EMR Serverless StarRocks 3.1.0版本正式支持存算分離模式。在該模式下計算和存儲資源被解耦,極大地優化了資源利用效率和成本。為了進一步提升查詢性能,該模式充分利用本地緩存技術,將熱數據存儲于計算節點的本地磁盤中。當查詢請求命中本地緩存時,存算分離集群的查詢性能與存算一體集群相當。此外,通過將數據從StarRocks BE本地磁盤遷移到阿里云對象存儲OSS,可以顯著降低數據存儲成本。
前提條件
已在OSS上創建存儲空間,詳情請參見控制臺創建存儲空間。
步驟一:創建并連接Serverless StarRocks存算分離實例
創建并連接Serverless StarRocks實例詳情,請參見快速開啟EMR Serverless StarRocks存算分離模式。
選擇3.1版本,打開存算分離開關,選擇OSS Location。
建議為StarRocks實例分配獨立的OSS Bucket,以便更好地管理、統計和監控存算分離實例在OSS上的存儲、帶寬和API使用情況。
請勿擅自修改存算分離實例使用的Bucket,否則可能會引起數據丟失。
步驟二:創建存算分離數據庫及數據表
創建數據庫
cloud_db和數據表detail_demo。說明存算分離(云原生)表的建表語法與存算一體完全兼容。
CREATE DATABASE cloud_db; USE cloud_db; CREATE TABLE IF NOT EXISTS detail_demo ( recruit_date DATE NOT NULL COMMENT "YYYY-MM-DD", region_num TINYINT COMMENT "range [-128, 127]", num_plate SMALLINT COMMENT "range [-32768, 32767] ", tel INT COMMENT "range [-2147483648, 2147483647]", id BIGINT COMMENT "range [-2^63 + 1 ~ 2^63 - 1]", password LARGEINT COMMENT "range [-2^127 + 1 ~ 2^127 - 1]", name CHAR(20) NOT NULL COMMENT "range char(m),m in (1-255) ", profile VARCHAR(500) NOT NULL COMMENT "upper limit value 65533 bytes", ispass BOOLEAN COMMENT "true/false") DUPLICATE KEY(recruit_date, region_num) DISTRIBUTED BY HASH(recruit_date, region_num) PROPERTIES ( "replication_num" = "1" );查看表的基本信息。
通過以下命令,可以獲取到數據庫
DbId。SHOW PROC '/dbs';返回信息如下所示。

通過以下命令,查看表的詳細信息。
SHOW PROC '/dbs/10061';示例代碼中的
10061為前一步驟中獲取到的DbId,返回信息如下所示。
其中,
Type字段標示出存算分離模式下的數據表類型是CLOUD_NATIVE。StoragePath字段為表在OSS對象存儲中的路徑,通過該路徑可以定位到存算分離表的數據存儲位置。
步驟三:存算分離Cache特性演示
準備初始數據環境。
通過一些可觀測性手段驗證和展示StarRocks存算分離的本地Cache特性,特別關注緩存開啟(datacache.enable)和關閉狀態對導入和查詢性能的影響。在該測試中,創建了兩個測試表,并使用Broker Load方式導入測試數據。
創建以下數據表。
catalog_sales:開啟本地緩存。
catalog_sales_nocache:關閉本地緩存。
USE cloud_db; --創建catalog_sales、catalog_sales_async、catalog_sales_nocache表。 create table if not exists catalog_sales( cs_order_number bigint, cs_item_sk bigint, cs_sold_date_sk bigint, cs_sold_time_sk bigint, cs_ship_date_sk bigint, cs_bill_customer_sk bigint, cs_bill_cdemo_sk bigint, cs_bill_hdemo_sk bigint, cs_bill_addr_sk bigint, cs_ship_customer_sk bigint, cs_ship_cdemo_sk bigint, cs_ship_hdemo_sk bigint, cs_ship_addr_sk bigint, cs_call_center_sk bigint, cs_catalog_page_sk bigint, cs_ship_mode_sk bigint, cs_warehouse_sk bigint, cs_promo_sk bigint, cs_quantity int, cs_wholesale_cost decimal(7,2), cs_list_price decimal(7,2), cs_sales_price decimal(7,2), cs_ext_discount_amt decimal(7,2), cs_ext_sales_price decimal(7,2), cs_ext_wholesale_cost decimal(7,2), cs_ext_list_price decimal(7,2), cs_ext_tax decimal(7,2), cs_coupon_amt decimal(7,2), cs_ext_ship_cost decimal(7,2), cs_net_paid decimal(7,2), cs_net_paid_inc_tax decimal(7,2), cs_net_paid_inc_ship decimal(7,2), cs_net_paid_inc_ship_tax decimal(7,2), cs_net_profit decimal(7,2) ) duplicate key (cs_order_number, cs_item_sk) distributed by hash(cs_order_number, cs_item_sk) buckets 90 properties( "replication_num"="1", "datacache.enable" = "true" ); --創建catalog_sales_nocache表。 create table if not exists catalog_sales_nocache( cs_order_number bigint, cs_item_sk bigint, cs_sold_date_sk bigint, cs_sold_time_sk bigint, cs_ship_date_sk bigint, cs_bill_customer_sk bigint, cs_bill_cdemo_sk bigint, cs_bill_hdemo_sk bigint, cs_bill_addr_sk bigint, cs_ship_customer_sk bigint, cs_ship_cdemo_sk bigint, cs_ship_hdemo_sk bigint, cs_ship_addr_sk bigint, cs_call_center_sk bigint, cs_catalog_page_sk bigint, cs_ship_mode_sk bigint, cs_warehouse_sk bigint, cs_promo_sk bigint, cs_quantity int, cs_wholesale_cost decimal(7,2), cs_list_price decimal(7,2), cs_sales_price decimal(7,2), cs_ext_discount_amt decimal(7,2), cs_ext_sales_price decimal(7,2), cs_ext_wholesale_cost decimal(7,2), cs_ext_list_price decimal(7,2), cs_ext_tax decimal(7,2), cs_coupon_amt decimal(7,2), cs_ext_ship_cost decimal(7,2), cs_net_paid decimal(7,2), cs_net_paid_inc_tax decimal(7,2), cs_net_paid_inc_ship decimal(7,2), cs_net_paid_inc_ship_tax decimal(7,2), cs_net_profit decimal(7,2) ) duplicate key (cs_order_number, cs_item_sk) distributed by hash(cs_order_number, cs_item_sk) buckets 90 properties( "replication_num"="1", "datacache.enable" = "false" );數據導入測試。
上傳測試數據到OSS。
說明本文示例通過ECS實例執行以下命令,您也可以在本地執行。創建ECS實例的具體操作,請參見通過控制臺使用ECS實例(快捷版)。
通過以下命令,編輯upload.sh。
vim upload.sh在upload.sh中新增以下內容。
#!/bin/bash # 日期時間 date_time=`date +%Y-%m-%d-%H-%M-%S` yum install -y wget unzip mkdir -p /data/ curl https://gosspublic.alicdn.com/ossutil/install.sh | sudo bash wget -O catalog_sales.zip "https://starrocks-oss.oss-cn-beijing.aliyuncs.com/public-access/catalog_sales.zip" && unzip -o catalog_sales.zip -d /data/ echo download data finish upload_url=$1 #ossutil cp -r /data/ ${upload_url} endpoint="oss-cn-****-internal.aliyuncs.com" accessKeyId="LTAI5tJKzJYFWJXtchWG****" accessKeySecret="oRHrl4fIR5NMlOTRvo99qDkLUf****" echo ossutil64 -e ${endpoint} -i ${accessKeyId} -k ${accessKeySecret} cp -r /data/ ${upload_url} ossutil64 -e ${endpoint} -i ${accessKeyId} -k ${accessKeySecret} cp -r -f /data/ ${upload_url} echo success for data upload請根據實際情況替換文件中的
endpoint、accessKeyId和accessKeySecret。參數
說明
endpoint
訪問OSS的EndPoint。例如,oss-cn-hangzhou-internal.aliyuncs.com。
accessKeyId
訪問OSS的AccessKey ID。
accessKeySecret
訪問OSS的AccessKey Secret。
執行以下命令,運行upload.sh并上傳測試數據到OSS。
sh upload.sh 'oss://yourBucketName/tcp_ds/'說明oss://yourBucketName/tcp_ds/為測試數據上傳的路徑。
使用Broker Load導入測試數據(約10 GB)。
-- 導入數據到catalog_sales。 LOAD LABEL cloud_db.catalog_sales_0001 ( DATA INFILE("file_path") INTO TABLE catalog_sales format as "parquet" ) WITH BROKER 'broker' ( "fs.oss.accessKeyId" = "yourKey", "fs.oss.accessKeySecret" = "yourSecret ", "fs.oss.endpoint" = "yourBucketEndpoint" ); -- 導入數據到catalog_sales_nocache。 LOAD LABEL cloud_db.catalog_sales_0003 ( DATA INFILE("file_path") INTO TABLE catalog_sales_nocache format as "parquet" ) WITH BROKER 'broker' ( "fs.oss.accessKeyId" = "yourKey", "fs.oss.accessKeySecret" = "yourSecret ", "fs.oss.endpoint" = "yourBucketEndpoint" );參數
說明
file_path
為測試數據的路徑,請根據實際情況修改。例如,oss://<yourBucketName>/tcp_ds/data/*.parquet。
fs.oss.accessKeyId
訪問OSS的AccessKey ID。
fs.oss.accessKeySecret
訪問OSS的AccessKey Secret。
fs.oss.endpoint
訪問OSS的EndPoint。例如,oss-cn-hangzhou-internal.aliyuncs.com。
在導入任務頁面,可以查看測試結果。
測試結果如下表所示。
表名稱
本地緩存
表模型
導入用時
catalog_sales
開啟
明細表
1m21s
catalog_sales_no_cache
未開啟
明細表
1m20s
測試結果表明,在存儲與計算分離的場景中,啟用緩存對導入性能的影響極為有限。
數據查詢測試。
針對開啟本地緩存和不開啟本地緩存兩種場景進行了測試,以評估本地緩存對查詢性能的影響。在StarRocks的存算分離模式下,Query執行引擎會在查詢執行過程中記錄訪問緩存和對象存儲OSS的指標,并將其記錄在Profile中。因此,我們可以使用Profile工具來查看相關指標。
-- 最大Query超時時間。 set global query_timeout=1200; -- 查詢catalog_sales開啟本地緩存。 select cs_item_sk,cs_bill_customer_sk from cloud_db.catalog_sales group by cs_item_sk,cs_bill_customer_sk order by cs_item_sk desc limit 100; -- 查詢catalog_sales_nocache關閉本地緩存。 select cs_item_sk,cs_bill_customer_sk from cloud_db.catalog_sales_nocache group by cs_item_sk,cs_bill_customer_sk order by cs_item_sk desc limit 100;在慢查詢或者全部查詢頁面,找到對應的Query,在執行詳情頁簽可以看到Profile執行樹,找到
CONNECTOR_SCAN節點,右側指標中主要關注CompressedBytesReadLocalDisk(從本地緩存讀取)和CompressedBytesReadRemote(從遠端OSS對象存儲讀取)兩個指標。本示例中,catalog_sales表開啟了本地緩存,指標值
CompressedBytesReadLocalDisk>0,因此可以確定查詢全部命中了本地緩存。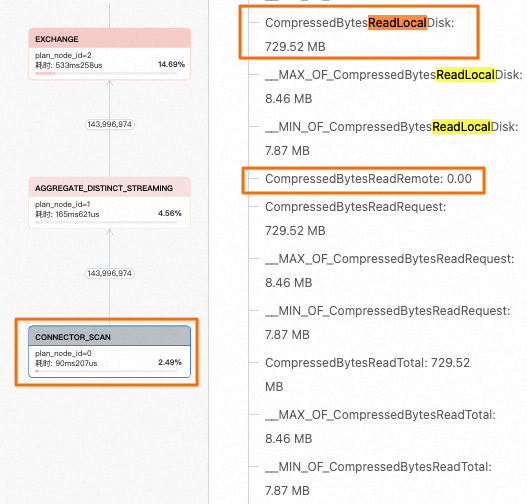
catalog_sales_nocache表沒有開啟本地緩存,指標值
CompressedBytesReadLocalDisk=0,查詢數據未命中本地緩存,數據全部來自遠端OSS對象存儲。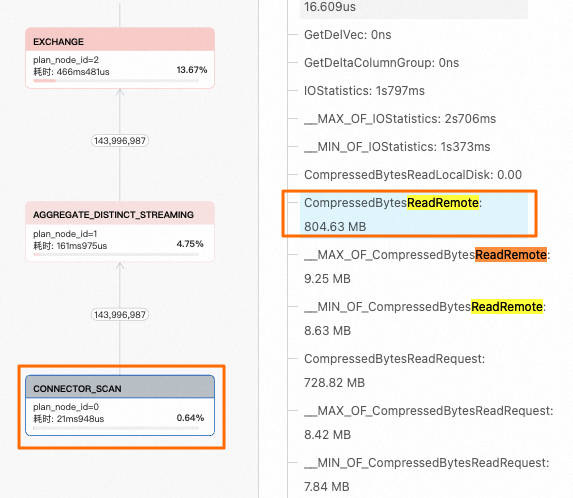
通過對兩個查詢的執行耗時對比,進一步驗證了結論:當查詢命中本地緩存時,查詢速度更快。
步驟四:對比存算分離和存算一體的性能
以下內容通過一個測試案例,為您展示了存算分離帶本地緩存和存算一體兩種模式下的查詢性能對比。您可以使用TPC-H測試集進行更詳細的性能對比測試,詳情請參見TPC-H性能測試說明。
準備數據環境。
集群資源配置:1FE(8CU)+3BE(算力:16CU|存儲:1000 GB)。
集群參數:使用默認設置,存算分離集群開啟本地緩存。
數據量:500 GB(sf=500),經過壓縮后約為180 GB。
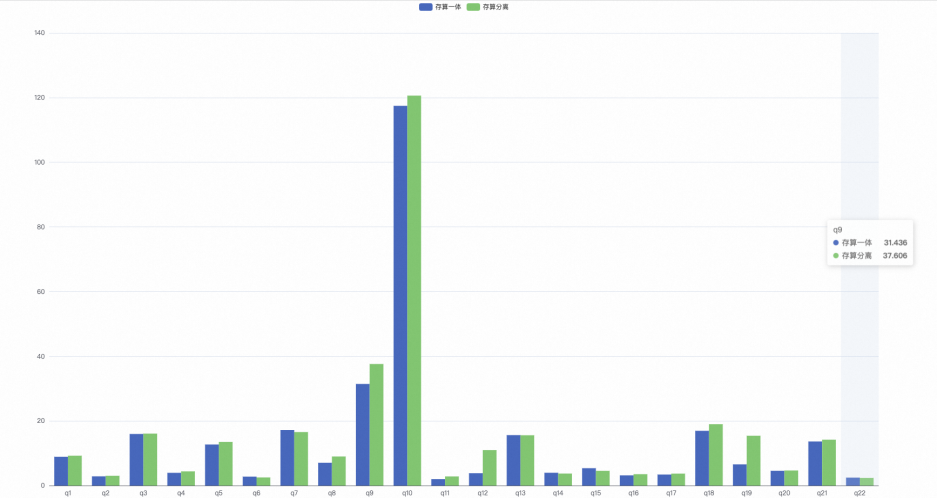
測試結果。
存算一體22條SQL總計用時:302.063 seconds。
存算分離22條SQL總計用時(第2次執行時開啟本地緩存的情況下):333.390 seconds。
根據TPC-H的結果顯示,在開啟本地緩存的情況下,存算分離和存算一體的查詢性能基本相同。
相關文檔
如需了解Query Profile更多信息,請參見Profile可視化查詢分析。
如果您想有效地查看和解讀Query Profile以優化StarRocks查詢性能,詳情請參見Profile性能診斷及優化案例。