在開始使用Dataphin前,您需要完成Dataphin實例計算引擎的設置,即配置Dataphin實例的計算集群地址。在后續數據研發過程中,計算引擎用于采集、連接及管理元數據。本文為您介紹如何設置Dataphin實例的計算引擎。
背景信息
前提條件
在開始執行操作前,請確認您已開通Dataphin。如何開通Dataphin請參見開通Dataphin。
操作步驟
- 在管理中心頁面,單擊左側導航欄的計算設置。
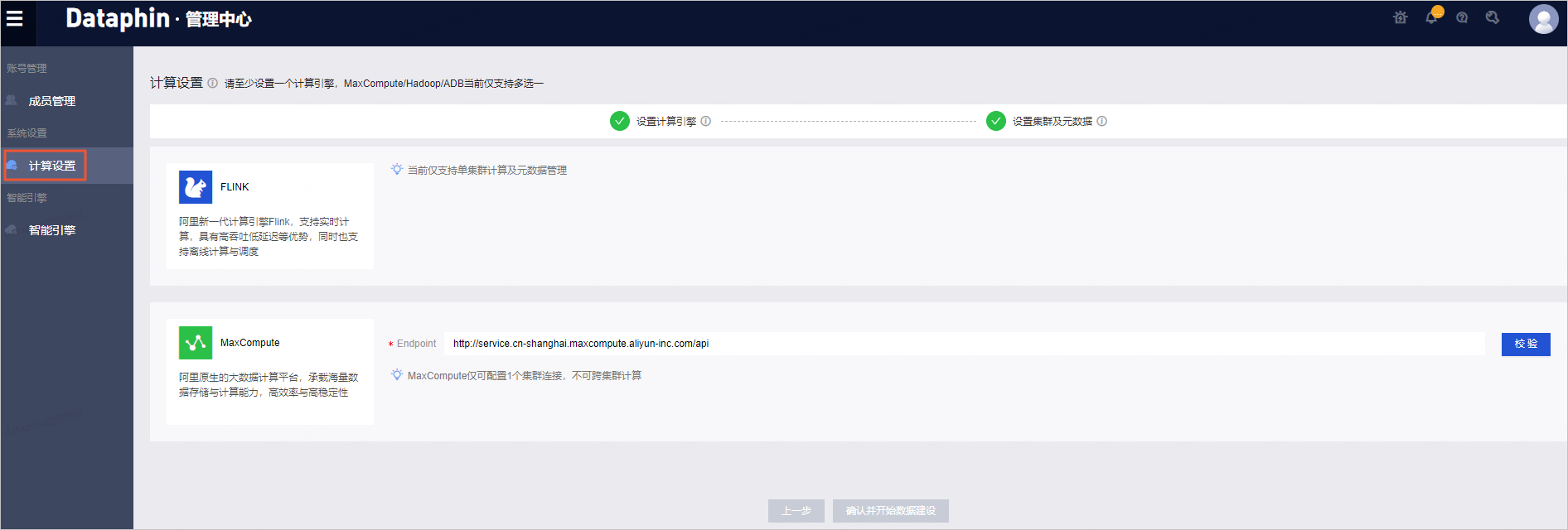
在開始使用Dataphin前,您需要完成Dataphin實例計算引擎的設置,即配置Dataphin實例的計算集群地址。在后續數據研發過程中,計算引擎用于采集、連接及管理元數據。本文為您介紹如何設置Dataphin實例的計算引擎。
在開始執行操作前,請確認您已開通Dataphin。如何開通Dataphin請參見開通Dataphin。