PolarDB并行查詢
本文介紹PolarDB MySQL版在并行查詢這一企業(yè)級查詢加速特性上做的技術(shù)探索、形態(tài)演進(jìn)和相關(guān)組件的實現(xiàn)原理。
并行查詢背景
PolarDB
亞馬遜在2017年發(fā)表的關(guān)于Aurora的這篇paper[1],引領(lǐng)了云原生關(guān)系型數(shù)據(jù)庫的發(fā)展趨勢,而作為國內(nèi)最早布局云計算的廠商,阿里云也在2018年推出了自己的云原生關(guān)系數(shù)據(jù)庫PolarDB,和Aurora的理念一致,PolarDB深度融合了云上基礎(chǔ)設(shè)施,目標(biāo)是在為客戶提供云上特有的擴(kuò)展性、彈性、高可用性的同時,能夠具備更低的響應(yīng)延遲和更高的并發(fā)吞吐,其基本架構(gòu)如下:
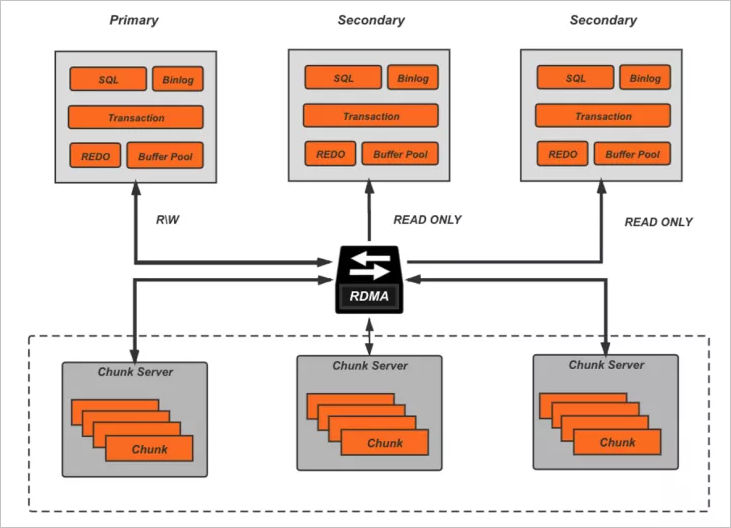 底層的分布式共享存儲突破了單機(jī)存儲容量的限制,而且可以隨用戶的數(shù)據(jù)量增長自動彈性擴(kuò)容,計算層則是一寫多讀的典型拓?fù)洌肦DMA提供的高速遠(yuǎn)程訪問能力來抵消計算存儲分離帶來的額外網(wǎng)絡(luò)開銷。
底層的分布式共享存儲突破了單機(jī)存儲容量的限制,而且可以隨用戶的數(shù)據(jù)量增長自動彈性擴(kuò)容,計算層則是一寫多讀的典型拓?fù)洌肦DMA提供的高速遠(yuǎn)程訪問能力來抵消計算存儲分離帶來的額外網(wǎng)絡(luò)開銷。挑戰(zhàn)
從上圖基本架構(gòu)中可以看到,存儲層將允許遠(yuǎn)大于單機(jī)的數(shù)據(jù)容量(目前是128 TB),甚至線上會出現(xiàn)一些用戶,單表容量達(dá)到xx TB級別,這在基于MySQL主從復(fù)制的傳統(tǒng)部署中是難以想象的。同時大量用戶會有對業(yè)務(wù)數(shù)據(jù)的實時分析訴求,如統(tǒng)計、報表等,但大家對MySQL的直觀印象就是:小事務(wù)處理快、并發(fā)能力強(qiáng)以及分析能力弱,對于這些實時性分析查詢,該如何應(yīng)對呢?
方案
隨著互聯(lián)網(wǎng)的發(fā)展,數(shù)據(jù)量的爆炸,一定的數(shù)據(jù)分析能力、異構(gòu)數(shù)據(jù)的處理能力開始成為事務(wù)型數(shù)據(jù)庫的標(biāo)配,MySQL社區(qū)在8.0版本中也對自身的查詢處理能力做了加強(qiáng),包括對子查詢的transformation、hash join、window function支持等,同時PolarDB MySQL版優(yōu)化器團(tuán)隊也做了大量工作來提升對復(fù)雜查詢的處理能力,如統(tǒng)計信息增強(qiáng)、子查詢更多樣的transformation、query cache等。
并行查詢(Parallel Query)是PolarDB MySQL版在一推出就配備的查詢加速功能,本質(zhì)上它解決的是一個最核心的問題:MySQL的查詢執(zhí)行是單線程的,無法充分利用現(xiàn)代多核大內(nèi)存的硬件資源。通過多線程并行執(zhí)行來降低包括IO以及CPU計算在內(nèi)的處理時間,來實現(xiàn)響應(yīng)時間的大幅下降。對于用戶而言,一條查詢?nèi)绻梢?分鐘用10個核完成,比10分鐘用1個核完成更有意義。此外所有成熟的商業(yè)型數(shù)據(jù)庫也都具備并行查詢的能力。
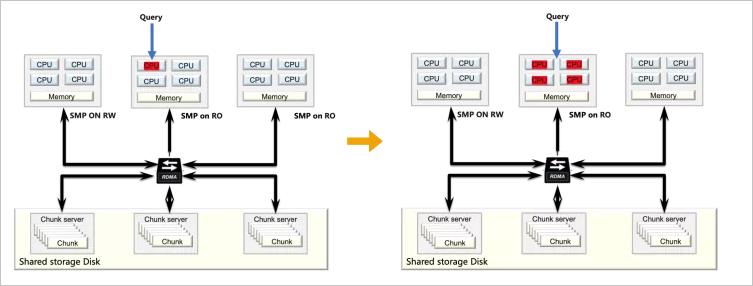
并行查詢介紹
特性
并行查詢可以說是PolarDB MySQL在計算層最為重要復(fù)雜度也最高的功能組件,隨著PolarDB的推出已經(jīng)線上穩(wěn)定運(yùn)行多年,而且一直在持續(xù)演進(jìn),它具備如下幾個特性:
完全基于MySQL codebase,原生的MySQL 100%兼容:
語法兼容。
類型兼容。
行為兼容。
0附加成本,隨產(chǎn)品發(fā)布就攜帶的功能:
無需額外存儲資源。
無需額外計算節(jié)點。
0維護(hù)成本,使用和普通查詢無差別,僅響應(yīng)提升了:
隨集群部署,開箱即用。
對業(yè)務(wù)無侵入。
單一配置參數(shù)(并行度)。
實時性分析,PolarDB原生的一部分,受惠于REDO物理復(fù)制的低延遲:
統(tǒng)一底層事務(wù)型數(shù)據(jù)。
提交即可見。
極致性能,隨著PQ的不斷完善,對于分析型算子、復(fù)雜查詢結(jié)構(gòu)的支持能力不斷提升:
全算子并行。
高效流水線。
支持復(fù)雜SQL結(jié)構(gòu)。
穩(wěn)定可靠,作為企業(yè)級特性:
擴(kuò)展MySQL測試體系。
線上多年積累。
完備的診斷體系。
演進(jìn)
并行查詢的功能是持續(xù)積累起來的,從最初的PQ1.0到PQ2.0,目前進(jìn)入了跨節(jié)點并行的研發(fā)階段,并且很快會發(fā)布上線。
PQ1.0
最早發(fā)布的并行查詢能力,其基本的思路是計算的下推,將盡可能多的計算分發(fā)到多個worker上并行完成,這樣像IO這樣的重操作就可以同時進(jìn)行,但和一般的share-nothing分布式數(shù)據(jù)庫不同,由于底層共享存儲,PolarDB并行中對于數(shù)據(jù)的分片是邏輯而非物理的,每個worker都可以看到全量的表數(shù)據(jù),關(guān)于邏輯分片的內(nèi)容,執(zhí)行器部分會詳細(xì)介紹。
并行拆分的計劃形態(tài)典型如下:
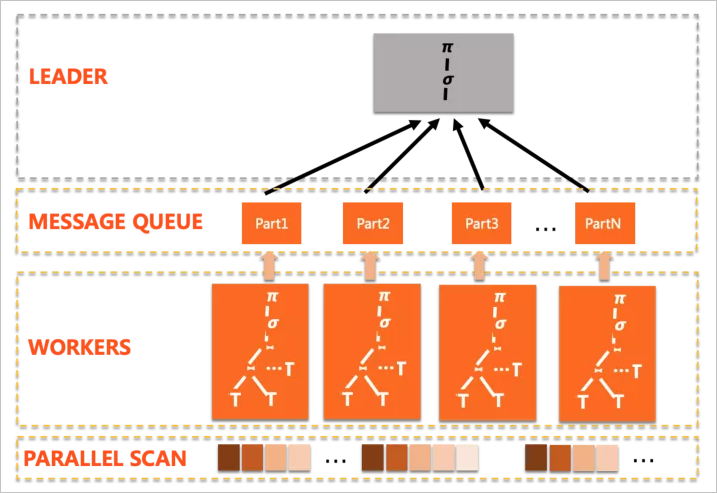 PQ1.0 有以下幾個特點:
PQ1.0 有以下幾個特點:執(zhí)行模式是scatter-gather,只有一個Plan Slice,多個worker完成相同的功能,匯總到leader。
盡可能的下推算子到worker上。
leader負(fù)責(zé)完成無法下推的計算。
這個方案能夠解決很多線上的慢查詢問題,得到很好的加速效果,不過也存在著一定的局限性:
計劃形態(tài)單一,導(dǎo)致算子的并行方式單一,比如group by + aggregation,只能通過二階段的聚集來完成:worker先做partial aggregation,leader上做final aggregation。
一旦leader上完成聚集操作,后續(xù)如果有
distinct/window function/order by等,都只能在leader上完成,形成單點瓶頸。如果存在數(shù)據(jù)傾斜,會使部分worker沒有工作可做,導(dǎo)致并行擴(kuò)展性差。
實現(xiàn)上還有一些待完善的地方,例如少量算子不支持并行、一些復(fù)雜的查詢嵌套結(jié)構(gòu)不支持并行。
PQ2.0
PQ2.0彌補(bǔ)了以上所說的局限性,從執(zhí)行模式上對齊了Oracle/SQL Server,實現(xiàn)了更加強(qiáng)大的多階段并行。
計劃形態(tài)典型如下:
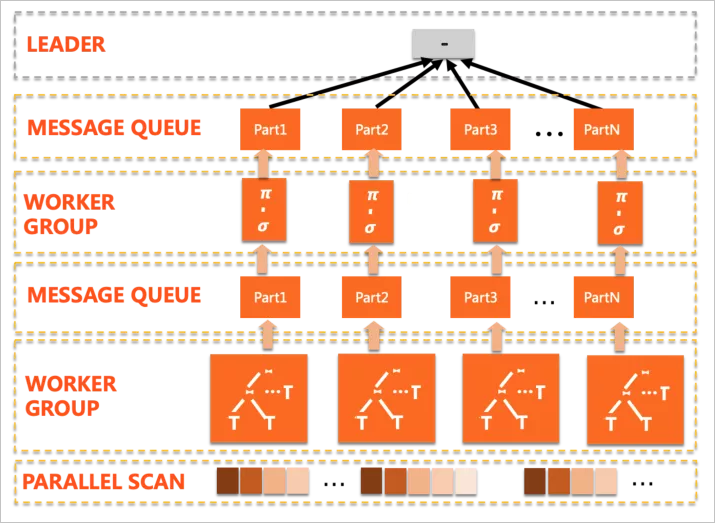
對比PQ1.0可以看出,PQ2.0存在多個worker group,PQ2.0的執(zhí)行計劃是多階段的,計劃會被拆分為若干片段(Plan Slice),每個Slice由一組worker并行完成,在slice之間通過exchange數(shù)據(jù)通道傳遞中間結(jié)果,并觸發(fā)后續(xù)slice的流水線執(zhí)行。其中一些加強(qiáng)的點如下:
全新的Cost-based并行優(yōu)化器,基于統(tǒng)計信息和代價決定最優(yōu)計劃形態(tài)。
全算子的并行支持,包括上面提到的復(fù)雜的多層嵌套結(jié)構(gòu),也可以做到完全的并行。
引入exchange算子,即支持Shuffle/Broadcast等數(shù)據(jù)分發(fā)操作。
引入一定自適應(yīng)能力,即使并行優(yōu)化完成了,也可以根據(jù)資源負(fù)載情況做動態(tài)調(diào)整,如回退串行或降低并行度。
示例:
SELECT t1.a, sum(t2.b) FROM t1 JOIN t2 ON t1.a = t2.a JOIN t3 ON t2.c = t3.c GROUP BY t1.a ORDER BY t1.a LIMIT 10;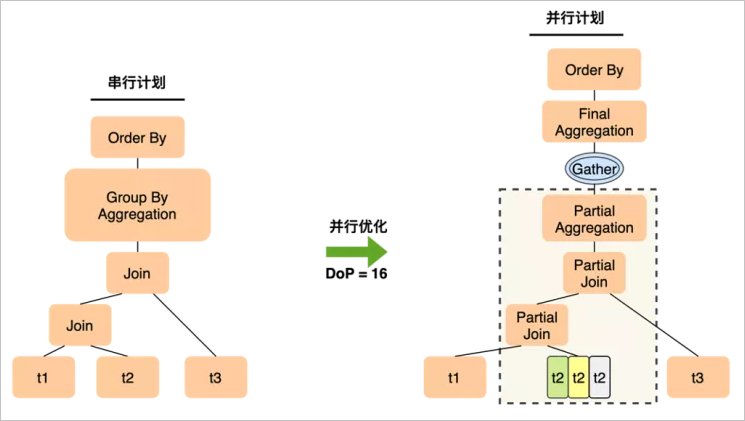 對上面的簡單查詢,在經(jīng)過優(yōu)化后,PQ1.0會生成圖中的執(zhí)行計劃。
對上面的簡單查詢,在經(jīng)過優(yōu)化后,PQ1.0會生成圖中的執(zhí)行計劃。在join的表集合中,尋找一個可以做邏輯分片的表做拆分,如果3個表都不足以拆分足夠多的分片,那就選最多的表,比如這里選擇了t2,它可能拆出12個分片,但仍然無法滿足并行度16的要求,導(dǎo)致有4個worker讀不到數(shù)據(jù)而idle。
聚集操作先在worker上做局部聚集,leader上做匯總聚集,如果各個worker上分組的聚攏不佳,導(dǎo)致leader仍然會收到來自下面的大量分組,leader上就會仍然有很重的聚集計算,leader計算慢會接收不到worker數(shù)據(jù),從而降低worker的執(zhí)行速度,導(dǎo)致查詢整體變慢。
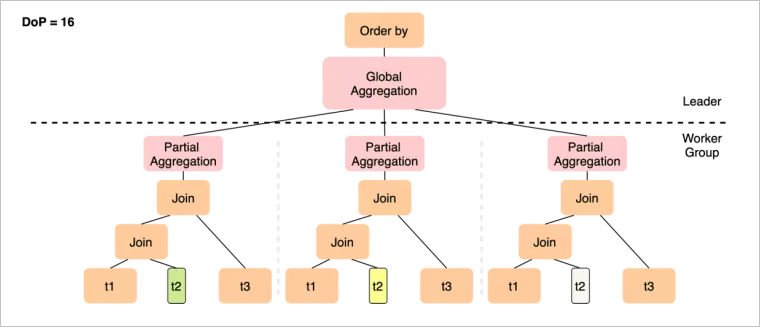
PQ2.0的執(zhí)行計劃如下:
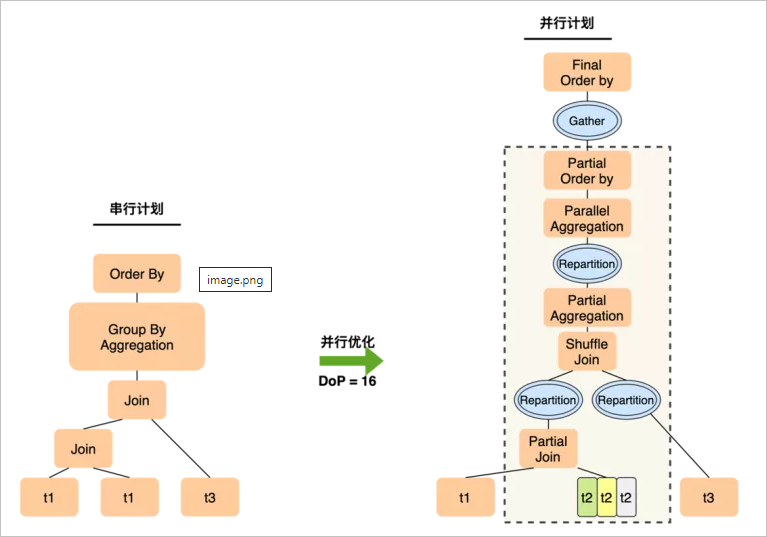
雖然只能在t2上做數(shù)據(jù)分片,但12個worker只需要完成t1 join t2這個操作,在join完成后一般數(shù)據(jù)量會膨脹,通過Shuffle(Repartition)將更多的中間結(jié)果分發(fā)到后續(xù)的Slice中,從而以更高的并行度完成與t3的join。
各worker完成局部聚集后,如果分組仍很多,可以基于Group By Key做一次Shuffle來將數(shù)據(jù)打散到下一層slice,下一組worker會并行完成較重的聚集操作,以及隨后的Order By局部排序,最終leader只需要做一次merge sort的匯總。
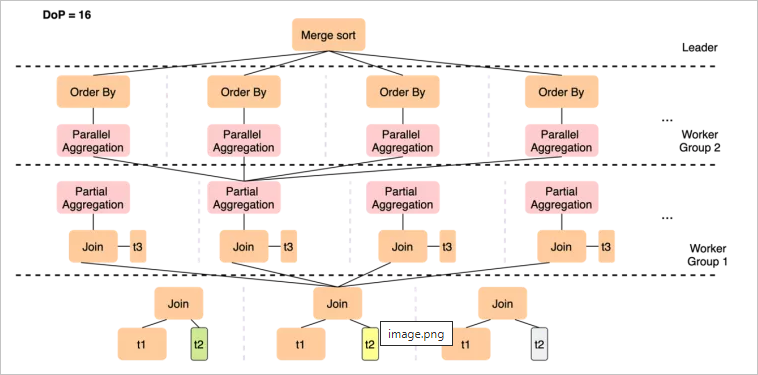
PQ2.0解決了單點瓶頸和數(shù)據(jù)量不足導(dǎo)致的擴(kuò)展性問題,實現(xiàn)線性加速。為什么線性擴(kuò)展如此重要?
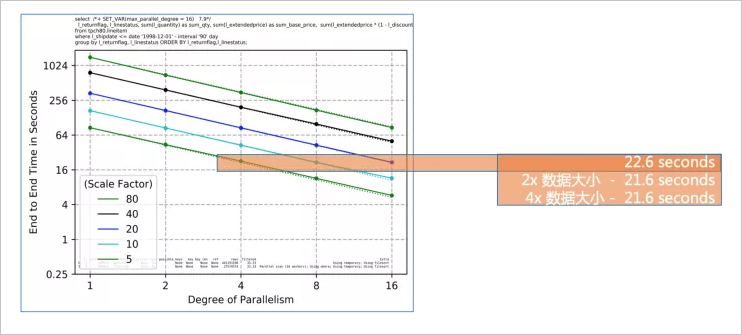 從上圖可以看到,隨著并行度的增長,E2E的響應(yīng)時間是線性下降的,這對于客戶有兩個重要作用:
從上圖可以看到,隨著并行度的增長,E2E的響應(yīng)時間是線性下降的,這對于客戶有兩個重要作用:隨著業(yè)務(wù)增長數(shù)據(jù)不斷膨脹,通過相應(yīng)提高并行度來使用匹配的計算資源,來持續(xù)得到穩(wěn)定可預(yù)期的查詢性能。
始終快速的分析時間可以驅(qū)動快速的業(yè)務(wù)決策,使企業(yè)在快速變化的市場環(huán)境中保持競爭力。
架構(gòu)
并行查詢組件的整體架構(gòu)如下:
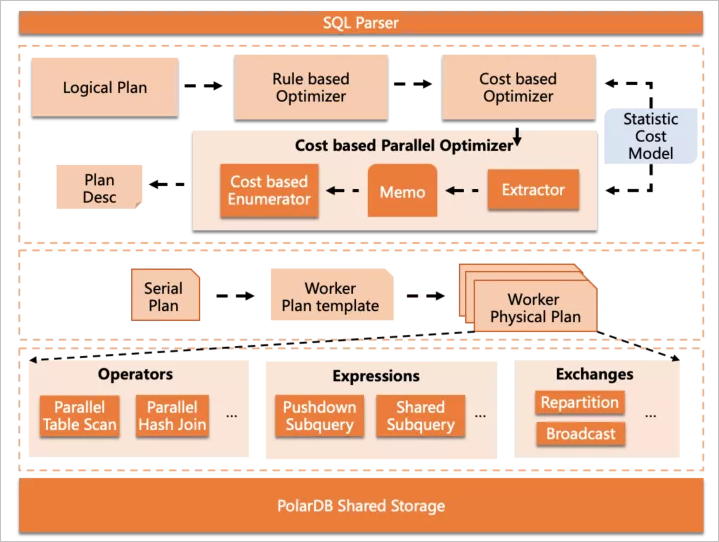 核心部分包括在3層中,從上到下依次是:
核心部分包括在3層中,從上到下依次是:Cost-based Parallel Optimizer,嵌入在MySQL的優(yōu)化器框架中,完成并行優(yōu)化部分。
Parallel Plan Generator,根據(jù)抽象的并行計劃描述,生成可供worker執(zhí)行的物理執(zhí)行計劃。
Parallel Executor,并行執(zhí)行器組件,包括一些算子內(nèi)并行功能和數(shù)據(jù)分發(fā)功能等。
性能
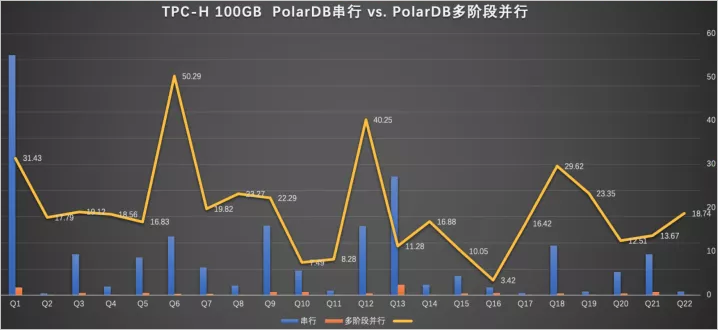
上圖可以看出PQ2.0的查詢加速能力,100%的SQL可以被加速,總和加速比是18.8倍。
使用方式
從易用性的角度,用戶開啟并行查詢只需要設(shè)置一個參數(shù):
set max_parallel_degree = xxx;如果想查看并行執(zhí)行計劃,只需要和普通查詢一樣,執(zhí)行
EXPLAIN / EXPLAIN FORMAT=TREE即可。Explain做了必要的增強(qiáng)來顯示并行相關(guān)的information,包括代價、并行模式、分發(fā)方式等。
并行查詢實現(xiàn)
并行優(yōu)化器
在PQ2.0中,由于計劃形態(tài)會變得更加多樣,如果拆分計劃只是依靠簡單規(guī)則和簡單統(tǒng)計是很難得到最優(yōu)解,因此我們重新實現(xiàn)了一套完全基于cost的并行優(yōu)化器。
基本的流程是在MySQL串行優(yōu)化后,進(jìn)一步做并行拆分,這里可能有讀者疑惑為什么不像Oracle或Greenplum那樣在優(yōu)化流程中統(tǒng)一考慮串/并行的執(zhí)行策略。原因在于MySQL的優(yōu)化流程中,各個子步驟之間沒有清晰的邊界,而且深度遞歸的join ordering算法以及嵌入其中的
semi-join優(yōu)化策略選擇等,都使得代碼邏輯與結(jié)構(gòu)更加復(fù)雜,很難在不大量侵入原生代碼的前提下實現(xiàn)一體化優(yōu)化,而一旦對社區(qū)代碼破壞嚴(yán)重,就無法follow社區(qū)后續(xù)的版本迭代,享受社區(qū)紅利。因此采用了兩步走的優(yōu)化流程,這也是業(yè)界常用的手法,如Spark、CockroachDB、SQL Server PDW、Oceanbase等都采用了類似的方案。
代價模型的增強(qiáng)
基于cost的優(yōu)化,在過程中就必然要能夠得到各個算子并行執(zhí)行的代價信息。為此PolarDB也做了大量統(tǒng)計信息增強(qiáng)的工作:
統(tǒng)計信息自動更新。
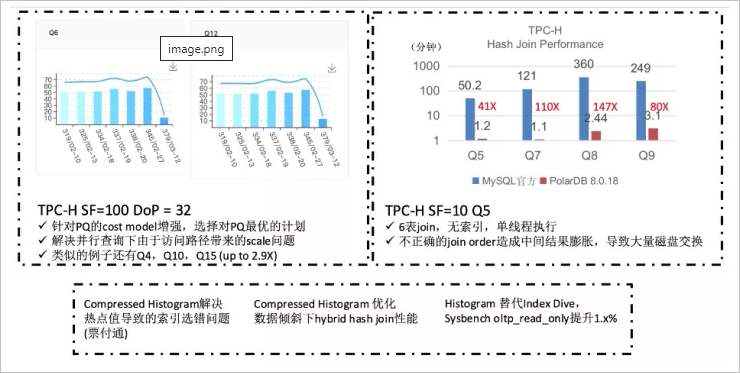
串行優(yōu)化流程中做針對并行執(zhí)行的補(bǔ)強(qiáng),例如修正table掃描方式等,這也是上面性能數(shù)據(jù)中Q6/Q12會有超線性加速比的原因。
全算子統(tǒng)計信息推導(dǎo)+代價計算,補(bǔ)充了一系列的cost formula和cardinality estimation推導(dǎo)機(jī)制。
自適應(yīng)執(zhí)行策略
在早期版本中,串行優(yōu)化和并行優(yōu)化,并行優(yōu)化和并行計劃生成之間存在一定的耦合性,導(dǎo)致在開始并行優(yōu)化后會無法退化回串行的問題,如果系統(tǒng)中這樣的查詢并發(fā)較多,會同時占用很多worker線程導(dǎo)致CPU打爆。新的并行優(yōu)化器解決了這個問題。
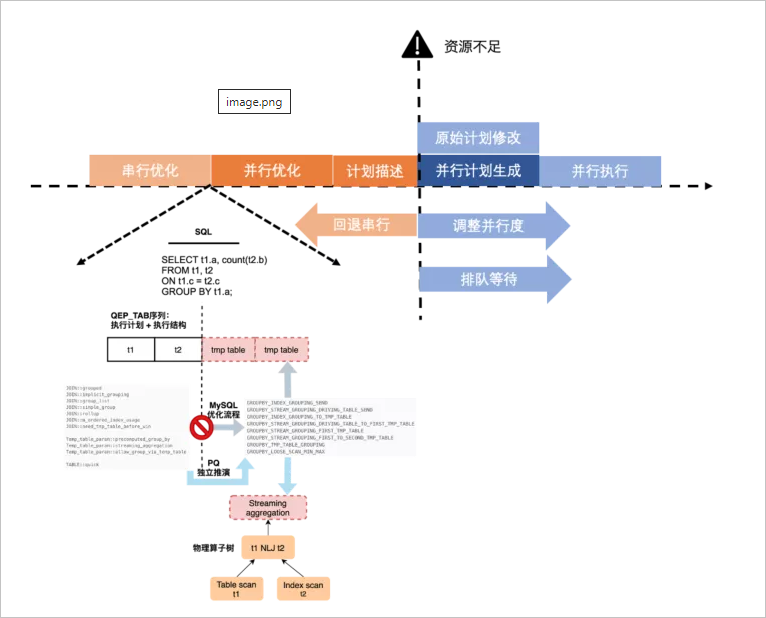
串行優(yōu)化與并行優(yōu)化解耦,并行優(yōu)化會重新構(gòu)建抽象算子樹,并以此為輸入開始
enumeration。并行優(yōu)化與并行計劃生成解耦,優(yōu)化的結(jié)果是計劃子片段的抽象描述,作為輸出進(jìn)行
plan generation。
這樣就使執(zhí)行策略的靈活性成為可能,允許在資源不足情況下,要么退回串行,要么降低并行度,或者進(jìn)入調(diào)度隊列排隊等資源。
基于代價的窮盡式枚舉
并行優(yōu)化是一個自底向上,基于動態(tài)規(guī)劃的窮盡式枚舉過程,實現(xiàn)思路參考了SQL Server PDW paper[2],在過程中會針對每個算子,枚舉可能的并行執(zhí)行方式和數(shù)據(jù)分發(fā)方式,并基于輸出數(shù)據(jù)的Physical Property(distribution + order)構(gòu)建物理等價類,從而做局部剪枝,獲取局部子問題的最優(yōu)解并向上層傳遞,最終到root operator獲取全局最優(yōu)解。
以下是針對t1 NLJ t2這個算子,做枚舉過程的一個簡要示例:
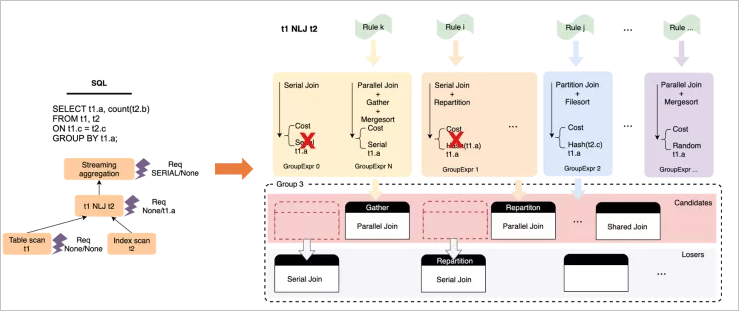 在整體枚舉完成后,計劃空間中會產(chǎn)生一系列帶有數(shù)據(jù)分發(fā)
在整體枚舉完成后,計劃空間中會產(chǎn)生一系列帶有數(shù)據(jù)分發(fā)Exchange Enforcer的物理算子樹,基于代價選擇最優(yōu)樹即可,然后以Enforcer作為子計劃的切分點,可以構(gòu)建出一系列的執(zhí)行計劃抽象描述,輸出到plan generator中。
并行計劃生成
從工程實現(xiàn)角度,并行計劃生成是整個組件中復(fù)雜度最高,bug最多的部分。這里采用了physical plan clone的機(jī)制來實現(xiàn),根據(jù)優(yōu)化器生成的并行計劃描述,從原始串行計劃clone出各個計劃片段的物理執(zhí)行計劃。
為什么要用這種方式呢?還是和MySQL本身機(jī)制相關(guān),MySQL的優(yōu)化和執(zhí)行是耦合在一起的,并沒有一個清晰的邊界,也就是在優(yōu)化過程中構(gòu)建了相關(guān)的執(zhí)行結(jié)構(gòu)。所以沒有辦法根據(jù)一個獨立的計劃描述,直接構(gòu)建出各個物理執(zhí)行結(jié)構(gòu),只能從串行計劃中clone出來,可以說是一切復(fù)雜度的根源。
MySQL的執(zhí)行結(jié)構(gòu)非常復(fù)雜,expression(Item)和query block(SELECT_LEX)的交叉引用,內(nèi)外層查詢的關(guān)聯(lián)(Item_ref)等,都使得這項任務(wù)難度大增,但在這個不斷填坑不斷完善的過程中,團(tuán)隊也對MySQL的優(yōu)化執(zhí)行結(jié)構(gòu)有了很深入的理解,還發(fā)現(xiàn)了社區(qū)不少bug。
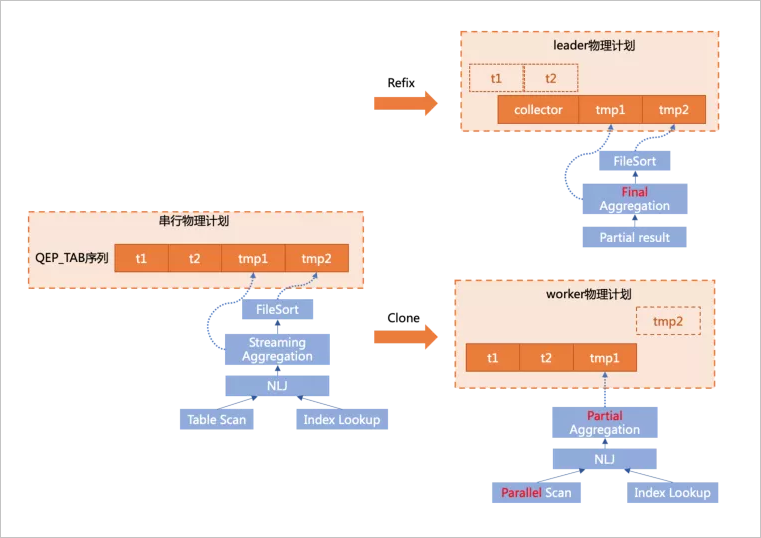 以上圖中簡單的查詢?yōu)槔?/p>
以上圖中簡單的查詢?yōu)槔?/p>SELECT t1.a, sum(t2.b) sumb FROM t1 join t2 ON t1.c = t2.c GROUP BY t1.a ORDER BY sumb;雖然社區(qū)版對執(zhí)行器做了基于Iterator model的重構(gòu),但本質(zhì)上,物理執(zhí)行計劃仍然是由QEP_TAB組成的序列,其中Group By+aggr由tmp table1完成,Order By由tmp table2完成。
在做plan generation時,有兩個核心的操作:
clone
根據(jù)串行Physical Plan和子slice的描述,將相對應(yīng)的結(jié)構(gòu)clone到各個worker線程中,如上圖右下部分,將在worker上執(zhí)行的t1 join t2和下推的聚集操作clone下來。
refix
原始的串行計劃需要轉(zhuǎn)換為leader計劃,因此要替掉不必要的執(zhí)行結(jié)構(gòu)并調(diào)整一些引用關(guān)系,如上圖右上部分,由于t1 join t2和部分聚集操作已經(jīng)下推,leader上需要去掉不必要的結(jié)構(gòu),并替換為從一個collector table中讀取worker傳遞上來的數(shù)據(jù),同時需要將后續(xù)步驟中引用的t1/t2表的結(jié)構(gòu)轉(zhuǎn)為引用collector表的對應(yīng)結(jié)構(gòu)。
并行執(zhí)行器
PQ實現(xiàn)了一系列算子內(nèi)并行的機(jī)制,如對表的邏輯分區(qū)和并行掃描,Parallel Hash join等,來使并行執(zhí)行成為可能或進(jìn)一步提升性能,還有多樣化的子查詢處理機(jī)制等。
Parallel Scan
PolarDB是共享存儲的,所有數(shù)據(jù)對所有節(jié)點均可見,這和sharding的分布式系統(tǒng)有所不同,不同worker處理哪一部分?jǐn)?shù)據(jù)無法預(yù)先確定,因此采用了邏輯分區(qū)的方案:
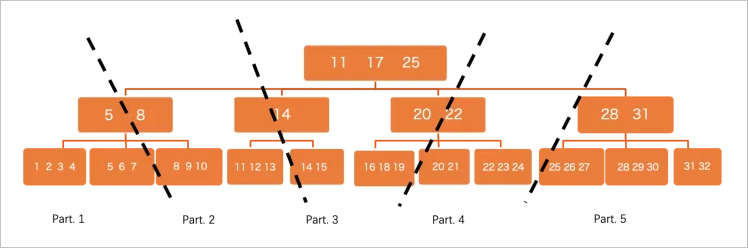 在btree這個level,會將數(shù)據(jù)切分成很多小分片,不同worker負(fù)責(zé)不同分片來觸發(fā)并行執(zhí)行,這里有一些優(yōu)化:
在btree這個level,會將數(shù)據(jù)切分成很多小分片,不同worker負(fù)責(zé)不同分片來觸發(fā)并行執(zhí)行,這里有一些優(yōu)化:盡量做細(xì)粒度的切分,使分片數(shù)遠(yuǎn)遠(yuǎn)大于worker數(shù),然后worker之間通過round robin的方式去“搶”分片來執(zhí)行,這樣自然做到了能者多勞,避免由于數(shù)據(jù)分布skew導(dǎo)致的負(fù)載不均衡問題,這是shared storage系統(tǒng)的一個天然優(yōu)勢。
切分時可以不用dive到葉子節(jié)點,也就是以page作為最小分區(qū)單位,來加速初始分區(qū)速度。
Parallel Hash join
hash join是社區(qū)8.0為加速分析型查詢所引入的功能,并隨著版本演進(jìn)對
semi hash/anti hasha/left hash join均做了支持,PolarDB也引入了這些patch來實現(xiàn)完整的Hash join功能,并實現(xiàn)了多種并行執(zhí)行策略。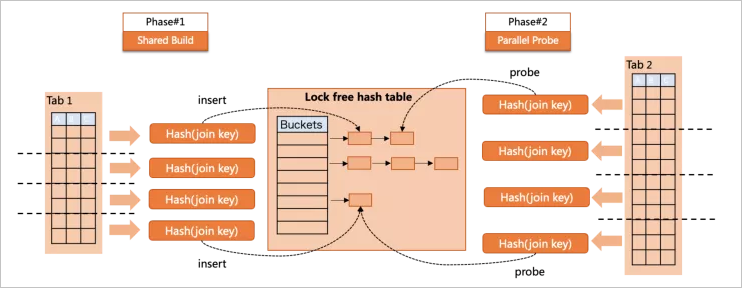 Parallel Hash join在build/probe兩個階段均做了并行支持:
Parallel Hash join在build/probe兩個階段均做了并行支持:build階段,多個worker向同一個共享的lock-free Hash Table中插入數(shù)據(jù)。
probe階段,多個worker并行到Hash Table做搜索。
兩個階段沒有重疊,這樣就實現(xiàn)了全階段的并行,但Parallel Hash join也有自身的問題,例如:共享Hash Table過大導(dǎo)致spill to disk問題,并行插入雖然無鎖,但仍有“同步”原語帶來的cache invalidation。
Partition Hash join
Partition Hash join可以避免Parallel Hash join自身問題,但引入數(shù)據(jù)Shuffle的開銷:
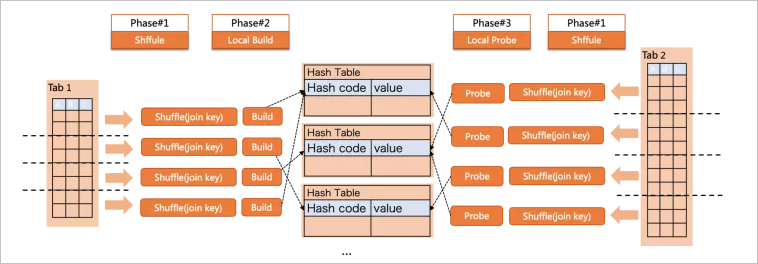
如上圖所示,查詢的執(zhí)行過程分為了3個階段
build/probe兩側(cè)都根據(jù)join key做Shuffle,將數(shù)據(jù)分發(fā)到目標(biāo)Partition;
在每個Partition內(nèi),build側(cè)各自構(gòu)建小Hash Table;
在每個Partition內(nèi),probe側(cè)各自查找對應(yīng)的Hash Table;
這樣就在各個Partition內(nèi),完成了co-located join,每個Hash Table都更小來避免落盤,此外也沒有了build中的并發(fā)問題
子查詢并行 - pushdown exec
這里子查詢是表達(dá)式中的一部分,可以存在于
select list/where/having等子句中。對于相關(guān)子查詢,唯一的并行方式是隨外層依賴的數(shù)據(jù)(表)下推到worker中,在每個worker內(nèi)完整執(zhí)行,但由于外層并行了,每個worker中子查詢執(zhí)行次數(shù)還是可以等比例減少。
例如:
SELECT c1 FROM t1 WHERE EXISTS ( SELECT c1 FROM t2 WHERE t2.a = t1.a <= EXISTS subquery ) ORDER BY c1 LIMIT 10;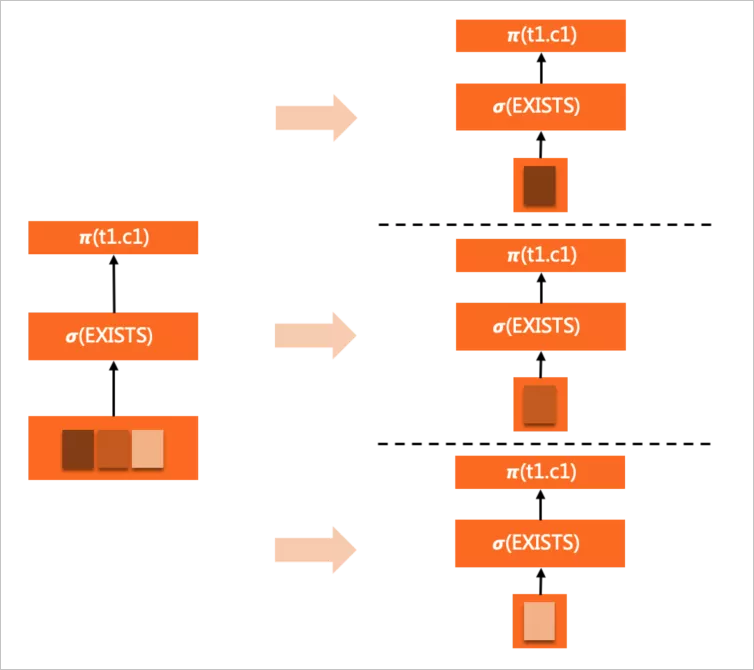
EXISTS子查詢完整的clone到各個worker中,隨著WHERE條件的evaluation反復(fù)觸發(fā)執(zhí)行。
子查詢并行-Pushdown Shared
這種并行方式的子查詢可以是表達(dá)式的一部分,也可以是派生表(derived table)。
這種并行方式適用于非相關(guān)子查詢,因此可以提前并行物化掉,形成一個臨時結(jié)果表,后續(xù)外層在并行中,各worker引用該子查詢時可以直接從表中并行讀取結(jié)果數(shù)據(jù)。
例如:
SELECT c1 FROM t1 WHERE t1.c2 IN ( SELECT c2 FROM t2 WHERE t2.c1 < 15 <= IN subquery ) ORDER BY c1 LIMIT 10;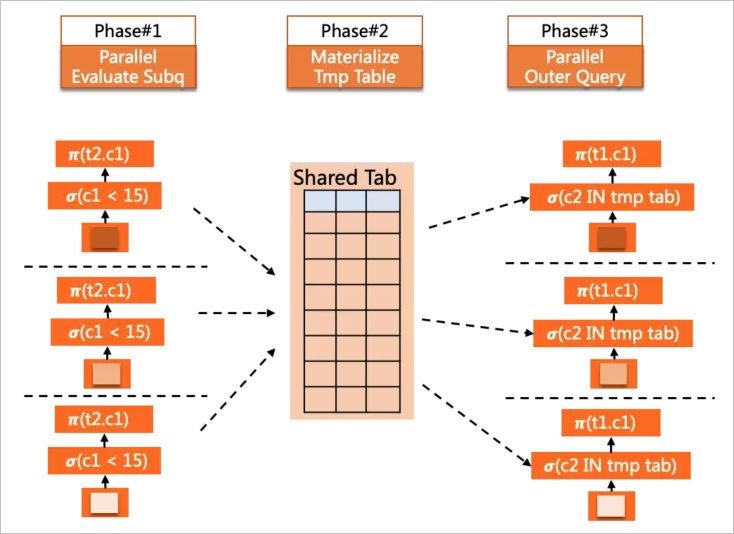
另外線上用戶的報表類查詢中,一種非常常見的Query模式就是derived table的多層嵌套,對于這類SQL,Pushdown Shared策略可以很好的提升并行執(zhí)行的性能,如下示例:

上圖中每個顏色的方塊,代表了一層query block,這里就構(gòu)成了多層derived table的嵌套邏輯,有些層中通過UNION ALL做了匯總,有些層則是多個表(包括derived table)的join,對于這樣的查詢,MySQL會對每個derived table做必要的物化,在外層形成一個臨時結(jié)果表參與后續(xù)計算,而PQ2.0對這種常見的查詢模式做了更普遍的支持,現(xiàn)在每一層查詢的執(zhí)行都是并行完成,力爭達(dá)到線性的加速效果。
Exchanges
要生成高效靈活的執(zhí)行計劃,數(shù)據(jù)分發(fā)組件是必不可少的,目前PolarDB支持了
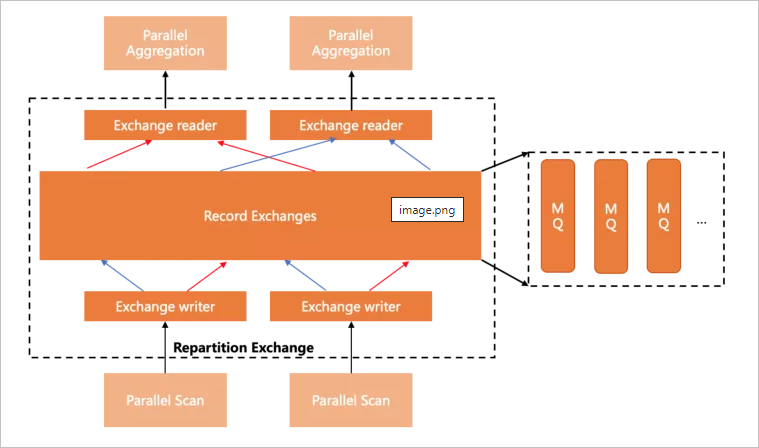
Shuffle/Broadcast/Gather三種分發(fā)方式,實現(xiàn)上利用lock-free shared ring buffer,做到流水線模式的高效數(shù)據(jù)傳輸。下圖展示了Shuffle(Repartition)的基本形態(tài):
未來規(guī)劃
這里說是未來規(guī)劃并不確切,因為團(tuán)隊已經(jīng)在跨節(jié)點并行上做了大量的工作并進(jìn)入了開發(fā)周期的尾端,跨節(jié)點的并行會把針對海量數(shù)據(jù)的復(fù)雜查詢能力提升到另一個水平:
打通節(jié)點間計算資源,實現(xiàn)更高的計算并行度。
突破單節(jié)點在IO/CPU上的瓶頸,充分利用分布式存儲的高吞吐能力。
結(jié)合全局節(jié)點管理與資源視圖,平衡調(diào)度全局計算資源,實現(xiàn)負(fù)載均衡的同時保證查詢性能。
結(jié)合全局一致性視圖,保證對事務(wù)性數(shù)據(jù)的正確讀取。