本文通過示例為您介紹如何使用Easyrec算法庫進行模型訓練、部署在線服務,并形成例行化Pipeline工作流。
前提條件
- 已創建DataScience集群,并且選擇了Kubeflow服務,詳情請參見創建集群。
- 本地安裝了PuTTY和文件傳輸工具(SSH Secure File Transfer Client)。
- 下載dsdemo代碼:請已創建DataScience集群的用戶,使用釘釘搜索釘釘群號32497587加入釘釘群以獲取dsdemo代碼。
操作流程
步驟一:準備工作
- 可選:安裝軟件包。
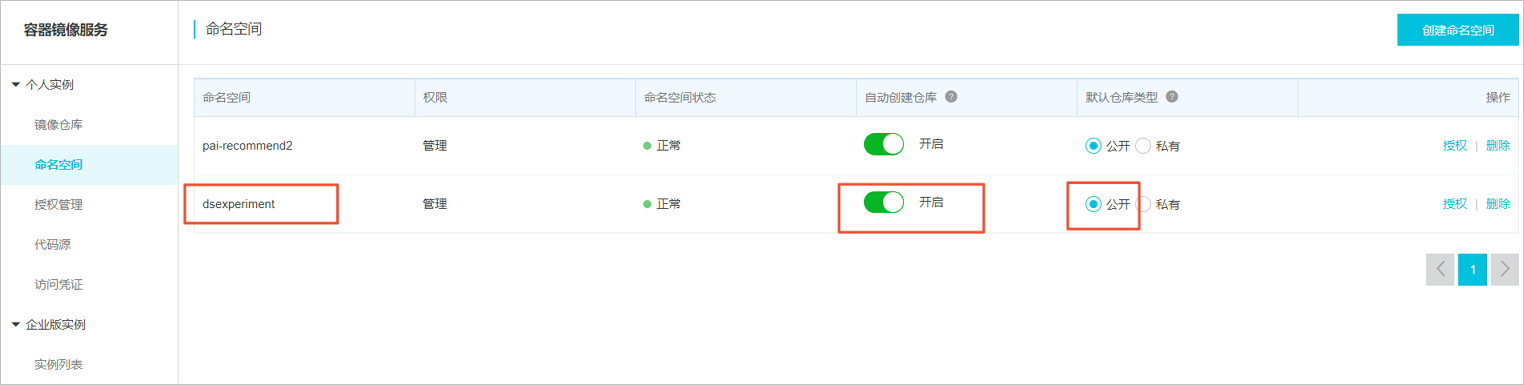
- 登錄容器鏡像服務控制臺,開通個人免費版ACR,并創建命名空間。
- 修改config文件的REGISTRY地址和experiment命名空間名稱,并登錄ACR。
- 掛載NAT網關訪問ACR,詳情請參見創建和管理公網NAT網關實例。
- 準備測試數據。重要 您可以將測試數據寫到DataScience集群的HDFS中,也可以按需寫到您自己的HDFS中,但需要保證網絡暢通。
# 選ppd, prepare test data. sh allinlone.sh根據返回信息提示,選擇
ppd) Prepare data。
 創建命名空間詳情,請參見
創建命名空間詳情,請參見步驟二:提交任務
重要 需要修改config的REPOSITORY地址為您自己的ACR倉庫地址、VERSION版本號以及experiment命名空間名稱。
- 執行allinone.sh文件。
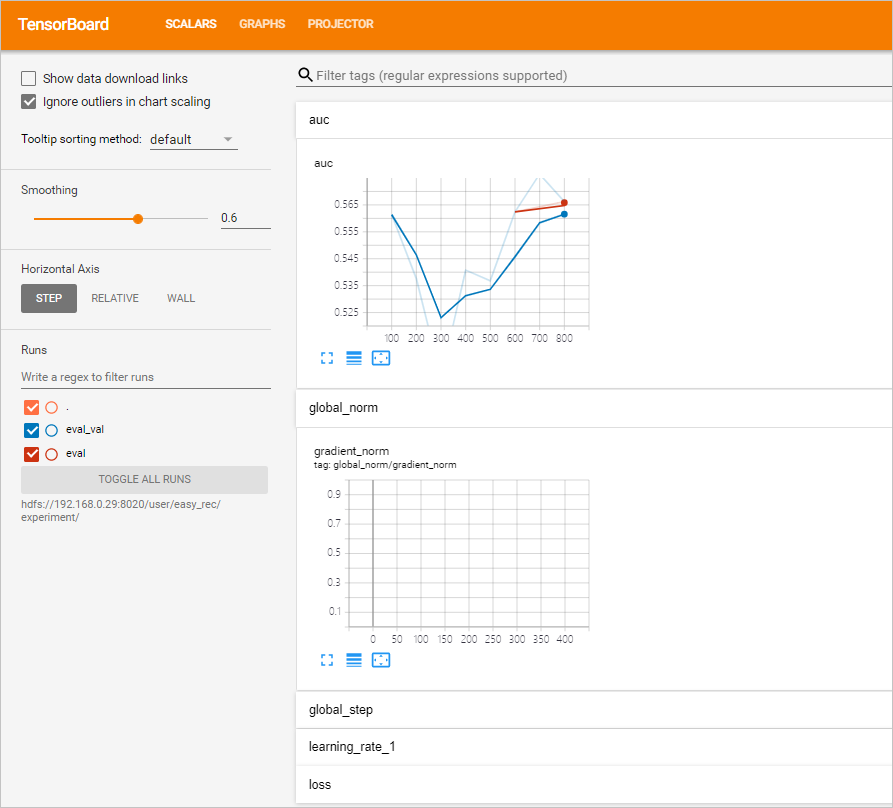
sh allinone.sh -d返回信息如下。loading ./config You are now working on k8snamespace: default *** Welcome to DataScience *** 0) Exit k8s: default ppd) Prepare data ppk) Prepare DS/K8S config cacr) checking ACR 1|build) build training image bnt) build notebook image buildall) build all images(slow) dck) deletecheckpoint ser) showevalresult apc) applyprecheck dpc) deleteprecheck 2) applytraining 3) deletetraining 4) applyeval 5) deleteeval 4d) applyevaldist 5d) deleteevaldist 4hr) applyevalhitrate 5hr) deleteevalhitrate 6) applyexport 7) deleteexport 8) applyserving 9) deleteserving 10) applypredict 11) deletepredict 12) applyfeatureselection 13) deletefeatureselection 14) applycustomizeaction 15) deletecustomizeaction 16) applypytorchtraining 17) deletepytorchtraining mt) multidaystraining dmt) deletemultidaystraining me) multidayseval dme) deletemultidayseval cnt) createnotebook dnt) deletenotebook snt) shownotebooklink cft) createsftp dft) deletesftp sft) showsftplink che) createhue dhe) deletehue she) showhuelink chd) createhttpd dhd) deletehttpd shd) showhttpdlink cvs) createvscode dvs) deletevscode svs) showvscodelink a) kubectl get tfjobs b) kubectl get sdep c) kubectl get pytorchjobs mp|mpl) compile mlpipeline bp|bpl) compile bdpipeline bu) bdupload tb) tensorboard vc) verifyconfigfile spl) showpaireclink tp) kubectl top pods tn) kubectl top nodes util) show nodes utils logs) show pod logs setnl) set k8s node label e|clean) make clean cleanall) make cleanall sml) showmilvuslink sall) show KubeFlow/Grafana/K8SOverview/Spark/HDFS/Yarn/EMR link 99) kubectl get pods 99l) kubectl get pods along with log url > - 輸入選項并單擊回車。您可以通過Tensorboard查看訓練過程中的auc曲線:
- 執行以下命令,進入ml_on_ds目錄。
sudo cd /root/dsdemo/ml_on_ds - 執行以下命令,運行Tensorboard。
sh run_tensorboard.sh選擇
tb, 會顯示當前實驗的ckpt的Tensorboard信息,或者執行sh run_tensorboard.sh 20211209命令,查看20211209訓練ckpt的Tensorboard信息。說明- 默認使用config里TODAY_MODELDIR的modeldir。您也可以指定日期的modeldir,例如
sh run_tensorboard.sh hdfs://192.168.**.**:9000/user/easy_rec/20210923/。 - 您可以自行修改run_tensorboard.sh腳本內容,調整相應的參數。
- 默認使用config里TODAY_MODELDIR的modeldir。您也可以指定日期的modeldir,例如
- 您可以在瀏覽器訪問http://<yourPublicIPAddress>:6006,查看auc曲線。
- 執行以下命令,進入ml_on_ds目錄。
(可選)步驟三:制作Hive CLI、Spark CLI、dscontroller、Hue、notebook或httpd鏡像
說明
- 制作Hive CLI或Spark CLI鏡像的目的是提交Hive或Spark任務進行大數據處理,生成待訓練的數據,如果您已經自行準備好數據,可以跳過本步驟。如果是Spark任務,則會直接使用DataScience集群自帶的Spark集群,如果是Hive任務,需要使用單獨的Hadoop或Hive集群。
- dscontroller鏡像用來進行動態擴縮容。
- Hive CLI進入Hive CLI目錄并制作鏡像。
cd hivecli && make - Spark CLI進入Spark CLI目錄并制作鏡像。
cd sparkcli && make - dscontroller進入dscontroller目錄并制作鏡像。
cd dscontroller && make - Hue進入Hue目錄并制作鏡像。
cd hue && make - notebook進入notebook目錄并制作鏡像。
cd notebook && make - httpd進入httpd目錄并制作鏡像。
cd httpd && make
步驟四:編譯Pipeline
Pipeline代碼具體請參見mlpipeline.py。
- 執行以下命令,進入/ml_on_ds目錄。
sudo cd /root/dsdemo/ml_on_ds - 執行以下命令,編譯Pipeline。
make mpl說明 您也可以執行命令sh allinone.sh,選擇mpl來編譯Pipeline。編譯成功后生成***_mlpipeline.tar.gz文件。您可以使用文件傳輸工具將編譯出來的***_mlpipeline.tar.gz文件,下載到本地PC,便于后續上傳。
步驟五:上傳Pipeline文件
- 進入集群詳情頁面。
- 登錄阿里云E-MapReduce控制臺。
- 在頂部菜單欄處,根據實際情況選擇地域和資源組。
- 單擊上方的集群管理頁簽。
- 在集群管理頁面,單擊相應集群所在行的詳情。
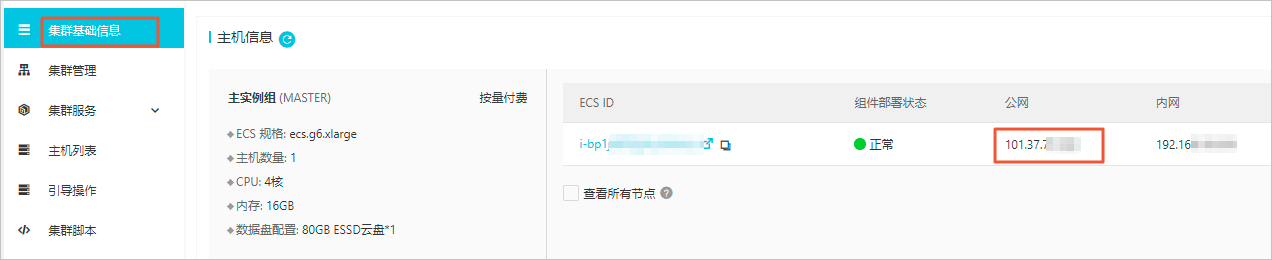
- 在集群基礎信息頁面的主機信息區域,查看公網IP地址。
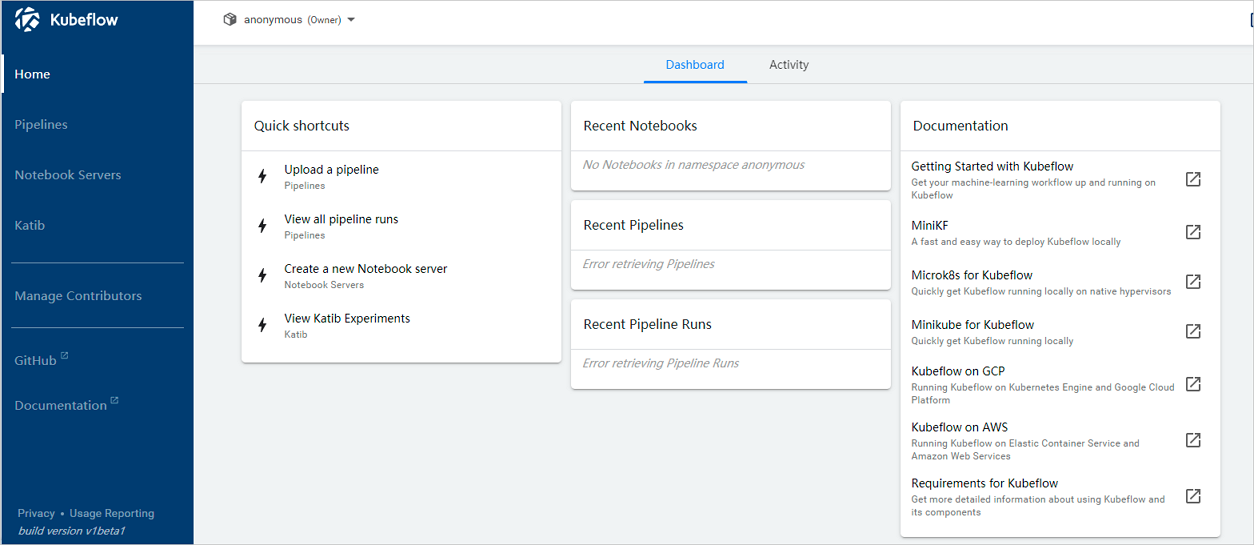
- 在地址欄中,輸入http://<yourPublicIPAddress>:31380,按回車鍵。使用默認的anonymous空間即可。進入后,默認頁面如下。說明 <yourPublicIPAddress>為您前一步驟中,獲取的公網IP地址。
- 在左側導航欄,單擊Pipelines。
- 在Pipelines頁面,單擊Upload pipeline。
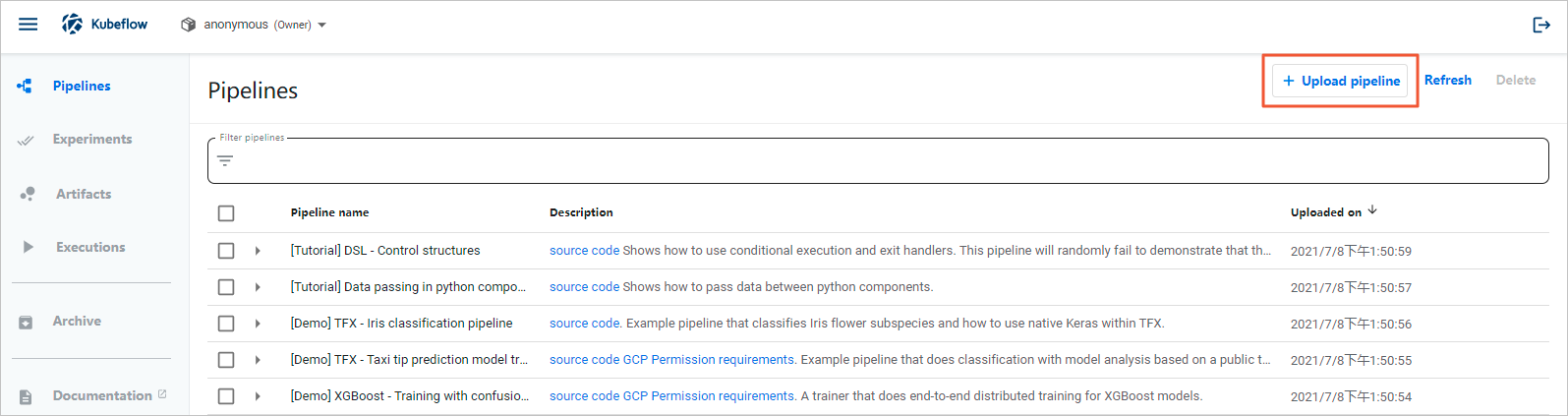
- 在Upload Pipeline or Pipeline Version,輸入Pipeline Name,選擇編譯出的文件。
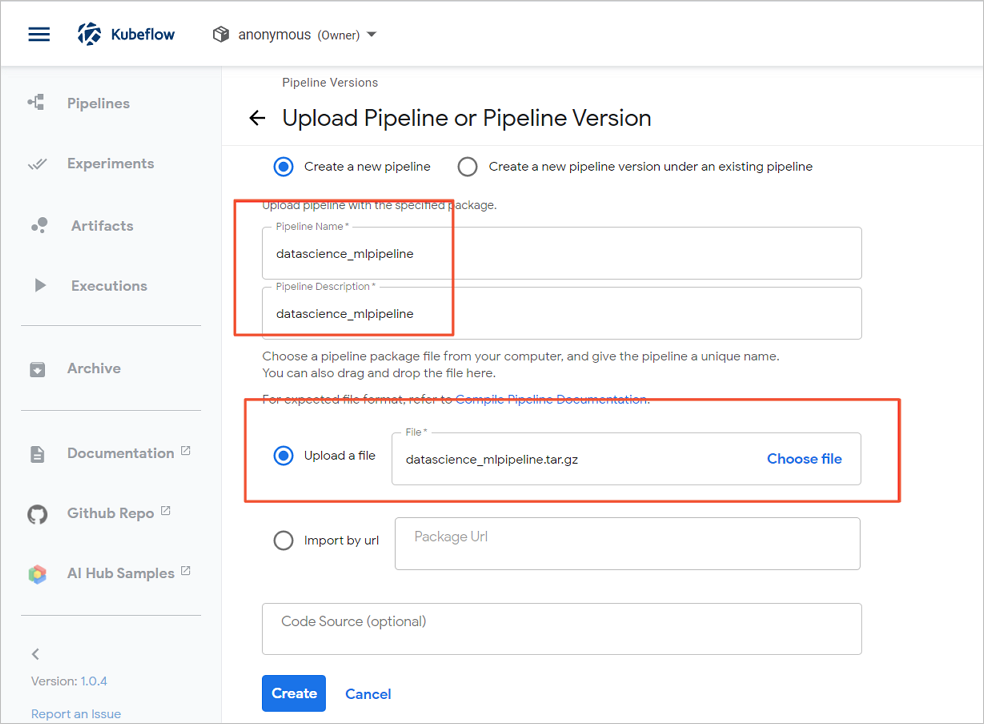
- 單擊Create。
步驟六:創建并運行Experiments
- 在Kubeflow的左側導航欄,單擊Experiments。
- 單擊上方的Create experiment。
- 在New experiment頁面,輸入Experiment name。
- 單擊Next。
- 在Start a run頁面,配置參數。
- 選擇步驟四:編譯Pipeline下載到本地的文件。
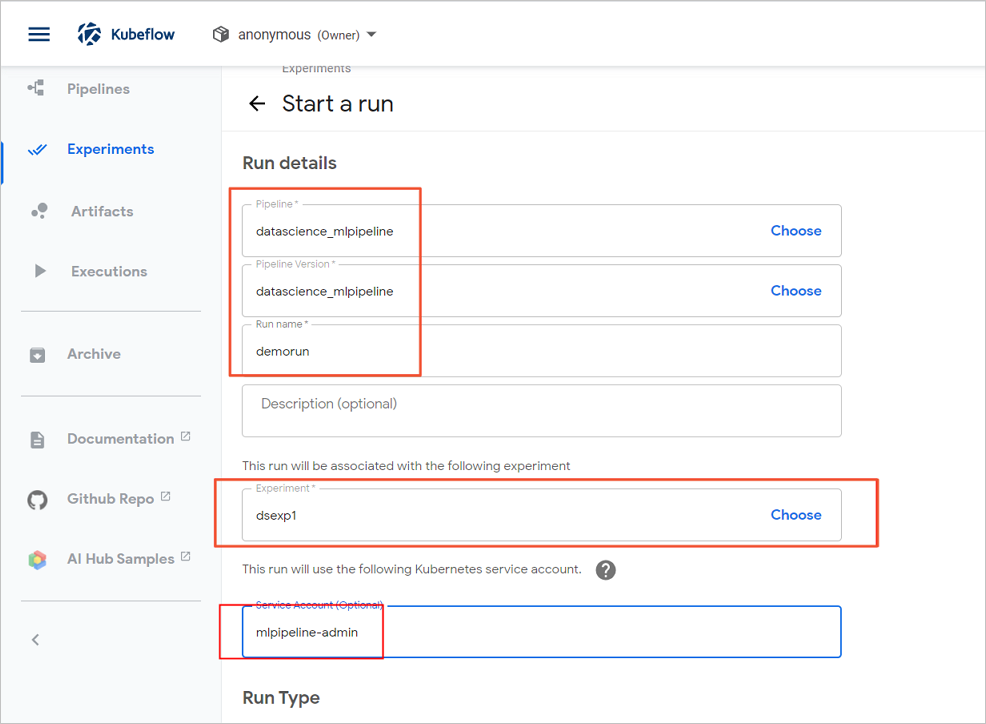
- 單擊Recurring。
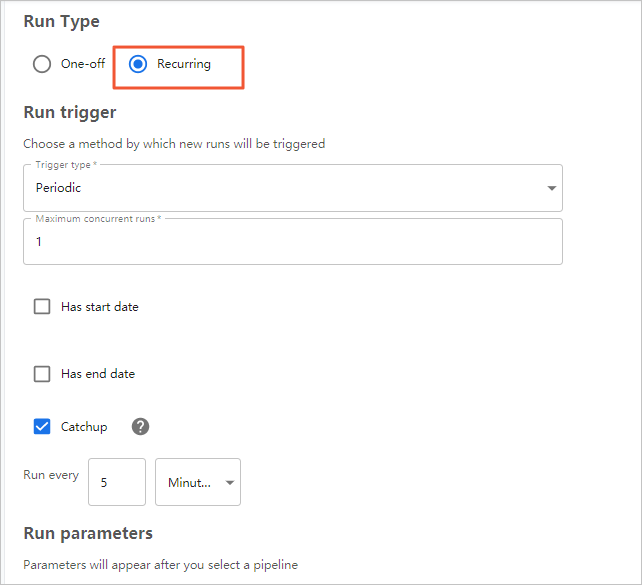
- 選擇步驟四:編譯Pipeline下載到本地的文件。
- 單擊Start。
(可選)步驟七:查看Pipeline狀態
您可以在Experiments中查看Pipeline狀態,模型示例展示如下。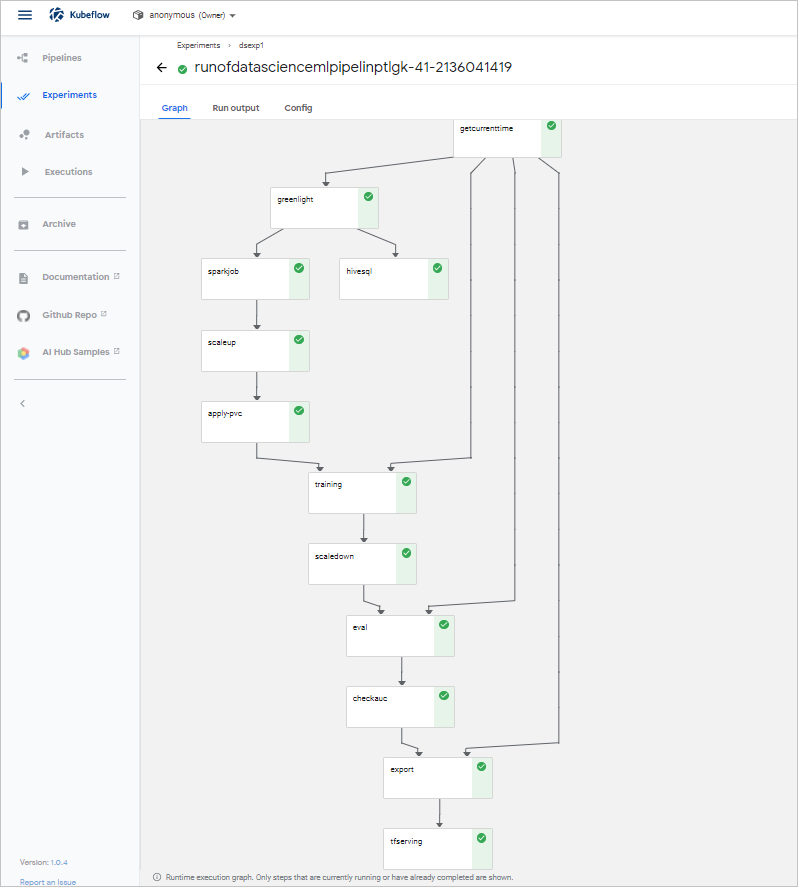
步驟八:模型預測
- (推薦)使用HTTP請求方式
此方式支持任何開發語言。預測代碼請參見predict_rest.sh文件。
您可以執行以下命令進行模型預測。重要 代碼中的default是default命令空間,easyrec-tfserving為部署Serving用的默認名稱,請您按需調整。!/bin/sh curl -X POST http://127.0.0.1:31380/seldon/default/easyrec-tfserving/api/v1.0/predictions -H 'Content-Type: application/json' -d ' { "jsonData": { "inputs": { "app_category":["10","10"], "app_domain":["1005","1005"], "app_id":["0","0"], "banner_pos":["85f751fd","4bf5bbe2"], "c1":["c4e18dd6","6b560cc1"], "c14":["50e219e0","28905ebd"], "c15":["0e8e4642","ecad2386"], "c16":["b408d42a","7801e8d9"], "c17":["09481d60","07d7df22"], "c18":["a99f214a","a99f214a"], "c19":["5deb445a","447d4613"], "c20":["f4fffcd0","cdf6ea96"], "c21":["1","1"], "device_conn_type":["0","0"], "device_id":["2098","2373"], "device_ip":["32","32"], "device_model":["5","5"], "device_type":["238","272"], "hour":["0","3"], "site_category":["56","5"], "site_domain":["0","0"], "site_id":["5","3"] } } }'返回結果如下。{"jsonData":{"outputs":{"logits":[-7.20718098,-4.15874624],"probs":[0.000740694755,0.0153866885]}},"meta":{}} - 使用Seldon庫方式執行以下命令,模型預測REST協議。
python3.7 predict_rest.py返回信息如下。Response: {'jsonData': {'outputs': {'logits': [-2.66068792, 0.691401482], 'probs': [0.0653333142, 0.66627866]}}, 'meta': {}}說明 預測代碼請參見predict_rest.py文件。
步驟九:通過PairecEngine部署在線服務
詳細信息,請參見PAI-Rec使用示例。
問題反饋
如果您在使用DataScience集群過程中有任何疑問或問題,請聯系我們的技術人員協助處理,同時也歡迎您使用釘釘搜索釘釘群號32497587加入釘釘群進行反饋或交流。