如果您需對大規模數據集使用基于主鍵的UPDATE或含范圍過濾條件的查詢,可以考慮為表設置Event Time Column(Segment Key),系統將數據文件基于Event Time Column范圍排序后進行合并,減少文件之間的重疊,使得查詢時能夠過濾掉盡可能多的文件,從而提升查詢效率。合理地應用Event Time Column有助于提高數據庫的處理效率、查詢速度和整體性能,本文為您介紹在Hologres中為表設置分段鍵Event_time_column。
Event Time Column介紹
Event_time_column原名為Segment Key,在Hologres V0.9版本默認改名為Event_time_column,Segment Key依舊向下兼容使用。
Segment Key主要適用的場景如下:
含范圍過濾條件(包括等值條件)的查詢場景。
基于主鍵的UPDATE。
Event_time_column在設置時,需要在建表時指定,語法如下:
-- Hologres V2.1版本起支持的語法
CREATE TABLE <table_name> (...) WITH (event_time_column = '[<columnName>[,...]]');
-- 所有版本支持的語法
BEGIN;
CREATE TABLE <table_name> (...);
call set_table_property('<table_name>', 'event_time_column', '[<columnName> [,...]]');
COMMIT;參數說明:
參數 | 說明 |
table_name | 設置分段鍵的表名稱。 |
columnName | 設置分段鍵的列。 |
使用建議
Event_time_column適用于數據為單調遞增或單調遞減的有序字段,例如時間戳字段。非常適用于日志、流量等和時間強相關的數據,合理設置可極大提升性能。完全無序的Event_time_column會導致合并之后每個文件缺乏區分度,達不到任何文件過濾效果。
如果表不存在明顯的單調遞增或單調遞減的字段,可以選擇額外擴充一列
update_time,每次UPSERT時將當前時間寫入該新增字段。Event_time_column具備左匹配原則,因此不建議將多個字段設置為Event_time_column,否則使得查詢場景受限,達不到加速效果,一般情況建議選擇設置兩個或者兩個以內字段設置為Event_time_column。
使用限制
Event_time_column必須為not nullable的列或者列組合,可以不設置,但不能設置為空。Hologres V1.3.20~1.3.27版本支持Event_time_column對應列的約束為nullable,從V1.3.28版本開始不支持Event_time_column對應列的約束為nullable,為nullable的Event_time_column可能會影響數據正確性,如果業務有強需求設置Event_time_column為null,可以在SQL前添加如下參數:
set hg_experimental_enable_nullable_segment_key = true;您可以使用如下SQL檢查當前數據庫是否有屬性為nullable的Event_time_column(Segment Key):
WITH t_base AS ( SELECT * FROM hologres.hg_table_info WHERE collect_time::date = CURRENT_DATE ), t1 AS ( SELECT db_name, schema_name, table_name, jsonb_array_elements(table_meta::jsonb -> 'columns') cols FROM t_base ), t2 AS ( SELECT db_name, schema_name, table_name, cols ->> 'name' col_name FROM t1 WHERE cols -> 'nullable' = 'true'::jsonb ), t3 AS ( SELECT db_name, schema_name, table_name, regexp_replace(regexp_split_to_table(table_meta::jsonb ->> 'segment_key', ','), ':asc|:desc$', '') segment_key_col FROM t_base WHERE table_meta::jsonb -> 'segment_key' IS NOT NULL ) SELECT CURRENT_DATE, t3.db_name, t3.schema_name, t3.table_name, jsonb_build_object('nullable_segment_key_column', string_agg(t3.segment_key_col, ',')) as nullable_segment_key_column FROM t2, t3 WHERE t3.db_name = t2.db_name AND t3.schema_name = t2.schema_name AND t3.table_name = t2.table_name AND t2.col_name = t3.segment_key_col GROUP BY t3.db_name, t3.schema_name, t3.table_name;不支持修改Event_time_column,如需修改請重新建表。
行存表不能設置Event_time_column。
列存表默認將表中的第一個非空的Timestamp或Timestamptz類型字段作為Event_time_column,如果不存在這樣的字段,則默認將第一個非空的Date類型字段作為Event_time_column(Hologres V0.9之前的版本默認為空)。
不支持Decimal、Numeric、Float、Double、Array、Json、Jsonb、Bit、Money及其他復雜數據類型。
技術原理
以一個Shard為例,數據寫入時的步驟如下圖所示: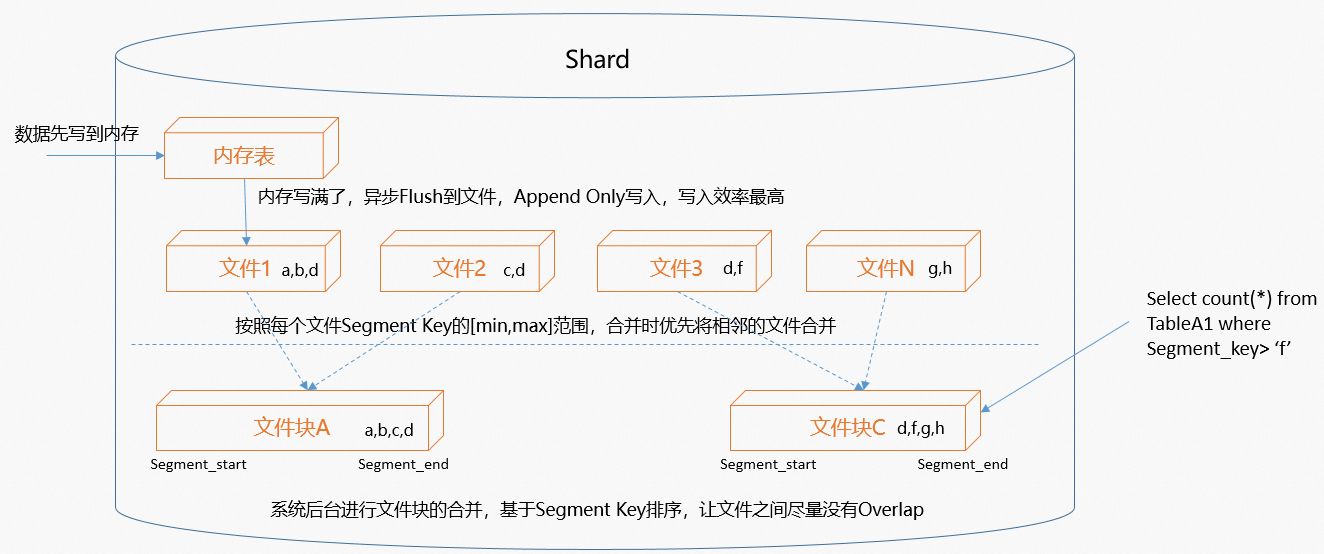
在一個Shard內,數據會先寫入至一個內存表,為了保證寫入效率最高,會使用Append Only的方式寫入。內存表有一定的大小,當內存表寫滿之后,系統會將內存表中的數據逐漸異步Flush到文件。
寫入時為了追求寫入性能,都為Append Only方式寫入,文件數會越來越多。因此系統會在后臺周期將文件進行合并。如果設置了Event_time_column(Segment Key),系統將文件基于Segment Key范圍排序后,選擇Segment Key范圍相鄰的文件進行合并,減少文件之間的重疊,這樣就使得查詢時能夠過濾掉盡可能多的文件,從而提升查詢效率。
文件基于Segment Key排序,因此Segment Key也具有左匹配原則,即
a、b、c三個字段設置了Segment Key,查詢時查a,b,c或者查a,b可以命中Segment Key,如果查a,c則只有a可以命中Segment Key,查b,c則無法命中。
從以上的介紹中可以看出Segment Key可以對以下場景進行加速:
含范圍過濾條件(包括等值條件)的查詢場景。
如果查詢字段設置為Segment Key,那么Hologres在掃描數據時,會將范圍查詢條件同文件內列的統計信息(min/max)進行匹配,快速過濾出所需的文件,加速查詢。
基于主鍵的UPDATE。
Hologres的
UPDATE命令原理是由DELETE命令和INSERT命令組合實現。在基于主鍵的UPDATE或INSERT ON CONFLICT(UPSERT)場景中,會先根據主鍵找到目標表(舊數據)的Segment Key值,再根據舊數據的Segment Key找到舊數據所在文件,最終定位舊數據所在位置進而標記為DELETE。如果設置了合理的Segment Key,那么就會快速定位到舊數據的文件,提高寫入性能。相反,如果這張列存表沒有配置Segment Key、Segment Key配置了不合理的字段或者Segment Key對應的字段在寫入時沒有與時間有強相關性(比如基本亂序),那在查找舊數據時需要掃描的文件將會非常多,不僅會有大量的IO操作,而且會大量占用CPU,影響寫入性能和整個實例的負載。
使用示例
在建表時創建一個Event_time_column。
V2.1版本起支持的建表語法:
CREATE TABLE tbl_segment_test ( a int NOT NULL, b timestamptz NOT NULL ) WITH ( event_time_column = 'b' ); INSERT INTO tbl_segment_test values (1,'2022-09-05 10:23:54+08'), (2,'2022-09-05 10:24:54+08'), (3,'2022-09-05 10:25:54+08'), (4,'2022-09-05 10:26:54+08'); EXPLAIN SELECT * FROM tbl_segment_test WHERE b > '2022-09-05 10:24:54+08';所有版本支持的建表語法:
BEGIN; CREATE TABLE tbl_segment_test ( a int NOT NULL, b timestamptz NOT NULL ); CALL set_table_property('tbl_segment_test', 'event_time_column', 'b'); COMMIT; INSERT INTO tbl_segment_test VALUES (1,'2022-09-05 10:23:54+08'), (2,'2022-09-05 10:24:54+08'), (3,'2022-09-05 10:25:54+08'), (4,'2022-09-05 10:26:54+08'); EXPLAIN SELECT * FROM tbl_segment_test WHERE b > '2022-09-05 10:24:54+08';
同時通過查詢執行計劃(explain SQL),如果出現
Segment Filter,說明有查詢命中Event_time_column。
建表時創建多個Event_time_column。
V2.1版本起支持的建表語法:
CREATE TABLE tbl_segment_test_2 ( a int NOT NULL, b timestamptz NOT NULL ) WITH ( event_time_column = 'a,b' ); INSERT INTO tbl_segment_test_2 VALUES (1,'2022-09-05 10:23:54+08'), (2,'2022-09-05 10:24:54+08'), (3,'2022-09-05 10:25:54+08'), (4,'2022-09-05 10:26:54+08') ; --不可命中segment key SELECT * FROM tbl_segment_test_2 WHERE b > '2022-09-05 10:24:54+08'; --可命中segment key SELECT * FROM tbl_segment_test_2 WHERE a = 3 and b > '2022-09-05 10:24:54+08'; SELECT * FROM tbl_segment_test_2 WHERE a > 3 and b < '2022-09-05 10:26:54+08'; SELECT * FROM tbl_segment_test_2 WHERE a > 3 and b > '2022-09-05 10:24:54+08';所有版本支持的建表語法:
BEGIN; CREATE TABLE tbl_segment_test_2 ( a int NOT NULL, b timestamptz NOT NULL ); CALL set_table_property('tbl_segment_test_2', 'event_time_column', 'a,b'); COMMIT; INSERT INTO tbl_segment_test_2 VALUES (1,'2022-09-05 10:23:54+08'), (2,'2022-09-05 10:24:54+08'), (3,'2022-09-05 10:25:54+08'), (4,'2022-09-05 10:26:54+08') ; --不可命中segment key SELECT * FROM tbl_segment_test_2 WHERE b > '2022-09-05 10:24:54+08'; --可命中segment key SELECT * FROM tbl_segment_test_2 WHERE a = 3 and b > '2022-09-05 10:24:54+08'; SELECT * FROM tbl_segment_test_2 WHERE a > 3 and b < '2022-09-05 10:26:54+08'; SELECT * FROM tbl_segment_test_2 WHERE a > 3 and b > '2022-09-05 10:24:54+08';
相關文檔
根據業務查詢場景設置合適的表屬性指南,請參見場景化建表調優指南。