本文通過場景化為您介紹如何使用Jindo DistCp。
前提條件
- 已創建相應版本的集群,詳情請參見創建集群。
- 已安裝JDK 1.8。
- 根據您使用的Hadoop版本,下載jindo-distcp-<version>.jar。
- Hadoop 2.7及后續版本,請下載jindo-distcp-3.0.0.jar。
- Hadoop 3.x系列版本,請下載jindo-distcp-3.0.0.jar。
場景預覽
Jindo DistCp常用使用場景如下所示:
- 場景一:導入HDFS數據至OSS,需要使用哪些參數?如果數據量很大、文件很多(百萬千萬級別)時,該使用哪些參數優化?
- 場景二:使用Jindo DistCp成功導完數據后,如何驗證數據完整性?
- 場景三:導入HDFS數據至OSS時,DistCp任務存在隨時失敗的情況,該使用哪些參數支持斷點續傳?
- 場景四:成功導入HDFS數據至OSS,數據不斷增量增加,在Distcp過程中可能已經產生了新文件,該使用哪些參數處理?
- 場景五:如果需要指定Jindo DistCp作業在Yarn上的隊列以及可用帶寬,該使用哪些參數?
- 場景六:當通過低頻或者歸檔形式寫入OSS,該使用哪些參數?
- 場景七:針對小文件比例和文件大小情況,該使用哪些參數來優化傳輸速度?
- 場景八:如果需要使用S3作為數據源,該使用哪些參數?
- 場景九:如果需要寫入文件至OSS上并壓縮(LZO和GZ格式等)時,該使用哪些參數?
- 場景十:如果需要把本次Copy中符合特定規則或者同一個父目錄下的部分子目錄作為Copy對象,該使用哪些參數?
- 場景十一:如果想合并符合一定規則的文件,以減少文件個數,該使用哪些參數?
- 場景十二:如果Copy完文件,需要刪除原文件,只保留目標文件時,該使用哪些參數?
- 場景十三:如果不想將OSS AccessKey這種參數寫在命令行里,該如何處理?
場景一:導入HDFS數據至OSS,需要使用哪些參數?如果數據量很大、文件很多(百萬千萬級別)時,該使用哪些參數優化?
如果您使用的不是EMR環境,當從HDFS上往OSS傳輸數據時,需要滿足以下幾點:
- 可以訪問HDFS,并有讀數據權限。
- 需要提供OSS的AccessKey(AccessKey ID和AccessKey Secret),以及Endpoint信息,且該AccessKey具有寫目標Bucket的權限。
- OSS Bucket不能為歸檔類型。
- 環境可以提交MapReduce任務。
- 已下載Jindo DistCp JAR包。
本場景示例如下。
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --parallelism 10說明 各參數含義請參見Jindo DistCp使用說明。
當您的數量很大,文件數量很多,例如百萬千萬級別時,您可以增大parallelism,以增加并發度,還可以開啟
--enableBatch參數來進行優化。優化命令如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --parallelism 500 --enableBatch場景二:使用Jindo DistCp成功導完數據后,如何驗證數據完整性?
您可以通過以下兩種方式驗證數據完整性:
- Jindo DistCp Counters
您可以在MapReduce任務結束的Counter信息中,獲取Distcp Counters的信息。
Distcp Counters Bytes Destination Copied=11010048000 Bytes Source Read=11010048000 Files Copied=1001 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0參數含義如下:- Bytes Destination Copied:表示目標端寫文件的字節數大小。
- Bytes Source Read:表示源端讀文件的字節數大小。
- Files Copied:表示成功Copy的文件數。
- Jindo DistCp --diff
您可以使用
--diff命令,進行源端和目標端的文件比較,該命令會對文件名和文件大小進行比較,記錄遺漏或者未成功傳輸的文件,存儲在提交命令的當前目錄下,生成manifest文件。在場景一的基礎上增加--diff參數即可,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --diff當全部文件傳輸成功時,系統返回如下信息。INFO distcp.JindoDistCp: distcp has been done completely
場景三:導入HDFS數據至OSS時,DistCp任務存在隨時失敗的情況,該使用哪些參數支持斷點續傳?
在場景一的基礎上,如果您的Distcp任務因為各種原因中間失敗了,而此時您想支持斷點續傳,只Copy剩下未Copy成功的文件,此時需要您在進行上一次Distcp任務完成后進行如下操作:
- 增加一個
--diff命令,查看所有文件是否都傳輸完成。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --diff當所有文件都傳輸完成,則會提示如下信息。INFO distcp.JindoDistCp: distcp has been done completely. - 文件沒有傳輸完成時會生成manifest文件,您可以使用
--copyFromManifest和--previousManifest命令進行剩余文件的Copy。示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --dest oss://yang-hhht/hourly_table --previousManifest=file:///opt/manifest-2020-04-17.gz --copyFromManifest --parallelism 20file:///opt/manifest-2020-04-17.gz為您當前執行命令的本地路徑。
場景四:成功導入HDFS數據至OSS,數據不斷增量增加,在Distcp過程中可能已經產生了新文件,該使用哪些參數處理?
- 未產生上一次Copy的文件信息,需要指定生成manifest文件,記錄已完成的文件信息。
在場景一的基礎上增加
--outputManifest=manifest-2020-04-17.gz和--requirePreviousManifest=false兩個信息,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --outputManifest=manifest-2020-04-17.gz --requirePreviousManifest=false --parallelism 20參數含義如下:--outputManifest:指定生成的manifest文件,文件名稱自定義但必須以gz結尾,例如manifest-2020-04-17.gz,該文件會存放在--dest指定的目錄下。--requirePreviousManifest:無已生成的歷史manifest文件信息。
- 當前一次Distcp任務結束后,源目錄可能已經產生了新文件,這時候需要增量同步新文件。
在場景一的基礎上增加
--outputManifest=manifest-2020-04-17.gz和--previousManifest=oss://yang-hhht/hourly_table/manifest-2020-04-17.gz兩個信息,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --outputManifest=manifest-2020-04-17.gz --requirePreviousManifest=false --parallelism 20hadoop jar jindo-distcp-2.7.3.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --outputManifest=manifest-2020-04-18.gz --previousManifest=oss://yang-hhht/hourly_table/manifest-2020-04-17.gz --parallelism 10 - 重復執行步驟2,不斷同步增量文件。
場景五:如果需要指定Jindo DistCp作業在Yarn上的隊列以及可用帶寬,該使用哪些參數?
在場景一的基礎上需要增加兩個參數。兩個參數可以配合使用,也可以單獨使用。
--queue:指定Yarn隊列的名稱。--bandwidth:指定帶寬的大小,單位為MB。
示例如下。
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --queue yarnqueue --bandwidth 6 --parallelism 10場景六:當通過低頻或者歸檔形式寫入OSS,該使用哪些參數?
- 當通過歸檔形式寫入OSS時,需要在場景一的基礎上增加
--archive參數,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --archive --parallelism 20 - 當通過低頻形式寫入OSS時,需要在場景一的基礎上增加
--ia參數,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --ia --parallelism 20
場景七:針對小文件比例和文件大小情況,該使用哪些參數來優化傳輸速度?
- 小文件較多,大文件較大情況。
如果要Copy的所有文件中小文件的占比較高,大文件較少,但是單個文件數據較大,在正常流程中是按照隨機方式來進行Copy文件分配,此時如果不做優化很可能造成一個Copy進程分配到大文件的同時也分配到很多小文件,不能發揮最好的性能。
在場景一的基礎上增加--enableDynamicPlan開啟優化選項,但不能和--enableBalancePlan一起使用。示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --enableDynamicPlan --parallelism 10優化對比如下。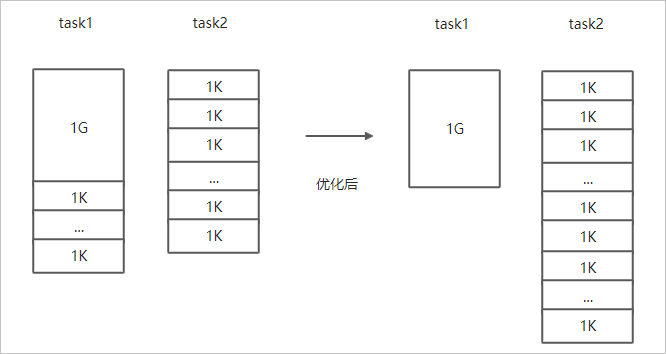
- 文件總體均衡,大小差不多情況。
如果您要Copy的數據里文件大小總體差不多,比較均衡,您可以使用
--enableBalancePlan優化。示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --enableBalancePlan --parallelism 10優化對比如下。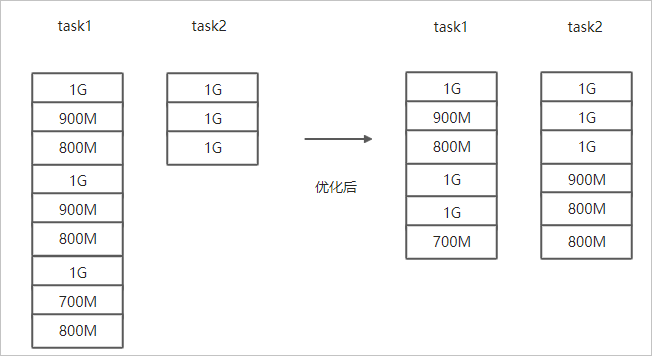
場景八:如果需要使用S3作為數據源,該使用哪些參數?
需要在場景一的基礎上替換OSS的AccessKey和EndPoint信息轉換成S3參數:
--s3Key:連接S3的AccessKey ID。--s3Secret:連接S3的AccessKey Secret。--s3EndPoint:連接S3的EndPoint信息。
示例如下。
hadoop jar jindo-distcp-<version>.jar --src s3a://yourbucket/ --dest oss://yang-hhht/hourly_table --s3Key yourkey --s3Secret yoursecret --s3EndPoint s3-us-west-1.amazonaws.com --parallelism 10場景九:如果需要寫入文件至OSS并壓縮文件(LZO和GZ格式等)時,該使用哪些參數?
如果您想壓縮寫入的目標文件,例如LZO和GZ等格式,以降低目標文件的存儲空間,您可以使用--outputCodec參數來完成。
需要在場景一的基礎上增加
--outputCodec參數,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --outputCodec=gz --parallelism 10Jindo DistCp支持編解碼器GZIP、GZ、LZO、LZOP和SNAPPY以及關鍵字none和keep(默認值)。這些關鍵字含義如下:
- none表示保存為未壓縮的文件。如果文件已壓縮,則Jindo DistCp會將其解壓縮。
- keep表示不更改文件壓縮形態,按原樣復制。
說明 如您在開源Hadoop集群環境中使用LZO壓縮功能,則您需要安裝gplcompression的native庫和hadoop-lzo包,
場景十:如果需要把本次Copy中符合特定規則或者同一個父目錄下的部分子目錄作為Copy對象,該使用哪些參數?
- 如果您需要將Copy列表中符合一定規則的文件進行Copy,需要在場景一的基礎上增加
--srcPattern參數,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --srcPattern .*\.log --parallelism 10--srcPattern:進行過濾的正則表達式,符合規則進行Copy,否則拋棄。 - 如果您需要Copy同一個父目錄下的部分子目錄,需要在場景一的基礎上增加
--srcPrefixesFile參數。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --srcPrefixesFile file:///opt/folders.txt --parallelism 20--srcPrefixesFile:存儲需要Copy的同父目錄的文件夾列表的文件。示例中的folders.txt內容如下。hdfs://emr-header-1.cluster-50466:9000/data/incoming/hourly_table/2017-02-01 hdfs://emr-header-1.cluster-50466:9000/data/incoming/hourly_table/2017-02-02
場景十一:如果想合并符合一定規則的文件,以減少文件個數,該使用哪些參數?
需要在場景一的基礎上增加如下參數:
--targetSize:合并文件的最大大小,單位MB。--groupBy:合并規則,正則表達式。
示例如下。
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --targetSize=10 --groupBy='.*/([a-z]+).*.txt' --parallelism 20場景十二:如果Copy完文件,需要刪除原文件,只保留目標文件時,該使用哪些參數?
需要在場景一的基礎上,增加
--deleteOnSuccess參數,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --deleteOnSuccess --parallelism 10場景十三:如果不想將OSS AccessKey這種參數寫在命令行里,該如何處理?
通常您需要將OSS AccessKey和endPoint信息寫在參數里,但是Jindo DistCp可以將OSS的AccessKey ID、AccessKey Secret和Endpoint預先寫在Hadoop的core-site.xml文件里 ,以避免使用時多次填寫的問題。
- 如果您需要保存OSS的AccessKey相關信息,您需要將以下信息保存在core-site.xml中。
<configuration> <property> <name>fs.jfs.cache.oss-accessKeyId</name> <value>xxx</value> </property> <property> <name>fs.jfs.cache.oss-accessKeySecret</name> <value>xxx</value> </property> <property> <name>fs.jfs.cache.oss-endpoint</name> <value>oss-cn-xxx.aliyuncs.com</value> </property> </configuration> - 如果您需要保存S3的AccessKey相關信息,您需要將以下信息保存在core-site.xml中。
<configuration> <property> <name>fs.s3a.access.key</name> <value>xxx</value> </property> <property> <name>fs.s3a.secret.key</name> <value>xxx</value> </property> <property> <name>fs.s3.endpoint</name> <value>s3-us-west-1.amazonaws.com</value> </property> </configuration>