Spark處理JindoFS上的數據,主要有兩種方式,一種是直接調用文件系統接口使用;一種是通過SparkSQL讀取存在JindoFS的數據表。
JindoFS配置
以EMR-3.35版本為例,創建名為emr-jfs的命名空間,相關配置參數示例如下:
- jfs.namespaces=emr-jfs
- jfs.namespaces.emr-jfs.oss.uri=oss://oss-bucket/oss-dir
- jfs.namespaces.emr-jfs.mode=block
處理JindoFS上的數據
- 調用文件系統
Spark中讀寫JindoFS上的數據,與處理其他文件系統的數據類似,以RDD操作為例,直接使用jfs的路徑即可:
val a = sc.textFile("jfs://emr-jfs/README.md")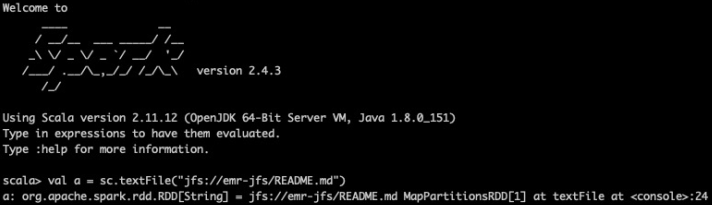
寫入數據:
scala> a.collect().saveAsTextFile("jfs://emr-jfs/output") - SparkSQL
創建數據庫、數據表以及分區時指定Location到JindoFS即可,SparkSQL處理JindoFS上的數據與HiveSQL類似,詳情請參見使用Hive查詢JindoFS上的數據。對于已經創建好的存儲在JindoFS上的數據表,直接查詢即可。