基于阿里云云原生數據倉庫AnalyticDB MySQL版向量分析構建的高效基因檢測系統,能夠在幾十分鐘內完成整個病原體的查詢檢測,大大提升了基因分析性能,為疑難雜癥的確診以及精準治療提供有力支持。
背景信息
病原體基因檢測為醫生診斷疑難雜癥提供了診斷基礎,病原體基因檢測流程分為五個步驟,如基因檢測流程所示:
采集病人的樣本,例如靜脈血、痰液、肺泡灌洗液或者腦脊髓液等。
對樣本進行培養,然后提取樣本中的核酸組織。
通過高通量基因測序儀(High-throughput Sequencing),對核酸序列進行測序。
為保證高通量測序儀的精度,可以將較長的核苷酸序列切成小的分片,分別進行測序。在讀取基因序列時,基因序列的數據大小一般為50PB~200PB。
通過高通量測序之后,查詢相關病原體標準序列,找到匹配的基因序列。
對切分成片的基因序列進行分析,得到全部基因片段的組成成分即檢測結果,從而為疾病的確診以及精準治療提供有力支持。
圖 1. 基因檢測流程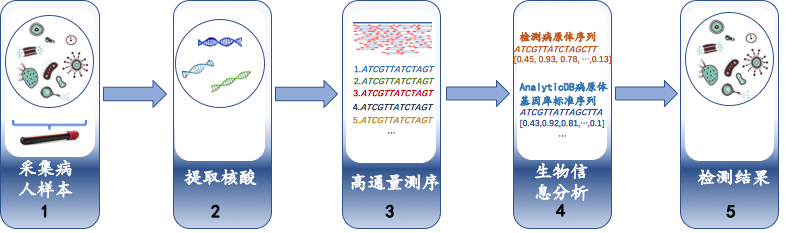
通常在生物分析檢測中進行一次病原體檢測,大約生成5億個75BP的基因片段。過濾掉屬于人的基因組織序列之后,仍需要查詢1億左右的基因片段。一般可以使用nBlast [1]工具進行基因匹配,整個病原體檢測過程大約需要2小時~3小時,耗時較長。
阿里云云原生數據倉庫AnalyticDB MySQL版(簡稱ADB,原分析型數據庫MySQL版)的向量分析提供了一個高效基因檢測系統,能夠在幾十分鐘內完成整個病原體的查詢檢測,大大提升了基因分析性能。
ADB基因檢測功能
系統界面是ADB基因檢測系統的界面。當前系統包含了12182個病毒的堿基序列,病毒的堿基序列切分成150BP的小片段(總共1590804個片段),轉化成向量之后存儲在ADB中。
您可以在檢測框中輸入一段基因序列,通過當前系統進行檢測。為方便使用,ADB基因檢測系統自帶新型冠狀病毒肺炎(簡稱新冠肺炎)、艾滋病病毒、埃博拉病病毒和中東呼吸綜合癥基因序列,您可以直接拷貝相關序列,檢測系統的查詢性能。
圖 2. 系統界面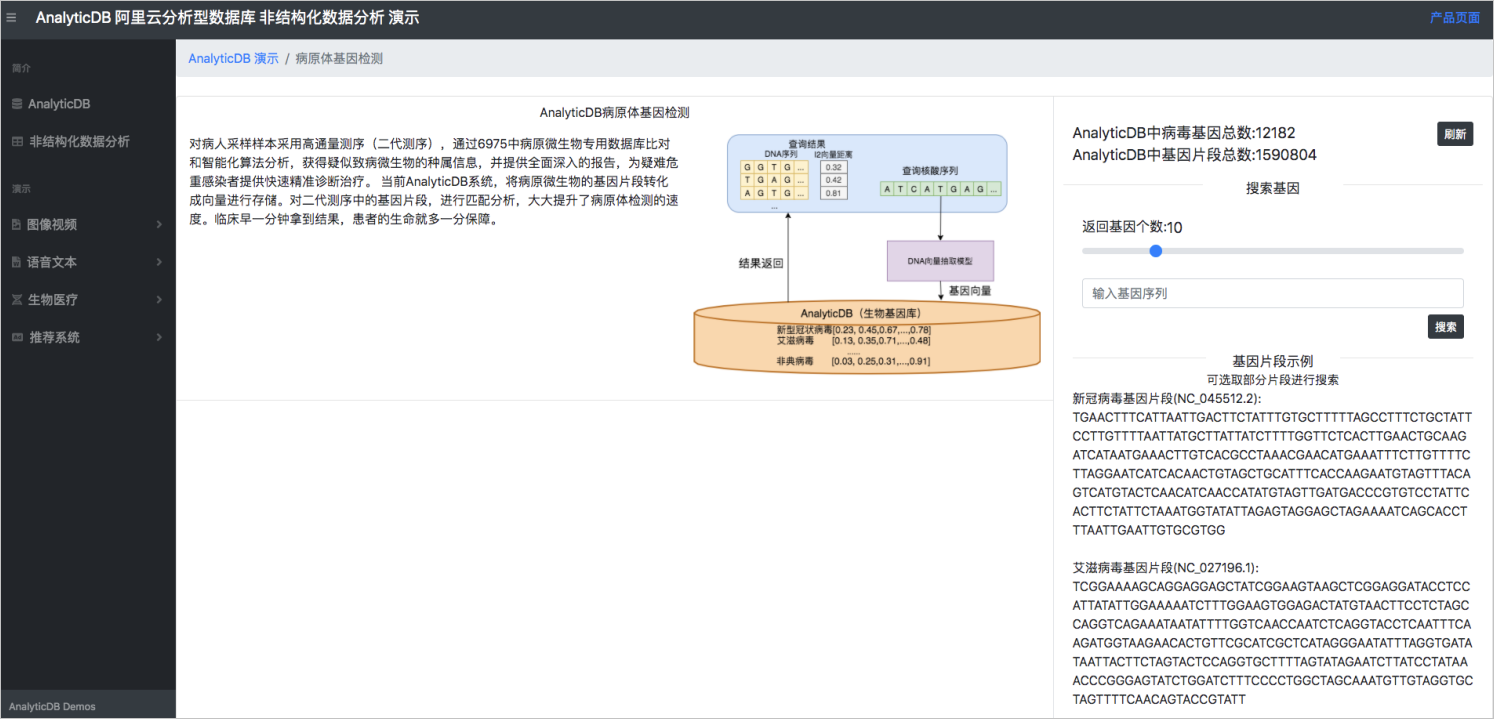
例如某用戶在基因序列輸入框中輸入一段新冠肺炎病毒序列,然后單擊檢索,系統在毫秒之內返回相關基因片段,查詢的基因序列顯示某用戶要查詢的病毒序列,如示例查詢所示。
圖 3. 示例查詢
系統架構
ADB負責存儲和查詢基因檢測系統中所有結構化數據(例如基因序列的長度、基因的名稱、基因的種類以及基因的詳細介紹,DNA或者RNA等)和基因序列產生的特征向量。查詢時使用基因向量抽取模型,將基因轉化成向量,在基因庫中進行粗排檢測,然后使用經典的Needleman-Wunsch [4]算法在匹配的向量結果集中進行精排,返回最相似的基因序列,如系統架構所示。
圖 4. 系統架構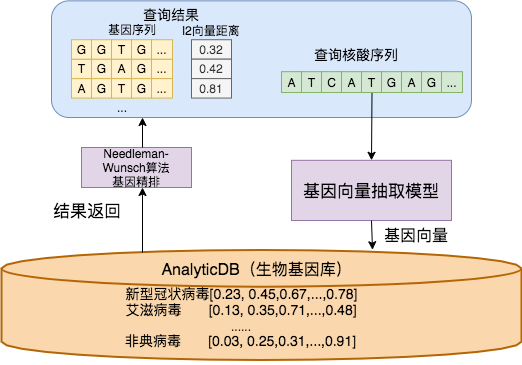
端到端的基因分析
本示例模擬人體的基因采樣,將新冠肺炎病毒基因(塞爾維亞MT450872 [2],美國MT450873 [3])和中東呼吸綜合癥MERS基因(NC_019843.3 [10])三株病毒混合在一起,打散成75BP的序列作為測試集。通過ADB高效基因檢測系統檢測分析,能夠快速識別當前測試集合中包含新冠肺炎病毒和MERS病毒。
圖 5. 基因匹配結果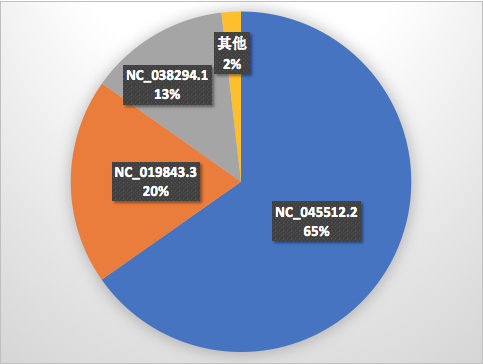
如基因匹配結果所示,ADB高效基因檢測系統從病毒庫檢測返回三個基因組(NC_045512.2,NC_019843.3和NC_038294.1)。其中NC_045512.2(占比65%)是武漢海鮮市場的新冠肺炎病毒的基因;NC_019843.3(占比20%)是MERS病毒的基因;NC_038294.1(占比13%)是Beta型英國冠狀病毒,是MERS病毒的另外一個名字 [8],也屬于MERS病毒。通過分析,當前測試樣本中包含了新冠肺炎病毒和MERS病毒。
基因查詢過程
ADB基因向量抽取算法通過DNA K-Mer模型得到每個k-mer的向量。如DNA序列轉向量所示的一段12BP的基因序列,在這段基因序列中抽取出5個8-mers,然后將這5個8-mers轉換成對應的向量,求和歸一化之后,就是這段12BP基因序列的向量。為提升精度,也可以使用doc2vec [6]等學習模型對整段基因片段進行轉化。詳細的基因向量抽取算法請參見基因向量抽取算法。
圖 6. DNA序列轉向量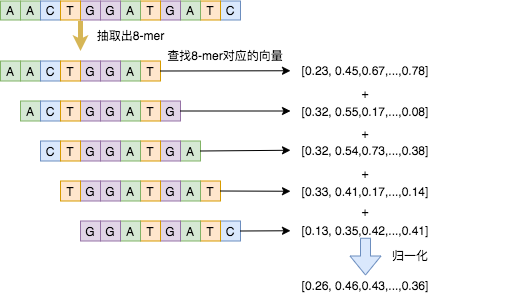
基因精度測試
為測試ADB高效基因檢測系統的基因精度,訓練了兩個模型,全部病毒模型和21個病原體細菌模型(痤瘡丙酸桿菌、金黃色葡萄球菌、表皮葡萄球菌、溶血葡萄球菌、大腸埃希氏菌、鮑曼不動桿菌、結核分枝桿菌、肺炎鏈球菌、肺炎克雷伯氏菌、流感嗜血桿菌、副流感嗜血桿菌、嗜麥芽窄食單胞菌、銅綠假單胞菌、屎腸球菌、紋帶棒狀桿菌、人皰疹病毒4型-EB病毒、細環病毒、人腺病毒B組、黃曲霉、白色假絲酵母、耶氏肺孢子菌)。將一個基因,每隔150個BP進行切分,然后將150BP的小分段轉換成向量并存入向量庫。病毒數據集包括12182個病毒、1590804個分段,21個細菌共275個基因,1521807個分段。
實驗一
目的:
隨機在當前基因庫中取出75BP的小片段,查詢75BP的基因片段是從哪個基因的哪個片段中提取的。
結果:
在基因庫中檢測75BP的基因片段,在返回的前N個結果集中,查看是否包含75BP基因片段對應的基因片段,通過公式計算Top-n的精度(Precision(n)),其中n表示查詢返回的列表長度;u表示查詢次數,取值為1000次。
圖 7. 公式
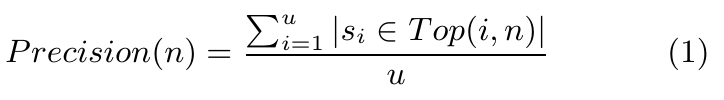
以上公式的含義為在第i次查詢中,序列si是否出現在Top-n的列表中,出現為1,不出現為0。如果n越小,精度越高,實際應用中的效率也越高。針對兩個模型來說,top20的精度均在99%以上,精度在0.99以上,如實驗一結果所示,對于實際檢驗基因片段是否包含物種基因是足夠的。
表 1. 實驗一結果
數據集
top1
top2
top3
top4
top5
top10
top20
病毒
0.866
0.965
0.983
0.986
0.99
0.992
0.994
21個細菌
0.901
0.975
0.987
0.987
0.993
0.994
1.0
實驗二
目的:
隨機在當前基因庫中取出75BP的基因片段,將75BP的基因段進行2%的隨機突變,在基因庫中查詢是否包含75BP的基因片段對應的基因片段。
說明自然界中基因突變的概率很低,例如人的30億個堿基,新生兒會有30個基因發生突變。病毒RNA的突變概率會高一些,一般也小于1%
結果:
在基因庫中檢測隨機突變后的75BP基因段,在返回的前N個結果集中,找到了包含75BP的基因片段對應的基因片段。基因突變之后,雖然查詢精度有所下降,但top20的精度也都達到了0.99,如實驗二結果所示。
表 2. 實驗二結果
數據集
top1
top2
top3
top4
top5
top10
top20
病毒
0.846
0.954
0.960
0.976
0.98
0.982
0.99
21個細菌
0.884
0.961
0.968
0.973
0.973
0.989
1.0
實驗三
目的:
對比在ADB數據庫和Blast數據庫中的基因檢測速度。
結果:
為得到實驗結果下載了病毒序列、菌類基因序列、部分植物基因序列 [7],總數量為9.7GB。分別將相關數據導入ADB數據庫和Blast數據庫中,分別進行100次不同的查詢,取實驗結果的平均值。Blast需要3.22秒才能返回結果,而ADB在算法精度為top30、精度為0.95的準確性下,測試端到端的查詢(包括查詢基因轉換向量、向量粗排和Needleman-Wunsch算法的精排)只需要0.257秒,相比Blast的3.22秒,ADB提升了12.5倍,如實驗三結果所示。
表 3. 實驗三結果
算法
響應時間(秒)
Blast
3.27
ADB
0.257
附錄
[1] blast+ https://ftp.ncbi.nlm.nih.gov/blast/executables/blast+/LATEST/.
[4] Needleman, Saul B. & Wunsch, Christian D. (1970). "A general method applicable to the search for similarities in the amino acid sequence of two proteins". Journal of Molecular Biology. 48 (3): 443–53. doi:10.1016/0022-2836(70)90057-4. PMID 5420325.
[5] Mikolov Tomas; et al. (2013). "Efficient Estimation of Word Representations in Vector Space". arXiv:1301.3781.
[6] 基因數據集 https://www.ncbi.nlm.nih.gov/genome/viruses/variation/help/flu-help-center/ftp/.
[7] de Groot RJ Baker SC Baric RS et al. Middle East respiratory syndrome coronavirus (MERS-CoV): announcement of the Coronavirus Study Group. J Virol. 2013; 87: 7790-7792.
[8] NC_045512.2.
[9] NC_019843.3.
[10] NC_038294.1.