參數服務器PS(Parameter Server)致力于解決大規模的離線及在線訓練任務,SMART(Scalable Multiple Additive Regression Tree)是GBDT(Gradient Boosting Decision Tree)基于PS實現的迭代算法。PS-SMART支持百億樣本及幾十萬特征的訓練任務,可以在上千節點中運行。同時,PS-SMART支持多種數據格式及直方圖近似等優化技術。
使用限制
PS-SMART多分類組件的輸入數據需要滿足以下要求:
PS-SMART多分類組件的目標列僅支持數值類型。如果MaxCompute表數據是STRING類型,則需要進行類型轉換。例如,分類目標是Good/Medium/Bad字符串,需要轉換為0/1/2。
如果數據是KV格式,則特征ID必須為正整數,特征值必須為實數。如果特征ID為字符串類型,則需要使用序列化組件進行序列化。如果特征值為類別型字符串,需要進行特征離散化等特征工程處理。
雖然PS-SMART多分類組件支持數十萬特征任務,但是消耗資源大且運行速度慢,可以使用GBDT類算法進行訓練。GBDT類算法適合直接使用連續特征進行訓練,除需要對類別特征進行One-Hot編碼(篩除低頻特征)外,不建議對其他連續型數值特征進行離散化。
PS-SMART算法會引入隨機性。例如,data_sample_ratio及fea_sample_ratio表示的數據和特征采樣、算法使用的直方圖近似優化及局部Sketch歸并為全局Sketch的順序隨機性。雖然多個Worker分布式執行時,樹結構不同,但是從理論上可以保證模型效果相近。如果您在訓練過程中,使用相同數據和參數,多次得到的結果不一致,屬于正常現象。
如果需要加速訓練,可以增大計算核心數。因為PS-SMART算法需要所有服務器獲得資源后,才能開始訓練,所以集群忙碌時,申請較多資源會增加等待時間。
注意事項
使用PS-SMART多分類組件時,需要注意以下事宜:
雖然PS-SMART多分類組件支持數十萬特征任務,但是消耗資源大且運行速度慢,可以使用GBDT類算法進行訓練。GBDT類算法適合直接使用連續特征進行訓練,除需要對類別特征進行One-Hot編碼(篩除低頻特征)外,不建議對其他連續型數值特征進行離散化。
PS-SMART算法會引入隨機性。例如,data_sample_ratio及fea_sample_ratio表示的數據和特征采樣、算法使用的直方圖近似優化及局部Sketch歸并為全局Sketch的順序隨機性。雖然多個Worker分布式執行時,樹結構不同,但是從理論上可以保證模型效果相近。如果您在訓練過程中,使用相同數據和參數,多次得到的結果不一致,屬于正常現象。
如果需要加速訓練,可以增大計算核心數。因為PS-SMART算法需要所有服務器獲得資源后,才能開始訓練,所以集群忙碌時,申請較多資源會增加等待時間。
組件配置
您可以使用以下任意一種方式,配置PS-SMART多分類組件參數。
方式一:可視化方式
在Designer工作流頁面配置組件參數。
頁簽 | 參數 | 描述 |
字段設置 | 是否稀疏格式 | 稀疏格式的KV之間使用空格分隔,key與value之間使用英文冒號(:)分隔。例如1:0.3 3:0.9。 |
選擇特征列 | 輸入表中,用于訓練的特征列。如果輸入數據是Dense格式,則只能選擇數值(BIGINT或DOUBLE)類型。如果輸入數據是Sparse KV格式,且key和value是數值類型,則只能選擇STRING類型。 | |
選擇標簽列 | 輸入表的標簽列,支持STRING類型。如果是內部列存儲,則內容僅支持數值類型。例如二分類中的0和1。 | |
選擇權重列 | 列可以對每行樣本進行加權,支持數值類型。 | |
參數設置 | 類別數 | 多分類的類別數量。如果類別數為n,則標簽列的取值為{0,1,2,...,n-1}。 |
評估指標類型 | 支持multiclass negative log likelihood和multiclass classification error類型。 | |
樹數量 | 需要配置為樹數量,正整數,樹數量和訓練時間成正比。 | |
樹最大深度 | 默認值為5,即最多32個葉子節點。 | |
數據采樣比例 | 構建每棵樹時,采樣部分數據進行學習,構建弱學習器,從而加快訓練。 | |
特征采樣比例 | 構建每棵樹時,采樣部分特征進行學習,構建弱學習器,從而加快訓練。 | |
L1懲罰項系數 | 控制葉子節點大小。該參數值越大,葉子節點規模分布越均勻。如果過擬合,則增大該參數值。 | |
L2懲罰項系數 | 控制葉子節點大小。該參數值越大,葉子節點規模分布越均勻。如果過擬合,則增大該參數值。 | |
學習速率 | 取值范圍為(0,1)。 | |
近似Sketch精度 | 構造Sketch的切割分位點閾值。該參數值越小,獲得的桶越多。一般使用默認值0.03,無需手動配置。 | |
最小分裂損失變化 | 分裂節點所需要的最小損失變化。該參數值越大,分裂越保守。 | |
特征數量 | 特征數量或最大特征ID。如果需要估計使用資源,則必須手動配置該參數。 | |
全局偏置項 | 所有樣本的初始預測值。 | |
隨機數產生器種子 | 隨機數種子,整型。 | |
特征重要性類型 | 支持模型中,該特征做為分裂特征的次數、模型中,該特征帶來的信息增益及模型中,該特征在分裂節點覆蓋的樣本數類型。 | |
執行調優 | 核心數 | 默認為系統自動分配。 |
每個核的內存大小 | 單個核心使用的內存,單位為MB。通常無需手動配置,系統自動分配。 |
方式二:PAI命令方式
使用PAI命令方式,配置該組件參數。您可以使用SQL腳本組件進行PAI命令調用,詳情請參見SQL腳本。
#訓練。
PAI -name ps_smart
-project algo_public
-DinputTableName="smart_multiclass_input"
-DmodelName="xlab_m_pai_ps_smart_bi_545859_v0"
-DoutputTableName="pai_temp_24515_545859_2"
-DoutputImportanceTableName="pai_temp_24515_545859_3"
-DlabelColName="label"
-DfeatureColNames="features"
-DenableSparse="true"
-Dobjective="multi:softprob"
-Dmetric="mlogloss"
-DfeatureImportanceType="gain"
-DtreeCount="5";
-DmaxDepth="5"
-Dshrinkage="0.3"
-Dl2="1.0"
-Dl1="0"
-Dlifecycle="3"
-DsketchEps="0.03"
-DsampleRatio="1.0"
-DfeatureRatio="1.0"
-DbaseScore="0.5"
-DminSplitLoss="0"
#預測。
PAI -name prediction
-project algo_public
-DinputTableName="smart_multiclass_input";
-DmodelName="xlab_m_pai_ps_smart_bi_545859_v0"
-DoutputTableName="pai_temp_24515_545860_1"
-DfeatureColNames="features"
-DappendColNames="label,features"
-DenableSparse="true"
-DkvDelimiter=":"
-Dlifecycle="28"模塊 | 參數 | 是否必選 | 描述 | 默認值 |
數據參數 | featureColNames | 是 | 輸入表中,用于訓練的特征列。如果輸入表是Dense格式,則只能選擇數值(BIGINT或DOUBLE)類型。如果輸入表是Sparse KV格式,且KV格式中key和value是數值類型,則只能選擇STRING類型。 | 無 |
labelColName | 是 | 輸入表的標簽列,支持STRING及數值類型。如果是內部存儲,則僅支持數值類型。例如多分類的{0,1,2,…,n-1},其中n表示類別數量。 | 無 | |
weightCol | 否 | 列可以對每行樣本進行加權,支持數值類型。 | 無 | |
enableSparse | 否 | 是否為稀疏格式,取值范圍為{true,false}。稀疏格式的KV之間使用空格分隔,key與value之間使用英文冒號(:)分隔。例如1:0.3 3:0.9。 | false | |
inputTableName | 是 | 輸入表的名稱。 | 無 | |
modelName | 是 | 輸出的模型名稱。 | 無 | |
outputImportanceTableName | 否 | 輸出特征重要性的表名。 | 無 | |
inputTablePartitions | 否 | 格式為ds=1/pt=1。 | 無 | |
outputTableName | 否 | 輸出至MaxCompute的表,二進制格式,不支持讀取,只能通過SMART的預測組件獲取。 | 無 | |
lifecycle | 否 | 輸出表的生命周期。 | 3 | |
算法參數 | classNum | 是 | 多分類的類別數量。如果類別數量為n,則標簽列取值為{0,1,2,...,n-1}。 | 無 |
objective | 是 | 目標函數類型。如果進行多分類訓練,則選擇multi:softprob。 | 無 | |
metric | 否 | 訓練集的評估指標類型,輸出在Logview文件Coordinator區域的stdout。支持以下類型:
| 無 | |
treeCount | 否 | 樹數量,與訓練時間成正比。 | 1 | |
maxDepth | 否 | 樹的最大深度,取值范圍為1~20。 | 5 | |
sampleRatio | 否 | 數據采樣比例,取值范圍為(0,1]。如果取值為1.0,則表示不采樣。 | 1.0 | |
featureRatio | 否 | 特征采樣比例,取值范圍為(0,1]。如果取值為1.0,則表示不采樣。 | 1.0 | |
l1 | 否 | L1懲罰項系數。該參數值越大,葉子節點分布越均勻。如果過擬合,則增大該參數值。 | 0 | |
l2 | 否 | L2懲罰項系數。該參數值越大,葉子節點分布越均勻。如果過擬合,則增大該參數值。 | 1.0 | |
shrinkage | 否 | 取值范圍為(0,1)。 | 0.3 | |
sketchEps | 否 | 構造Sketch的切割分位點閾值,桶數為O(1.0/sketchEps)。該參數值越小,獲得的桶越多。一般使用默認值,無需手動配置。取值范圍為(0,1)。 | 0.03 | |
minSplitLoss | 否 | 分裂節點所需要的最小損失變化。該參數值越大,分裂越保守。 | 0 | |
featureNum | 否 | 特征數量或最大特征ID。如果需要估計使用資源,則必須手動配置該參數。 | 無 | |
baseScore | 否 | 所有樣本的初始預測值。 | 0.5 | |
randSeed | 否 | 隨機數種子,整型。 | 無 | |
featureImportanceType | 否 | 計算特征重要性的類型,包括:
| gain | |
調優參數 | coreNum | 否 | 核心數量,該參數值越大,算法運行越快。 | 系統自動分配 |
memSizePerCore | 否 | 每個核心使用的內存,單位為MB。 | 系統自動分配 |
示例
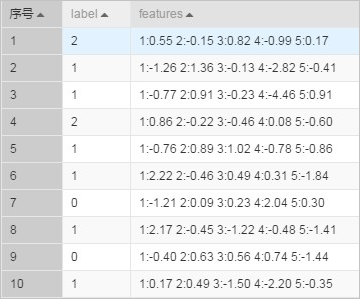
使用開發ODPS SQL任務創建表smart_multiclass_input。以KV格式數據為例,命令如下。
drop table if exists smart_multiclass_input; create table smart_multiclass_input lifecycle 3 as select * from ( select '2' as label, '1:0.55 2:-0.15 3:0.82 4:-0.99 5:0.17' as features union all select '1' as label, '1:-1.26 2:1.36 3:-0.13 4:-2.82 5:-0.41' as features union all select '1' as label, '1:-0.77 2:0.91 3:-0.23 4:-4.46 5:0.91' as features union all select '2' as label, '1:0.86 2:-0.22 3:-0.46 4:0.08 5:-0.60' as features union all select '1' as label, '1:-0.76 2:0.89 3:1.02 4:-0.78 5:-0.86' as features union all select '1' as label, '1:2.22 2:-0.46 3:0.49 4:0.31 5:-1.84' as features union all select '0' as label, '1:-1.21 2:0.09 3:0.23 4:2.04 5:0.30' as features union all select '1' as label, '1:2.17 2:-0.45 3:-1.22 4:-0.48 5:-1.41' as features union all select '0' as label, '1:-0.40 2:0.63 3:0.56 4:0.74 5:-1.44' as features union all select '1' as label, '1:0.17 2:0.49 3:-1.50 4:-2.20 5:-0.35' as features ) tmp;生成的數據如下。
構建如下工作流,詳情請參見算法建模。
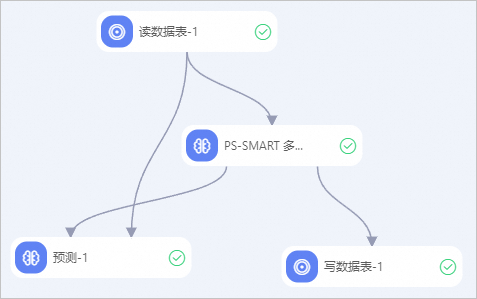
配置組件參數。
單擊讀數據表-1組件,在右側表選擇頁簽中,配置表名為smart_multiclass_input。
配置PS-SMART多分類-1組件的參數(配置如下表格中的參數,其余參數使用默認值)。
頁簽
參數
描述
字段設置
特征列
選擇features列。
標簽列
選擇label列。
是否稀疏格式
選中是否稀疏格式復選框。
參數設置
類別數
輸入3。
評估指標類型
選擇multiclass negative log likelihood。
樹數量
輸入5。
配置預測-1組件的參數(配置如下表格中的參數,其余參數使用默認值)。
頁簽
參數
描述
字段設置
特征列
選擇features列。
原樣輸出列
選擇label列和features列。
稀疏矩陣
選中稀疏矩陣復選框。
key與value分隔符
輸入半角冒號(:)。
kv對間的分隔符
使用空格作為分隔符,留空即可。
單擊寫數據表-1組件,在右側表選擇頁簽中,配置寫入表表名為smart_multiclass_output。
單擊畫布中的運行按鈕
 ,運行工作流。
,運行工作流。工作流執行成功后,右鍵單擊預測-1組件,在快捷菜單中,選擇,查看統一預測組件的預測結果。
 其中:
其中:prediction_detail列中的0、1及2表示多分類的類別。
predict_result列表示預測的結果類別。
predict_score列表示預測為predict_result類別的概率。
右鍵單擊PS-SMART多分類-1組件,在快捷菜單中,選擇,查看特征重要性。
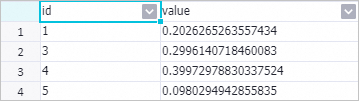 其中:
其中:id列表示傳入的特征序號。因為該示例的輸入數據是KV格式,所以id列表示KV對中的key。
value列表示特征重要性類型,默認為gain,即該特征對模型帶來的信息增益之和。
PS-SMART模型部署說明
如果您需要將PS-SMART組件生成的模型部署為在線服務,您需要在該組件的下游接入通用模型導出組件,并按照PS系列組件的使用方式配置組件參數,詳情請參見通用模型導出。
組件運行成功后,您可以前往PAI EAS模型在線服務頁面,部署模型服務,詳情請參見服務部署:控制臺。