評分卡是信用風險評估領域常用的建模工具,其原理是通過分箱輸入將原始變量離散化后再使用線性模型(邏輯回歸或線性回歸等)進行模型訓練,其中包含特征選擇及分數轉換等功能。同時也支持在訓練過程中為變量添加約束條件。
如果未指定分箱輸入,則評分卡訓練過程完全等價于一般的邏輯回歸或線性回歸。
使用限制
使用評分卡訓練組件生成的臨時模型僅支持使用MaxCompute臨時表進行存儲,該臨時表在Studio中的默認生命周期為369天,在Designer中的默認生命周期為當前所在工作空間配置的臨時表保存時長,具體配置方法請參見管理工作空間。如果您需要長期使用該臨時模型,需要通過寫數據表進行固化,操作詳情請參見如何將運行畫布節點輸出的臨時表數據進行持久化存儲?。
基本概念
以下介紹評分卡訓練過程中的相關概念:
特征工程
評分卡與普通線性模型的最大區別在于進行線性模型訓練之前會對數據進行一定的特征工程處理。本文中,評分卡提供了如下兩種特征工程方法:
先通過分箱組件將特征離散化,再將每個變量根據分箱結果進行One-Hot編碼,分別生成N個Dummy變量(N為變量的分箱數量)。
說明使用Dummy變量變換時,每個原始變量的Dummy變量之間可以設置相關的約束,詳情請參見分箱。
先通過分箱組件將特征離散化,再進行WOE轉換,即使用變量落入的分箱所對應的WOE值替換變量的原始值。
分數轉換
評分卡的信用評分等場景中,需要通過線性變換將預測得到的樣本odds轉換成分數,通常通過如下的線性變換實現。
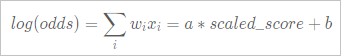 您可以通過如下三個參數指定線性變換關系:
您可以通過如下三個參數指定線性變換關系:scaledValue:給出一個分數的基準點。
odds:在給定的分數基準點處的odds值。
pdo(Point Double Odds):表示分數增長多少分時,odds值增長到雙倍。
例如,scaledValue=800,odds=50,pdo=25,則表示指定了直線中的如下兩點。
log(50)=a×800+b log(100)=a×825+b解出a和b,對模型中的分數進行線性變換即可得到變換后的變量分。
Scaling信息由參數
-Dscale指定,格式為JSON,示例如下。{"scaledValue":800,"odds":50,"pdo":25}當
-Dscale參數不為空時,需要同時配置scaledValue、odds及pdo的值。訓練過程中增加約束
評分卡訓練過程支持對變量添加約束。例如指定某個bin所對應的分數為固定值,兩個bin的分數滿足一定比例,對bin之間的分數進行大小限制,或設置bin的分數按照bin的WOE值排序等。約束的實現依賴于底層帶約束的優化算法,可以在分箱組件中通過可視化方式設置約束,設置完成后分箱組件會生成一個JSON格式的約束條件,并將其自動傳遞給下游連接的訓練組件,詳情請參見如下演示操作。
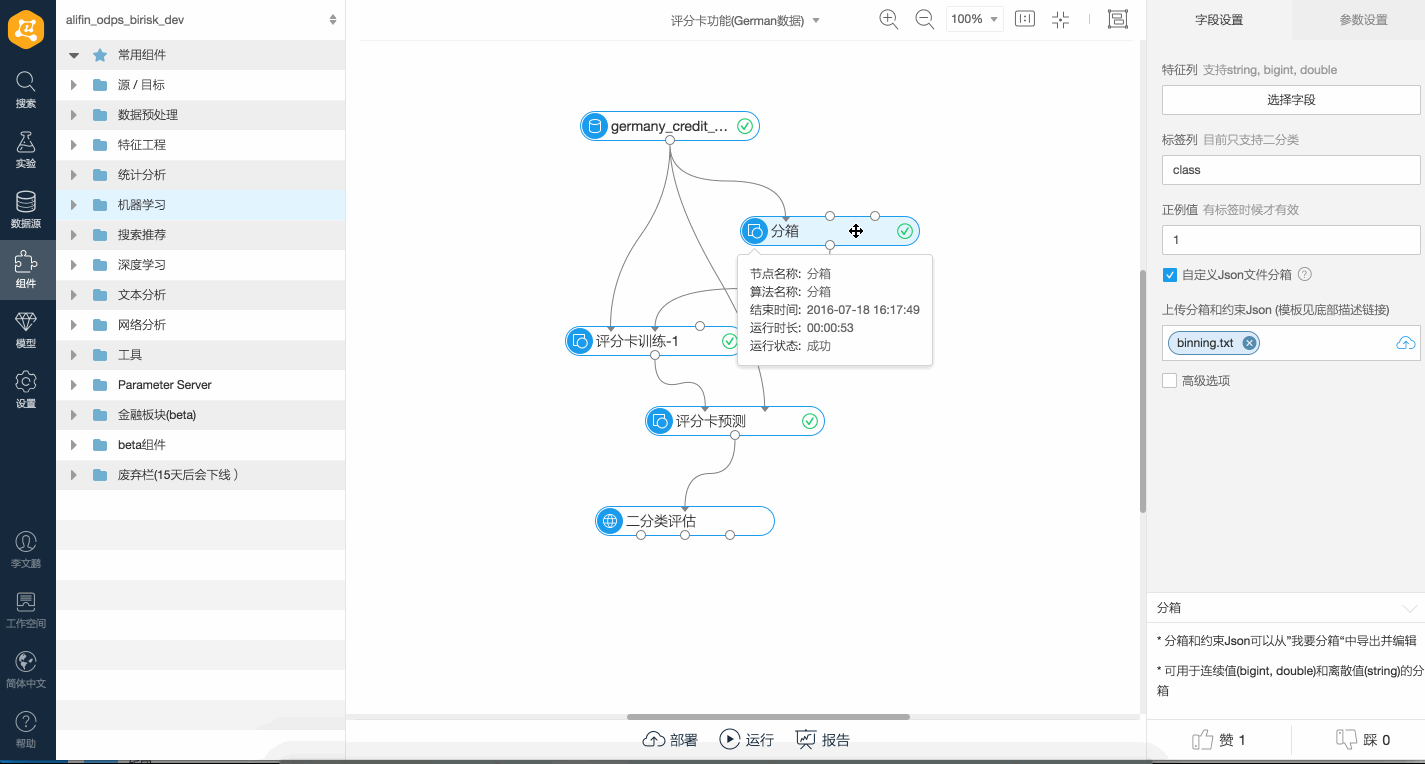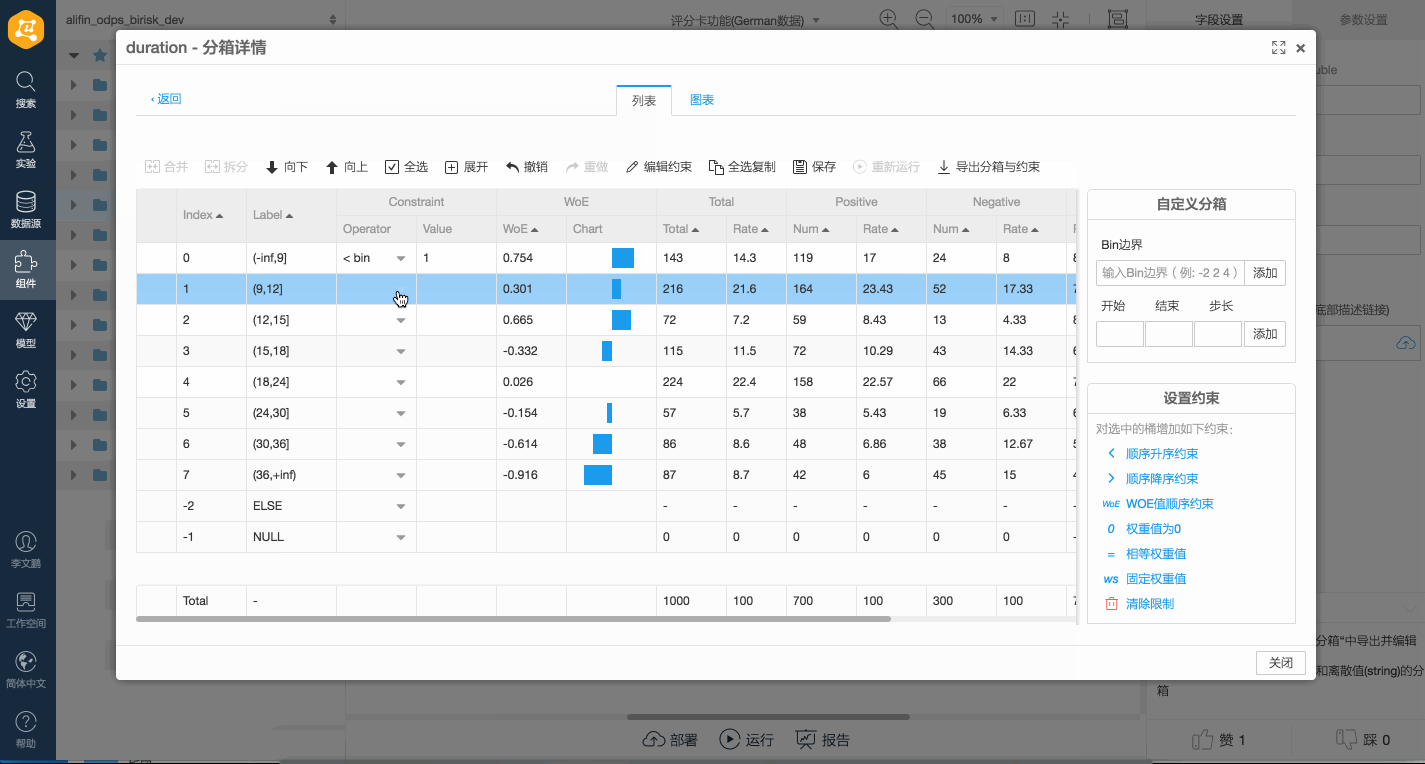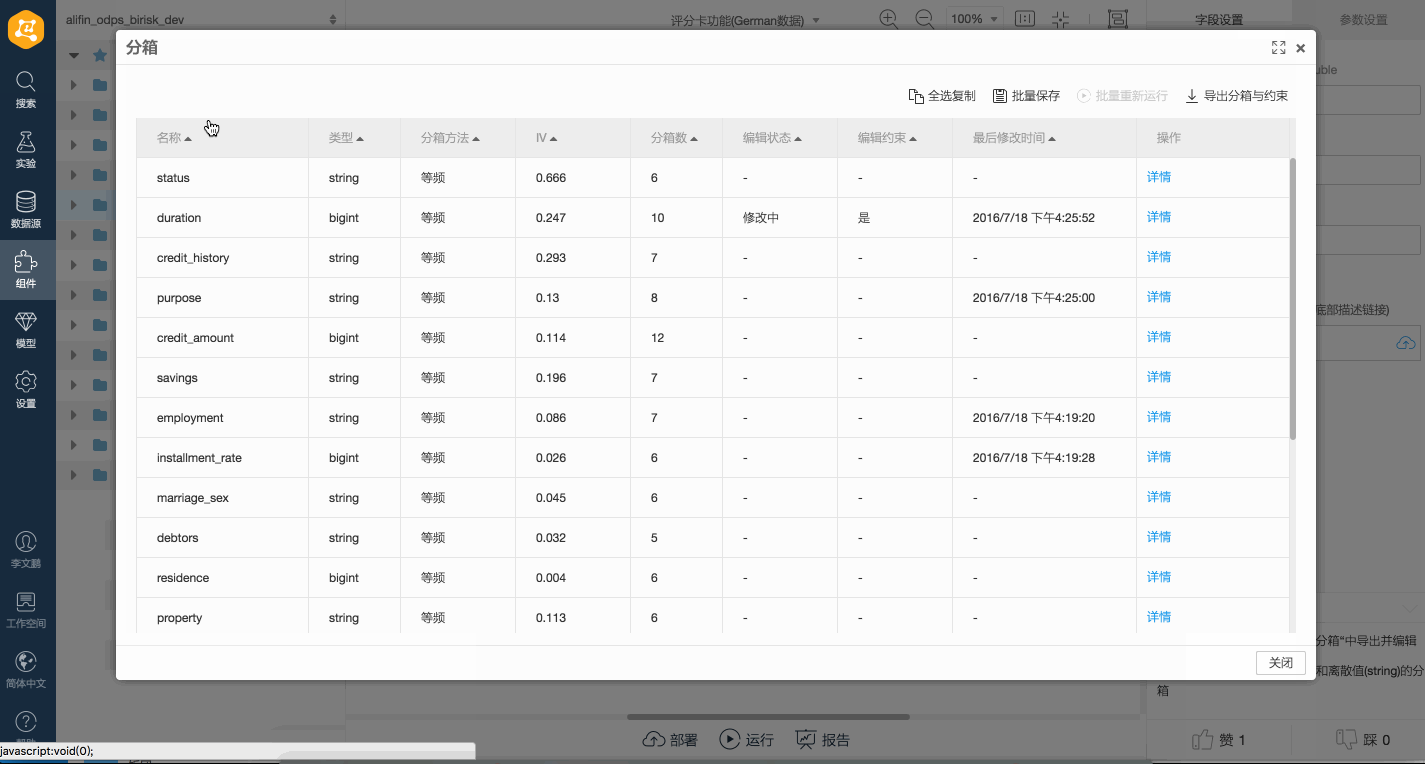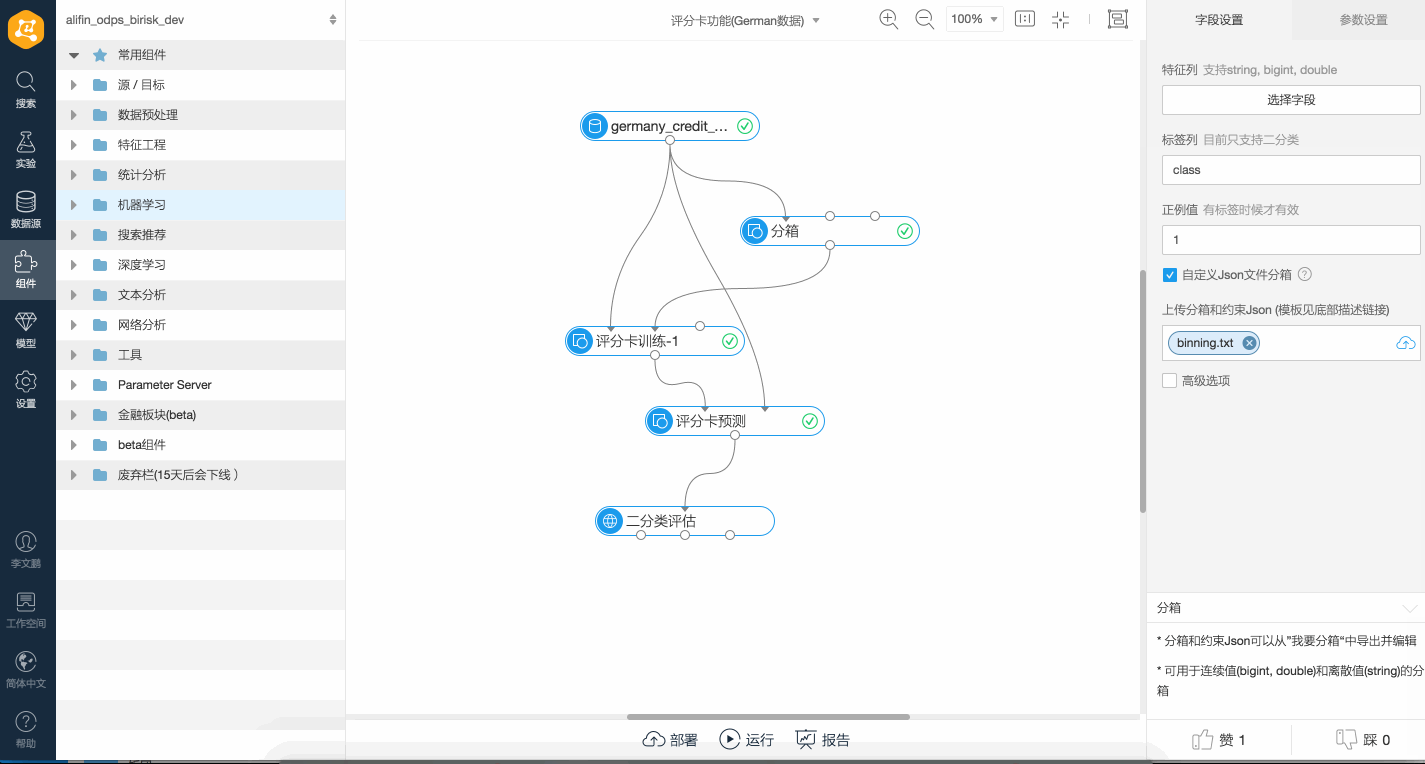 系統支持如下六種JSON約束:
系統支持如下六種JSON約束:“<”:變量權重按照順序滿足升序的約束。
“>”:變量權重按照順序滿足降序的約束。
“=”:變量權重等于固定值。
“%”:變量之間的權重符定一定的比例關系。
“UP”:變量的權重約束上限。例如,0.5表示訓練獲得的權重值不大于0.5。
“LO”:變量的權重約束下限。例如,0.5表示訓練獲得的權重值不小于0.5。
JSON約束以字符串的形式存儲在單行單列(字符串類型)的表中,存儲的JSON字符串示例如下。
{ "name": "feature0", "<": [ [0,1,2,3] ], ">": [ [4,5,6] ], "=": [ "3:0","4:0.25" ], "%": [ ["6:1.0","7:1.0"] ] }內置約束
每個原始變量都有一個隱含約束,無需用戶指定,即單個變量人群的分數平均值為0。通過該約束,模型截距項的scaled_weight即為整個人群的平均分。
優化算法
在高級選項中可以配置訓練過程中使用的優化算法,系統支持如下四種優化算法:
L-BFGS:是一階的優化算法,支持較大規模的特征數據集。該算法屬于無約束的優化算法,會自動忽略約束條件。
Newton's Method:牛頓法是經典的二階算法,收斂速度快,準確度高。但是由于需要計算二階Hessian Matrix,因此不適用于較大特征規模。該算法屬于無約束的優化算法,會自動忽略約束條件。
Barrier Method:二階的優化算法,在沒有約束條件的情況下完全等價于牛頓法。該算法的計算性能和準確性與SQP差別不大,通常建議選擇SQP。
SQP
二階的優化算法,在沒有約束條件的情況下完全等價于牛頓法。該算法的計算性能和準確性與Barrier Method差別不大,通常建議選擇SQP。
說明L-BFGS和Newton's Method均屬于無約束的優化算法,Barrier Method和SQP屬于帶約束的優化算法。
如果不了解優化算法,建議將優化算法配置為”自動選擇“,系統會自動根據用戶任務的數據規模和約束情況選擇最合適的優化算法。
特征選擇
訓練模塊支持Stepwise特征選擇功能。Stepwise是一種前向選擇和后向選擇的融合,即每次進行前向特征選擇將一個新變量加入模型后,需要對已經進入模型的變量進行一次后向選擇,以移除顯著性不滿足需求的變量。由于同時支持多種目標函數和多種特征變換方法,因此Stepwise特征選擇過程支持如下多種選擇標準:
邊緣貢獻(Marginal Contribution):適用于所有目標函數和特征工程方法。
模型A中不包含變量X,模型B包含所有A的變量,且包含變量X。兩個訓練模型最終收斂時所對應目標函數的差值,即為變量X在模型B中所有變量之間的邊緣貢獻度。在特征工程為Dummy變換的場景中,原始變量的X邊緣貢獻度定義為兩個模型分別包含和不包含該變量的所有Dummy變量的目標函數之差。因此,使用邊緣貢獻度進行特征選擇支持所有的特征工程方法。
該方法的優點是比較靈活,不局限于某一種模型,直接選擇使得目標函數更優的變量進入模型。缺點是邊緣貢獻度不同于統計顯著性,統計顯著性通常選擇0.05為閾值,而邊緣貢獻度新用戶沒有一個絕對的概念閾值,建議將其設置為10E-5。
評分檢驗(Score Test):僅支持WOE轉換或無特征工程的邏輯回歸選擇。
前向選擇過程中,首先訓練一個僅有截距項的模型,在之后的每一步迭代中,分別對未進入模型的變量計算其評分卡方統計量(Score Chi-Square),然后將評分卡方統計量最大的變量選入模型。同時,根據卡方分布計算該統計量所對應的顯著性P Value。如果評分卡方統計量最大的變量其P Value大于用戶指定的進入模型的最大顯著性閾值(slentry),則不會將該變量納入模型,并停止選擇過程。
完成一輪前向選擇后,將對已經選中進入模型的變量進行一輪后向選擇。后向選擇過程中,對于已經進入模型中的變量分別計算其對應的沃爾德卡方統計量(Wald Chi-Square),并計算其對應的顯著性P Value。如果P Value大于用戶指定的移除模型的最大顯著性閾值(slstay),則從模型中移除該變量,并繼續進行下一輪迭代選擇。
F檢驗(F Test):僅支持WOE轉換或無特征工程的線性回歸選擇。
前向選擇過程中,首先訓練一個僅有截距項的變量,在之后的每一步迭代中,分別對未進入模型的變量計算其F Value。F Value的計算與邊緣貢獻度的計算類似,需要訓練兩個模型以計算一個變量的F Value。F Value符合F分布,可以根據其F分布的概率密度函數求得其對應的顯著性P Value。如果P Value大于用戶指定的進入模型的最大顯著性閾值(slentry),則不會將變量納入模型,并停止選擇過程。
后向選擇過程也是使用F Value計算顯著性,其過程與評分檢驗類似。
強制選擇加入模型的變量
進行特征選擇之前,可以設置強制進入模型的變量,被選中的變量不參與前向和后向的特征選擇過程。無論選中的變量其顯著性取值如何,都會直接進入模型。您可以在命令行中通過-Dselected參數指定迭代次數和顯著性閾值,格式為JSON,示例如下。
{"max_step":2, "slentry": 0.0001, "slstay": 0.0001}如果-Dselected參數為空或max_step為0,則表示正常的訓練流程,不進行特征選擇。
組件配置
Designer支持通過可視化(詳見評分卡訓練示例)或PAI命令的方式配置評分卡訓練組件的參數,使用PAI命令的方式如下。
pai -name=linear_model -project=algo_public
-DinputTableName=input_data_table
-DinputBinTableName=input_bin_table
-DinputConstraintTableName=input_constraint_table
-DoutputTableName=output_model_table
-DlabelColName=label
-DfeatureColNames=feaname1,feaname2
-Doptimization=barrier_method
-Dloss=logistic_regression
-Dlifecycle=8參數 | 描述 | 是否必選 | 默認值 |
inputTableName | 輸入特征數據表。 | 是 | 無 |
inputTablePartitions | 輸入特征表選擇的分區。 | 否 | 全表 |
inputBinTableName | 輸入分箱結果表。如果該表指定,則先自動根據該表的分箱規則對原始特征進行離散化,再進行訓練。 | 否 | 無 |
featureColNames | 輸入表選擇的特征列。 | 否 | 選擇全部,自動排除Label列。 |
labelColName | 目標列。 | 是 | 無 |
outputTableName | 輸出模型表。 | 是 | 無 |
inputConstraintTableName | 輸入的JSON格式約束條件,存儲在表的一個單元中。 | 否 | 無 |
optimization | 優化類型,支持的類型包括:
僅sqp和barrier_method支持約束,auto即為根據用戶數據和相關參數自動選擇合適的優化算法。如果您對優化算法不太了解,建議使用auto。 | 否 | auto |
loss | Loss類型,支持logistic_regression和least_square類型。 | 否 | logistic_regression |
iterations | 優化的最大迭代次數。 | 否 | 100 |
l1Weight | L1正則的參數權重,僅lbfgs優化算法支持L1 Weight。 | 否 | 0 |
l2Weight | L2正則的參數權重。 | 否 | 0 |
m | lbfgs優化過程中的歷史長度,僅對lbfgs優化算法有效。 | 否 | 10 |
scale | 評分卡對Weight進行Scale的信息。 | 否 | 空 |
selected | 評分卡特征選擇功能。 | 否 | 空 |
convergenceTolerance | 收斂條件。 | 否 | 1e-6 |
positiveLabel | 正樣本的分類。 | 否 | 1 |
lifecycle | 輸出表的生命周期。 | 否 | 無 |
coreNum | 核心數。 | 否 | 系統自動計算 |
memSizePerCore | 內存數,單位為MB。 | 否 | 系統自動計算 |
組件輸出
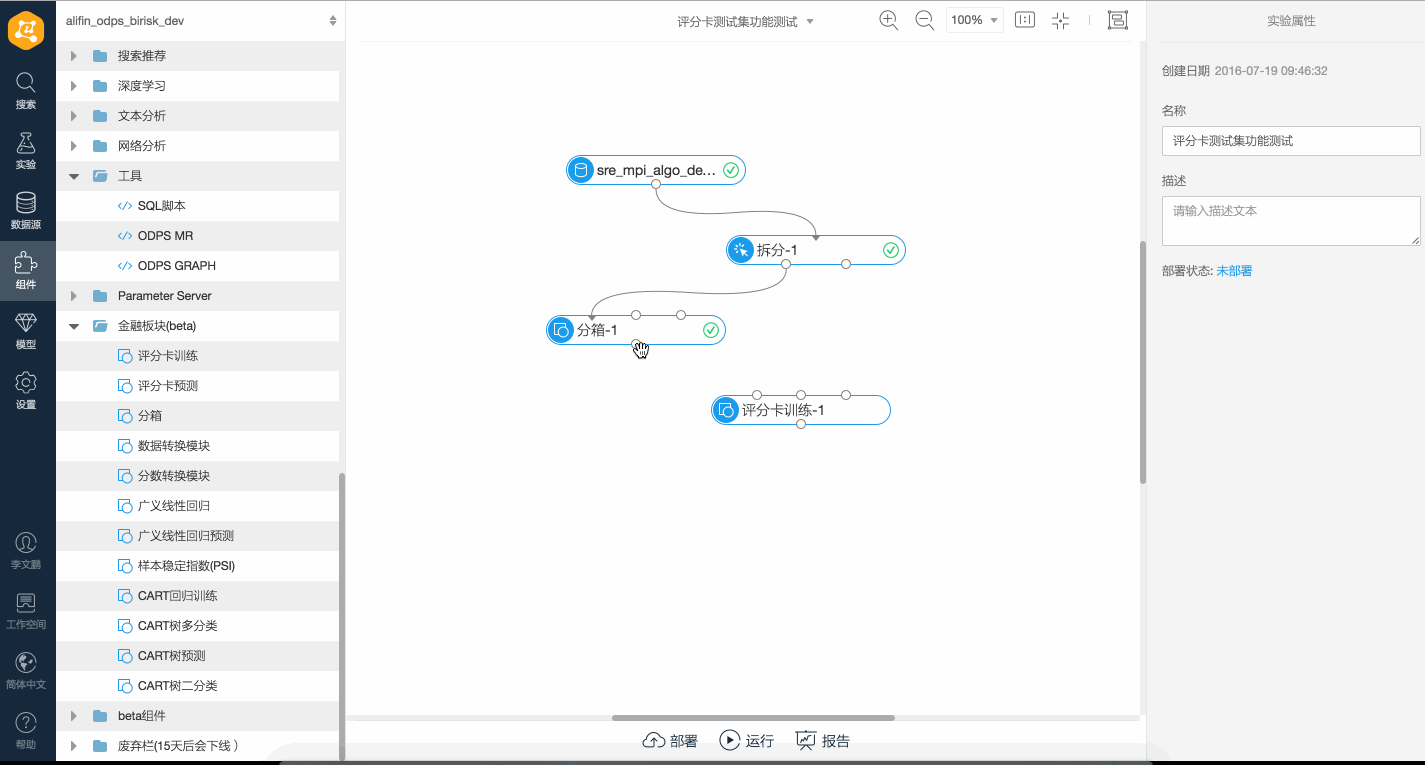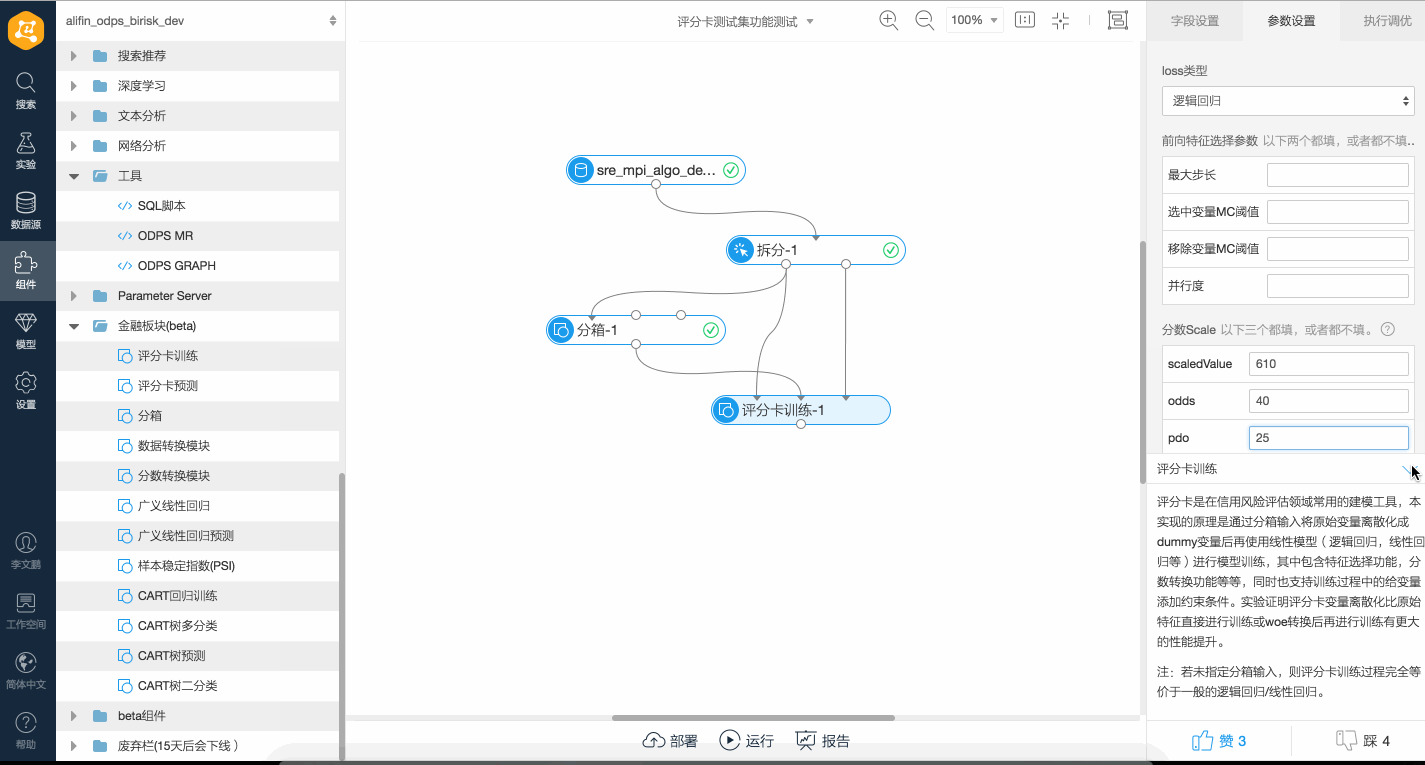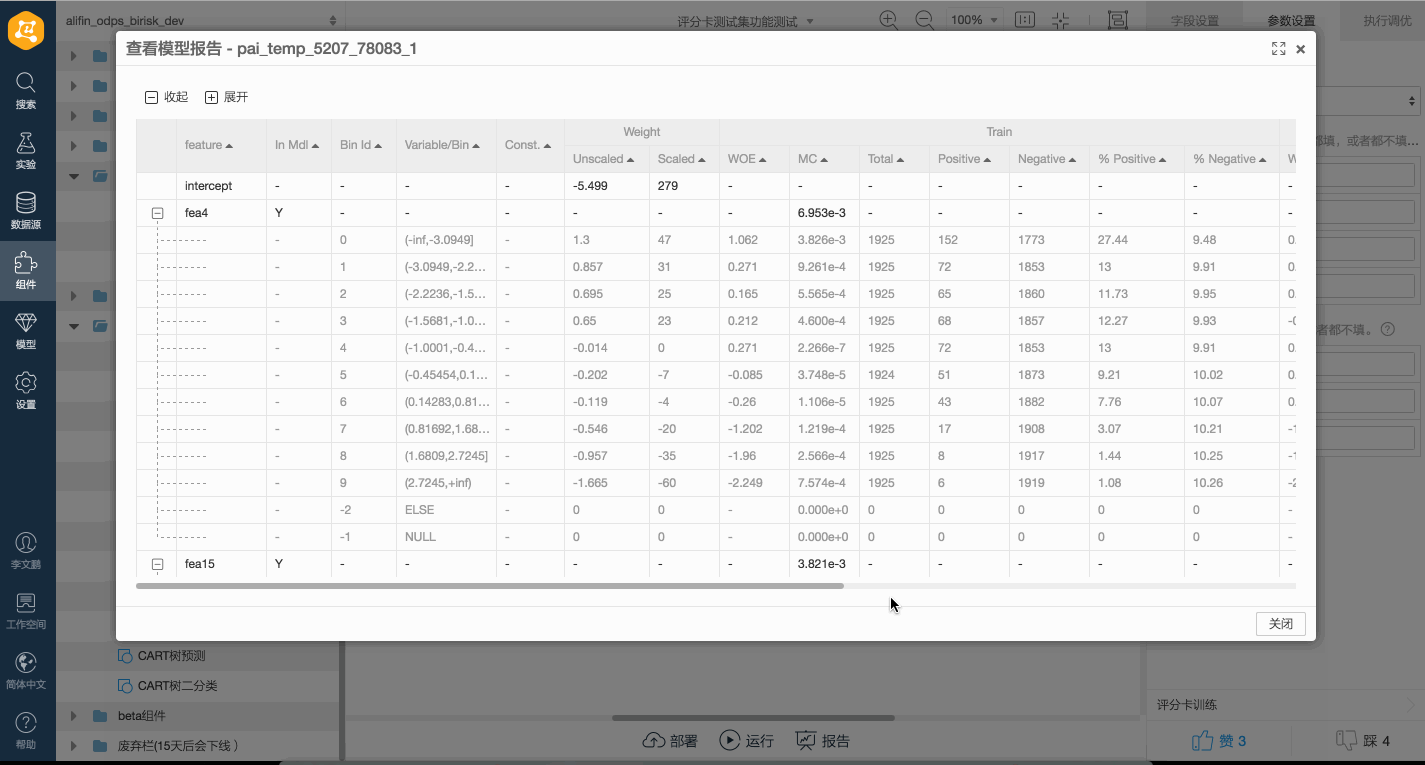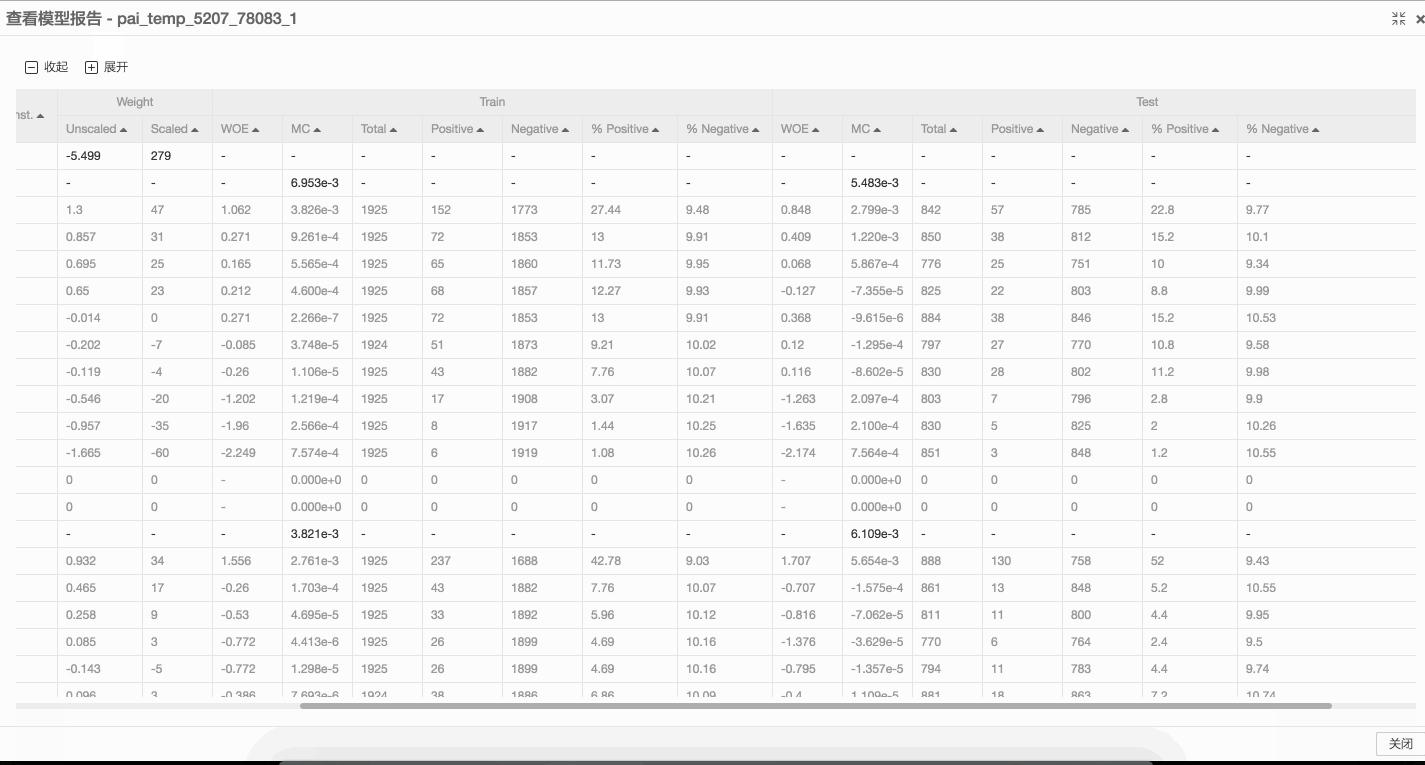
評分卡模型的輸出為一個Model Report,其中包含了變量的分箱信息、分箱的約束信息、WOE及Marginal Contribution等基本的統計指標。PAI Web端展示的評分卡模型評估報告的相關列描述如下所示。
列名 | 列類型 | 描述 |
feaname | STRING | 特征名稱。 |
binid | BIGINT | 分箱ID。 |
bin | STRING | 分箱描述,用于表明該分箱的值域。 |
constraint | STRING | 訓練時增加到該分箱的約束條件。 |
weight | DOUBLE | 訓練完成后所對應的分箱變量權重,或未指定分箱輸入的非評分卡模型,該項直接對應模型變量權重。 |
scaled_weight | DOUBLE | 評分卡模型訓練過程中指定分數轉換信息后,將分箱變量權重經過線性變換得到的分數值。 |
woe | DOUBLE | 統計指標:訓練集上該分箱的WOE值。 |
contribution | DOUBLE | 統計指標:訓練集上該分箱的Marginal Contribution值。 |
total | BIGINT | 統計指標:訓練集上該分箱的總樣本數。 |
positive | BIGINT | 統計指標:訓練集上該分箱的正樣本數。 |
negative | BIGINT | 統計指標:訓練集上該分箱的負樣本數。 |
percentage_pos | DOUBLE | 統計指標:訓練集上該分箱的正樣本數占總正樣本的比例。 |
percentage_neg | DOUBLE | 統計指標:訓練集上該分箱的負樣本數占總負樣本的比例。 |
test_woe | DOUBLE | 統計指標:測試集上該分箱的WOE值。 |
test_contribution | DOUBLE | 統計指標:測試集上該分箱的Marginal Contribution值。 |
test_total | BIGINT | 統計指標:測試集上該分箱的總樣本數。 |
test_positive | BIGINT | 統計指標:測試集上該分箱的正樣本數。 |
test_negative | BIGINT | 統計指標:測試集上該分箱的負樣本數。 |
test_percentage_pos | DOUBLE | 統計指標:測試集上該分箱的正樣本數占總正樣本的比例。 |
test_percentage_neg | DOUBLE | 統計指標:測試集上該分箱的負樣本數占總負樣本的比例。 |
示例
推薦使用Designer提交評分卡訓練任務,如下是一個簡單的評分卡Stepwise特征選擇、特征WOE變換及邏輯回歸Stepwise特征選擇的對比演示。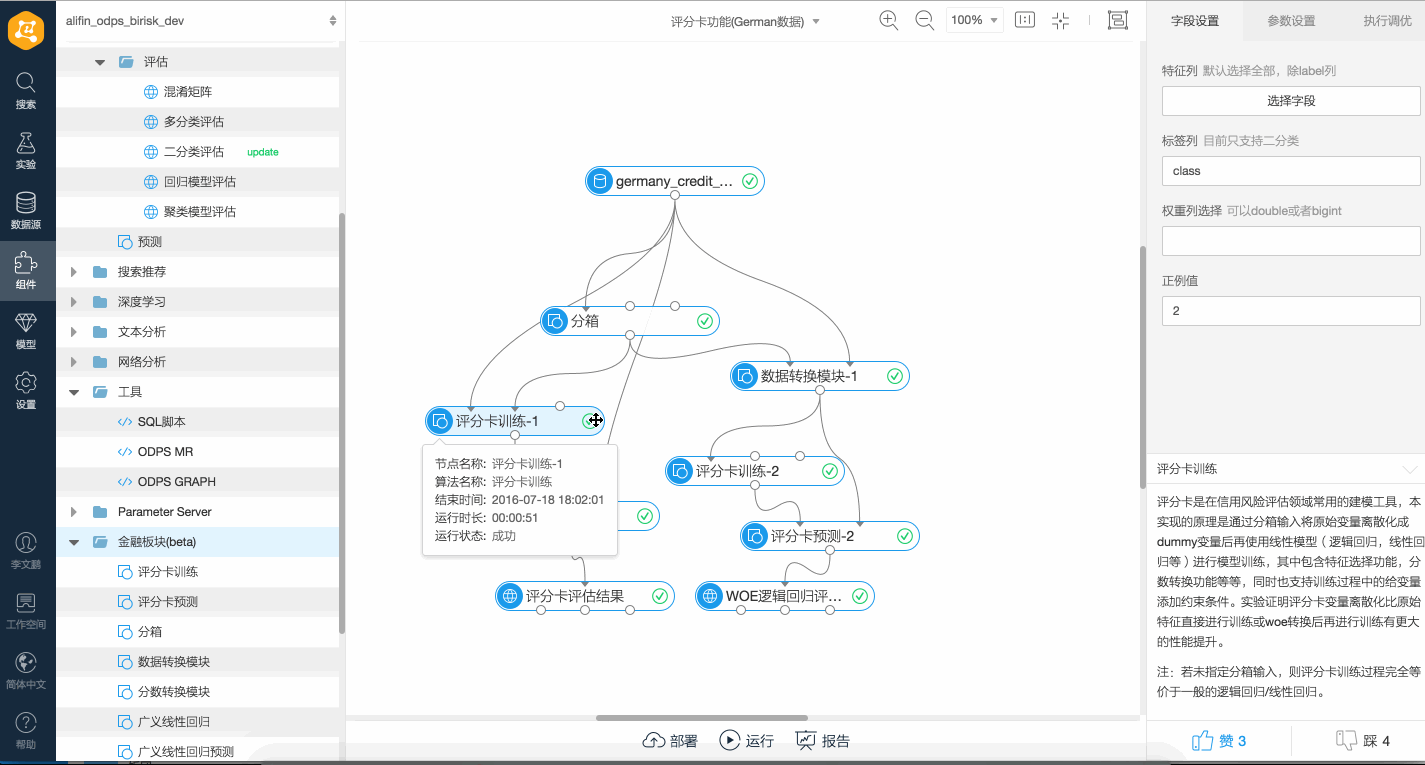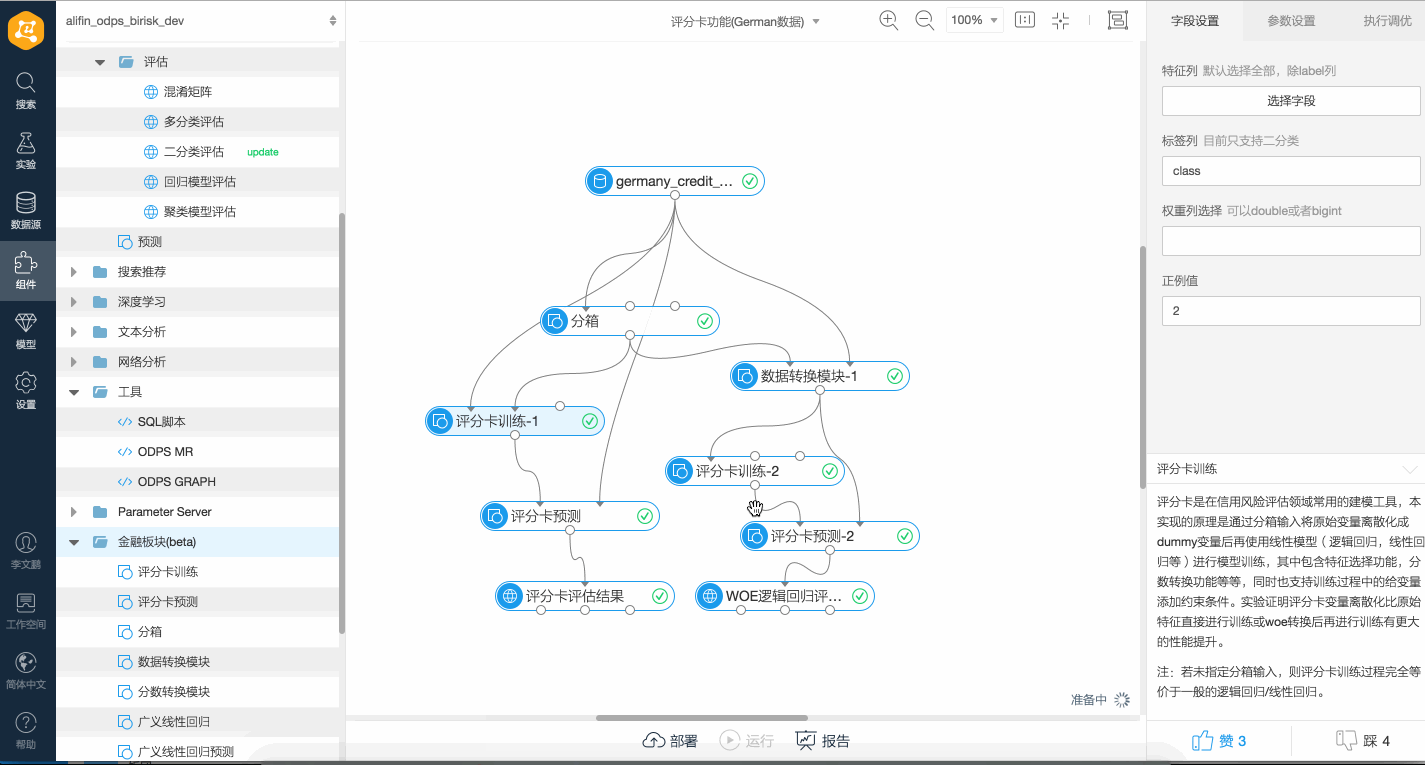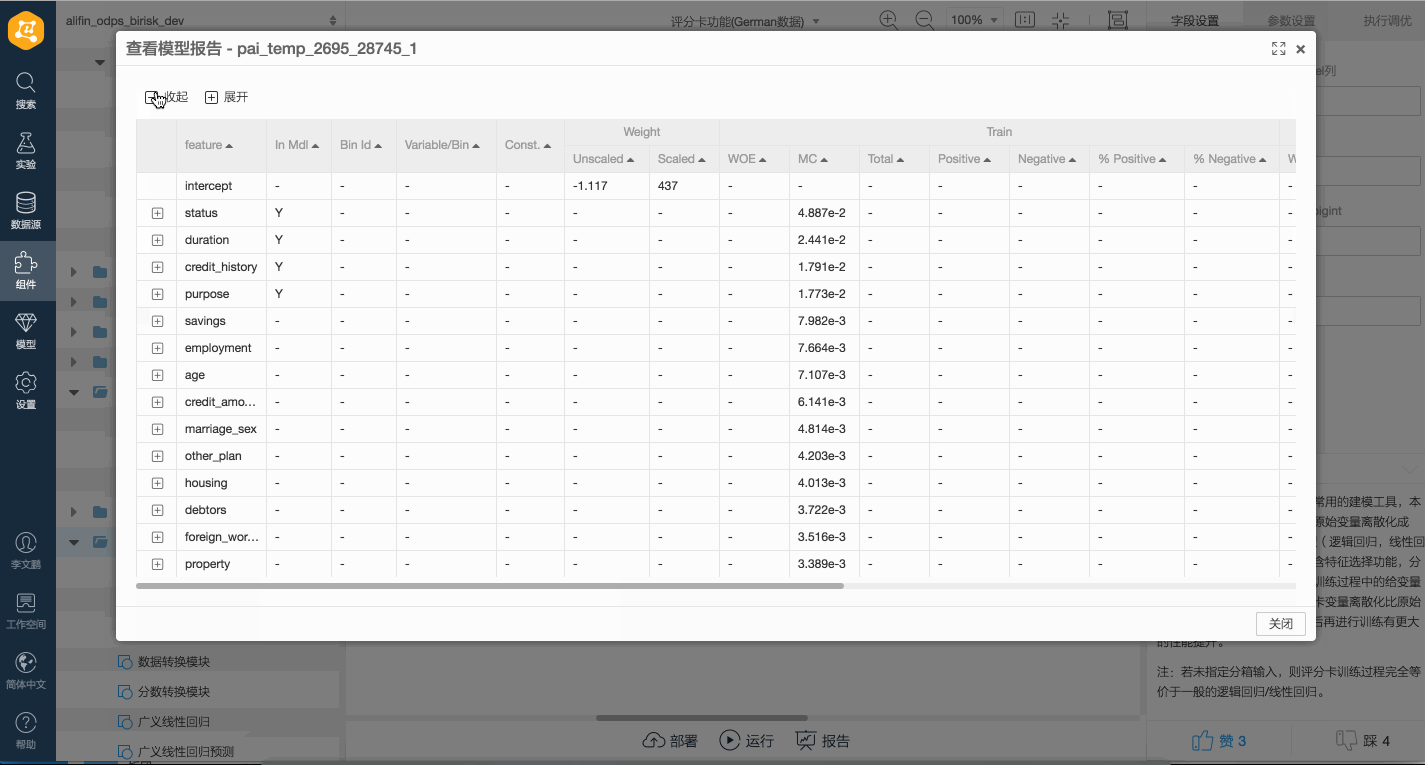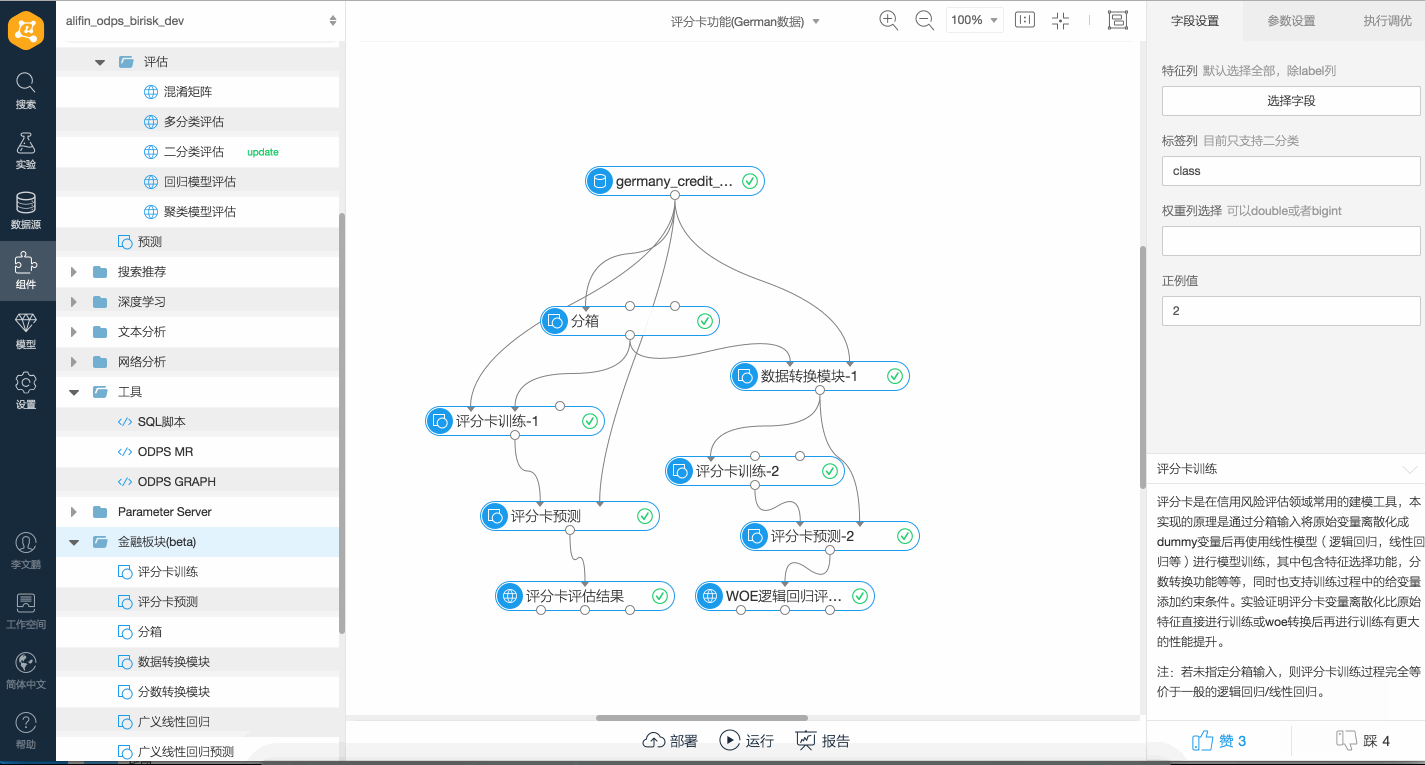 如下是一個簡單的評分卡訓練、特征WOE變換及邏輯回歸的對比演示。
如下是一個簡單的評分卡訓練、特征WOE變換及邏輯回歸的對比演示。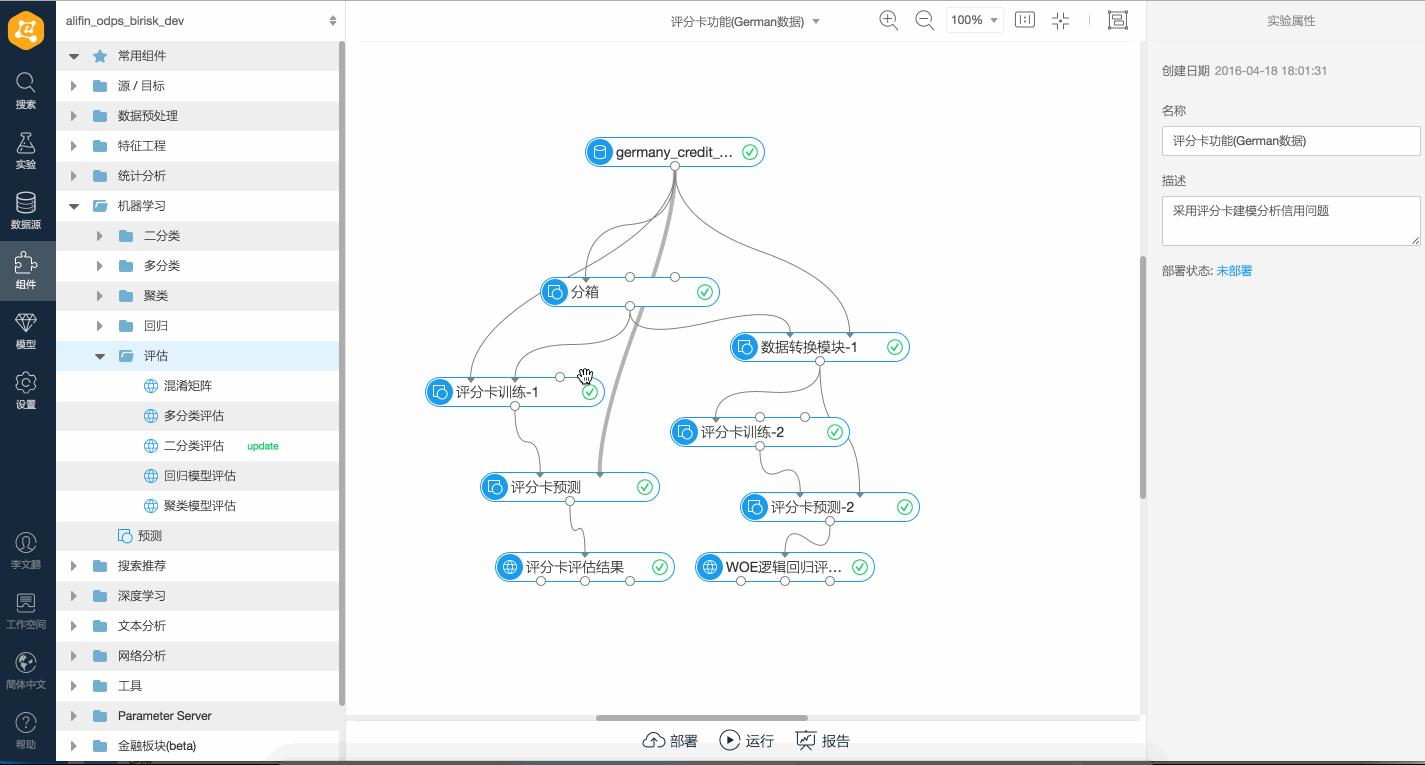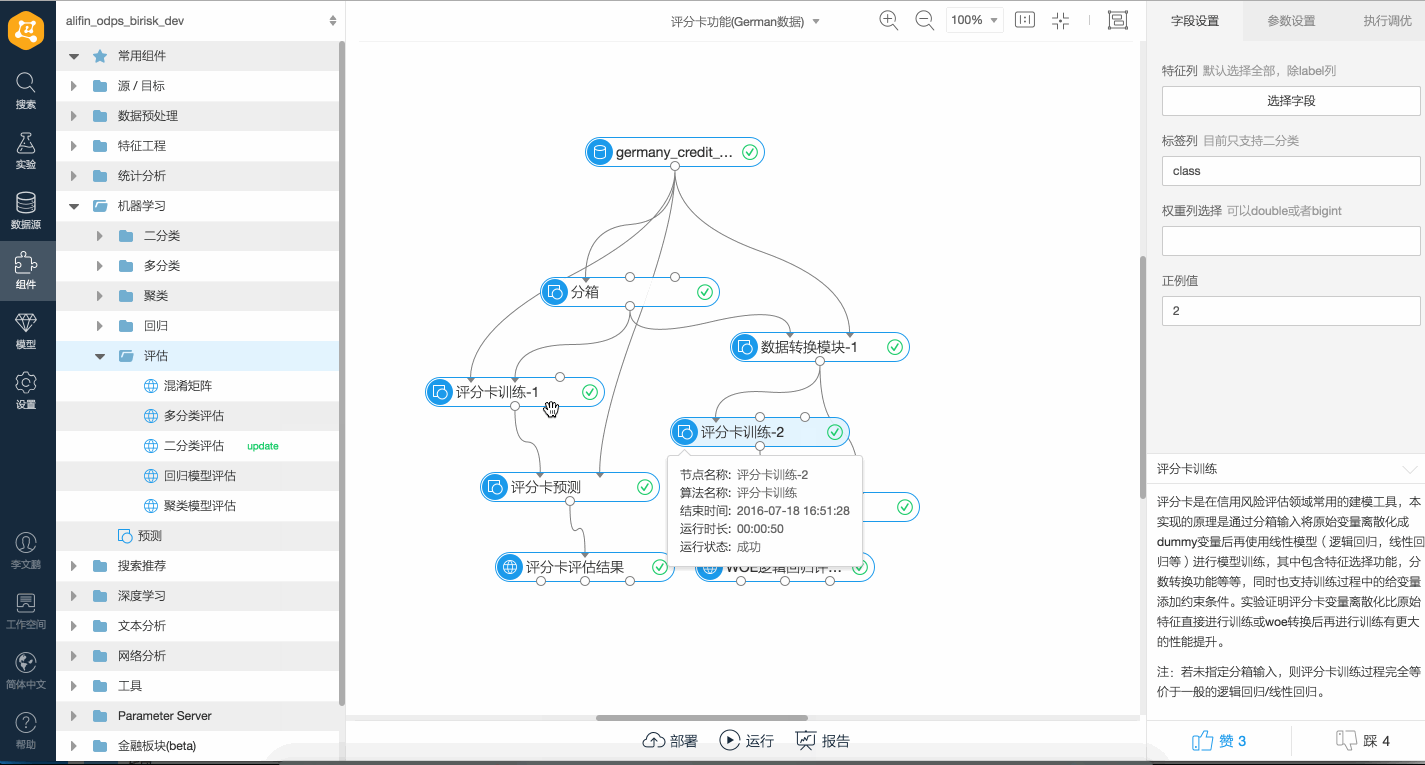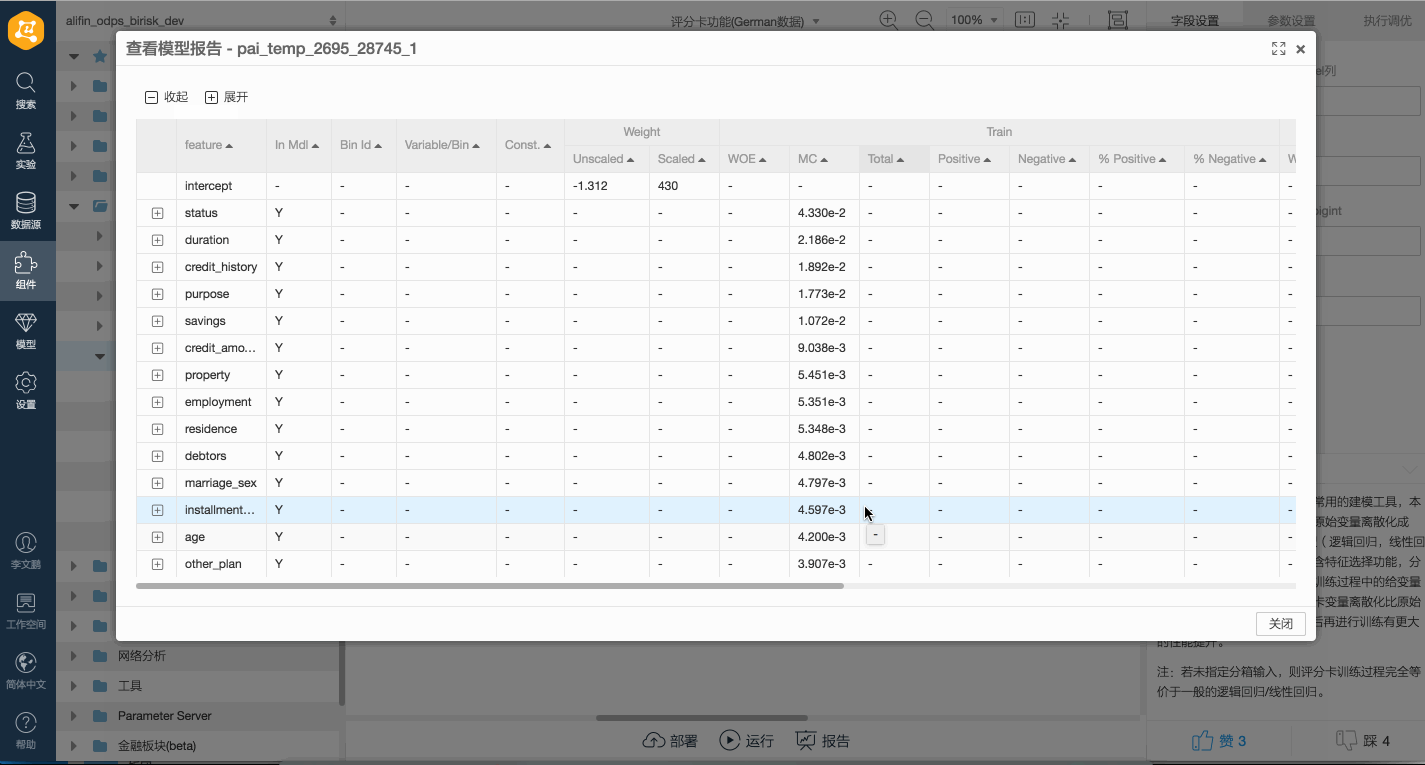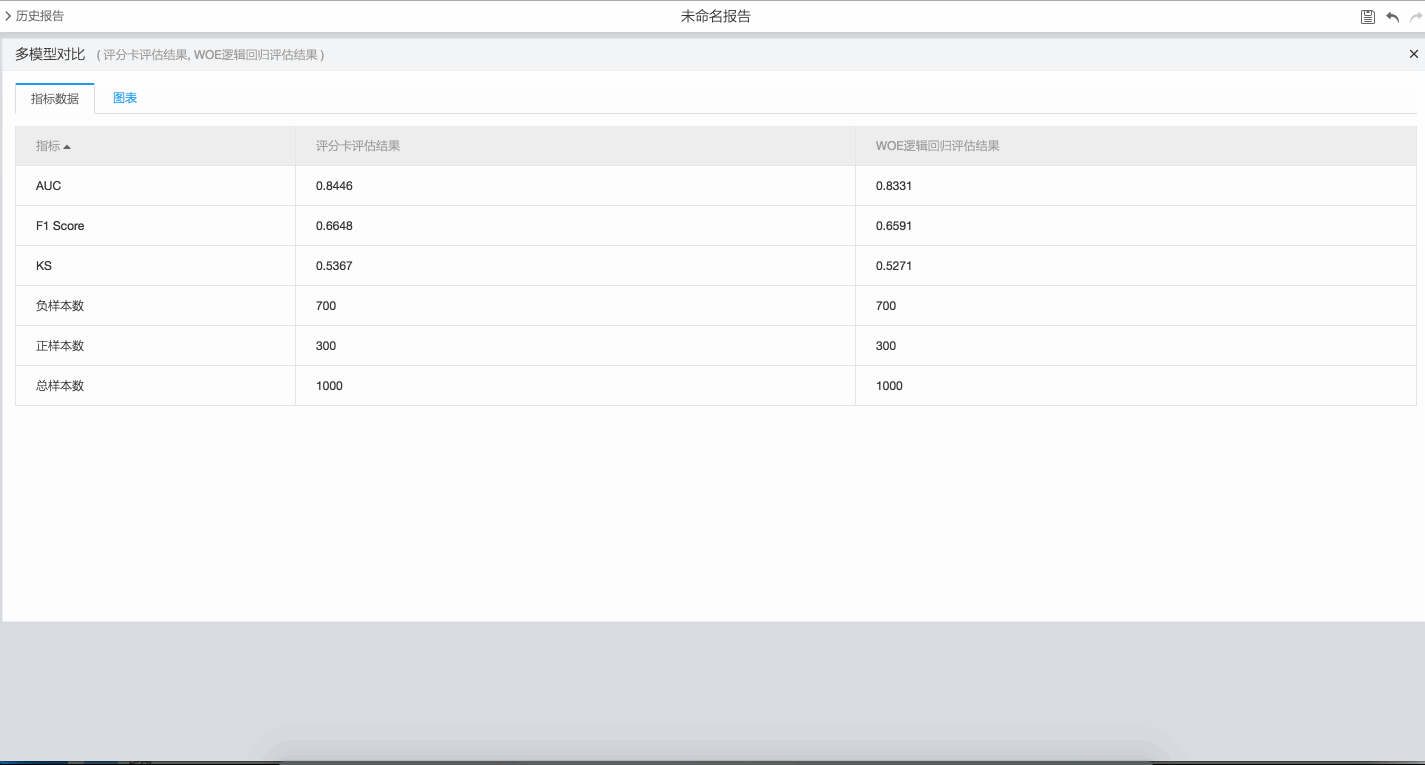 如果輸入訓練組件中連接測試集,則輸出的模型報告中會同時輸出模型在測試集上的統計指標,例如WOE及MC等。如下是一個簡單的帶測試集的訓練演示。
如果輸入訓練組件中連接測試集,則輸出的模型報告中會同時輸出模型在測試集上的統計指標,例如WOE及MC等。如下是一個簡單的帶測試集的訓練演示。