DataScience支持您將自定義DAG轉(zhuǎn)換為Pipeline,并在KubeFlow上運(yùn)行。本文通過示例為您介紹如何將自定義DAG轉(zhuǎn)為Pipeline。
前提條件
- 已創(chuàng)建DataScience集群,并且選擇了Kubeflow服務(wù),詳情請參見創(chuàng)建集群。
- 已通過SSH方式連接DataScience集群,詳情請參見登錄集群。
操作步驟
- 準(zhǔn)備數(shù)據(jù)。例如,將以下JSON表述的DAG運(yùn)行在KubeFlow中,借助dag2pipeline,您可以自定義非常復(fù)雜的spark-sql進(jìn)行特征工程,并設(shè)置好例行化選項(xiàng)。
{ "name": "DataScience", "link": "https://emr.console.aliyun.com/#/cn-beijing/cluster/create", "nodes": [{ "name": "rec_tem_behavior_table_test_preprocess", "database": "xy_rec_sln_test", "type": "SPARKSQL_PARALLEL", "relative_start_date": -4, "relative_end_date": 0, "dependencies": [], "sqlfile": "test/feature/rec_tem_behavior_table_test_preprocess.sql", "args": [ "--num-executors", "1" ], "comment": "sparksql parallel" }, { "name": "rec_tem_user_table_test_preprocess", "database": "xy_rec_sln_test", "type": "SPARKSQL_PARALLEL", "relative_start_date": -4, "relative_end_date": 0, "dependencies": [], "sqlfile": "test/feature/rec_tem_user_table_test_preprocess.sql", "args": [ "--num-executors", "1" ], "comment": "sparksql parallel" }, { "name": "rec_tem_item_table_test_preprocess", "database": "xy_rec_sln_test", "type": "SPARKSQL_PARALLEL", "relative_start_date": -4, "relative_end_date": 0, "dependencies": [], "sqlfile": "test/feature/rec_tem_item_table_test_preprocess.sql", "args": [ "--num-executors", "1" ], "comment": "sparksql parallel" }, { "name": "rec_tem_behavior_table_test_preprocess_wide", "database": "xy_rec_sln_test", "type": "SPARKSQL_PARALLEL", "relative_start_date": -4, "relative_end_date": 0, "dependencies": [ "rec_tem_item_table_test_preprocess", "rec_tem_user_table_test_preprocess", "rec_tem_behavior_table_test_preprocess" ], "sqlfile": "test/feature/rec_tem_behavior_table_test_preprocess_wide.sql", "args": [ "--num-executors", "1" ], "comment": "sparksql parallel" }, { "name": "rec_tem_user_table_test_preprocess_all_feature", "database": "xy_rec_sln_test", "type": "SPARKSQL_PARALLEL", "relative_start_date": -1, "relative_end_date": 0, "dependencies": [ "rec_tem_behavior_table_test_preprocess_wide", "rec_tem_user_table_test_preprocess" ], "sqlfile": "test/feature/rec_tem_user_table_test_preprocess_all_feature.sql", "args": [ "--num-executors", "1" ], "comment": "sparksql parallel" }, { "name": "rec_tem_item_table_test_preprocess_all_feature", "database": "xy_rec_sln_test", "type": "SPARKSQL_PARALLEL", "relative_start_date": -1, "relative_end_date": 0, "dependencies": [ "rec_tem_behavior_table_test_preprocess_wide", "rec_tem_item_table_test_preprocess" ], "sqlfile": "test/feature/rec_tem_item_table_test_preprocess_all_feature.sql", "args": [ "--num-executors", "1" ], "comment": "sparksql parallel" }, { "name": "rec_tem_behavior_table_test_preprocess_rank_sample", "database": "xy_rec_sln_test", "type": "SPARKSQL_PARALLEL", "relative_start_date": 0, "relative_end_date": 0, "dependencies": [ "rec_tem_item_table_test_preprocess_all_feature", "rec_tem_behavior_table_test_preprocess", "rec_tem_user_table_test_preprocess_all_feature" ], "sqlfile": "test/rank/rec_tem_behavior_table_test_preprocess_rank_sample.sql", "args": [ "--num-executors", "1" ], "comment": "sparksql parallel" }, { "name": "insert_rec_tem_user_table_test_preprocess_all_feature_holo", "type": "DI", "dependencies": [ "rec_tem_user_table_test_preprocess_all_feature" ], "dataxjson": "test/feature/1.json", "comment": "DATAX, for more detail please access https://github.com/alibaba/datax" }, { "name": "hadoop_mr_job1", "type": "HADOOP_MR", "dependencies": [ "insert_rec_tem_user_table_test_preprocess_all_feature_holo" ], "jar": "hadoop-mapreduce-examples-2.8.5.jar", "classname": "wordcount", "args": [ "/wordcount/input/", "/wordcount/output%%DATE%%" ], "comment": "jar file should be placed in bigdata directoray." } ] }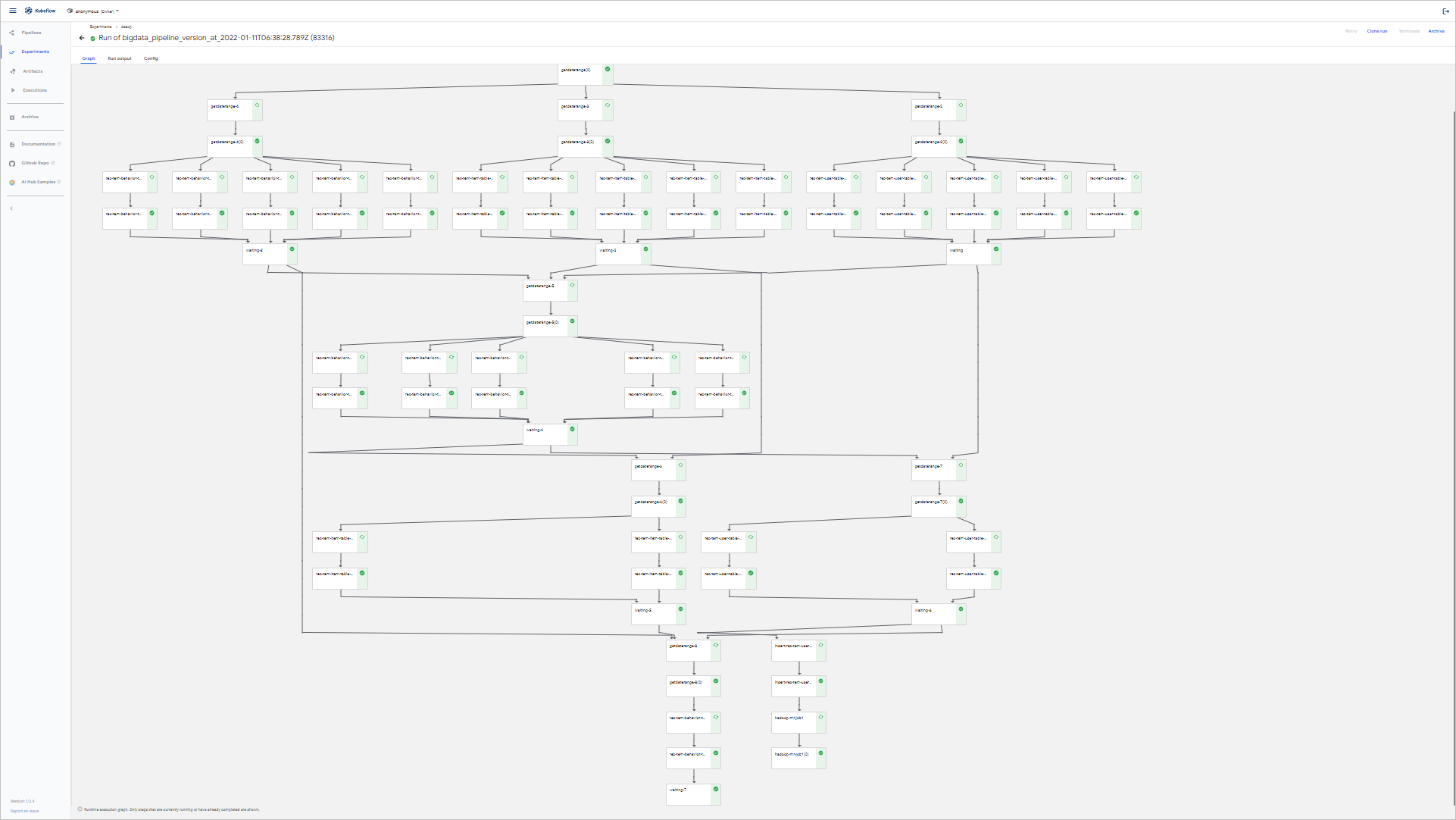
上述代碼示例中,您可以根據(jù)節(jié)點(diǎn)類型,將包放置到相應(yīng)的目錄。
- SPARKSQL_PARALLEL
可以并行執(zhí)行sparksql節(jié)點(diǎn)。代碼詳細(xì)信息如下所示。
{ "name": "rec_tem_behavior_table_test_preprocess", "database": "xy_rec_sln_test", "type": "SPARKSQL_PARALLEL", "relative_start_date": -4, "relative_end_date": 0, "dependencies": [], "sqlfile": "test/feature/rec_tem_behavior_table_test_preprocess.sql", "args": [ "--num-executors", "1" ], "comment": "sparksql parallel" }代碼示例中將test目錄置于bigdata/目錄下。
其中,涉及參數(shù)描述如下:- relative_start_date和relative_end_date:并行執(zhí)行rec_tem_behavior_table_test_preprocess.sql的起止日期。
- args:spark-sql參數(shù)。
- database:spark-sql運(yùn)行的數(shù)據(jù)庫名稱。
- HADOOP_MR
代碼詳細(xì)信息如下所示。
{ "name": "hadoop_mr_job1", "type": "HADOOP_MR", "dependencies": [ "insert_rec_tem_user_table_test_preprocess_all_feature_holo" ], "jar": "hadoop-mapreduce-examples-2.8.5.jar", "classname": "wordcount", "args": [ "/wordcount/input/", "/wordcount/output%%DATE%%" ], "comment": "jar file should be placed in bigdata directoray." }代碼示例中將hadoop-mapreduce-examples-2.8.5.jar置于bigdata/目錄下。
其中,涉及參數(shù)描述如下:- args:Hadoop Job的參數(shù)。
- jar:Hadoop Job的JAR包。
- classname:JAR包內(nèi)的ClassName。
- DI/DATAX
代碼詳細(xì)信息如下所示。
{ "name": "insert_rec_tem_user_table_test_preprocess_all_feature_holo", "type": "DI", "dependencies": [ "rec_tem_user_table_test_preprocess_all_feature" ], "dataxjson": "test/feature/1.json", "comment": "DATAX, for more detail please access https://github.com/alibaba/datax" }代碼示例中將test目錄置于bigdata/下。
其中,參數(shù)dataxjson表示DataX Job的參數(shù),詳細(xì)信息請參見DataX。
- SPARKSQL_PARALLEL