將Kafka數據實時導入到OSS等湖存儲中來降低存儲成本或者進行查詢分析是常見的使用場景。在EMR-3.37.1及之后的版本中,DataFlow集群內置了JindoFS相關的依賴,使得您可以在DataFlow集群中運行Flink作業,將Kafka數據以Exactly-Once語義流式寫入阿里云OSS。本文通過示例為您介紹如何在DataFlow集群中編寫并運行Flink作業來滿足上述場景。
背景信息
關于JindoFS的部分高級配置(例如,熵注入),請參見支持Flink可恢復性寫入JindoFS或OSS。
前提條件
- 已開通E-MapReduce服務和OSS服務。
- 已完成云賬號的授權,詳情請參見角色授權。
操作流程
步驟一:準備環境
步驟二:準備JAR包
下載Demo代碼。
基于JindoFS,您可以在Flink作業中,如同HDFS一樣將數據以流式的方式寫入OSS中(路徑需要以oss://為前綴)。本示例中使用了Flink的StreamingFileSink方法來演示開啟了檢查點(Checkpoint)之后,Flink如何以Exactly-Once語義寫入OSS。
下述代碼片段演示了如何構建Kafka Source與OSS Sink,完整代碼您可以從GitHub鏈接中下載獲得。
重要JindoFS支持免密讀寫相同阿里云賬號下的OSS存儲,因此作業中無需聲明相關AccessKey信息。
public class OssDemoJob { public static void main(String[] args) throws Exception { ... // Check output oss dir Preconditions.checkArgument( params.get(OUTPUT_OSS_DIR).startsWith("oss://"), "outputOssDir should start with 'oss://'."); // Set up the streaming execution environment final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // Checkpoint is required env.enableCheckpointing(30000, CheckpointingMode.EXACTLY_ONCE); String outputPath = params.get(OUTPUT_OSS_DIR); // Build Kafka source with new Source API based on FLIP-27 KafkaSource<Event> kafkaSource = KafkaSource.<Event>builder() .setBootstrapServers(params.get(KAFKA_BROKERS_ARG)) .setTopics(params.get(INPUT_TOPIC_ARG)) .setStartingOffsets(OffsetsInitializer.latest()) .setGroupId(params.get(INPUT_TOPIC_GROUP_ARG)) .setDeserializer(new EventDeSerializationSchema()) .build(); // DataStream Source DataStreamSource<Event> source = env.fromSource( kafkaSource, WatermarkStrategy.<Event>forMonotonousTimestamps() .withTimestampAssigner((event, ts) -> event.getEventTime()), "Kafka Source"); StreamingFileSink<Event> sink = StreamingFileSink.forRowFormat( new Path(outputPath), new SimpleStringEncoder<Event>("UTF-8")) .withRollingPolicy(OnCheckpointRollingPolicy.build()) .build(); source.addSink(sink); // Compile and submit the job env.execute(); } }說明本示例代碼片段給出了主要的示例程序,您可以根據自身環境進行修改(例如,添加包名以及修改代碼中的Checkpoint間隔)后,進行編譯。關于如何構建Flink作業的JAR包,可以參見Flink官方文檔。如果無需任何修改,您可以直接使用 dataflow-oss-demo-1.0-SNAPSHOT.jar 包進行操作。
在命令行中,進入到下載的項目文件的根目錄下,執行以下命令打包文件。
mvn clean package根據您pom.xml文件中artifactId的信息,項目對應目錄dataflow-demo/dataflow-oss-demo/target下會出現dataflow-oss-demo-1.0-SNAPSHOT.jar包。
步驟三:創建Kafka Topic并生成數據
通過SSH方式連接DataFlow集群,詳情請參見登錄集群。
執行以下命令,創建測試所需的Topic。
kafka-topics.sh --create --bootstrap-server core-1-1:9092 \ --replication-factor 2 \ --partitions 3 \ --topic kafka-test-topic創建成功后,命令行會打印如下信息。
Created topic kafka-test-topic.寫入數據至Kafka Topic。
在命令行中執行以下命令,進入Kafka Producer Console。
kafka-console-producer.sh --broker-list core-1-1:9092 --topic kafka-test-topic輸入五條測試數據。
1,Ken,0,1,1662022777000 1,Ken,0,2,1662022777000 1,Ken,0,3,1662022777000 1,Ken,0,4,1662022777000 1,Ken,0,5,1662022777000按下Ctrl+C退出Kafka Producer Console。
步驟四:運行Flink作業
通過SSH方式連接DataFlow集群,詳情請參見登錄集群。
上傳打包好的dataflow-oss-demo-1.0-SNAPSHOT.jar至DataFlow集群的根目錄下。
說明本文示例中dataflow-oss-demo-1.0-SNAPSHOT.jar是上傳至root根目錄下,您也可以自定義上傳路徑。
執行以下命令,提交作業。
本示例通過Per-Job Cluster模式提交作業,其他方式請參見基礎使用。
flink run -t yarn-per-job -d -c com.alibaba.ververica.dataflow.demo.oss.OssDemoJob \ /dataflow-oss-demo-1.0-SNAPSHOT.jar \ --outputOssDir oss://xung****-flink-dlf-test/oss_kafka_test \ --kafkaBrokers core-1-1:9092 \ --inputTopic kafka-test-topic \ --inputTopicGroup my-group參數說明:
outputOssDir:指定您計劃寫入的OSS目錄。
kafkaBrokers:指定Kafka集群的broker,使用
core-1-1:9092即可。inputTopic:指定計劃讀取的Kafka Topic,使用在步驟三中創建的
kafka-test-topic。inputTopicGroup:指定計劃使用的Kafka Consumer Group,使用
my-group用于測試即可。

您可以執行以下命令,查看作業狀態。
flink list -t yarn-per-job -Dyarn.application.id=<appId>說明<appId>為作業運行后返回的Application ID。例如,本示例截圖中的application_1670236019397_0003。
步驟五:查看輸出的結果
作業正常運行后,您可以在OSS控制臺查看輸出結果。
登錄OSS管理控制臺。
單擊創建的存儲空間。
在文件管理頁面指定的輸出目錄下查看輸出結果,輸出結果如下圖所示。
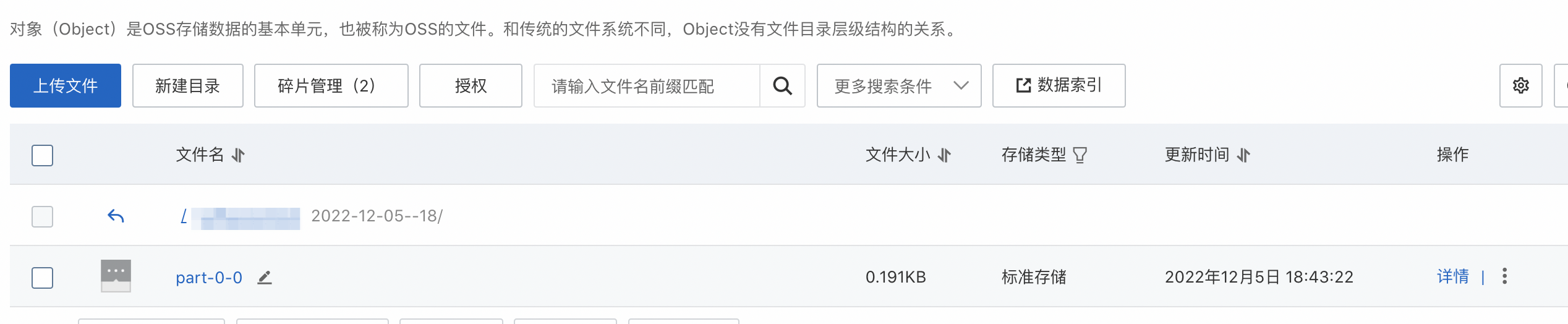 重要
重要由于該作業為流式作業會持續運行,會產生較多輸出文件,應在完成驗證后,及時在命令行中通過
yarn application -kill <appId>命令終止該作業。
您也可以在DataFlow集群中,通過命令行運行
hdfs dfs -cat oss://<YOUR_TARGET_BUCKET>/oss_kafka_test/<DATE_DIR>/part-0-0來展示實際存儲到OSS中的數據,如下圖所示。 重要
重要為了保證Exactly-Once語義,在Flink作業每完成一次Checkpoint(本示例中Checkpoint間隔為30s),數據文件才會落盤到OSS中。
此外,由于該作業為流式作業會持續運行,會產生較多輸出文件,應在完成驗證后,及時在命令行中通過yarn application -kill <appId>命令終止該作業。