本文介紹如何基于本地知識庫和云端大模型構建RAG(檢索增強生成)應用,用于私域知識問答、客戶支持等場景。
如果您希望將知識庫部署在本地,實現靈活的文檔切分與嵌入模型選擇,請參考本文檔進行操作。
如果您希望將知識庫部署在云端,直觀、快速地創建RAG應用,請使用百煉提供的0代碼構建RAG應用功能。
方案概覽
您可以通過本文檔實現以下效果:
RAG應用能夠根據用戶提供的文檔生成回復,有效緩解大模型面對私有領域問題時的局限性,整體上可分為檢索與生成兩個環節。
在本應用中,檢索環節在本地執行,您能夠便捷地管理和維護知識文檔、靈活定義文檔切分方法,同時避免因文件體積龐大而導致的上傳失敗問題;生成環節則調用由百煉提供的通義千問API,您無需考慮本地計算資源及環境配置問題,即可獲得相較于開源模型更優質的回復效果。
本應用的整體框架如下圖所示:

搭建示例應用
您僅需3步就可以搭建示例應用:
1. 解壓文件
下載local_rag.zip并解壓,您可以看到如下圖所示的目錄結構: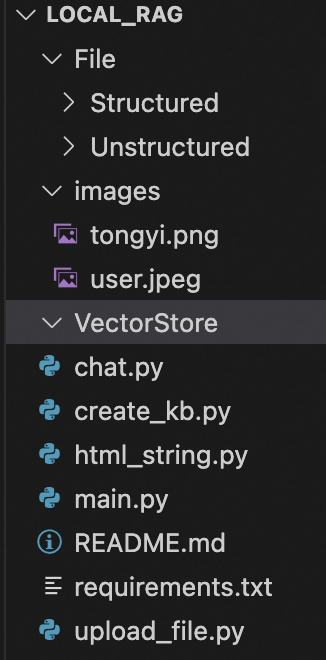
其中File/Structured用于存放用戶上傳的結構化數據,File/Unstructured用于存放用戶上傳的非結構化數據;images中的兩張圖片用于設置對話角色的頭像;VectorStore用于存放用戶創建的知識庫。
2.配置計算環境
您的Python版本需要不低于3.8。在解壓后的local_rag目錄中運行:pip install -r requirements.txt,安裝本應用所需要的依賴。
本應用默認使用百煉提供的embedding模型API來創建知識庫。如果您計劃使用本地embedding模型,請取消requirements.txt中的注釋部分再運行pip install -r requirements.txt命令。
請獲取百煉API Key,并參考配置API Key到環境變量將API Key配置到環境變量中。
修改嵌入模型配置(可選)
本應用默認使用百煉提供的嵌入模型API。如果您計劃使用本地部署的嵌入模型,可以參考以下內容:
請在
local_rag目錄下運行以下命令(以下載通義實驗室提供的GTE文本向量-中文-通用領域-large模型為例),將嵌入模型下載到local_rag/modelscope文件夾中:如果您使用Windows系統,且系統中缺少Microsoft Visual C++ Redistributable包,請前往Microsoft Visual C++ Redistributable 下載鏈接進行下載。
macOS/Linux
modelscope download --model 'iic/nlp_gte_sentence-embedding_chinese-large' --local_dir 'modelscope/iic/nlp_gte_sentence-embedding_chinese-large'Windows
modelscope download --model iic/nlp_gte_sentence-embedding_chinese-large --local_dir modelscope/iic/nlp_gte_sentence-embedding_chinese-large更改
chat.py與create_kb.py中的嵌入模型配置部分,將以下部分取消注釋:# from langchain_community.embeddings import ModelScopeEmbeddings # from llama_index.embeddings.langchain import LangchainEmbedding # embeddings = ModelScopeEmbeddings(model_id="modelscope/iic/nlp_gte_sentence-embedding_chinese-large") # EMBED_MODEL = LangchainEmbedding(embeddings)
3.運行應用
在local_rag目錄下運行:uvicorn main:app --port 7866,在終端中出現:INFO: Uvicorn running on http://127.0.0.1:7866 (Press CTRL+C to quit)后,訪問http://127.0.0.1:7866即可進入RAG應用的網頁。單擊RAG問答,即可開始對話。
傳入知識文件
您可以通過以下兩種方法之一向RAG應用傳入知識文件:
若同時使用兩種方法,RAG應用會優先參考臨時性文件。
傳入臨時性文件
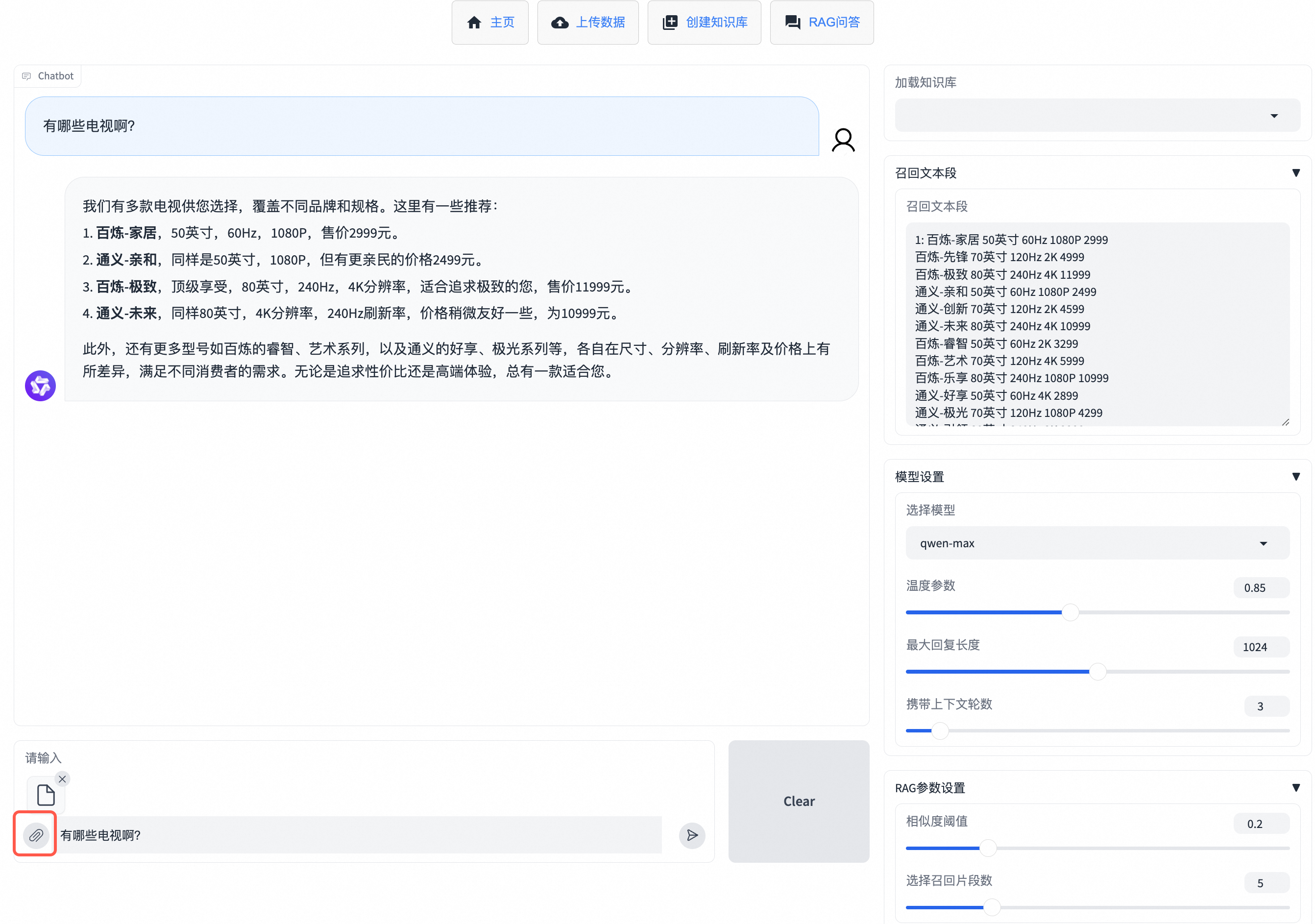
如果您想要直接在對話框中上傳文件,并基于該文件進行問答,可以在RAG問答頁面單擊輸入框旁的![]() 進行臨時知識庫文件的上傳,便能直接輸入問題并獲得回復。該方法在頁面刷新后無法找回上傳的文件。
進行臨時知識庫文件的上傳,便能直接輸入問題并獲得回復。該方法在頁面刷新后無法找回上傳的文件。
支持傳入的文件類型有:pdf、docx、txt、xlsx、csv。
上傳數據并創建知識庫
如果您需要長期使用特定的知識庫文件,建議您通過創建知識庫的方法來傳入知識文件。需要以下2步:
上傳數據
在上傳數據頁面,您可以上傳非結構化數據(暫時支持pdf與docx)或結構化數據(xlsx或csv)。非結構化數據會上傳到您命名的類目中,
File/Unstructured中會新建一個您命名類目名稱的文件夾,存放您上傳的文件;結構化數據會上傳到您命名的數據表中,File/Structured中會新建一個您命名數據表名稱的文件夾,存放您上傳的數據。如果您需要刪除類目或數據表,請在管理類目或管理數據表中操作。
創建知識庫
在創建知識庫界面,您可以使用上一步創建的類目或數據表進行知識庫的創建。您可以選擇多個類目或多個數據表,并設置知識庫名稱,單擊確認創建知識庫,在界面上顯示:
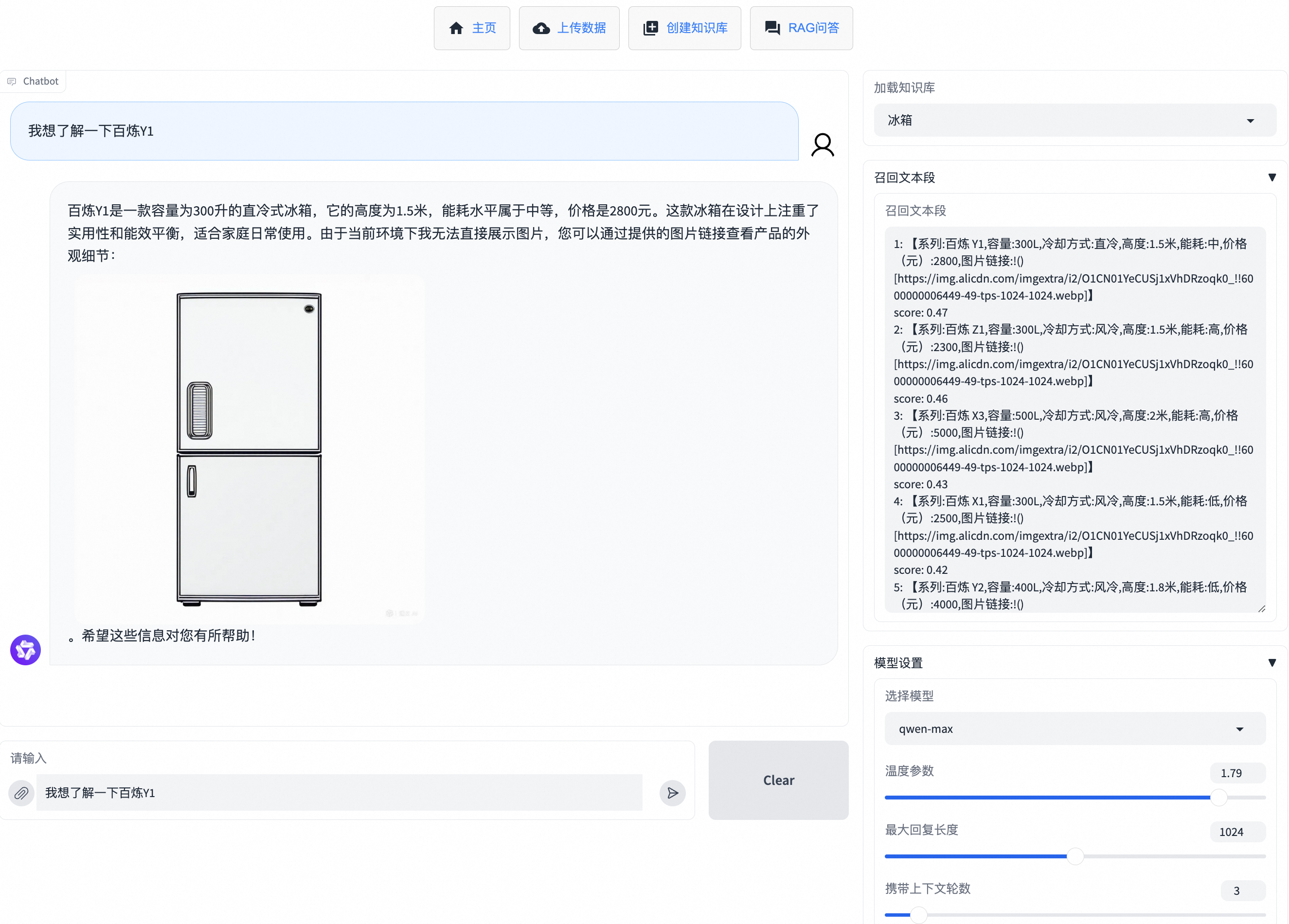
知識庫創建成功,可前往RAG問答進行提問后,即代表知識庫創建完成。知識庫文件會存放在VectorStore中您命名知識庫名稱的文件夾下。您可以前往RAG問答,在加載知識庫位置選中創建的知識庫,便可以輸入問題進行問答。如果您需要刪除知識庫,請在管理知識庫中操作。
優化回復效果
您可以參考以下方法,來優化RAG應用的回復效果。
修改模型參數與RAG參數
對于模型參數,您可以調整:
模型選擇
您可以選擇qwen-max、qwen-plus或qwen-turbo三個通義千問商業模型。一般來說,qwen-max性能優秀,qwen-turbo生成速度較快,價格較低,qwen-plus效果、速度、成本均衡,介于qwen-max和qwen-turbo之間。
溫度參數
該參數用于控制模型生成的隨機性,溫度值越高生成的隨機性越高。
最大回復長度
該參數用于控制模型生成的最多token個數。如果您希望生成詳細的描述可以將該值調高;如果希望生成簡短的回答可以將該值調低。
攜帶上下文輪數
該參數用于控制模型參考歷史對話的輪數,設為1時表示模型在回復時不會參考歷史對話信息。
對于RAG參數,您可以調整:
召回片段數
該參數用于控制選擇與用戶輸入最相關文本段的個數。該值越大,模型可獲得的參考信息越多,但無用信息也可能增加;該值越小,模型可獲得的參考信息越少,但無用信息可能減少。
相似度閾值
該參數會剔除已被選擇的相關文本段中,相似度低于該值的文本段。該值越大,模型可獲得的參考信息越少,但無用信息可能減少。該值為0時,表示不對召回片段進行剔除。
優化切分方法
RAG應用會對文檔進行切分,不同文檔有不同的最佳切分策略。在創建知識庫的過程中,本應用針對結構化數據的切分進行了優化;對于非結構化數據,本應用采用了LlamaIndex默認的切分策略。您可以根據您的文檔內容,進行定制化的切分。
更換嵌入模型
嵌入模型對于檢索過程十分重要,對于同一個知識文件,不同的嵌入模型可能有不同的表現。您可以嘗試更換嵌入模型,查看召回的效果,以選出最符合您業務場景的嵌入模型。
優化提示詞
您可以在chat.py中找到prompt_template參數,并根據您的使用場景進行改寫,使得大模型的回復更符合業務預期。
總結
通過前面的內容,您已經能搭建一個基于本地知識庫與通義千問API的RAG應用。
持續改進
大模型課程
系統體驗的改進優化永遠沒有終點,您可以考慮學習并通過阿里云大模型 ACA 認證,該認證配套的免費課程能幫助您進一步了解大模型的能力和應用場景,以及如何優化通過大模型的應用效果。