報警配置功能提供容器場景報警能力的統一管理,包括容器服務異常事件報警,以及容器場景指標報警。您可以通過集群內部署CRD的方式配置容器服務的報警規則。本文介紹在注冊集群中如何接入報警配置功能及如何配置報警規則。
前提條件
通過容器服務Kubernetes版接入一個注冊的Kubernetes集群。具體操作,請參見創建注冊集群。
通過kubectl連接注冊集群。具體操作,請參見獲取集群KubeConfig并通過kubectl工具連接集群。
功能使用場景
容器服務報警配置功能集合容器場景的監控報警能力,提供報警的統一配置管理,有如下幾個典型的使用場景:
集群運維
可以通過監控報警了解集群管控、存儲、網絡、彈性擴縮容等異常事件。例如:
通過集群資源異常報警規則集感知集群基礎資源的關鍵指標是否異常。例如,CPU、Memory、網絡等關鍵指標是否出現高水位情況,避免影響集群穩定性。
通過配置并查看集群異常事件報警規則集感知集群節點或容器節點異常。例如,集群節點Docker進程異常、集群節點進程異常及集群容器副本啟動失敗等異常。
通過配置并查看集群存儲異常事件報警規則集感知集群存儲的變更與異常。
通過配置并查看集群網絡異常事件報警規則集感知集群網絡的變更與異常。
通過配置并查看集群管控運維異常報警規則集感知集群管控的變更與異常等。
應用開發
可以通過監控報警了解在集群中運行應用的異常事件、指標是否異常。例如,集群容器副本異常或者應用Deployment的CPU、內存水位指標是否超過閾值等。可通過開啟報警配置功能中的默認報警規則模板,即可快速接收集群內應用容器副本的異常事件報警通知。例如,通過配置并訂閱關注集群容器副本異常報警規則集感知所屬應用的Pod是否異常。
應用管理
關注運行在集群上的應用健康、容量規劃、集群運行穩定性及異常甚至是錯誤報警等貫穿應用生命周期的一系列問題。例如,通過配置并訂閱關注集群重要事件報警規則集感知集群內所有Warning、Error等異常報警;關注集群資源異常報警規則集感知集群的資源情況,從而更好地做容量規劃等。
多集群管理
當您有多個集群需要管理,為集群配置報警規則往往會是一個重復繁瑣且難以同步的操作。容器服務報警配置功能,支持通過集群內部署CRD配置的方式管理報警規則。可通過維護多個集群中同樣配置的CRD資源,來方便快捷地實現多集群中報警規則的同步配置。
在注冊集群中配置云監控組件
步驟一:為云監控組件配置RAM權限
通過onectl配置
在本地安裝配置onectl。具體操作,請參見通過onectl管理注冊集群。
執行以下命令,為云監控組件配置RAM權限。
onectl ram-user grant --addon alicloud-monitor-controller預期輸出:
Ram policy ack-one-registered-cluster-policy-alicloud-monitor-controller granted to ram user ack-one-user-ce313528c3 successfully.
通過控制臺配置
在注冊集群中安裝組件前,您需要在接入集群中設置AccessKey用來訪問云服務的權限。設置AccessKey前,您需要創建RAM用戶并為其添加訪問相關云資源的權限。
創建RAM用戶。具體操作,請參見創建RAM用戶。
創建權限策略。具體操作,請參見創建自定義權限策略。
權限策略模板如下所示:
{ "Action": [ "log:*", "arms:*", "cms:*", "cs:UpdateContactGroup" ], "Resource": [ "*" ], "Effect": "Allow" }為RAM用戶添加權限。具體操作,請參見為RAM用戶授權。
為RAM用戶創建AccessKey。具體操作,請參見獲取AccessKey。
使用AccessKey在注冊集群中創建名為alibaba-addon-secret的Secret資源。
安裝云監控組件時將自動引用此AccessKey訪問對應的云服務資源。
kubectl -n kube-system create secret generic alibaba-addon-secret --from-literal='access-key-id=<your access key id>' --from-literal='access-key-secret=<your access key secret>'說明<your access key id>及<your access key secret>為上一步獲取的AccessKey信息。
步驟二:安裝與升級云監控組件
通過onectl安裝
執行以下命令,安裝云監控組件。
onectl addon install alicloud-monitor-controller預期輸出:
Addon alicloud-monitor-controller, version **** installed.通過控制臺安裝
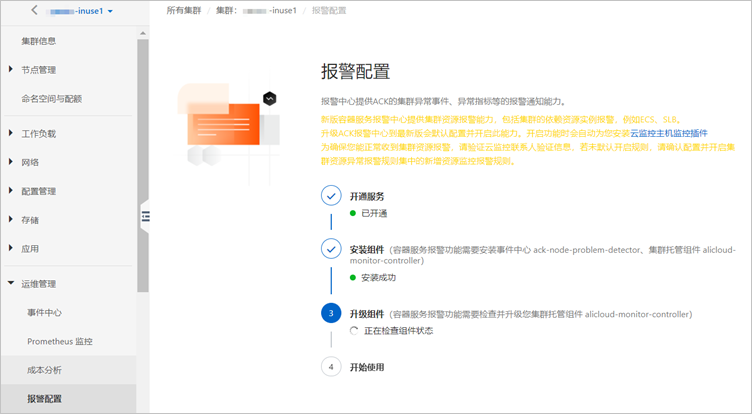
控制臺會自動檢測報警配置環境是否符合要求,并會引導進行開通、安裝或升級組件。
登錄容器服務管理控制臺。
在控制臺左側導航欄,單擊集群。
在集群列表頁面,單擊目標集群名稱或者目標集群右側操作列下的詳情。
在集群管理頁左側導航欄,選擇。
在報警配置頁面控制臺會自動檢查以下條件。
若不符合條件,請按以下提示完成操作。
已開通SLS日志服務云產品。當您首次使用日志服務時,需要登錄日志服務控制臺,根據頁面提示開通日志服務。
說明關于日志服務的詳細計費,請參見按使用功能付費模式計費項。
已安裝事件中心。具體操作,請參見事件監控。
集群托管組件alicloud-monitor-controller升級到最新版本。更多信息,請參見alicloud-monitor-controller。
接入報警配置功能
步驟一:開啟默認報警規則
登錄容器服務管理控制臺。
在控制臺左側導航欄,單擊集群。
在集群列表頁面,單擊目標集群名稱或者目標集群右側操作列下的詳情。
在集群管理頁左側導航欄,選擇。
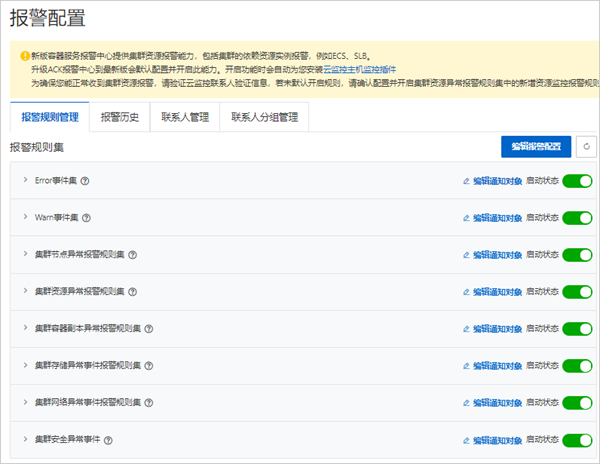
在報警規則管理頁簽,開啟對應報警規則集。
步驟二:手動配置報警規則
登錄容器服務管理控制臺。
在控制臺左側導航欄,單擊集群。
在集群列表頁面,單擊目標集群名稱或者目標集群右側操作列下的詳情。
在集群管理頁左側導航欄,選擇。
功能特性
說明
報警規則管理
容器服務報警規則功能會默認生成容器場景下的報警模板(包含異常事件報警、異常指標報警)。
報警規則被分類為若干個報警規則集,可為報警規則集關聯多個聯系人分組,并啟動或關閉報警規則集。
報警規則集中包含多個報警規則,一個報警規則對應單個異常的檢查項。多個報警規則集可以通過一個YAML資源配置到對應集群中,修改YAML會同步生成報警規則。
關于報警規則YAML配置,請參見如何通過CRD配置報警規則。
關于默認報警規則模板,請參見默認報警規則模板。
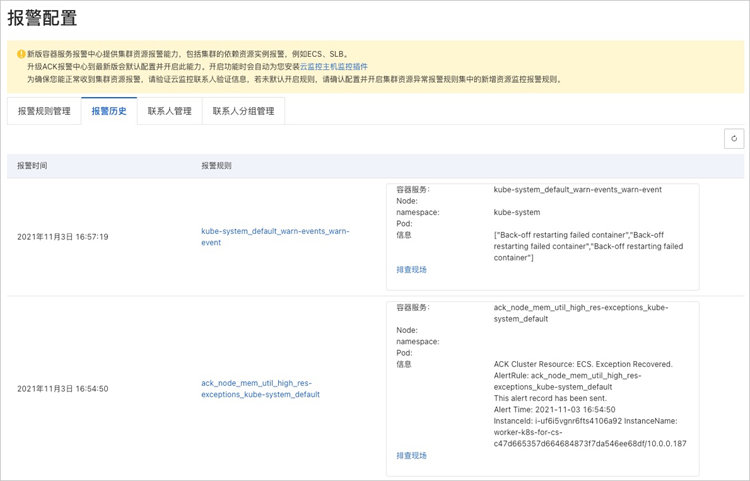
報警歷史
目前可查看最近發送的近100條歷史記錄。單擊對應報警規則類型的鏈接,可跳轉到對應監控系統中查看詳細規則配置;單擊對應報警排查現場的鏈接可快速定位到異常發生的資源頁面(異常事件、指標異常的資源)。
聯系人管理
對聯系人進行管理,可創建、編輯或刪除聯系人。
聯系人分組管理
對聯系人分組進行管理,可創建、編輯或刪除聯系人分組。當無聯系人分組時,控制臺會從您的阿里云賬號注冊信息中同步創建一個默認聯系人分組。
在報警規則管理頁簽,單擊編輯通知對象可設置關聯的通知對象;打開啟動狀態可開啟對應報警規則集。
如何通過CRD配置報警規則
報警配置功能開啟時,會默認在kube-system命名空間下創建一個AckAlertRule類型的資源配置,包含默認報警規則模板。容器服務報警規則集可通過此資源配置在集群中。
登錄容器服務管理控制臺。
在控制臺左側導航欄,單擊集群。
在集群列表頁面,單擊目標集群名稱或者目標集群右側操作列下的詳情。
在集群管理頁左側導航欄,選擇。
在報警規則管理頁簽中,單擊右上角編輯報警配置,可查看當前集群中的AckAlertRule資源配置,并可通過YAML文件修改。
報警規則配置的YAML文件示例如下:
apiVersion: alert.alibabacloud.com/v1beta1 kind: AckAlertRule metadata: name: default spec: groups: #以下是一個集群事件報警規則配置樣例。 - name: pod-exceptions #報警規則分組名,對應報警模板中的Group_Name字段。 rules: - name: pod-oom #報警規則名。 type: event #報警規則類型(Rule_Type),枚舉值為event(事件類型)、metric-cms(云監控指標類型)。 expression: sls.app.ack.pod.oom #報警規則表達式,當規則類型為event時,表達式的值為本文默認報警規則模板中Rule_Expression_Id值。 enable: enable #報警規則開啟狀態,枚舉值為enable、disable。 - name: pod-failed type: event expression: sls.app.ack.pod.failed enable: enable #以下是一個集群基礎資源報警規則配置樣例。 - name: res-exceptions #報警規則分組名,對應報警模板中的Group_Name字段。 rules: - name: node_cpu_util_high #報警規則名。 type: metric-cms #報警規則類型(Rule_Type),枚舉值為event(事件類型)、metric-cms(云監控指標類型)。 expression: cms.host.cpu.utilization #報警規則表達式,當規則類型為metric-cms時,表達式的值為本文默認報警規則模板中Rule_Expression_Id值。 contactGroups: #報警規則映射的聯系人分組配置,由ACK控制臺生成,同一個賬號下聯系人相同,可在多集群中復用。 enable: enable #報警規則開啟狀態,枚舉值為enable、disable。 thresholds: #報警規則閾值,詳情見文檔如何更改報警規則閾值部分。 - key: CMS_ESCALATIONS_CRITICAL_Threshold unit: percent value: '1'
默認報警規則模板
在以下情況下注冊集群會默認創建相應報警規則:
開啟默認報警規則功能。
未開啟默認報警規則,首次進入報警規則頁面。
默認創建的報警規則如下表所示。
規則集類型 | 規則名 | 規則說明 | Rule_Type | ACK_CR_Rule_Name | SLS_Event_ID |
critical-events集群重要事件報警規則集 | 集群Error事件 | 集群中所有Error Level異常事件觸發該報警。 | event | error-event | sls.app.ack.error |
集群Warn事件 | 集群中關鍵Warn Level異常事件觸發該報警,排除部分可忽略事件。 | event | warn-event | sls.app.ack.warn | |
cluster-error集群異常事件報警規則集 | 集群節點Docker進程異常 | 集群中節點Dockerd或Containerd 運行時異常。 | event | docker-hang | sls.app.ack.docker.hang |
集群驅逐事件 | 集群中發生驅逐事件。 | event | eviction-event | sls.app.ack.eviction | |
集群GPU的XID錯誤事件 | 集群中GPU XID異常事件。 | event | gpu-xid-error | sls.app.ack.gpu.xid_error | |
集群節點下線 | 集群中節點下線。 | event | node-down | sls.app.ack.node.down | |
集群節點重啟 | 集群中節點重啟。 | event | node-restart | sls.app.ack.node.restart | |
集群節點時間服務異常 | 集群中節點時間同步系統服務異常。 | event | node-ntp-down | sls.app.ack.ntp.down | |
集群節點PLEG異常 | 集群中節點PLEG異常。 | event | node-pleg-error | sls.app.ack.node.pleg_error | |
集群節點進程異常 | 集群中節點進程數異常。 | event | ps-hang | sls.app.ack.ps.hang | |
res-exceptions集群資源異常報警規則集 | 集群節點-CPU使用率≥85% | 集群中節點實例CPU使用率超過水位。默認值85%。 剩余資源不足15%時,可能會超過容器引擎層CPU資源預留。更多信息,請參見節點資源預留策略。這可能引起高頻CPU Throttle,最終嚴重影響進程響應速度。請及時優化CPU使用情況或調整閾值。 關于如何調整閾值,請參見如何修改集群基礎資源報警規則的閾值。 | metric-cms | node_cpu_util_high | cms.host.cpu.utilization |
集群節點-內存使用率≥85% | 集群中節點實例內存使用率超過水位。默認值85%。 剩余資源不足15%時,若仍然使用,水位將超過容器引擎層內存資源預留。更多信息,請參見節點資源預留策略。此場景下,Kubelet將發生強制驅逐行為。請及時優化內存使用情況或調整閾值。 關于如何調整閾值,請參見如何修改集群基礎資源報警規則的閾值。 | metric-cms | node_mem_util_high | cms.host.memory.utilization | |
集群節點-磁盤使用率≥85% | 集群中節點實例磁盤使用率超過水位。默認值85%。 關于如何調整閾值,請參見如何修改集群基礎資源報警規則的閾值。 | metric-cms | node_disk_util_high | cms.host.disk.utilization | |
集群節點-公網流出帶寬使用率≥85% | 集群中節點實例公網流出帶寬使用率超過水位。默認值85%。 關于如何調整閾值,請參見如何修改集群基礎資源報警規則的閾值。 | metric-cms | node_public_net_util_high | cms.host.public.network.utilization | |
集群節點-inode使用率≥85% | 集群中節點實例inode使用率超過水位。默認值85%。 關于如何調整閾值,請參見如何修改集群基礎資源報警規則的閾值。 | metric-cms | node_fs_inode_util_high | cms.host.fs.inode.utilization | |
集群資源-負載均衡最大連接數使用率≥85% | 集群中負載均衡實例最大連接數超過水位。默認值85%。 說明 負載均衡實例,即API-Server、Ingress所關聯的SLB負載均衡實例。 關于如何調整閾值,請參見如何修改集群基礎資源報警規則的閾值。 | metric-cms | slb_qps_util_high | cms.slb.qps.utilization | |
集群資源-負載均衡網絡流出帶寬使用率≥85% | 集群中負載均衡實例網絡流出帶寬使用率超過水位。默認值85%。 說明 負載均衡實例,即API-Server、Ingress所關聯的SLB負載均衡實例。 關于如何調整閾值,請參見如何修改集群基礎資源報警規則的閾值。 | metric-cms | slb_traff_tx_util_high | cms.slb.traffic.tx.utilization | |
集群資源-負載均衡最大連接數使用率≥85% | 集群中負載均衡實例最大連接數使用率超過水位。默認值85%。 說明 負載均衡實例,即API-Server、Ingress所關聯的SLB負載均衡實例。 關于如何調整閾值,請參見如何修改集群基礎資源報警規則的閾值。 | metric-cms | slb_max_con_util_high | cms.slb.max.connection.utilization | |
集群資源-負載均衡監聽每秒丟失連接數持續≥1 | 集群中負載均衡實例每秒丟失連接數持續超過水位。默認值1次。 說明 負載均衡實例,即API-Server、Ingress所關聯的SLB負載均衡實例。 關于如何調整閾值,請參見如何修改集群基礎資源報警規則的閾值。 | metric-cms | slb_drop_con_high | cms.slb.drop.connection | |
集群節點文件句柄過多 | 集群中節點文件句柄數過多異常。 | event | node-fd-pressure | sls.app.ack.node.fd_pressure | |
集群節點磁盤空間不足 | 集群中節點磁盤空間不足異常事件。 | event | node-disk-pressure | sls.app.ack.node.disk_pressure | |
集群節點進程數過多 | 集群中節點進程數過多異常事件。 | event | node-pid-pressure | sls.app.ack.node.pid_pressure | |
集群節點調度資源不足 | 集群中無調度資源異常事件。 | event | node-res-insufficient | sls.app.ack.resource.insufficient | |
集群節點IP資源不足 | 集群中IP資源不足異常事件。 | event | node-ip-pressure | sls.app.ack.ip.not_enough | |
pod-exceptions集群容器副本異常報警規則集 | 集群容器副本OOM | 集群容器副本Pod或其中進程出現OOM(Out of Memory)。 | event | pod-oom | sls.app.ack.pod.oom |
集群容器副本啟動失敗 | 集群容器副本Pod啟動失敗事件(Pod Start Failed)。 | event | pod-failed | sls.app.ack.pod.failed | |
集群鏡像拉取失敗事件 | 集群容器副本Pod出現鏡像拉取失敗事件。 | event | image-pull-back-off | sls.app.ack.image.pull_back_off | |
cluster-ops-err集群管控運維異常報警規則集 | 無可用LoadBalancer | 集群無法創建LoadBalancer事件。請提交工單聯系容器服務團隊。 | event | slb-no-ava | sls.app.ack.ccm.no_ava_slb |
同步LoadBalancer失敗 | 集群創建LoadBalancer同步失敗事件。請提交工單聯系容器服務團隊。 | event | slb-sync-err | sls.app.ack.ccm.sync_slb_failed | |
刪除LoadBalancer失敗 | 集群刪除LoadBalancer失敗事件。請提交工單聯系容器服務團隊。 | event | slb-del-err | sls.app.ack.ccm.del_slb_failed | |
刪除節點失敗 | 集群刪除節點失敗事件。請提交工單聯系容器服務團隊。 | event | node-del-err | sls.app.ack.ccm.del_node_failed | |
添加節點失敗 | 集群添加節點失敗事件。請提交工單聯系容器服務團隊。 | event | node-add-err | sls.app.ack.ccm.add_node_failed | |
創建VPC網絡路由失敗 | 集群創建VPC網絡路由失敗事件。請提交工單聯系容器服務團隊。 | event | route-create-err | sls.app.ack.ccm.create_route_failed | |
同步VPC網絡路由失敗 | 集群同步VPC網絡路由失敗事件。請提交工單聯系容器服務團隊。 | event | route-sync-err | sls.app.ack.ccm.sync_route_failed | |
托管節點池命令執行失敗 | 集群托管節點池異常事件。請提交工單聯系容器服務團隊。 | event | nlc-run-cmd-err | sls.app.ack.nlc.run_command_fail | |
托管節點池未提供任務的具體命令 | 集群托管節點池異常事件。請提交工單聯系容器服務團隊。 | event | nlc-empty-cmd | sls.app.ack.nlc.empty_task_cmd | |
托管節點池出現未實現的任務模式 | 集群托管節點池異常事件。請提交工單聯系容器服務團隊。 | event | nlc-url-m-unimp | sls.app.ack.nlc.url_mode_unimpl | |
托管節點池發生未知的修復操作 | 集群托管節點池異常事件。請提交工單聯系容器服務團隊。 | event | nlc-opt-no-found | sls.app.ack.nlc.op_not_found | |
托管節點池銷毀節點發生錯誤 | 集群托管節點池異常事件。請提交工單聯系容器服務團隊。 | event | nlc-des-node-err | sls.app.ack.nlc.destroy_node_fail | |
托管節點池節點排水失敗 | 集群托管節點池排水異常事件。請提交工單聯系容器服務團隊。 | event | nlc-drain-node-err | sls.app.ack.nlc.drain_node_fail | |
托管節點池重啟ECS未達到終態 | 集群托管節點池異常事件。請提交工單聯系容器服務團隊。 | event | nlc-restart-ecs-wait | sls.app.ack.nlc.restart_ecs_wait_fail | |
托管節點池重啟ECS失敗 | 集群托管節點池異常事件。請提交工單聯系容器服務團隊。 | event | nlc-restart-ecs-err | sls.app.ack.nlc.restart_ecs_fail | |
托管節點池重置ECS失敗 | 集群托管節點池異常事件。請提交工單聯系容器服務團隊。 | event | nlc-reset-ecs-err | sls.app.ack.nlc.reset_ecs_fail | |
托管節點池自愈任務失敗 | 集群托管節點池異常事件。請提交工單聯系容器服務團隊。 | event | nlc-sel-repair-err | sls.app.ack.nlc.repair_fail | |
cluster-network-err集群網絡異常事件報警規則集 | Terway資源無效 | 集群Terway網絡資源無效異常事件。請提交工單聯系容器服務團隊。 | event | terway-invalid-res | sls.app.ack.terway.invalid_resource |
Terway分配IP失敗 | 集群Terway網絡資源分配IP失敗異常事件。請提交工單聯系容器服務團隊。 | event | terway-alloc-ip-err | sls.app.ack.terway.alloc_ip_fail | |
解析Ingress帶寬配置失敗 | 集群Ingress網絡解析配置異常事件。請提交工單聯系容器服務團隊。 | event | terway-parse-err | sls.app.ack.terway.parse_fail | |
Terway分配網絡資源失敗 | 集群Terway網絡資源分配失敗異常事件。請提交工單聯系容器服務團隊。 | event | terway-alloc-res-err | sls.app.ack.terway.allocate_failure | |
Terway回收網絡資源失敗 | 集群Terway網絡資源回收失敗異常事件。請提交工單聯系容器服務團隊。 | event | terway-dispose-err | sls.app.ack.terway.dispose_failure | |
Terway虛擬模式變更 | 集群Terway網絡虛擬模式變更事件。 | event | terway-virt-mod-err | sls.app.ack.terway.virtual_mode_change | |
Terway觸發PodIP配置檢查 | 集群Terway網絡觸發PodIP配置檢查事件。 | event | terway-ip-check | sls.app.ack.terway.config_check | |
Ingress重載配置失敗 | 集群Ingress網絡配置重載異常事件。請檢查Ingress配置是否正確。 | event | ingress-reload-err | sls.app.ack.ingress.err_reload_nginx | |
cluster-storage-err集群存儲異常事件報警規則集 | 云盤容量少于20 GiB限制 | 集群網盤固定限制,無法掛載小于20 GiB的磁盤。請檢查所掛載云盤的容量大小。 | event | csi_invalid_size | sls.app.ack.csi.invalid_disk_size |
容器數據卷暫不支持包年包月類型云盤 | 集群網盤固定限制,無法掛載包年包月類型的云盤。請檢查所掛載云盤的售賣方式。 | event | csi_not_portable | sls.app.ack.csi.disk_not_portable | |
掛載點正在被進程占用,卸載掛載點失敗 | 集群存儲掛載點正在被進程占用,卸載掛載點失敗。 | event | csi_device_busy | sls.app.ack.csi.deivce_busy | |
無可用云盤 | 集群存儲掛載時無可用云盤異常。請提交工單聯系容器服務團隊。 | event | csi_no_ava_disk | sls.app.ack.csi.no_ava_disk | |
云盤IOHang | 集群出現IOHang異常。請提交工單聯系容器服務團隊。 | event | csi_disk_iohang | sls.app.ack.csi.disk_iohang | |
磁盤綁定的PVC發生slowIO | 集群磁盤綁定的PVC發生slowIO異常。請提交工單聯系容器服務團隊。 | event | csi_latency_high | sls.app.ack.csi.latency_too_high | |
磁盤容量超過水位閾值 | 集群磁盤使用量超過水位值異常。請檢查您的集群磁盤水位情況。 | event | disk_space_press | sls.app.ack.csi.no_enough_disk_space | |
security-err集群安全異常事件 | 安全巡檢發現高危風險配置 | 集群安全巡檢發現高危風險配置事件。請提交工單聯系容器服務團隊。 | event | si-c-a-risk | sls.app.ack.si.config_audit_high_risk |