目標識別:TorchAcc提速Swin Transformer分布式訓練
阿里云PAI為您提供了部分典型場景下的示例模型,便于您便捷地接入TorchAcc進行訓練加速。本文為您介紹如何在Swin Transformer分布式訓練中接入TorchAcc并實現(xiàn)訓練加速。
測試環(huán)境配置
測試環(huán)境配置方法,請參見配置測試環(huán)境。
本案例以PAI-DSW環(huán)境V100M16卡型為例,例如:節(jié)點規(guī)格選擇ecs.gn6v-c8g1.16xlarge-64c256gNVIDIA V100 * 8。
接入TorchAcc加速Swin Transformer分布式訓練
以DSW環(huán)境為例:
進入DSW實例頁面下載并解壓測試代碼及腳本文件。
在交互式建模(DSW)頁面,單擊DSW實例操作列下的打開。
在Notebook頁簽的Launcher頁面,單擊快速開始區(qū)域Notebook下的Python3。
執(zhí)行以下命令下載并解壓測試代碼及腳本文件。
!wget http://odps-release.cn-hangzhou.oss.aliyun-inc.com/torchacc/accbench/gallery/swin_transformer.tar.gz && tar -zxvf swin_transformer.tar.gz
進入
Swin-Transformer目錄,雙擊打開swin_transformer.ipynb文件。后續(xù),您可以直接在該文件中運行下述步驟中的命令,當成功運行結束一個步驟命令后,再順次運行下個步驟的命令。
執(zhí)行以下命令下載類似Imagenet-1k的mock數(shù)據(jù)集并安裝Swin Transformer模型依賴的第三方包。
!bash prepare.sh分別使用普通訓練方法(baseline)和接入TorchAcc進行Swin Transformer模型分布式訓練,來驗證TorchAcc的性能提升效果。
說明在測試不同GPU卡型(例如V100、A10等)時,可以通過調整batch_size來適配不同卡型的顯存大小。
在測試不同機器實例時,由于單機GPU卡數(shù)不同(假設為N),因此可以通過設置nproc_per_node來啟動單卡或多卡的任務,其中:1<=nproc_per_node<=N。
Pytorch Eager單卡(baseline訓練)
!#!/bin/bash !set -ex !python launch_single_task.py --amp_level=O1 --batch_size=32 --nproc_per_node=1Pytorch Eager八卡(baseline訓練)
!#!/bin/bash !set -ex !python launch_single_task.py --amp_level=O1 --batch_size=32 --nproc_per_node=8TorchAcc單卡(PAI-OPT)
!#!/bin/bash !set -ex !python launch_single_task.py --nproc_per_node=1 --amp_level=O2 --kernel-opt --batch_size=32 --nproc_per_node=1TorchAcc八卡(PAI-OPT)
!#!/bin/bash !set -ex !python launch_single_task.py --nproc_per_node=1 --amp_level=O2 --kernel-opt --batch_size=32 --nproc_per_node=8
其中:普通訓練方法和接入TorchAcc訓練方法的優(yōu)化配置如下:
baseline:Torch112+DDP+AMPO1
PAI-Opt:Torch112+TorchAcc+AMPO1
執(zhí)行以下命令,獲取性能數(shù)據(jù)結果。
import os from plot import plot, traverse from parser import parse_file #import seaborn as sns if __name__ == '__main__': path = "output" file_names = {} traverse(path, file_names) for model, tags in file_names.items(): for tag, suffixes in tags.items(): title = model + "_" + tag label = [] api_data = [] for suffix, o_suffixes in suffixes.items(): label.append(suffix) for output_suffix, node_ranks in o_suffixes.items(): assert "0" in node_ranks assert "log" in node_ranks["0"] parse_data = parse_file(node_ranks["0"]["log"]) api_data.append(parse_data) plot(title, label, api_data)生成如下圖所示結果。
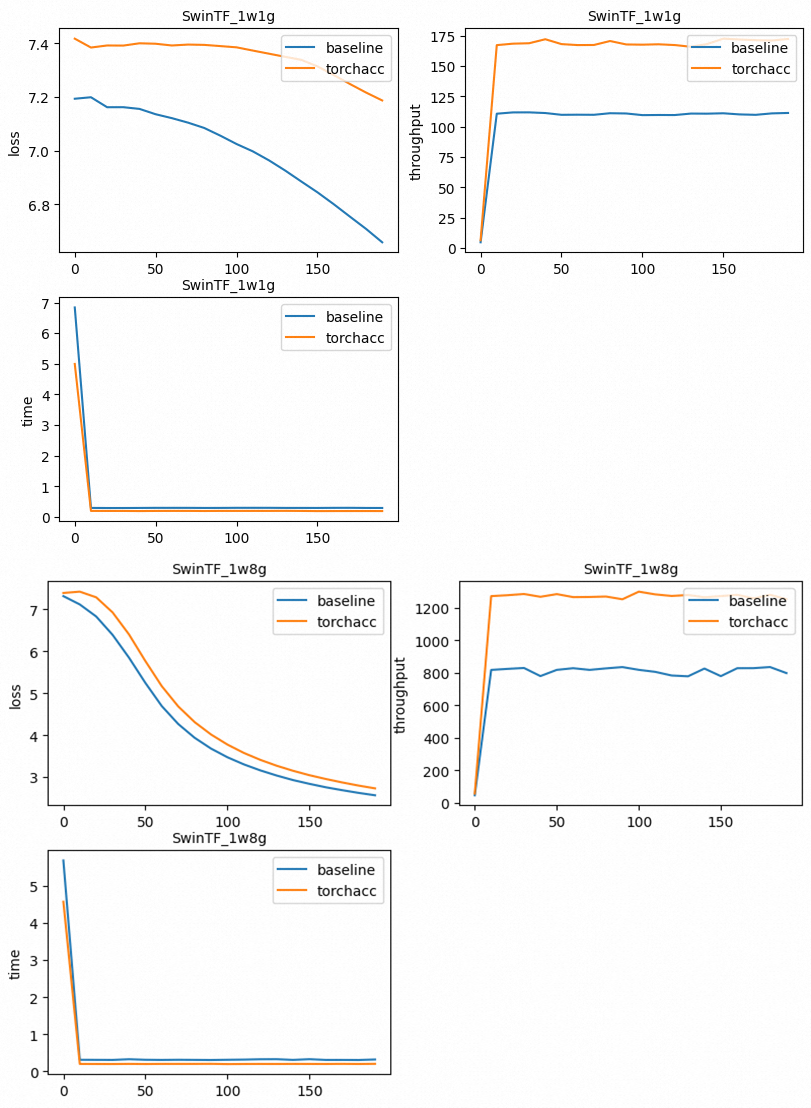
實驗結果表明,使用TorchAcc進行Swin Transformer分布式訓練可以明顯提升性能。接入TorchAcc更詳細的代碼實現(xiàn)原理,請參見代碼實現(xiàn)原理。
代碼實現(xiàn)原理
將上述的Swin Transformer模型接入TorchAcc框架進行分布式訓練加速的代碼配置,請參考已下載的代碼文件Swin-Transformer/main.py。
Import TorchAcc API
在main函數(shù)import處添加以下代碼:
def enable_torchacc_compiler():
return os.getenv('USE_TORCHACC') is not None如果打開TorchAcc,則會在main.py文件import處添加以下代碼:
from logger import create_logger, enable_torchacc_compiler, enable_torchacc_kernel, log_params, log_metrics
+if enable_torchacc_compiler():
+ import torchacc.torch_xla.core.xla_model as xm
+ import torchacc.torch_xla.distributed.parallel_loader as pl
+ import torchacc.torch_xla.test.test_utils as test_utils
+ import torchacc.torch_xla.utils.utils as xu
+ from torchacc.torch_xla.amp import autocast, GradScaler
+ dist.get_rank = xm.get_ordinal
+ dist.get_world_size = xm.xrt_world_size
+ scaler = GradScaler()
+ device = xm.xla_device()
else:
from torch.cuda.amp import GradScaler, autocast
scaler = GradScaler()分布式初始化
在調用dist.init_process_group函數(shù)時,將backend參數(shù)設置為xla:
dist.init_process_group(backend="xla", init_method="env://")set_replication+封裝dataloader+model placement+optimizer
在模型和dataloader定義完成之后,獲取xla_device并調用set_replication函數(shù),以封裝dataloader并設置模型的設備位置。
+if enable_torchacc_compiler():
+ xm.set_replication(device, [device])
+ model.to(device)
+ data_loader_train = pl.MpDeviceLoader(data_loader_train, device)
+ data_loader_val = pl.MpDeviceLoader(data_loader_val, device)
+ model_without_ddp = model
+ optimizer = build_optimizer(config, model)
+else:
model.cuda()
optimizer = build_optimizer(config, model)
if config.AMP_OPT_LEVEL == "O2":
loss_scale = float(config.AMP_LOSS_SCALE) if config.AMP_LOSS_SCALE != "dynamic" else "dynamic"
model, optimizer = amp.initialize(model, optimizer, opt_level=config.AMP_OPT_LEVEL, loss_scale=loss_scale)
local_rank = int(os.environ["LOCAL_RANK"]) if 'LOCAL_RANK' in os.environ else config.LOCAL_RANK
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], broadcast_buffers=False)
model_without_ddp = model.module在Swin-Transformer/data/build.py中,如果dataset使用了mixup_fn,則TorchAcc場景下需要替換成collate_mixedup function,如果沒有使用mixup_fn,則可以忽略。
# setup mixup / cutmix
mixup_fn = None
collate_mixup_fn = None
mixup_active = config.AUG.MIXUP > 0 or config.AUG.CUTMIX > 0. or config.AUG.CUTMIX_MINMAX is not None
if mixup_active:
# 使用TorchAcc時使用collate_mixedup_fn
+ if config.AUG.COLLATE_MIXUP:
+ collate_mixup_fn = CollateMixup(
+ mixup_alpha=config.AUG.MIXUP, cutmix_alpha=config.AUG.CUTMIX, cutmix_minmax=config.AUG.CUTMIX_MINMAX,
+ prob=config.AUG.MIXUP_PROB, switch_prob=config.AUG.MIXUP_SWITCH_PROB, mode=config.AUG.MIXUP_MODE,
+ label_smoothing=config.MODEL.LABEL_SMOOTHING, num_classes=config.MODEL.NUM_CLASSES
+ )
+ else:
mixup_fn = Mixup(
mixup_alpha=config.AUG.MIXUP, cutmix_alpha=config.AUG.CUTMIX, cutmix_minmax=config.AUG.CUTMIX_MINMAX,
prob=config.AUG.MIXUP_PROB, switch_prob=config.AUG.MIXUP_SWITCH_PROB, mode=config.AUG.MIXUP_MODE,
label_smoothing=config.MODEL.LABEL_SMOOTHING, num_classes=config.MODEL.NUM_CLASSES
)
data_loader_train = torch.utils.data.DataLoader(
dataset_train, sampler=sampler_train,
batch_size=config.DATA.BATCH_SIZE,
num_workers=config.DATA.NUM_WORKERS,
pin_memory=config.DATA.PIN_MEMORY,
collate_fn=collate_mixup_fn, # TorchAcc enabled
drop_last=True,
)
data_loader_val = torch.utils.data.DataLoader(
dataset_val, sampler=sampler_val,
batch_size=config.DATA.BATCH_SIZE,
shuffle=False,
num_workers=config.DATA.NUM_WORKERS,
pin_memory=config.DATA.PIN_MEMORY,
drop_last=False
)梯度allreduce通信
如果啟用了AMP開關,需要在loss backward后對梯度進行allreduce,并在backward和apply計算階段修改代碼。具體請參考main.py文件的273-324行代碼。
if config.TRAIN.ACCUMULATION_STEPS > 1:
loss = loss / config.TRAIN.ACCUMULATION_STEPS
if config.AMP_OPT_LEVEL == "O2":
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
if config.TRAIN.CLIP_GRAD:
grad_norm = torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), config.TRAIN.CLIP_GRAD)
else:
grad_norm = get_grad_norm(amp.master_params(optimizer))
else:
loss.backward()
if config.TRAIN.CLIP_GRAD:
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), config.TRAIN.CLIP_GRAD)
else:
grad_norm = get_grad_norm(model.parameters())
if (idx + 1) % config.TRAIN.ACCUMULATION_STEPS == 0:
optimizer.step()
optimizer.zero_grad()
lr_scheduler.step_update(epoch * num_steps + idx)
else:
optimizer.zero_grad()
if config.AMP_OPT_LEVEL != "O0":
if config.AMP_OPT_LEVEL == "O2":
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
if config.TRAIN.CLIP_GRAD:
grad_norm = torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), config.TRAIN.CLIP_GRAD)
else:
grad_norm = get_grad_norm(amp.master_params(optimizer))
optimizer.step()
else:
scaler.scale(loss).backward()
+ if not enable_torchacc_compiler():
if config.TRAIN.CLIP_GRAD:
scaler.unscale_(optimizer)
+ else:
+ gradients = xm._fetch_gradients(optimizer)
+ xm.all_reduce('sum', gradients, scale=1.0/xm.xrt_world_size())
if config.TRAIN.CLIP_GRAD:
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), config.TRAIN.CLIP_GRAD)
else:
grad_norm = get_grad_norm(model.parameters())
scaler.step(optimizer)
scaler.update()
else:
loss.backward()
if config.TRAIN.CLIP_GRAD:
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), config.TRAIN.CLIP_GRAD)
else:
grad_norm = get_grad_norm(model.parameters())
optimizer.step()
lr_scheduler.step_update(epoch * num_steps + idx)Training Loop封裝
更新代碼邏輯:
從dataloader取出樣本(數(shù)據(jù))作為后面訓練的輸入,具體請參考main.py文件的262-264行代碼。
+if not enable_torchacc_compiler(): samples = samples.cuda(non_blocking=True) targets = targets.cuda(non_blocking=True)如果開啟了AMP功能,由于TorchAcc暫時只能使用AMP的AutoCast功能,因此需要在training loop中添加autocast_context_manager代碼,具體請參考main.py文件的269-270行代碼。
with autocast_context_manager(config): outputs = model(samples)其中
autocast_context_manager函數(shù)的實現(xiàn)可以參考main.py文件的79-87行代碼。def autocast_context_manager(config): if config.AMP_OPT_LEVEL == "O2": if enable_torchacc_compiler(): ctx_manager = autocast() else: ctx_manager = contextlib.nullcontext() if sys.version_info >= (3, 7) else contextlib.suppress() else: ctx_manager = torch.cuda.amp.autocast(enabled=config.AMP_ENABLE) return ctx_manager