本文介紹IMCI背后的技術路線和具體方案。
背景信息
PolarDB MySQL版是因云而生的一個數據庫系統。除云上OLTP場景外,大量客戶也對PolarDB提出了實時數據分析的性能需求。對此,PolarDB技術團隊提出了In-Memory Column Index(IMCI)的技術方案,此方案在復雜分析查詢場景獲得了數百倍的加速效果。
MySQL生態HTAP數據庫解決方案
MySQL是一款主要面向OLTP場景設計的開源數據庫。開源社區的研發方向側重于加強其事務處理的能力,例如:提升單核性能、多核擴展性能、增強集群能力以提升可用性等。在處理大數據量下復雜查詢所需要的能力方面,如優化器處理子查詢的能力、高性能算子HashJoin、SQL并行執行等。社區將其處于低優先級,因此MySQL的數據分析能力提升進展緩慢。
隨著MySQL的發展,用戶使用其存儲了大量的數據,并且運行著關鍵的業務邏輯。對這些數據進行實時分析成為一個日益增長的需求。當單機MySQL不能滿足需求時,用戶尋求一個更好的解決方案。
MySQL+專用AP數據庫的搭積木方案
專用分析型數據庫產品眾多,一個可選方案為:使用兩套系統來分別滿足OLTP和OLAP型需求,在兩套系統中間通過數據同步工具進行數據實時同步。用戶甚至可以增加一層proxy,自動將TP型負載路由至MySQL數據庫,而將分析型負載路由至OLAP數據庫。
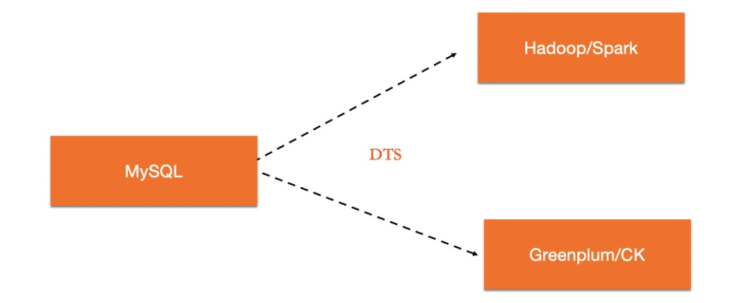 這樣的架構有其靈活之處。例如,對于TP數據庫和AP數據庫都可以各自選擇最好的方案,并且實現了TP/AP負載的完全隔離。但其缺點也是顯而易見的。首先,在技術上需要維護兩套不同技術體系的數據庫系統。其次,由于兩套系統處理機制的差異,維護上下游的數據實時一致性非常具有挑戰。而且由于數據同步存在延遲,下游AP系統存儲的經常是過時的數據,導致無法滿足用戶實時分析數據的需求。
這樣的架構有其靈活之處。例如,對于TP數據庫和AP數據庫都可以各自選擇最好的方案,并且實現了TP/AP負載的完全隔離。但其缺點也是顯而易見的。首先,在技術上需要維護兩套不同技術體系的數據庫系統。其次,由于兩套系統處理機制的差異,維護上下游的數據實時一致性非常具有挑戰。而且由于數據同步存在延遲,下游AP系統存儲的經常是過時的數據,導致無法滿足用戶實時分析數據的需求。基于多副本的Divergent Design方法
隨著互聯網而興起的新型數據庫產品很多都兼容MySQL協議。因此,新型數據庫成為替代MySQL的一個可選項。而這些分布式數據庫產品大部分采用了分布式Share Nothing的方案。核心特點是使用分布式一致性協議來保障單個partition多副本之間的數據一致性。由于一份數據在多個副本之間完全獨立,因此在不同副本上使用不同格式進行存儲,來服務不同的查詢負載是一個易于實施的方案。例如,TiDB從TiDB4.0開始,在Raft Group的其中一個副本上使用列式存儲(TiFlash)來響應AP型負載,并通過TiDB的智能路由功能來自動選取數據來源。實現了一套數據庫系統同時服務OLTP型負載和OLAP型負載。該方法在諸多Research及Industry領域的工作中都被借鑒并使用,并日益成為分布式數據領域一體化HTAP的事實標準方案。但是應用這個方案的前提是用戶需要遷移到對應的NewSQL數據庫系統,而這會出現各種兼容性適配問題。
一體化的行列混合存儲方案
較多副本Divergent Design方法更進一步的方案,是在同一個數據庫實例中采用行列混合存儲,同時響應TP型和AP型負載。這是傳統商用數據庫Oracle、SQL Server或DB2等不約而同采用的方案。
Oracle公司在2013年發表的Oracle 12C上,發布了Database In-Memory套件。其最核心的功能即為In-Memory Column Store,通過提供行列混合存儲、高級查詢優化(物化表達式,JoinGroup)等技術提升OLAP性能。
微軟在SQL Server 2016 SP1上,開始提供Column Store Index功能。用戶可以根據負載特征,靈活的使用純行存表、純列存表、行列混合表、列存表+行存索引等多種模式。
IBM在2013年發布的10.5版本(Kepler)中,增加了DB2 BLU Acceleration組件,通過列式數據存儲配合內存計算以及DataSkipping技術,大幅提升分析場景的性能。
三家領先的商用數據庫廠商,均同時采用了行列混合存儲結合內存計算的技術路線。列式存儲由于有更好的IO效率(壓縮,DataSkipping,列裁剪)以及CPU計算效率(Cache Friendly)。因此要達到最極致的分析性能必須使用列式存儲,而列式存儲中索引稀疏導致的索引精準度問題決定它不可能成為TP場景的存儲格式,如此行列混合存儲成為一個必選方案。但在行列混合存儲架構中,行存索引和列存索引在處理隨機更新時存在性能鴻溝,必須借助DRAM的低讀寫延時來彌補列式存儲更新效率低的問題。因此在低延時在線事務處理和高性能實時數據分析兩大前提下,行列混合存儲結合內存計算是唯一方案。
對比上述三種方案,從組合搭積木的方法,到Divergent Design方法,再到一體化的行列混合存儲。其集成度越來越高,用戶的使用體驗也越來越好。但是其對內核工程實現上的挑戰也越來越大。基礎軟件的作用就是將復雜留給自己,把簡單留給用戶。因此一體化的方法更符合技術發展趨勢。
PolarDB MySQL版 AP能力的演進
PolarDB MySQL版能力棧與開源MySQL類似,長于TP但AP能力較弱。由于PolarDB提供了單實例500 TB的存儲能力,同時其事務處理能力遠超用戶自建MySQL。因此PolarDB用戶傾向于在單實例存儲更多的數據,同時會在這些數據上運行一些復雜聚合查詢。借助于PolarDB一寫多讀的架構,用戶可以增加只讀的RO節點以運行復雜只讀查詢,從而避免分析型查詢對TP負載的干擾。
MySQL的架構在AP場景的缺陷
MySQL的實現架構在執行復雜查詢時,性能差存在諸多原因。對比專用的OLAP系統,其性能瓶頸體如下:
MySQL的SQL執行引擎基于流式迭代器模型(Volcano Iterator),而這個模型在工程實現上依賴大量深層次的函數嵌套及虛函數調用,當處理海量數據時,會影響CPU流水線的Pipeline效率,導致CPU Cache效率低下。同時Iterator執行模型也不能使用CPU提供的SIMD指令來做執行加速。
執行引擎只能串行執行,不能發揮多核CPU的并行執行能力。從MySQL 8.0開始,在一些count(*)等基本查詢上增加并行執行的能力,但是復雜SQL的并行執行能力構建依然任重道遠。
MySQL最常用的存儲引擎都是按行存儲。在按列進行海量數據分析時,按行從磁盤讀取數據存在非常大的IO帶寬浪費,其次,行式存儲格式在處理大量數據時會大量拷貝不必要的列數據,對內存讀寫效率也存在沖擊。
PolarDB 并行查詢突破CPU瓶頸
PolarDB團隊開發的并行查詢框架(Parallel Query),在查詢數據量到達一定閾值時,會自動啟動并行執行。在存儲層將數據分片至不同的線程,多個線程并行計算。并將結果流水線匯總到總線程。最后,總線程做些簡單歸并返回給用戶。
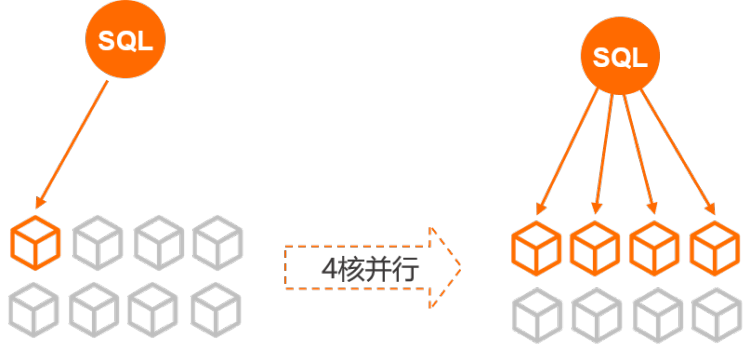 并行查詢的加入使得PolarDB突破了單核執行性能的限制,利用多核CPU的并行處理能力,PolarDB部分SQL查詢耗時成指數級下降。
并行查詢的加入使得PolarDB突破了單核執行性能的限制,利用多核CPU的并行處理能力,PolarDB部分SQL查詢耗時成指數級下降。Why We Need Column-Store
并行執行框架突破了CPU擴展能力的限制,帶來了顯著的性能提升。然而受限于行式存儲及行式執行器的效率限制,單核執行性能存在天花板,其峰值性能依然與專用的OLAP系統存在差距。更進一步的提升PolarDB MySQL版的分析性能,我們需要引入列式存儲:
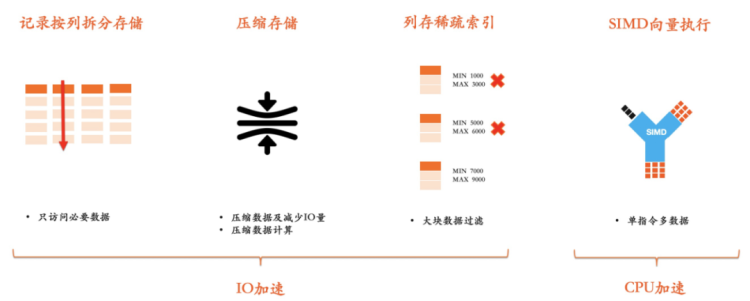
在分析場景,經常需要訪問某個列的大量記錄。而列存按列拆分存儲的方式會避免讀取不需要的列。其次,列存由于把相同屬性的列連續保存,其壓縮效率也遠超行存,通常可以達到10倍以上。最后,列存中的大塊存儲結構,結合MIN、MAX等粗糙索引信息可以實現大范圍的數據過濾。所有這些行為都極大的提升了IO的效率。在存儲計算分離架構下,減少網絡讀取的數據量,可以縮短對查詢處理的響應時間。
列式存儲同樣能提高CPU在處理數據時的執行效率。首先,列存的緊湊排列方式可提升CPU訪問內存效率,減少L1/L2 Cache miss導致的執行停頓。其次,在列式存儲上可以使用SIMD技術進一步提升單核吞吐能力,這也是現代高性能分析執行引擎的通用技術路線(Oracle/SQL Server/ClickHouse)。
PolarDB In-Memory Column Index
PolarDB In-Memory Column Index功能,為PolarDB帶來列式存儲以及內存計算能力。讓用戶可以在一套PolarDB數據庫上同時運行TP和AP型混合負載。在保證現有PolarDB優異的OLTP性能的同時,大幅提升PolarDB在大數據量上運行復雜查詢的性能。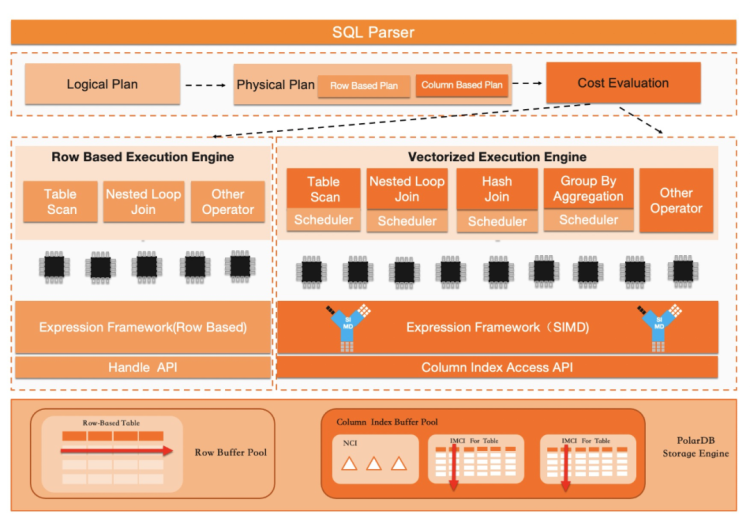 In-Memory Column Index使用行列混合存儲技術,同時結合了PolarDB共享存儲一寫多讀的架構。其包含如下幾個關鍵的技術創新點:
In-Memory Column Index使用行列混合存儲技術,同時結合了PolarDB共享存儲一寫多讀的架構。其包含如下幾個關鍵的技術創新點:
在PolarDB的存儲引擎(InnoDB)上,新增列式索引(Columnar Index)。用戶可以選擇通過DDL將一張表的全部列或者部分列創建為列索引,列索引采用列壓縮存儲,其存儲空間消耗會遠小于行存格式。默認列索引會全部常駐內存以實現最大化分析性能,當內存不夠時,也支持將其持久化至共享存儲。
PolarDB的SQL執行器層,重寫了一套面向列存的執行器引擎框架(Column-oriented)。該執行器框架充分利用列式存儲的優勢,例如,以一個4096行的Batch為單位訪問存儲層的數據,使用SIMD指令提升CPU單核處理數據的吞吐量,所有關鍵算子均支持并行執行。對比MySQL原有的行存執行器,性能有數量級的提升。
支持行列混合執行的優化器框架,該優化器框架會根據下發的SQL是否能在列索引上執行覆蓋查詢,并且其所依賴的函數及算子能被列式執行器所支持,來決定是否啟動列式執行。優化器會同時對行存執行計劃和列存執行計劃做代價估算,并選中代價較低的執行計劃。
用戶可以使用PolarDB集群中的一個RO節點作為分析型節點,在該RO節點上配置生成列存索引。復雜查詢運行在列存索引上并使用所有可用的CPU的計算能力,在獲得最大執行性能的同時,不影響該集群上TP型負載的可用內存和CPU資源。
關鍵技術的結合,使得PolarDB成為了一個真正的HTAP數據庫系統。其在大數據量上運行復雜查詢的性能可以與Oracle、SQL Server等業界商用數據庫系統處在同一水平。
In-Memory Column Index的技術架構
行列混合的優化器
PolarDB原生有一套面向行存的優化器組件。在引擎層增加列存功能后,此部分需要進行功能增強,優化器需要能夠判斷一個查詢應該被調度到行存執行還是列存執行。通過一套白名單機制和執行代價計算框架來完成此項任務。系統保證對支持的SQL進行加速,同時兼容運行不支持的SQL。
如何實現100%的MySQL兼容性?
通過一套白名單機制來實現兼容性目標。使用白名單機制基于以下兩點。
系統可用資源(主要是內存)限制。一般情況下,不會給所有的表都創建列索引,當一個查詢語句需要使用的列不在列存中存在時,其不能在列存上執行。
性能。完全重寫了一套面向列存的SQL執行引擎,包括其中所有的物理執行算子和表達式。其所覆蓋的場景較MySQL原生行存支持的范圍有欠缺。當下發的SQL中包含一些IMCI執行引擎不能支持的算子片段或者列類型時,需要能夠識別攔截并切換回行存執行。
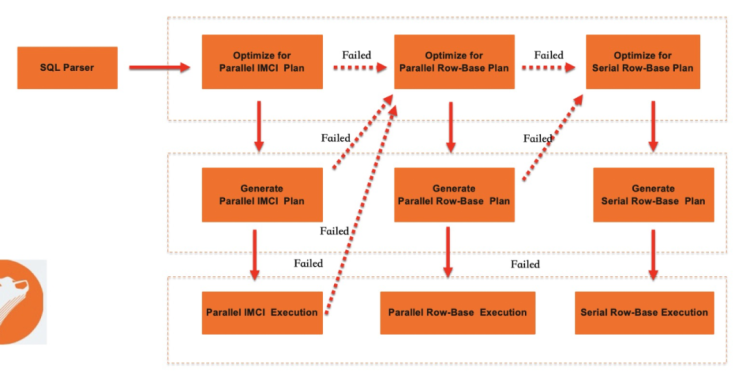
查詢計劃轉換
Plan轉換的目的,是將MySQL的原生邏輯執行計劃表示方式AST轉換為IMCI的Logical Plan。在生成IMCI的Logical Plan后,會經過Optimize過程,生成Physical Plan。Plan轉換的方法簡單,只需要遍歷執行計劃樹,將MySQL優化后的AST轉換成IMCI中以relation operator為節點的樹狀結構即可。在這個過程中,會做一部分額外的動作。例如,類型的隱式轉換。
兼顧行列混合執行的優化器
存在行存和列存兩套執行引擎,優化器在選擇執行計劃時有了更多的選擇。其可以對比行存執行計劃的Cost和列存執行計劃的Cost,并使用代價最低的執行計劃。在PolarDB中,除原生MySQL的行存串行執行外,還有能夠發揮多核計算能力的基于行存的Parallel Query功能。因此,優化器會在行存串行執行、行存Parallel Query和IMCI三個選項之中選擇。在目前的迭代階段,優化器按如下的流程執行:
執行SQL的Parse過程,并生成LogicalPlan,然后再調用MySQL原生優化器。同時該階段獲得的邏輯執行計劃轉給IMCI的執行計劃編譯模塊后,會嘗試生成一個列存的執行計劃(此處可能會被白名單攔截并fallback回行存)。
PolarDB的Optimizer會根據行存的Plan,計算得出一個面向行存的執行Cost。如果此Cost超過一定閾值,則會嘗試下推到IMCI執行器并使用IMCI_Plan執行。
如果IMCI無法執行此SQL,則PolarDB會嘗試編譯出一個Parallel Query的執行計劃并執行。如果無法生成PQ的執行計劃,則說明IMCI和PQ均無法支持此SQL,fallback回行存執行。
上述策略從執行性能比較,IMCI優于行存并行執行,行存并行執行優于行存串行執行。從SQL兼容性比較,行存串行執行優于行存并行執行,行存并行執行優于IMCI。但實際情況可能會更復雜,例如,某些情況下,基于行存有序索引覆蓋的并行Index Join會比基于列存的Sort Merge join有更低的Cost。目前的策略下,可能選擇IMCI列存執行。
面向列式存儲的執行引擎
IMCI執行引擎面向列存優化,并完全獨立于現有MySQL行式執行器。重寫執行器的目的是消除現有行存執行引擎在執行分析型SQL時導致效率低下的兩個關鍵瓶頸點,按行訪問導致的虛函數訪問開銷以及無法并行執行。
支持BATCH并行的算子
IMCI執行器引擎使用經典的火山模型,同時借用了列存存儲以及向量執行來提升執行性能。
火山模型中,SQL生成的語法樹所對應的關系代數中,每一種操作會抽象為一個Operator,執行引擎會將整個SQL構建為一個Operator 樹。查詢樹時,自頂向下調用Next()接口,數據則自底向上被拉取處理。該方法的優點為:計算模型簡單直接,通過把不同物理算子抽象為迭代器。每一個算子只關注其內部邏輯,各個算子之間的耦合性降低,從而比較容易寫出一個邏輯正確的執行引擎。
IMCI執行引擎中,每個Operator使用迭代器函數來訪問數據。不同的是,每次調用迭代器時會返回一批數據,而不是一行。可以認為是一個支持batch處理的火山模型。
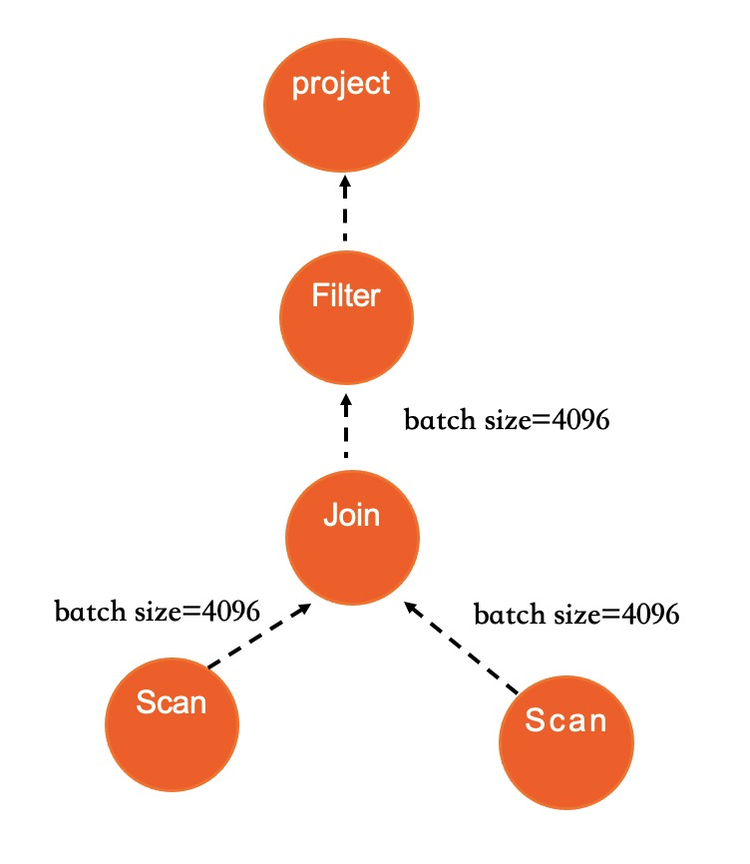
串行執行受限于單核計算效率、訪存延時和IO延遲等。而IMCI執行器在幾個關鍵物理算子(Scan/Join/Agg等)上均支持并行執行。除物理算子需要支持并行外,IMCI的優化器需要生成并行執行計劃。優化器在確定一個表的訪問方式時,會根據需要訪問的數據量來決定是否啟用并行執行。如果確定啟用并行執行,則會參考一系列狀態數據決定并行度,包括當前系統可用的CPU、Memory、IO資源、目前已經調度和在排隊的任務信息、統計信息、query 的復雜程度以及用戶可配置的參數等。根據這些數據計算出一個推薦的DOP值給算子, 而算子內部會使用相同的DOP。同時DOP也支持用戶使用Hint的方式自行設定。
 向量化執行解決了單核執行效率低的問題,而并行執行突破了單核的計算瓶頸。二者結合使用使得IMCI執行速度相比傳統MySQL行式執行有了數量級的提升。
向量化執行解決了單核執行效率低的問題,而并行執行突破了單核的計算瓶頸。二者結合使用使得IMCI執行速度相比傳統MySQL行式執行有了數量級的提升。
SIMD向量化計算加速
AP型場景,SQL中經常會包含很多涉及到一個或者多個值、運算符、函數組成的計算過程,都屬于表達式計算的范疇。表達式的求值是一個計算密集型的任務。因此,表達式的計算效率是影響整體性能的一個關鍵因素。
傳統MySQL表達式計算體系,是以一行為單位的逐行運算,一般稱其為迭代器模型實現。由于迭代器對整張表進行了抽象,整個表達式實現為一個樹形結構,其實現代碼易于理解,整個處理過程非常清晰。
這種抽象同時會帶來性能上的損耗。在迭代器進行迭代的過程中,每獲取一行數據都會引發多層的函數調用。同時逐行地獲取數據會帶來過多的 I/O,對緩存也不友好。MySQL采用樹形迭代器模型,其受限于存儲引擎訪問方法,導致其很難對復雜的邏輯計算進行優化。
在列存格式下,由于每一列的數據都單獨順序存儲,涉及到某一個特定列上的表達式計算過程都可以批量進行。對每一個計算表達式,其輸入和輸出都以Batch為單位,在Batch處理模式下,計算過程可以使用SIMD指令進行加速。即表達式系統有兩項關鍵優化:
充分利用列式存儲的優勢,使用分批處理模型代替迭代器模型,使用SIMD指令重寫大部分常用數據類型的表達式。例如,所有數字類型(int、decimal、double)的基本數學運算(+-*/abs),全部使用對應的SIMD指令。在AVX512指令集的加持下,單核運算性能獲得數倍提升。
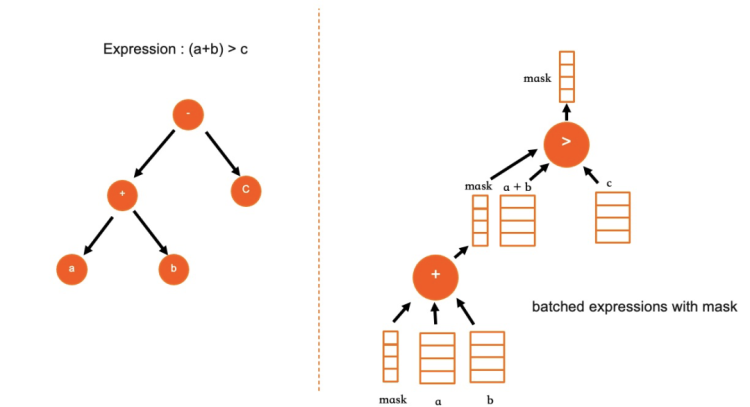
采用了與PostgreSQL類似的表達式實現方法。在SQL編譯及優化階段,IMCI的表達式以一個樹形結構來存儲,在執行前對該表達式樹進行后序遍歷,將其轉換為一維數組來存儲。在后續計算時,只需要遍歷該一維數組即可。由于消除了樹形迭代器模型中的遞歸過程,計算效率會更高。同時,該方法在計算過程中將數據和計算過程分離,適合并行計算。
支持行列混合存儲的存儲引擎
事務型應用和分析型應用對存儲引擎有截然不同的要求。前者要求索引可以精確定位到每一行,并支持高效的增刪改。而后者則需要支持高效批量掃描處理。這兩個場景對存儲引擎的設計要求完全不同,有時甚至矛盾。
因此設計一個一體化的存儲引擎能同時服務OLTP型和OLAP型負載非常具有挑戰性。目前市場上HTAP存儲引擎做的比較好的只有有幾十年研發經驗的大公司,如Oracle(In-Memory Column Store)、SQL Server(In Memory Column index)、DB2(BLU)等。TiDB等只能通過將多副本集群中的單個副本調整為列存來支持HTAP需求。
一體化的HTAP存儲引擎一般使用行列混合的存儲方案。即引擎中同時存在行存和列存,行存服務于TP,列存服務于AP。相比于獨立部署OLTP數據庫和OLAP數據庫來滿足業務需求,HTAP引擎具有以下優勢:
行存數據和列存數據具有實時一致性,能滿足很多苛刻的業務需求,所有數據寫入即可見于分析型查詢。
成本低。用戶可以指定一張表中的哪些列,甚至哪個范圍的存儲為列存格式。全量數據繼續以行存存儲。
管理運維方便。用戶無需關注數據是否在兩套系統之間同步及數據一致性問題。
PolarDB采用了和Oracle、SQL Server等商用數據庫類似的行列混合存儲技術,稱之為In-Memory Column Index。
建表時可以指定部分表或者列為列存格式,或者對已有的表使用Alter table語句為其增加列存屬性。分析型查詢會自動使用列存格式來進行查詢加速。
列存數據默認以壓縮格式存儲在磁盤,并可以使用In-Memory Column-Store Area做緩存加速查詢,傳統的行格式依然保存在BufferPool中供OLTP負載使用。
所有事務的增刪改操作都會實時反應在列存存儲上,保證事務級別的數據一致性。
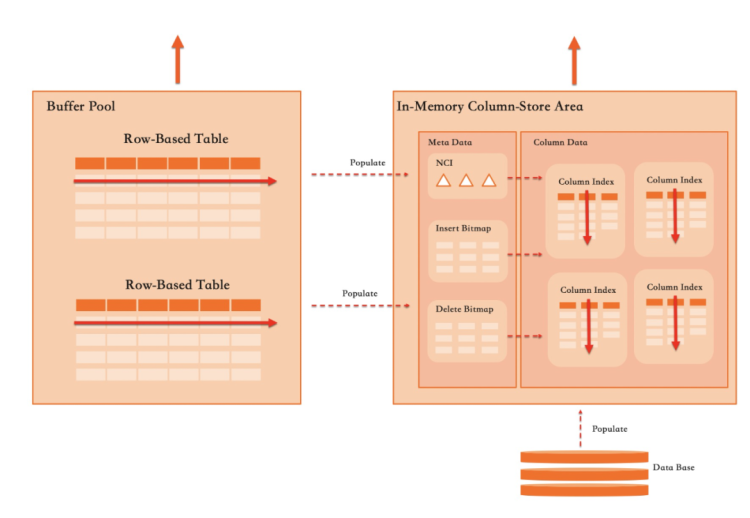
實現行列混合存儲引擎技術上非常困難,但在InnoDB這樣一個成熟的面向OLTP負載優化的存儲引擎中增加列存支持,又面臨不同的情況:
滿足OLTP業務需求為第一優先級,因此增加列存不能對TP性能影響太大。這就要求維護列存必須足夠輕量,必要時需要降低AP的性能提升TP的性能。
列存設計無需考慮事務并發對數據的修改以及數據unique check等問題,這些問題在行存系統中已經被解決,而這些問題對ClickHouse等單獨的列存引擎難以處理。
由于行存系統的存在,列存系統出現任何問題都可以切換回行存系統。
上述條件可謂有利有弊,這也影響了對PolarDB整個行列混合存儲的方案設計,表現為以下幾個方面。
Index列存
基于MySQL插件式的存儲引擎框架架構,增加列存最簡單方案為實現一個單獨的存儲引擎。例如,Inforbright以及MarinaDB的ColumnStore。而PolarDB采用了將列存實現為InnoDB的二級索引的方案,主要基于如下幾點考量:
InnoDB原生支持多索引,Insert、Update和Delete操作都會以行粒度apply到Primary Index和所有的Secondary Index上。將列存實現為一個二級索引。
在數據編碼格式上,二級索引的列存可以和其他行存索引使用完全一樣的格式,直接拷貝即可。不需要考慮charset和collation等信息。
二級索引操作非常靈活,可以在建表時指定索引所包含的列,也可以后續通過DDL語句對一個二級索引中包含的列進行增加或者刪除操作。例如,用戶可以將需要分析的INT、FLOAT和DOUBLE列加入列索引。而對于只需要點查但又占用大量空間的TEXT和BLOB字段,則可以保留在行存中。
崩潰恢復過程可以復用InnoDB的Redo事務日志模塊,與現有實現無縫兼容。同時也支持PolarDB的物理復制過程,支持在獨立RO節點或者Standby節點上生成列存索引。
同時二級索引與主表有一樣的生命周期,方便管理。
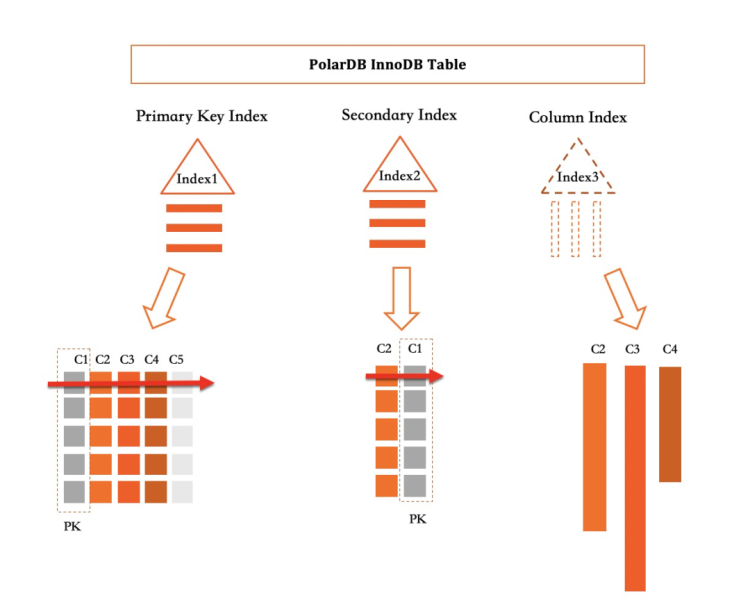 如上圖所示,在PolarDB中,所有Primary Index和Secondary Index都實現為一個B+Tree。而列索引定義為一個Index,但其是一個虛擬索引,用于捕獲對該索引覆蓋列的增刪改操作。
如上圖所示,在PolarDB中,所有Primary Index和Secondary Index都實現為一個B+Tree。而列索引定義為一個Index,但其是一個虛擬索引,用于捕獲對該索引覆蓋列的增刪改操作。主表(Primary Index)包含(C1、C2、C3、C4、C5)5列數據,Secondary Index索引包含(C2、C1)兩列數據,在普通二級索引中,C2與C1編碼為一行,并保存在B+tree中。而其中的列存索引包含(C2、C3、C4)三列數據。在實際物理存儲時,會對三列進行拆分獨立存儲,每一列都會按寫入順序轉成列存格式。
列存實現為二級索引的另一個優點為:執行器的工程實現非常簡單,在MySQL中已經存在覆蓋索引的概念,即查詢所需要的列均在一個二級索引中存儲,則這個二級索引中的數據均滿足查詢需求,使用二級索引相對于使用Primary Index可以極大減少讀取的數據量,進而提升查詢性能。當一個查詢所需要的列都被列索引覆蓋時,借助列存的加速作用,可以數十倍甚至數百倍的提升查詢性能。
列存數據組織
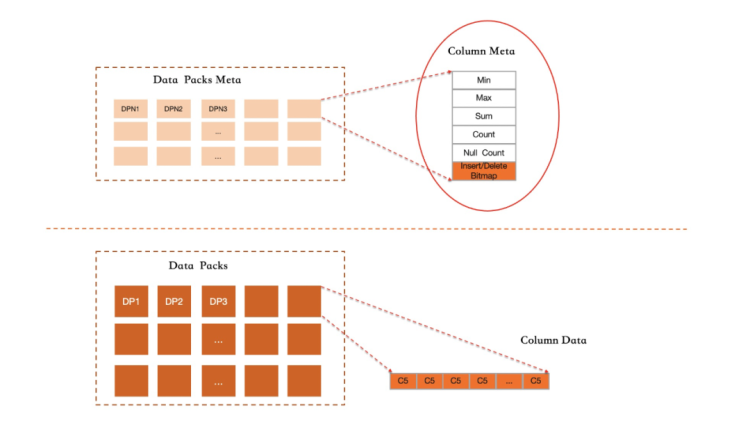
Column Index中的每一列,其存儲都使用了無序且追加寫的格式。結合刪除標記及后臺異步compaction,實現空間回收。其具體實現關鍵點有:
列索引中,記錄按照RowGroup進行組織,每個RowGroup中不同的列會各自打包成DataPack。
每個RowGroup都采用追加寫格式,每個列的DataPack也采用追加寫格式。對于一個列索引,只有Active RowGroup負責接受新的寫入。當該RowGroup寫滿后即凍結,其所有的Datapack會轉為壓縮格式保存到磁盤,同時記錄每個數據塊的統計信息。
列存RowGroup中每新寫入一行,會分配一個RowID定位。屬于一行的所有列都可以使用該RowID計算定位,同時系統維護PK到RowID的映射索引,以支持后續的刪除和修改操作。
更新操作,首先根據RowID計算出其原始位置并設置刪除標記,然后在ActiveRowGroup中寫入新的數據版本。
當RowGroup中的無效記錄超過一定閾值時,會觸發后臺異步compaction操作。其作用一方面是為了回收空間,另一方面可以讓有效的數據存儲更加緊湊,提升分析型查詢單的效率。
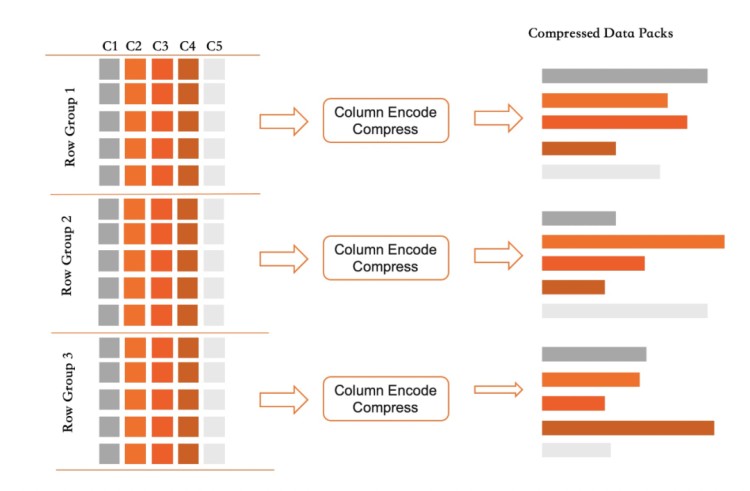
采用列存數據組織方式,一方面滿足了分析型查詢按列進行批量掃描過濾的要求。另一方面,對于TP型事務操作影響非常小,寫入操作只需要按列追加寫入內存即可。刪除操作只需要設置一個刪除標記位。而更新操作則是刪除標記附加追加寫。列存支持事務級別更新的同時,幾乎不影響OLTP的性能。
全量及增量行轉列
以下兩種情況,會涉及行轉列操作。
使用DDL語句對部分列創建列索引,此時需要掃描全表數據以創建列索引。
在實際操作過程中,對于涉及到的列執行行轉列操作。
涉及全表行轉列時,使用并行掃描的方式對InnoDB的Primary Key進行掃描,并依次將所有涉及到的列轉換為列存形式。這種操作的速度非常快,其基本只受限于服務器可用的IO吞吐速度和可用CPU資源。該操作是一個online-DDL過程,不會阻塞在線業務的運行。
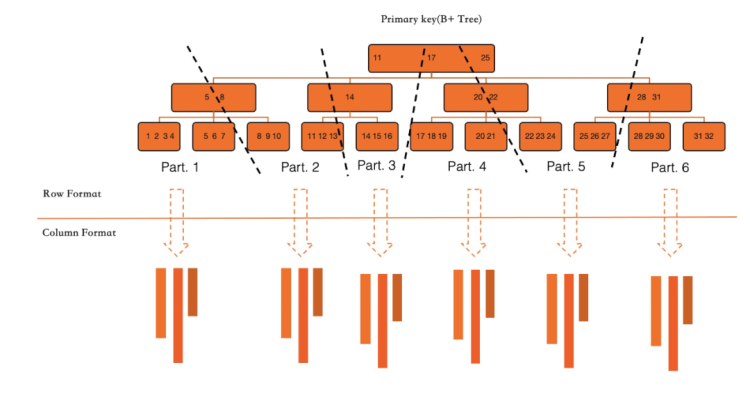
在一張表上建立列索引之后,所有的更新事務將會同步更新行存和列存數據,以保證二者事務的一致性。下圖演示了在IMCI功能關閉和開啟之間的差異性。
關閉IMCI功能時,事務對所有行的更新操作都會先加鎖,然后再對數據頁進行修改。在事務提交之前會對所有加鎖的記錄一次性放鎖。
開啟IMCI功能時,事務系統會創建一個列存更新緩存。在所有數據頁被修改的同時,會記錄所涉及到的列存的修改操作,在事務提交結束前,該更新緩存會應用到列存系統。
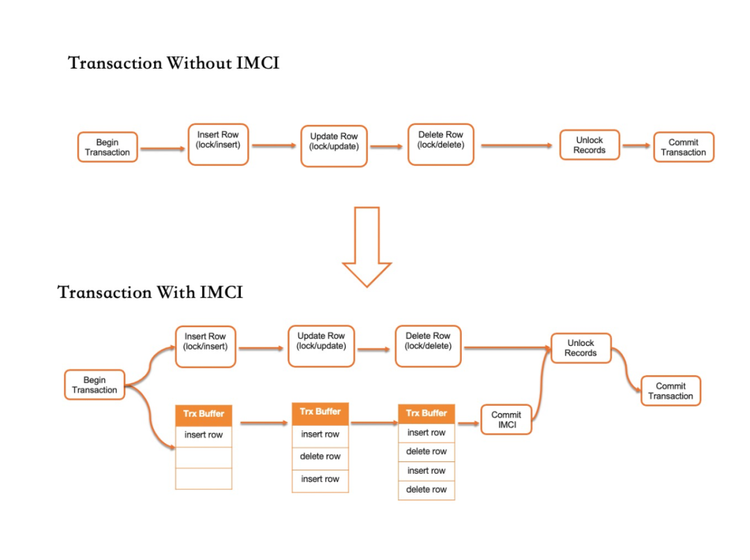
在此實現下,列存存儲提供了與行存一樣的事務隔離級別。對于每一個寫操作,RowGroup中的每一行都會記錄修改該行的事務編號。而對于每個標記,刪除操作也會記錄該動作的事務編號。借助寫事務編號和刪除事務編號,AP型查詢可以使用非常輕量級的方式,來獲得一個全局一致性的快照。
列索引粗糙索引
由列存格式可以看出,IMCI中所有的Datapack都采用無序且追加寫的方式。因此,無法像InnoDB的普通有序索引那樣,可以精準的過濾掉不符合要求的數據。在IMCI中,借助統計信息來進行數據塊過濾以達到降低數據訪問單價的目的。
在每個Active Datapack終結寫入時,會預先進行計算,并生成Datapack所包含數據的最小值、最大值、數值的總和、空值的個數、記錄總條數等信息。所有這些信息會維護在DataPacks Meta元信息區域并常駐內存。由于凍結的Datapack中存在數據的刪除操作,因此,統計信息的更新維護會在后臺完成。
對于查詢請求,會根據查詢條件將Datapacks分為相關、不相關、可能相關三大類,從而減少實際的數據塊訪問量。而對于一些聚合查詢操作,如
count和sum等,可以通過預先計算好的統計值進行簡單的運算得出,且這些數據塊不需要解壓。
 采用基于統計信息的粗糙索引方案,對于一些需要精準定位部分數據的查詢并不友好。但是,在一個行列混合存儲引擎中,列索引只需要輔助加速那些涉及到大量數據掃描的查詢,這種場景下,使用列索引具有顯著的優勢。而對于那些只訪問少量數據的SQL,優化器會基于代價模型計算得出一個基于行存的成本更低的方案。
采用基于統計信息的粗糙索引方案,對于一些需要精準定位部分數據的查詢并不友好。但是,在一個行列混合存儲引擎中,列索引只需要輔助加速那些涉及到大量數據掃描的查詢,這種場景下,使用列索引具有顯著的優勢。而對于那些只訪問少量數據的SQL,優化器會基于代價模型計算得出一個基于行存的成本更低的方案。行列混合存儲下的TP和AP資源隔離
PolarDB行列混合存儲可以應用于實例中同時存在AP型查詢和TP型查詢的場景。但很多業務有很高的OLTP型負載,而突發性的OLAP負載可能干擾到TP型業務的響應時延。因此負載隔離在HTAP數據庫中是一個必要的功能。借助PolarDB的一寫多讀架構,可以非常方便的對AP型負載和TP型負載進行隔離。基于PolarDB技術架構,有以下三種部署方式:
第一種方式,在RW節點開啟行列混合存儲。這種部署模式可以支持輕量級的AP查詢,在主要負載為TP且AP型請求比較少時,可以采用此部署模式。或使用PolarDB進行報表查詢,但報表查詢僅適用于數據來自批量數據導入的場景。
第二種方式,RW節點支持OLTP型負載,并啟動AP型RO節點開啟行列混合存儲。這種部署模式下CPU資源可以實現100%隔離,同時該AP型RO節點上的內存可以100%分配給列存存儲和執行器。但是,由于使用相同的共享存儲,在IO上會相互影響。
第三種方式,RW節點和RO節點同時支持OLTP型負載,在單獨的Standby節點開啟行列混合存儲以支持AP型查詢。由于Standby使用獨立的共享存儲集群,這種方案在第二種方案支持CPU和內存資源隔離的基礎上,還可以實現IO資源的隔離。
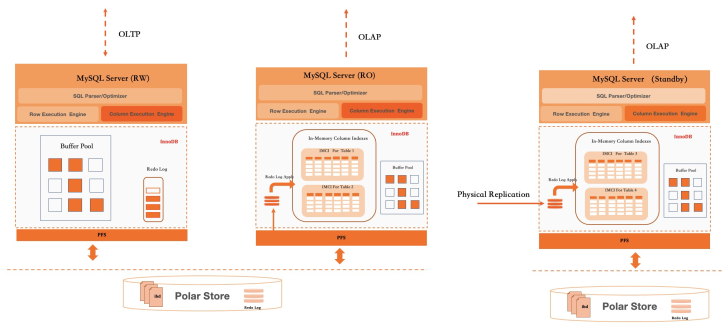
除上述部署架構不同,但可以支持資源隔離之外。PolarDB內部對于一些需要使用并行執行的大查詢支持動態并行度調整(Auto DOP),這個機制會綜合考慮當前系統的負載以及可用的CPU和內存資源,限制查詢所用資源,以避免查詢消耗的資源太多,影響系統處理其他請求。
PolarDB IMCI的OLAP性能
為了驗證IMCI的技術效果,對PolarDB MySQL IMCI進行了TPC-H場景測試。同時在相同場景下,將其與原生MySQL的行存執行引擎以及當前OLAP引擎單機性能最強的ClickHouse進行了對比。測試參數簡要介紹如下:
數據量TPC-H 100 GB,22條Query語句。
CPU Intel(R) Xeon(R) CPU E5-2682 2 socket
內存512 GB,啟動后數據均輸入內存。
PolarDB IMCI VS MySQL串行
TPC-H場景下,22條Query語句。IMCI處理延時相比原生MySQL有數十倍到數百倍不等的加速效果。其中Q6的效果將近400倍。體現出了IMCI的巨大優勢。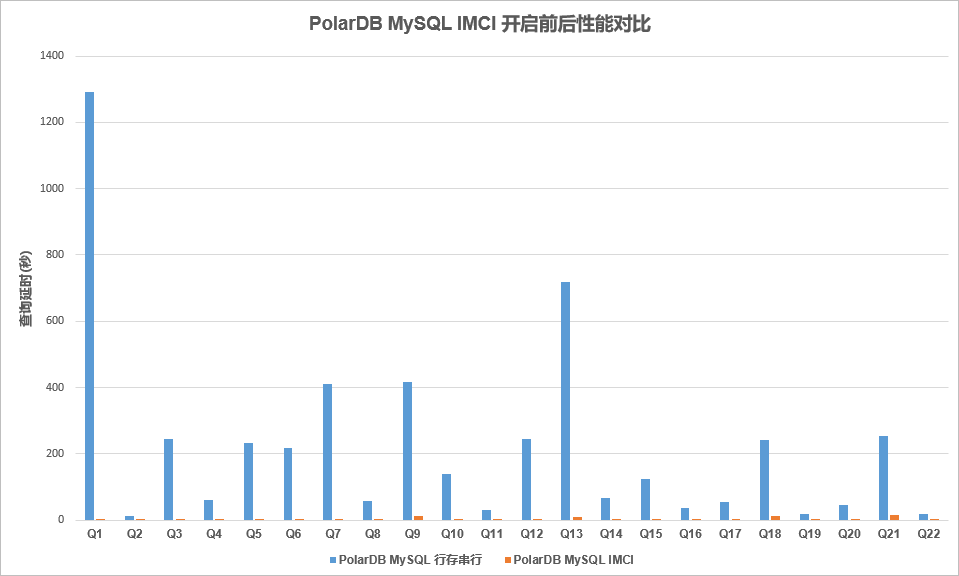
PolarDB IMCI VS ClickHouse
對比當前社區最火熱的分析型數據庫ClickHouse時,IMCI在TPC-H場景下的性能也與其基本位于同一水平。在處理部分SQL的處理延時時各有優劣。用戶完全可以使用IMCI替代ClickHouse,同時其數據管理也更加方便。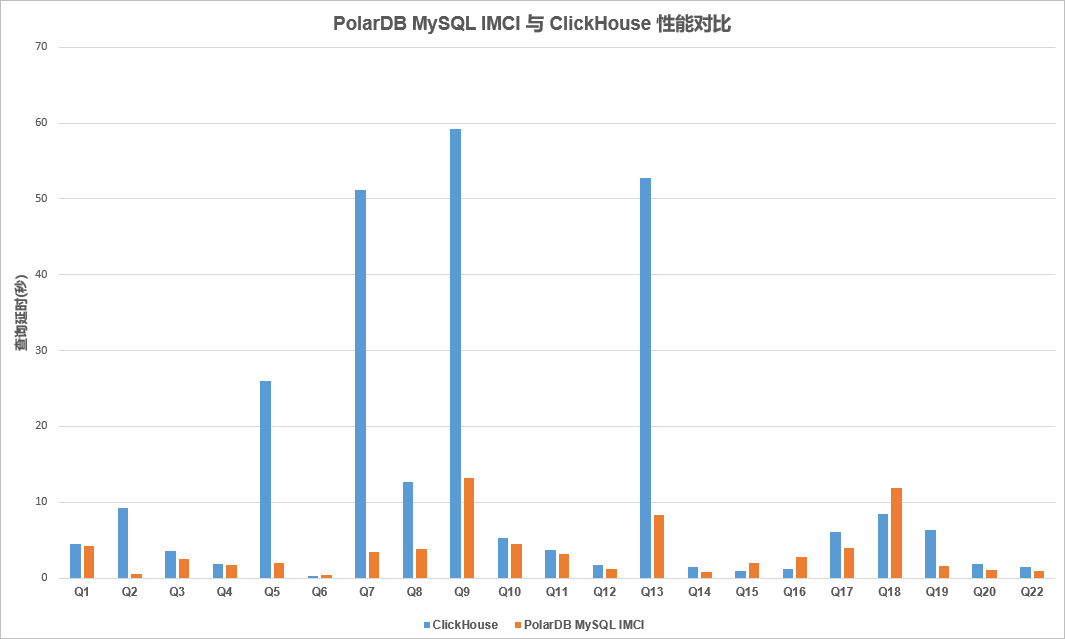
FutureWork
IMCI是PolarDB邁向數據分析市場的第一步,它的迭代腳步不會停止,接下來我們會在如下幾個方向進一步研究和探索,給客戶帶來更好的使用體驗:
自動化的索引推薦系統。目前列存的創建和刪除需要用戶手動指定,增加了DBA的工作量,研究方向上即將引入自動化推薦技術,根據用戶的SQL請求,自動創建列存索引,降低維護工作量。
單獨的列存表以及OSS存儲。目前IMCI只是一個索引,對于純分析型場景,刪除行存可以更進一步的降低存儲大小。而IMCI執行器支持讀寫OSS對象存儲,可以將存儲成本降到最低。
行列混合執行。即SQL執行計劃部分片段在行存執行,部分片段在列存執行。以獲得最大化的執行加速效果。