大語言模型的訓練和推理過程存在高能耗及長響應時間等問題,這些問題限制了其在資源有限場景中使用。為了解決這些問題,PAI提出了模型蒸餾功能。該功能支持將大模型知識遷移到較小模型,從而在保留大部分性能的同時,大幅降低模型的規模和對計算資源的需求,為更多的實際應用場景提供支持。本文將以通義千問2(Qwen2)大語言模型為基礎,為您介紹大語言模型數據增強和蒸餾解決方案的完整開發流程。
使用流程
該解決方案的完整開發流程如下:
您可以參照數據格式要求和數據準備策略準備相應的訓練數據集。
您可以在快速開始(QuickStart)中使用預置的指令增廣模型(Qwen2-1.5B-Instruct-Exp或Qwen2-7B-Instruct-Exp),根據已準備好的數據集中的指令語義信息,自動擴寫更多相似的指令。指令增廣有助于提升大語言模型的蒸餾訓練的泛化性。
您可以在快速開始(QuickStart)中使用預置的指令優化模型(Qwen2-1.5B-Instruct-Refine或Qwen2-7B-Instruct-Refine),將已準備好的數據集中的指令(以及增廣的指令)進行優化精煉。指令優化有助于提升大語言模型的語言生成能力。下表對比展示了Qwen2-7B-Instruct模型在接收簡略與詳細指令輸入時的輸出情況,表明指令的優化對模型輸出有顯著的提升作用。
指令
回復
優化后的指令
優化后的回復
請解釋一下“重力”是什么。
重力是一種自然現象,是所有物體之間相互吸引的力量。它是由物體的質量產生的,質量越大,產生的重力也越大。重力是宇宙中所有物體之間存在的基本力之一,它決定了物體的運動和位置。地球上的重力是由地球的質量產生的,因此所有物體都會受到地球的重力作用,從而產生重力加速度,即9.8米/秒2。
請詳細解釋“重力”是什么,包括它的定義、產生的原因以及在自然界中的作用。
重力是物理學中的一種基本力,它是由質量體之間相互作用而產生的。根據牛頓的萬有引力定律,兩個物體之間的引力與它們的質量成正比,與它們之間的距離的平方成反比。這意味著,質量越大,引力也越大;距離越近,引力也越大。
### 定義
重力通常指的是地球表面附近物體受到的吸引力。地球對所有物體施加的這種吸引力是重力的一個實例。在更廣泛的意義上,重力是所有物體之間的相互吸引力,不僅限于地球表面。
### 產生的原因
重力是由物體的質量產生的。根據愛因斯坦的廣義相對論,質量會彎曲它周圍的時空結構,這種彎曲會導致其他物體沿著彎曲的路徑移動,即我們所理解的“重力”。在牛頓的理論中,重力被解釋為所有物體之間的吸引力,而廣義相對論則提供了一個更深層次的解釋,即質量彎曲了時空,從而影響了物體的運動軌跡。
### 在自然界中的作用
重力在自然界中扮演著極其重要的角色:
1. **維持行星軌道**:太陽系中的行星繞太陽運行,是因為它們受到太陽的引力,同時它們自身的引力也作用于太陽,這形成了一個穩定的軌道。
2. **地球的形成**:在地球形成初期,巨大的質量聚集在一起,通過重力作用形成了行星。
3. **維持地球的形狀**:地球不是完美的球體,而是稍微扁平的,這是由于地球自轉產生的離心力與重力的相互作用。
4. **物體的運動**:從蘋果落地到火箭發射,物體的運動都受到重力的影響。在沒有其他力干擾的情況下,物體將遵循重力作用下的運動規律。
5. **影響潮汐**:月球和太陽對地球的引力作用導致了潮汐現象,影響海洋水位的周期性變化。
### 結論
重力是自然界中一種基本且普遍的力,它不僅影響著我們日常生活中的物體運動,也是宇宙結構和演化的關鍵因素。從地球上的物體運動到宇宙的宏觀結構,重力無處不在,是理解宇宙物理現象的基礎之一。
寫一首關于春天的詩。
春日暖陽照人間,
萬物復蘇展新顏。
綠草如茵鋪大地,
花兒競相綻放間。
微風輕拂柳絲間,
鳥兒歡鳴歌聲甜。
溪水潺潺流不息,
魚兒跳躍水中翻。
春雨綿綿潤物華,
滋潤大地生機發。
農民忙碌播種忙,
期待豐收的季節來。
春光無限好,
讓我們珍惜每一刻。
與大自然共呼吸,
感受春天的美妙與神奇。
創作一首表達春天美景與生機的詩歌。
注意事項:
1. 請在詩中描繪春天的自然景象,如花朵、樹木、小溪等。
2. 表達春天帶來的希望和活力。
3. 保持詩歌的節奏和韻律。
4. 詩歌長度在20至30行之間。
春之贊歌
春風輕拂,萬物復蘇,
綠意盎然,生機勃發。
山間溪流,潺潺作響,
映照著,生機勃勃的春光。
桃花笑開,如霞似錦,
杏花輕舞,滿枝紅艷。
梨花雪白,點綴著山野,
一片片,如夢如幻的畫卷。
嫩葉輕搖,綠意盈枝,
鳥語花香,滿溢林間。
小溪潺潺,細流清澈,
滋潤著,大地的每一寸。
春雨綿綿,潤物無聲,
滋養著,生命的希望。
每一滴,都是大自然的恩賜,
喚醒了,沉睡的大地。
田野里,綠意盎然,
麥苗青青,生機勃勃。
農人忙碌,播種希望,
期待著,金秋的豐收。
春風吹過,帶著溫暖,
帶來的是,無盡的希望。
每一個生命,都在生長,
在這春的季節,綻放光芒。
春日陽光,溫柔而明媚,
照亮了,每一個角落。
希望與活力,在這里匯聚,
春天的故事,正在上演。
讓我們擁抱這春的季節,
感受生命的奇跡與美好。
在這萬物復蘇的時光里,
共同見證,希望與夢想的綻放。
您可以在快速開始(QuickStart)中使用預置的教師大語言模型(通義千問2-72B-Instruct)對訓練數據集中的指令生成回復,從而將對應教師大模型的知識進行蒸餾。
您可以在快速開始(QuickStart)中使用生成完成的指令-回復數據集,蒸餾訓練對應較小的學生模型,用于實際的應用場景。
前提條件
在開始執行操作前,請確認您已完成以下準備工作:
已開通PAI(DLC、EAS)后付費,并創建默認工作空間,詳情請參見開通PAI并創建默認工作空間。
已創建OSS存儲空間(Bucket),用于存儲訓練數據和訓練獲得的模型文件。關于如何創建存儲空間,詳情請參見控制臺創建存儲空間。
準備指令數據
數據準備策略
為了提升模型蒸餾的有效性和穩定性,您可以參考以下策略準備數據:
您需要準備至少數百條數據,準備的數據多有助于提升模型的效果。
準備的種子數據集的分布應該盡可能廣泛且均衡。例如:任務場景分布廣泛;數據輸入輸出長度應該包含較短和較長場景;如果數據不止一種語言,例如有中文和英文,應當確保語言分布較為均衡。
處理異常數據。即使是少量的異常數據也會對微調效果造成很大的影響。您應當先使用基于規則的方式清洗數據,過濾掉數據集中的異常數據。
數據格式要求
訓練數據集格式要求為:JSON格式的文件,包含instruction一個字段,為輸入的指令。相應的指令數據示例如下:
[
{
"instruction": "在2008年金融危機期間,各國政府采取了哪些主要措施來穩定金融市場?"
},
{
"instruction": "在氣候變化加劇的背景下,各國政府采取了哪些重要行動來推動可持續發展?"
},
{
"instruction": "在2001年科技泡沫破裂期間,各國政府采取了哪些主要措施來支持經濟復蘇?"
}
](可選)使用指令增廣模型進行指令增廣
指令增廣是大語言模型提示工程(Prompt Engineering)的一種常見應用,用于自動增廣用戶提供的指令數據集,以實現數據增強的作用。
例如給定如下輸入:
如何做魚香肉絲? 如何準備GRE考試? 如果被朋友誤會了怎么辦?模型輸出類似如下結果:
教我如何做麻婆豆腐? 提供一個關于如何準備托福考試的詳細指南? 如果你在工作中遇到了挫折,你會如何調整心態?
由于指令的多樣性直接影響了大語言模型的學習泛化性,進行指令增廣能有效提升最終產生的學生模型的效果。基于Qwen2基座模型,PAI提供了兩款自主研發的指令增廣模型,分別為Qwen2-1.5B-Instruct-Exp和Qwen2-7B-Instruct-Exp。您可以在快速開始(QuickStart)中一鍵部署模型服務,具體操作步驟如下:
部署模型服務
您可以按照以下操作步驟,將指令增廣模型部署為EAS在線服務:
進入Model Gallery頁面。
登錄PAI控制臺。
在頂部左上角根據實際情況選擇地域。
在左側導航欄選擇工作空間列表,單擊指定工作空間名稱,進入對應工作空間內。
在左側導航欄選擇。
在Model Gallery頁面右側的模型列表中,搜索Qwen2-1.5B-Instruct-Exp或Qwen2-7B-Instruct-Exp,并在相應卡片中單擊部署。
在部署配置面板中,系統已默認配置了模型服務信息和資源部署信息,您也可以根據需要進行修改。參數配置完成后單擊部署按鈕。
在計費提醒對話框中,單擊確定。
系統自動跳轉到部署任務頁面,當狀態為運行中時,表示服務部署成功。
調用模型服務
服務部署成功后,您可以使用API進行模型推理。具體使用方法參考LLM大語言模型部署。以下提供一個示例,展示如何通過客戶端發起Request調用:
獲取服務訪問地址和Token。
在服務詳情頁面,單擊基本信息區域的查看調用信息。
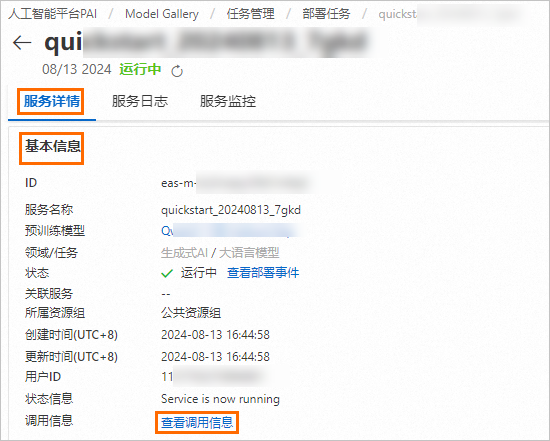
在調用信息對話框中,查詢服務訪問地址和Token,并保存到本地。
在終端中,創建并執行如下Python代碼文件來調用服務。
import argparse import json import requests from typing import List def post_http_request(prompt: str, system_prompt: str, host: str, authorization: str, max_new_tokens: int, temperature: float, top_k: int, top_p: float) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "do_sample": True, "eos_token_id": 151645 } response = requests.post(host, headers=headers, json=pload) return response def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] return output if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=50) parser.add_argument("--top-p", type=float, default=0.95) parser.add_argument("--max-new-tokens", type=int, default=2048) parser.add_argument("--temperature", type=float, default=1) parser.add_argument("--prompt", type=str, default="給我唱首歌。") args = parser.parse_args() prompt = args.prompt top_k = args.top_k top_p = args.top_p temperature = args.temperature max_new_tokens = args.max_new_tokens host = "EAS HOST" authorization = "EAS TOKEN" print(f" --- input: {prompt}\n", flush=True) system_prompt = "我希望你扮演一個指令創建者的角色。 你的目標是從【給定指令】中獲取靈感,創建一個全新的指令。" response = post_http_request( prompt, system_prompt, host, authorization, max_new_tokens, temperature, top_k, top_p) output = get_response(response) print(f" --- output: {output}\n", flush=True)其中:
host:配置為已獲取的服務訪問地址。
authorization:配置為已獲取的服務Token。
批量實現指令增廣
您可以使用上述EAS在線服務進行批量調用,實現批量指令增廣。以下代碼示例展示了如何讀取自定義的JSON格式數據集,批量調用上面的模型接口進行指令增廣。您需要在終端中,創建并執行如下Python代碼文件來批量調用模型服務。
import requests
import json
import random
from tqdm import tqdm
from typing import List
input_file_path = "input.json" # 輸入文件名
with open(input_file_path) as fp:
data = json.load(fp)
total_size = 10 # 期望的擴展后的總數據量
pbar = tqdm(total=total_size)
while len(data) < total_size:
prompt = random.sample(data, 1)[0]["instruction"]
system_prompt = "我希望你扮演一個指令創建者的角色。 你的目標是從【給定指令】中獲取靈感,創建一個全新的指令。"
top_k = 50
top_p = 0.95
temperature = 1
max_new_tokens = 2048
host = "EAS HOST"
authorization = "EAS TOKEN"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
temp = {
"instruction": output
}
data.append(temp)
pbar.update(1)
pbar.close()
output_file_path = "output.json" # 輸出文件名
with open(output_file_path, 'w') as f:
json.dump(data, f, ensure_ascii=False)其中:
host:配置為已獲取的服務訪問地址。
authorization:配置為已獲取的服務Token。
file_path:請替換為數據集文件所在的本地路徑。
post_http_request和get_response函數的定義與其在調用模型服務的Python腳本中對應的函數定義保持一致。
您也可以使用PAI-Designer的LLM-指令擴充(DLC)組件零代碼實現上述功能。具體操作方法,請參考自定義工作流demo。
(可選)使用指令優化模型進行指令優化
指令優化是大語言模型提示工程(Prompt Engineering)的另一種常見技術,用于自動優化用戶提供的指令數據集,生成更加詳細的指令。這些更詳細的指令能讓大語言模型輸出更詳細的回復。
例如,在指令優化模型中給定如下輸入:
如何做魚香肉絲? 如何準備GRE考試? 如果被朋友誤會了怎么辦?模型輸出類似如下結果:
請提供一個詳細的中國四川風味的魚香肉絲的食譜。包括所需的具體材料列表(如蔬菜、豬肉和調料),以及詳細的步驟說明。如果可能的話,還請推薦適合搭配這道菜的小菜和主食。 請提供一個詳細的指導方案,包括GRE考試的報名、所需資料、備考策略和建議的復習資料。同時,如果可以的話,也請推薦一些有效的練習題和模擬考試來幫助我更好地準備考試。 請提供一個詳細的指導,教我如何在被朋友誤會時保持冷靜和理智,并且有效地溝通來解決問題。請包括一些實用的建議,例如如何表達自己的想法和感受,以及如何避免誤解加劇,并且建議一些具體的對話場景和情境,以便我能更好地理解和練習。
由于指令的詳細性直接影響了大語言模型的輸出指令,進行指令優化能有效提升最終產出學生模型的效果。基于Qwen2基座模型,PAI提供了兩款自主研發的指令優化模型,分別為Qwen2-1.5B-Instruct-Refine和Qwen2-7B-Instruct-Refine。您可以在快速開始(QuickStart)中一鍵部署模型服務,具體操作步驟如下:
部署模型服務
進入Model Gallery頁面。
登錄PAI控制臺。
在頂部左上角根據實際情況選擇地域。
在左側導航欄選擇工作空間列表,單擊指定工作空間名稱,進入對應工作空間內。
在左側導航欄選擇。
在Model Gallery頁面右側的模型列表中,搜索Qwen2-1.5B-Instruct-Refine或Qwen2-7B-Instruct-Refine,并在相應卡片中單擊部署。
在部署配置面板中,系統已默認配置了模型服務信息和資源部署信息,您也可以根據需要進行修改。參數配置完成后單擊部署按鈕。
在計費提醒對話框中,單擊確定。
系統自動跳轉到部署任務頁面,當狀態為運行中時,表示服務部署成功。
調用模型服務
服務部署成功后,您可以使用API進行模型推理。具體使用方法參考LLM大語言模型部署。以下提供一個示例,展示如何通過客戶端發起Request調用:
獲取服務訪問地址和Token。
在服務詳情頁面,單擊基本信息區域的查看調用信息。
在調用信息對話框中,查詢服務訪問地址和Token,并保存到本地。
在終端中,創建并執行如下Python代碼文件來調用服務。
import argparse import json import requests from typing import List def post_http_request(prompt: str, system_prompt: str, host: str, authorization: str, max_new_tokens: int, temperature: float, top_k: int, top_p: float) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "do_sample": True, "eos_token_id": 151645 } response = requests.post(host, headers=headers, json=pload) return response def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] return output if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=2) parser.add_argument("--top-p", type=float, default=0.95) parser.add_argument("--max-new-tokens", type=int, default=256) parser.add_argument("--temperature", type=float, default=0.5) parser.add_argument("--prompt", type=str, default="給我唱首歌。") args = parser.parse_args() prompt = args.prompt top_k = args.top_k top_p = args.top_p temperature = args.temperature max_new_tokens = args.max_new_tokens host = "EAS HOST" authorization = "EAS TOKEN" print(f" --- input: {prompt}\n", flush=True) system_prompt = "請優化這個指令,將其修改為一個更詳細具體的指令。" response = post_http_request( prompt, system_prompt, host, authorization, max_new_tokens, temperature, top_k, top_p) output = get_response(response) print(f" --- output: {output}\n", flush=True)其中:
host:配置為已獲取的服務訪問地址。
authorization:配置為已獲取的服務Token。
批量實現指令優化
您可以使用上述EAS在線服務進行批量調用,實現批量指令優化。以下代碼示例展示了如何讀取自定義的JSON格式數據集,批量調用上面的模型接口進行質量優化。您需要在終端中,創建并執行如下Python代碼文件來批量調用模型服務。
import requests
import json
import random
from tqdm import tqdm
from typing import List
input_file_path = "input.json" # 輸入文件名
with open(input_file_path) as fp:
data = json.load(fp)
pbar = tqdm(total=len(data))
new_data = []
for d in data:
prompt = d["instruction"]
system_prompt = "請優化以下指令。"
top_k = 50
top_p = 0.95
temperature = 1
max_new_tokens = 2048
host = "EAS HOST"
authorization = "EAS TOKEN"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
temp = {
"instruction": output
}
new_data.append(temp)
pbar.update(1)
pbar.close()
output_file_path = "output.json" # 輸出文件名
with open(output_file_path, 'w') as f:
json.dump(new_data, f, ensure_ascii=False)
其中:
host:配置為已獲取的服務訪問地址。
authorization:配置為已獲取的服務Token。
file_path:請替換為數據集文件所在的本地路徑。
post_http_request和get_response函數的定義與其在調用模型服務的Python腳本中對應的函數定義保持一致。
您也可以使用PAI-Designer的LLM-指令優化(DLC)組件零代碼實現上述功能。具體操作方法,請參考自定義工作流demo。
部署教師大語言模型生成對應回復
部署模型服務
在優化好數據集中的指令以后,您可以按照以下操作步驟,部署教師大語言模型生成對應回復。
進入Model Gallery頁面。
登錄PAI控制臺。
在頂部左上角根據實際情況選擇地域。
在左側導航欄選擇工作空間列表,單擊指定工作空間名稱,進入對應工作空間內。
在左側導航欄選擇。
在Model Gallery頁面右側的模型列表中,搜索通義千問2-72B-Instruct,并在相應卡片中單擊部署。
在部署配置面板中,系統已默認配置了模型服務信息和資源部署信息,您也可以根據需要進行修改。參數配置完成后單擊部署按鈕。
在計費提醒對話框中,單擊確定。
系統自動跳轉到部署任務頁面,當狀態為運行中時,表示服務部署成功。
調用模型服務
服務部署成功后,您可以使用API進行模型推理。具體使用方法參考LLM大語言模型部署。以下提供一個示例,展示如何通過客戶端發起Request調用:
獲取服務訪問地址和Token。
在服務詳情頁面,單擊基本信息區域的查看調用信息。
在調用信息對話框中,查詢服務訪問地址和Token,并保存到本地。
在終端中,創建并執行如下Python代碼文件來調用服務。
import argparse import json import requests from typing import List def post_http_request(prompt: str, system_prompt: str, host: str, authorization: str, max_new_tokens: int, temperature: float, top_k: int, top_p: float) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "do_sample": True, } response = requests.post(host, headers=headers, json=pload) return response def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] return output if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=50) parser.add_argument("--top-p", type=float, default=0.95) parser.add_argument("--max-new-tokens", type=int, default=2048) parser.add_argument("--temperature", type=float, default=0.5) parser.add_argument("--prompt", type=str) parser.add_argument("--system_prompt", type=str) args = parser.parse_args() prompt = args.prompt system_prompt = args.system_prompt top_k = args.top_k top_p = args.top_p temperature = args.temperature max_new_tokens = args.max_new_tokens host = "EAS HOST" authorization = "EAS TOKEN" print(f" --- input: {prompt}\n", flush=True) response = post_http_request( prompt, system_prompt, host, authorization, max_new_tokens, temperature, top_k, top_p) output = get_response(response) print(f" --- output: {output}\n", flush=True)其中:
host:配置為已獲取的服務訪問地址。
authorization:配置為已獲取的服務Token。
批量實現教師模型的指令標注
以下代碼示范了如何讀取自定義JSON格式數據集,批量調用上述模型接口進行教師模型標注。您需要在終端中,創建并執行如下Python代碼文件來批量調用模型服務。
import json
from tqdm import tqdm
import requests
from typing import List
input_file_path = "input.json" # 輸入文件名
with open(input_file_path) as fp:
data = json.load(fp)
pbar = tqdm(total=len(data))
new_data = []
for d in data:
system_prompt = "You are a helpful assistant."
prompt = d["instruction"]
print(prompt)
top_k = 50
top_p = 0.95
temperature = 0.5
max_new_tokens = 2048
host = "EAS HOST"
authorization = "EAS TOKEN"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
temp = {
"instruction": prompt,
"output": output
}
new_data.append(temp)
pbar.update(1)
pbar.close()
output_file_path = "output.json" # 輸出文件名
with open(output_file_path, 'w') as f:
json.dump(new_data, f, ensure_ascii=False)其中:
host:配置為已獲取的服務訪問地址。
authorization:配置為已獲取的服務Token。
file_path:請替換為數據集文件所在的本地路徑。
post_http_request和get_response函數的定義與其在調用模型服務腳本中對應的函數定義保持一致。
蒸餾訓練較小的學生模型
訓練模型
當獲得教師模型的回復后,您可以在快速開始(QuickStart)中,實現學生模型的訓練,無需編寫代碼,極大簡化了模型的開發過程。本方案以Qwen2-7B-Instruct模型為例,為您介紹如何使用已準備好的訓練數據,在快速開始(QuickStart)中進行模型訓練,具體操作步驟如下:
進入Model Gallery頁面。
登錄PAI控制臺。
在頂部左上角根據實際情況選擇地域。
在左側導航欄選擇工作空間列表,單擊指定工作空間名稱,進入對應工作空間內。
在左側導航欄選擇。
在Model Gallery頁面右側的模型列表中,搜索并單擊通義千問2-72B-Instruct模型卡片,進入模型詳情頁面。
在模型詳情頁面,單擊右上角的微調訓練。
在微調訓練配置面板中,配置以下關鍵參數,其他參數取默認配置。
參數
描述
默認值
數據集配置
訓練數據集
在下拉列表中選擇OSS文件或目錄,并按照以下步驟選擇數據集文件所在的OSS存儲路徑:
單擊
 ,并選擇已創建的OSS存儲空間。
,并選擇已創建的OSS存儲空間。單擊上傳文件,并按控制臺操作指引,將從上述步驟獲得的數據集文件上傳到OSS目錄中。
單擊確定。
無
訓練輸出配置
model
單擊
 ,選擇已創建的OSS存儲目錄。
,選擇已創建的OSS存儲目錄。無
tensorboard
單擊
,選擇已創建的OSS存儲目錄。無
計算資源配置
任務資源
選擇資源規格,系統會自動推薦適合的資源規格。
無
超參數配置
learning_rate
模型訓練的學習率,Float類型。
5e-5
num_train_epochs
訓練輪次,INT類型。
1
per_device_train_batch_size
每張GPU卡在一次訓練迭代的數據量,INT類型。
1
seq_length
文本序列長度,INT類型。
128
lora_dim
LoRA維度,INT類型。當lora_dim>0時,使用LoRA/QLoRA輕量化訓練。
32
lora_alpha
LoRA權重,INT類型。當lora_dim>0時,使用LoRA/QLoRA輕量化訓練,該參數生效。
32
load_in_4bit
模型是否以4比特加載,bool類型。取值如下:
true
false
當lora_dim>0、load_in_4bit為true且load_in_8bit為false時,使用4比特QLoRA輕量化訓練。
true
load_in_8bit
模型是否以8比特加載,bool類型。取值如下:
true
false
當lora_dim>0、load_in_4bit為false且load_in_8bit為true時,使用8比特QLoRA輕量化訓練。
false
gradient_accumulation_steps
梯度累積步數,INT類型。
8
apply_chat_template
算法是否結合訓練數據與默認的Chat Template來優化模型輸出,bool類型。取值如下:
true
false
以Qwen2系列模型為例,格式為:
問題:
<|im_end|>\n<|im_start|>user\n + instruction + <|im_end|>\n答案:
<|im_start|>assistant\n + output + <|im_end|>\n
true
system_prompt
模型訓練使用的系統提示語,String類型。
You are a helpful assistant
參數配置完成后,單擊訓練。
在計費提醒對話框中,單擊確定。
系統將自動跳轉到訓練任務頁面。
部署模型服務
當模型訓練完成后,您可以按照以下操作步驟,將模型部署為EAS在線服務。
在訓練任務頁面右側,單擊部署。
在部署配置面板中,系統已默認配置了模型服務信息和資源部署信息,您也可以根據需要進行修改。參數配置完成后單擊部署按鈕。
在計費提醒對話框中,單擊確定。
系統自動跳轉到部署任務頁面,當狀態為運行中時,表示服務部署成功。
調用模型服務
服務部署成功后,您可以使用API進行模型推理。具體使用方法參考LLM大語言模型部署。