在項目中,您可以通過創(chuàng)建作業(yè)來進(jìn)行任務(wù)開發(fā)。本文為您介紹作業(yè)編輯相關(guān)的創(chuàng)建、設(shè)置和運行等操作。
背景信息
本文為您提供作業(yè)編輯的相關(guān)操作,具體如下:
前提條件
已創(chuàng)建項目或已被加入到項目中,詳情請參見項目管理。
新建作業(yè)
- 進(jìn)入數(shù)據(jù)開發(fā)的項目列表頁面。
- 通過阿里云賬號登錄阿里云E-MapReduce控制臺。
- 在頂部菜單欄處,根據(jù)實際情況選擇地域和資源組。
- 單擊上方的數(shù)據(jù)開發(fā)頁簽。
- 單擊待編輯項目所在行的作業(yè)編輯。
- 新建作業(yè)。
設(shè)置作業(yè)
各類作業(yè)類型的開發(fā)與設(shè)置,請參見作業(yè)部分。以下內(nèi)容介紹的是作業(yè)的基礎(chǔ)設(shè)置、高級設(shè)置、共享庫和告警設(shè)置。
- 在作業(yè)設(shè)置面板,設(shè)置基礎(chǔ)信息。
配置項 說明 作業(yè)概要 作業(yè)名稱 您創(chuàng)建作業(yè)的名稱。 作業(yè)類型 您創(chuàng)建作業(yè)的類型。 失敗重試次數(shù) 作業(yè)運行失敗后的重試次數(shù),可以選擇的重試次數(shù)范圍為:0~5次。 失敗策略 作業(yè)運行失敗后支持的策略如下: - 暫停當(dāng)前工作流:作業(yè)運行失敗后,不再繼續(xù)執(zhí)行當(dāng)前工作流。
- 繼續(xù)執(zhí)行下一個作業(yè):作業(yè)運行失敗后,繼續(xù)執(zhí)行下一個作業(yè)。
根據(jù)業(yè)務(wù)情況,可以打開或者關(guān)閉使用最新作業(yè)內(nèi)容和參數(shù)開關(guān)。- 關(guān)閉:作業(yè)失敗后重新執(zhí)行時,使用初始作業(yè)內(nèi)容和參數(shù)生成作業(yè)實例。
- 打開:作業(yè)失敗后重新執(zhí)行時,使用最新的作業(yè)內(nèi)容和參數(shù)生成作業(yè)實例。
作業(yè)描述 單擊右側(cè)的編輯,可以修改作業(yè)的描述。 運行資源 單擊右側(cè)的  圖標(biāo),添加作業(yè)執(zhí)行所依賴的JAR包或UDF等資源。
圖標(biāo),添加作業(yè)執(zhí)行所依賴的JAR包或UDF等資源。
您需要將資源先上傳至OSS,然后在運行資源中直接添加即可。
配置參數(shù) 指定作業(yè)代碼中所引用的變量的值。您可以在代碼中引用變量,格式為${變量名}。 單擊右側(cè)的
圖標(biāo),添加Key和Value,根據(jù)需要選擇是否為Value進(jìn)行加密。其中,Key為變量名,Value為變量的值。另外,您還可以根據(jù)調(diào)度啟動時間在此配置時間變量,詳情請參見作業(yè)日期設(shè)置。
在作業(yè)中添加注解
進(jìn)行數(shù)據(jù)開發(fā)時,您可以通過在作業(yè)內(nèi)容里添加特定的注解來添加作業(yè)參數(shù)。注解的格式如下。
!!! @<注解名稱>: <注解內(nèi)容>說明
!!!必須頂格,并且每行一個注解。
當(dāng)前支持的注解如下。
| 注解名稱 | 說明 | 示例 |
|---|---|---|
| rem | 表示一行注釋。 | |
| env | 添加一個環(huán)境變量。 | |
| var | 添加一個自定義變量。 | |
| resource | 添加一個資源文件。 | |
| sharedlibs | 添加依賴庫,僅對Streaming SQL作業(yè)有效。包含多個依賴庫時,依賴庫間用英文半角逗號(,)隔開。 | |
| scheduler.queue | 設(shè)置提交隊列。 | |
| scheduler.vmem | 設(shè)置申請內(nèi)存,單位MB。 | |
| scheduler.vcores | 設(shè)置申請的核數(shù)。 | |
| scheduler.priority | 設(shè)置申請的優(yōu)先級,取值范圍為1~100。 | |
| scheduler.user | 設(shè)置提交用戶名。 | |
注意
使用注解時,需要注意以下事項:
- 無效注解將被自動跳過。例如,設(shè)置未知注解、注解內(nèi)容不符合預(yù)期等。
- 注解中的作業(yè)參數(shù)優(yōu)先級高于作業(yè)配置中的參數(shù),如果作業(yè)注解和作業(yè)配置中有相同的參數(shù),則以作業(yè)注解為準(zhǔn)。
作業(yè)注解示例如下: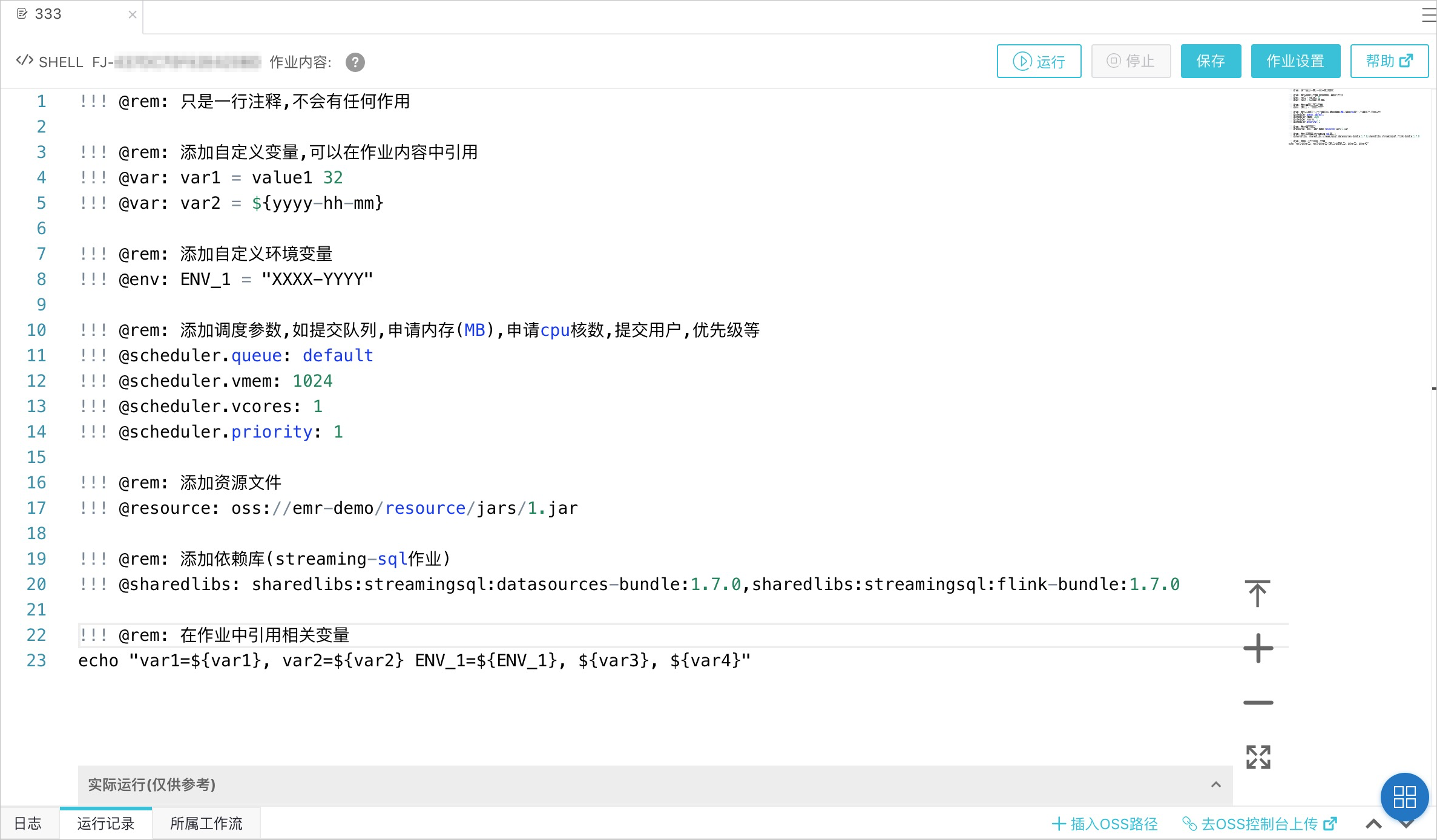
運行作業(yè)
- 執(zhí)行作業(yè)。
- 在新建的作業(yè)頁面,單擊右上方的運行來執(zhí)行作業(yè)。
- 在運行作業(yè)對話框中,選擇資源組和執(zhí)行集群。
- 單擊確定。
- 查看作業(yè)運行日志。
- 作業(yè)運行后,您可以在日志頁簽中查看作業(yè)運行的日志。
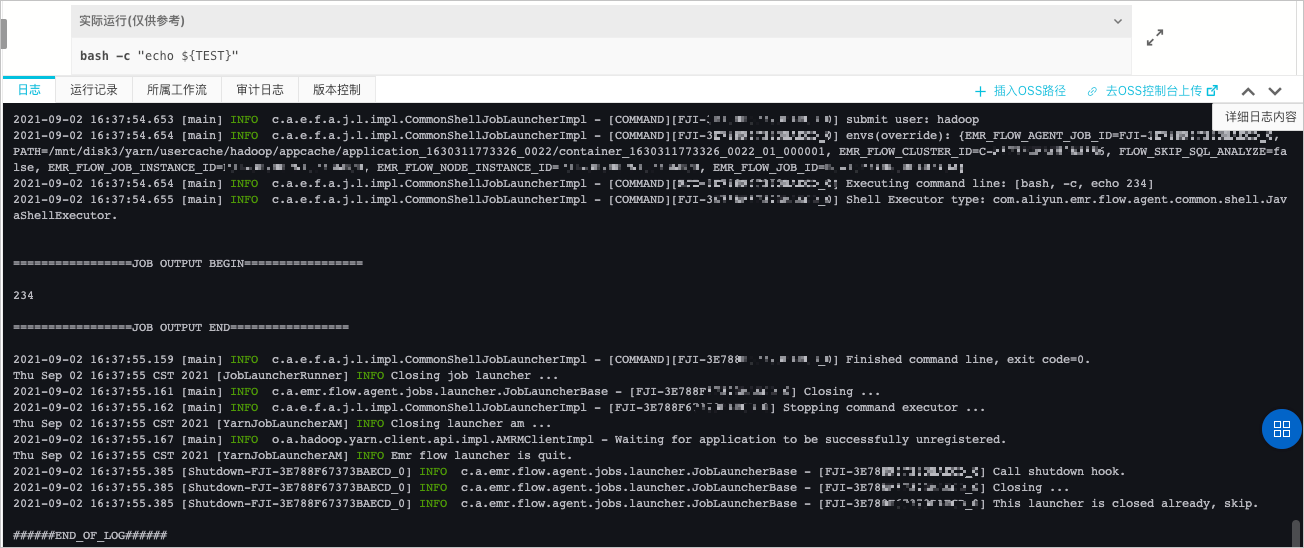
- 作業(yè)運行后,您可以在日志頁簽中查看作業(yè)運行的日志。
作業(yè)可執(zhí)行操作
在作業(yè)編輯區(qū)域,您可以在作業(yè)名稱上單擊右鍵,執(zhí)行如下操作。
| 操作 | 說明 |
|---|---|
| 克隆作業(yè) | 在相同文件夾下,克隆當(dāng)前作業(yè)的配置,生成一個新的作業(yè)。 |
| 重命名作業(yè) | 重新命名作業(yè)名稱。 |
| 刪除作業(yè) | 只有在作業(yè)沒有關(guān)聯(lián)工作流,或關(guān)聯(lián)的工作流沒有在運行或調(diào)度時,才可以被刪除。 |
作業(yè)提交模式說明
Spark-Submit進(jìn)程(在數(shù)據(jù)開發(fā)模塊中為啟動器Launcher)是Spark的作業(yè)提交命令,用于提交Spark作業(yè),一般占用600 MB以上內(nèi)存。作業(yè)設(shè)置面板中的內(nèi)存設(shè)置,用于設(shè)置Launcher的內(nèi)存配額。
新版作業(yè)提交模式包括以下兩種。
| 作業(yè)提交模式 | 描述 |
|---|---|
| 在Header/Gateway節(jié)點提交 | Spark-Submit進(jìn)程運行在Header節(jié)點上,不受YARN監(jiān)控。Spark-Submit內(nèi)存消耗大,作業(yè)過多會造成Header節(jié)點資源緊張,導(dǎo)致整個集群不穩(wěn)定。 |
| 在Worker節(jié)點提交 | Spark-Submit進(jìn)程運行在Worker節(jié)點上,占用YARN的一個Container,受YARN監(jiān)控。此模式可以緩解Header節(jié)點的資源使用。 |
在E-MapReduce集群中,作業(yè)實例消耗內(nèi)存計算方式如下。
作業(yè)實例消耗內(nèi)存 = Launcher消耗內(nèi)存 + 用戶作業(yè)(Job)消耗內(nèi)存在Spark作業(yè)中,用戶作業(yè)(Job)消耗內(nèi)存又可以進(jìn)一步細(xì)分,計算方式如下。
Job消耗內(nèi)存 = Spark-Submit(指邏輯模塊,非進(jìn)程)消耗內(nèi)存 + Driver端消耗內(nèi)存 + Executor端消耗內(nèi)存作業(yè)配置不同,Driver端消耗的物理內(nèi)存的位置也不同,詳細(xì)內(nèi)容如下表。
| Spark使用模式 | Spark-Submit和Driver端 | 進(jìn)程情況 | |
|---|---|---|---|
| Yarn-Client模式 | 作業(yè)提交進(jìn)程使用LOCAL模式 | Spark-Submit和Driver端是在同一個進(jìn)程中。 | 作業(yè)提交進(jìn)程是Header節(jié)點上的一個進(jìn)程,不受YARN監(jiān)控。 |
| 作業(yè)提交進(jìn)程使用YARN模式 | 作業(yè)提交進(jìn)程是Worker節(jié)點上的一個進(jìn)程,占用YARN的一個Container,受YARN監(jiān)控。 | ||
| Yarn-Cluster模式 | Driver端是獨立的一個進(jìn)程,與Spark-Submit不在一個進(jìn)程中。 | Driver端占用YARN的一個Container。 | |