本文將介紹StarRocks遷移至EMR Serverless的整體解決方案及具體遷移步驟。該遷移方案僅供參考,您需要結合實際業務情況進行調整與優化,以更好地滿足您的需求。
遷移流程
整體遷移流程如下圖所示,涵蓋了作業改寫、作業雙跑、數據校驗、業務校驗以及割接等多個步驟。

前期評估
確認當前集群情況
請確認當前集群的基本情況,包括集群的版本,FE規格和數量,BE規格和數量,以及負載等信息。
集群信息 | 集群信息 | 配置示例 |
FE配置 | 機型配置 | 通用型ecs.g7.4xlarge 16 Core 64 GB 系統盤:ESSD PL1 云盤 100 GB * 1塊 數據盤:ESSD PL1 云盤 100 GB * 1塊 |
節點數量 | 3臺 | |
BE配置 | 機型配置 | 通用型ecs.g7.4xlarge 16 Core 64 GB 系統盤:ESSD PL1 云盤 100 GB * 1塊 數據盤:ESSD PL1 云盤 1000 GB * 4塊 |
節點數量 | 3臺 | |
StarRocks版本號 | - | 例如:2.5.13 |
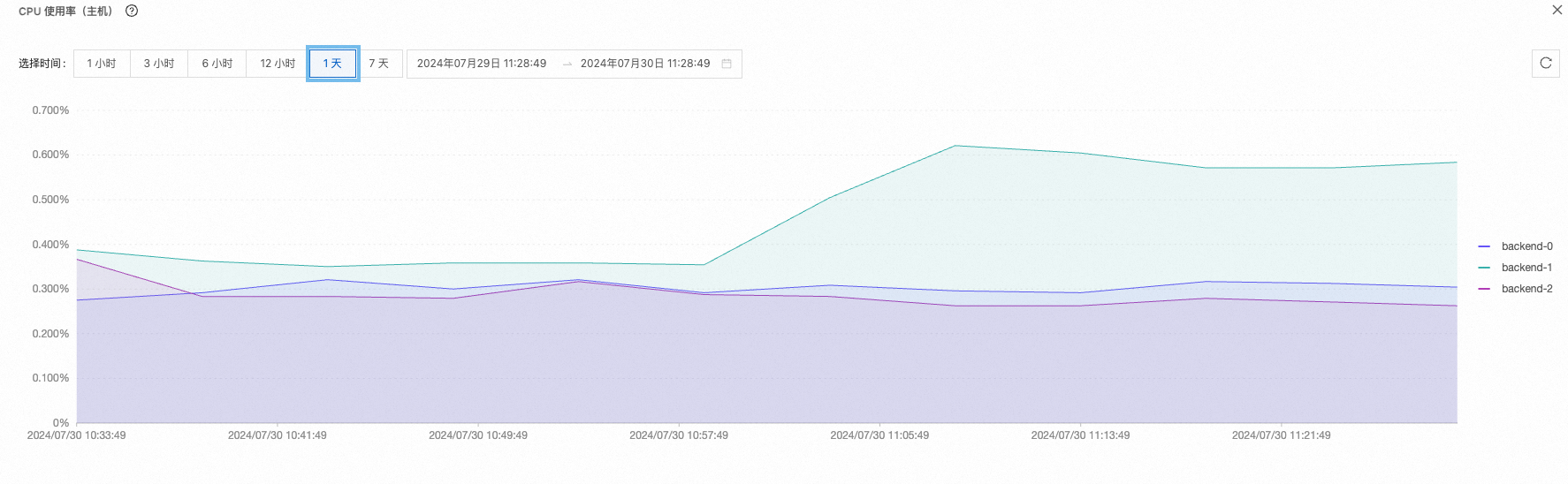
集群負載 | CPU負載 | 高峰:82.9% 低峰:50.3%
|
MEM負載 | 高峰:82.9% 低峰:50.3%
| |
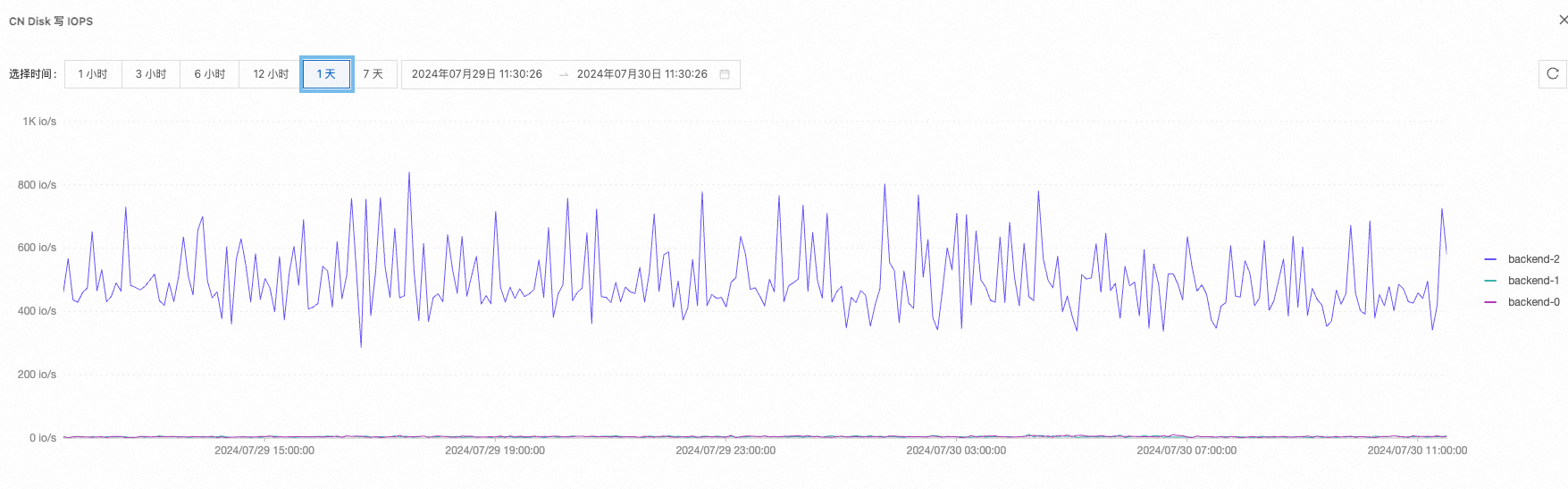
磁盤IOPS負載 | 高峰:10504 低峰:1003
| |
磁盤IO負載 | 高峰:514 MB/s 低峰:15 MB/s
|
確認業務使用情況
以下信息僅為配置示例,實際應用時需根據具體情況調整。
數據導入方式
數據導入方式
數據寫入分類
每日數據增量
每日新行數
任務數
實時寫入(Flink)
實時數據
10 GB
1 億行
80
Kafka + Routine
實時數據
10 GB
1 億行
20
離線導入(Spark Connector、DataX)
離線數據
10 GB
1 億行
120
物化視圖使用情況
物化視圖
任務數
同步頻率
同步物化視圖
12個
無
異步物化視圖
89個
大部分為每小時更新
Insert Overwrite
120個
大部分為每半小時更新
確認業務能夠接受的停服時間
為了確保業務連續性,必須提前評估業務能夠接受的停服時間。整個遷移的停服時間取決于具體方案,通常在30分鐘至半天左右不等。因此,務必提前與業務方進行充分溝通,明確預期停服時間。
新建目標集群
建議目標集群與源集群的配置盡量保持一致,待業務文檔運行后再根據負載情況靈活進行擴縮容。
根據您的業務需求,選擇適當的實例類型創建Serverless StarRocks實例。您也可以通過釘釘群24010016636聯系我們進行評估。參考文檔如下:
數據遷移
1、安裝遷移工具
該工具基于兩個集群的元數據以及文件元數據對比,會定期將源集群的元數據以及數據增量同步到目標集群中。它作為遷移過程的一環,主要解決存量數據同步,元數據同步以及離線部分增量數據更新。
遷移工具的使用限制、安裝、使用等信息,請參見StarRocks跨集群數據遷移工具。
遷移工具速率說明:
參考經驗值:約1 TB/小時。
具體遷移速率受以下因素影響:同步的庫表數量、表數據量、表分區數量以及桶的數量。對于單表來說,tablet數量越多,遷移速率會越慢。
遠距離跨地域或跨VPC的遷移速率主要受網絡穩定性影響。遷移過程中需要在兩個集群之間建立大量連接,若網絡不穩定或速率較慢,遷移速率也會受到顯著影響。
遷移工具測試:在完成安裝并正確配置了源集群與目標集群的詳細信息后,進行工具的功能驗證,確保其能夠順暢運作。
2、表結構&存量數據同步
通過上述遷移工具可以實現表結構以及存量數據的同步。您可以參考遷移工具的速率,同時結合實際測試情況來合理評估同步時間。通過配置遷移工具的以下2個參數,可以合理控制期望同步的表和數據的范圍。
如果您需要遷移集群中所有數據庫和表,則無須配置以下參數。
參數 | 說明 |
include_data_list | 需要遷移的數據庫和表,多個對象時使用逗號( |
exclude_data_list | 不需要遷移的數據庫和表,多個對象時使用逗號( |
3、實時任務遷移
如果您正在執行Flink或Kafka的實時寫入任務,建議進行雙寫配置,以便同時將數據寫入目標集群和源集群,從而確保數據一致性。
停止遷移工具:首先,停止當前的遷移工具,并調整配置,以排除對正在實時更新的表數據的同步。可通過
exclude_data_list參數進行控制。Flink作業:在Flink作業的平臺上,復制現有任務,并修改數據源配置,指向目標集群。
Stream Load作業:在目標集群中手動創建相應的Stream Load作業,以實現對Kafka數據的雙寫同步。
在業務數據導入時,通常會有明確的offset或時間戳標識。例如,若同步任務于13:00啟動并于13:30結束,目標集群表中至少應包含13:00之前的數據。同步任務結束后,可以將雙寫的Flink或Kafka任務設置到13:00之前的offset,以便完成遷移窗口期的數據追平工作。
4、離線任務遷移
離線任務啟動:去掉實時更新的相關表后,繼續啟動離線任務,保持對離線更新數據的持續同步。
離線任務復制:復制離線任務實現對目標集群的更新,但在割接階段之前暫時不啟動相關任務。
確保提交離線任務的機器與目標集群之間的網絡連接穩定,避免因網絡問題導致任務失敗。
選擇1~2個任務進行驗證,以確認離線任務流程的準確性和順暢性。
5、(可選)物化視圖遷移
請參考以下社區命令,以獲取相關的物化視圖或普通視圖的定義。然后,在目標集群中逐個創建相應的視圖。
6、(可選)外表遷移
3.x及之后版本,建議使用Catalog對StarRocks的外表進行統一管理。更多Catalog信息,請參見Catalog概述。
如果需要獲取源表的DDL,可以通過SHOW CREATE TABLE命令,但不推薦在新集群中采用這種方式進行外表管理,建議優先使用Catalog。
根據您的具體需求,選擇合適的方法在目標集群中創建外表,并測試外表功能是否正常。
7、(可選)UDF遷移
請參考SHOW FUNCTIONS命令,獲取相關FUNCTION內容,并在目標集群中逐個創建相應的UDF。
在EMR Serverless StarRocks中,您的JAR等文件應存儲在阿里云OSS中,使用以oss:為前綴的文件路徑進行替換。
數據校驗
1、數據一致性校驗
數據一致性校驗主要目的是驗證同步數據的準確性,通過對源表與目標集群進行比較。可以從以下幾個維度進行檢查:
庫或表數量對比
表記錄數對比
每行記錄的匯總或去重計數對比
如果源表與目標表存在輕微差異,可能是由于同步工具存在延遲導致的。建議結合業務場景,添加合適的時間戳,以進行更精準的校驗。
2、下游業務校驗
下游業務校驗主要從業務角度出發,對結果進行驗證,以確保源表、物化視圖及其他預處理數據的正確性。具體校驗方式如下:
有下游測試系統:可切換數據源至目標集群,從業務角度對查詢結果和報表數據進行驗證。
無下游測試系統,可采取以下兩種方法:
業務SQL復現:手動挑選關鍵業務SQL,執行查詢并比對結果,以進行校驗。
生產環境驗證:利用業務系統進行驗證,此過程需與業務方提前協商,驗證完成后應盡快切換回源集群。
如果業務結果數據存在輕微差異,建議結合業務場景,添加合適的時間戳,以進行更精準的校驗。
3、性能驗證
性能驗證的關鍵在于復現實際生產業務的各種壓力,包括數據導入、業務查詢以及物化視圖的處理。同時,必須確保實時數據的雙跑、離線任務的同步處理以及物化視圖的正常運行,以模擬真實的生產環境。以下是需要驗證的要點:
集群負載:確保CPU、內存、磁盤IO、IOPS及磁盤利用率等各項指標均在預期范圍內。
業務查詢:驗證業務查詢的響應時間,確保其在業務需求的合理范圍內。
數據導入:檢查數據導入的延遲情況,確保其在業務需求的合理范圍內。
業務割接
1、確認停服時間
由于業務割接將導致短暫停服,我們需要提前評估停服時間,并與業務方確認。建議在業務低峰期進行停服,以最小化對業務的影響。
通常情況下,割接的中斷時間主要集中在第五步(即業務系統切換至目標集群)。此步驟預計耗時較短,預計30分鐘至1小時。具體時間會根據項目情況進行實際評估。
2、終止源集群的離線數據同步
為確保割接時目標集群能夠追平源集群的數據,請在割接前停止離線同步任務。這意味著需要選擇適當的更新間隔期,并停止新數據的寫入,確保源集群不再增加新的離線數據。
3、遷移工具持續同步,直至追平源集群
遷移工具將保持實時同步狀態,直至與源集群數據完全一致。
觀察時間至少10分鐘,若此期間無新數據同步,則算追平源集群。
請確認所有離線寫入任務已終止,避免遷移工具因持續更新而無法追平。
4、離線同步任務寫入目標集群
在之前的遷移步驟中,已配置好離線任務寫入目標集群。本步驟僅需啟動這些任務,并觀察其運行情況,重點校驗:
同步任務是否正常運行。
目標集群的數據是否正常更新。
請確保同步任務的開始周期與原停止周期能夠無縫對接。例如,如果上次停止更新的時間為2024年02月01日 00:00,則新任務應從該時間點的下一個周期啟動。
5、業務系統切換為目標集群
將下游使用StarRocks的業務系統數據源配置切換為目標集群的配置,并驗證業務系統的查詢功能,確保查詢耗時符合預期。
若業務系統需要進行大量配置修改,建議提前準備修改腳本,以縮短配置修改時間。
6、割接驗證
割接后,對業務系統進行驗證,主要從下游進行檢驗,驗證項包括:
業務系統查詢結果是否正確。
業務系統查詢耗時是否符合預期。
如驗證中發現問題,請參考回滾方案。
7、終止實時雙跑任務
驗證通過后,可以停止源集群的實時寫入任務,正式完成割接。
回滾方案
如果割接后驗證存在問題,請首先聯系阿里云EMR團隊協同解決相關問題。如果問題無法解決,再考慮回滾方案。回滾流程如下:
保持實時任務雙跑,避免執行數據校驗階段的第7步操作(即終止實時雙跑任務)。
將業務系統切換回源集群地址,驗證業務系統是否正常運行。
從上次停止的周期開始,恢復離線任務對源集群的寫入。
停止向目標集群寫入離線數據。
常見問題
盡管遷移工具已支持了Schema Change,但是Schema Change后,工具會對該表進行全量同步,會大幅增加同步所需的時間。具體的時間影響需結合表的數據量進行評估。
遷移時間通常在1至4周之間,具體時長需根據您的實際業務情況進行評估。主要耗時環節包括實時任務雙跑、離線任務復制以及業務驗證。如果您的調度工具平臺支持快速任務復制,可顯著縮短遷移時間。