本文介紹統(tǒng)計云數(shù)據(jù)庫HBase表行數(shù)的方法。
根據(jù)云數(shù)據(jù)庫HBase表的服務(wù)類型使用不同的統(tǒng)計方法。
- 如果云數(shù)據(jù)庫HBase表為增強版,統(tǒng)計HBase表行數(shù)的方法具體請參見統(tǒng)計表行數(shù)的方法。
- 如果云數(shù)據(jù)庫HBase表為標(biāo)準(zhǔn)版,可以通過兩種方式精確的統(tǒng)計HBase表行數(shù)。先使用HBase Shell連接云數(shù)據(jù)庫HBase標(biāo)準(zhǔn)版,具體操作請參見使用HBase Shell訪問。
- 通過HBase Shell工具使用COUNT命令可以精確的統(tǒng)計HBase表行數(shù)。執(zhí)行COUNT命令的原理是將表的數(shù)據(jù)一批一批全部掃描出來進行統(tǒng)計,所以建議在相同內(nèi)網(wǎng)的ECS客戶端上執(zhí)行COUNT命令。如果通過公網(wǎng)執(zhí)行COUNT命令,網(wǎng)絡(luò)使用率會較大,導(dǎo)致統(tǒng)計效率降低。根據(jù)表結(jié)構(gòu)的不同,掃描的速度會有所差別,使用COUNT命令掃描全表的速度可以達(dá)到小于10萬行每秒。
執(zhí)行以下語句統(tǒng)計table表的總行數(shù)。
執(zhí)行結(jié)果如下:COUNT 'table'
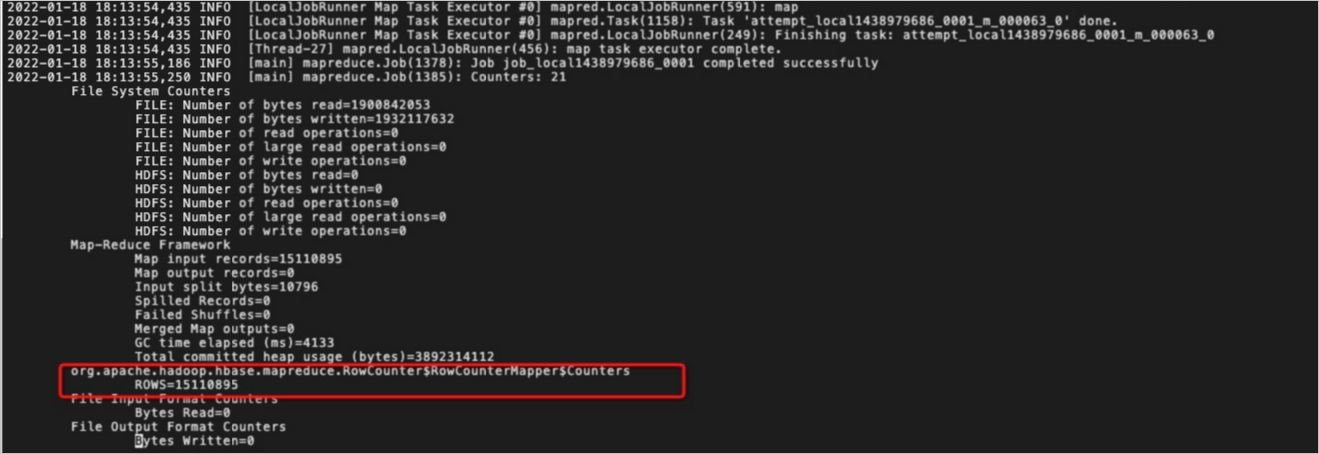
- RowCounter會在本地啟動一個偽分布式的MR任務(wù)來進行COUNT操作。默認(rèn)情況下這種方式是按照單個線程來執(zhí)行的,統(tǒng)計速率與HBase Shell執(zhí)行COUNT命令的統(tǒng)計速率差不多。如果您想提高統(tǒng)計速度,可以通過指定
Dmapreduce.local.map.tasks.maximum=線程數(shù)來進行多線程并發(fā)執(zhí)行,需要注意以下兩點:- 線程數(shù)小于等于表Region的個數(shù)。
- 線程數(shù)增多可能造成集群負(fù)載過高從而影響線上業(yè)務(wù),請根據(jù)業(yè)務(wù)需求設(shè)置。
在HBase Shell中執(zhí)行以下代碼統(tǒng)計Lindorm寬表的行數(shù)。- 統(tǒng)計目標(biāo)表table的總行數(shù)。
./alihbase-2.0.18/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter "table" - 統(tǒng)計目標(biāo)表table的總行數(shù),16個線程并發(fā)執(zhí)行。
./alihbase-2.0.18/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter -Dmapreduce.local.map.tasks.maximum=16 "table" - 統(tǒng)計NameSpace為ns中的目標(biāo)表table的總行數(shù)。
./alihbase-2.0.18/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter "ns:table"
- 通過HBase Shell工具使用COUNT命令可以精確的統(tǒng)計HBase表行數(shù)。執(zhí)行COUNT命令的原理是將表的數(shù)據(jù)一批一批全部掃描出來進行統(tǒng)計,所以建議在相同內(nèi)網(wǎng)的ECS客戶端上執(zhí)行COUNT命令。如果通過公網(wǎng)執(zhí)行COUNT命令,網(wǎng)絡(luò)使用率會較大,導(dǎo)致統(tǒng)計效率降低。根據(jù)表結(jié)構(gòu)的不同,掃描的速度會有所差別,使用COUNT命令掃描全表的速度可以達(dá)到小于10萬行每秒。