Impala為存儲在Apache Hadoop中的數據,提供了高性能和低延遲的SQL查詢。 使用Impala,您可以通過SELECT、JOIN和聚合函數實時查詢存儲在HDFS或HBase中的數據。
背景信息
Impala使用與Apache Hive相同的元數據、SQL語法(Hive SQL)和ODBC驅動程序等,為面向批處理或實時查詢提供了一個熟悉且統一的平臺。
注意事項
如果使用Impala組件,請勿直接通過系統文件刪除hive表分區目錄,請使用Impala或者Hive命令刪除,否則會導致該表不可用。
優點
為了避免延遲,Impala沒有使用MapReduce,而是使用分布式查詢引擎直接訪問數據,該引擎與RDBMS中的查詢引擎相似,其性能比Hive快了幾個數量級,具體取決于查詢和配置的類型。
- 由于在數據節點上進行了本地處理,因此避免了網絡的限制。
- 由于無需進行昂貴的數據格式轉換,因此不會產生任何費用。
- 可以使用單個、開放和統一的元數據存儲。
- 所有數據均可立即查詢,無需等待ETL(Extract-transform-load)。
- 所有硬件均用于Impala查詢以及MapReduce。
- 僅需單個計算機池即可擴展。
Impala的詳細信息,請參見Apache Impala。
架構
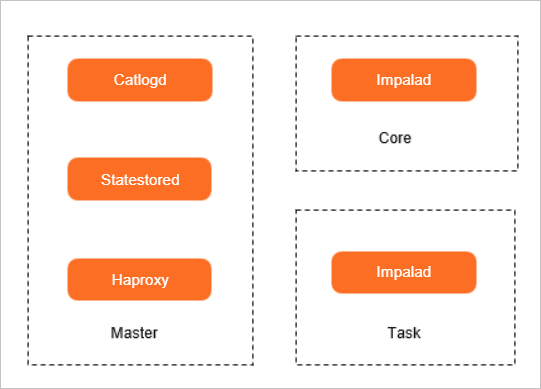
- Impalad
部署在Core節點和Task節點,允許擴容和縮容。
Impala的核心組件是運行在各個節點上的Impala Daemon,進程名為Impalad,負責讀取和寫入數據文件,接收從
impala-shell命令、Hue、JDBC或ODBC等接口發送的查詢語句,并行查詢語句和分發工作任務到集群的各個Impala節點上,同時負責將本地計算好的查詢結果發送回協調器節點(Coordinator Node)。 - Statestored
部署在Master節點的master-1-1機器。
Statestore服務對應的進程名為Statestored,負責管理集群中所有Impalad進程的健康狀態,并將狀況結果轉發到所有Impalad進程。當某一個Impalad進程由于節點異常、網絡異常或軟件問題等導致節點不可用時,StateStore確保將狀況結果通知其他Impalad進程,當有新的查詢請求時,Impalad進程將不會發送查詢請求到該不可用的節點。
- Catalogd
部署在Master節點的master-1-1機器。
Catalogd負責將每個Impalad進程上的元數據變動同步到集群內其他Impalad進程。由于所有的請求都是通過StateStore進程傳遞的,所以建議StateStore和Catalog運行在同一個節點上。