator。
ack-koordinator對(duì)舊版本協(xié)議的兼容期限截止至2023年07月30日。強(qiáng)烈建議您將原協(xié)議資源字段及時(shí)升級(jí)到新版本。
ACK Pro調(diào)度器和ack-koordinator對(duì)各版本協(xié)議的適配如下。
ACK調(diào)度器版本 | ack-koordinator版本(ack-slo-manager) | alibabacloud.com協(xié)議 | koordinator.sh協(xié)議 |
≥1.18且<1.22.15-ack-2.0 | ≥0.3.0 | 支持 | 不支持 |
≥1.22.15-ack-2.0 | ≥0.8.0 | 支持 | 支持 |
應(yīng)用使用了Batch資源后,內(nèi)存資源用量突然變得更高是什么原因?
對(duì)于在Pod資源限制Limit中配置了kubernetes.io/batch-memory的應(yīng)用(簡(jiǎn)稱batch limit),koordinator會(huì)等待容器創(chuàng)建后根據(jù)batch limit在節(jié)點(diǎn)上為其設(shè)置cgroup限制參數(shù)。由于部分應(yīng)用在啟動(dòng)時(shí)會(huì)根據(jù)容器cgroup參數(shù)自動(dòng)申請(qǐng)內(nèi)存,若應(yīng)用在cgroup的memory.limit參數(shù)設(shè)置前就啟動(dòng)完成,其內(nèi)存的真實(shí)用量可能會(huì)超過batch limit。而受操作系統(tǒng)約束,這時(shí)容器的內(nèi)存cgroup參數(shù)將無法設(shè)置成功,直至其真實(shí)用量降低至batch limit以下才會(huì)設(shè)置成功。
對(duì)于這種情況,我們建議適當(dāng)修改應(yīng)用配置參數(shù),控制其內(nèi)存真實(shí)用量在batch limit以下,或在應(yīng)用啟動(dòng)腳本中首先檢查內(nèi)存限制參數(shù),確認(rèn)設(shè)置完成后再啟動(dòng),確保應(yīng)用的內(nèi)存用量得到合理限制,避免出現(xiàn)OOM等情況。
在容器內(nèi)執(zhí)行以下命令,可以查看內(nèi)存資源限制參數(shù)。
# 單位為字節(jié)
cat /sys/fs/cgroup/memory/memory.limit_in_bytes
1048576000