PolarDB MySQL版在社區版MySQL Federated引擎的基礎上進行了性能優化和增強。
社區版MySQL支持的Federated引擎可以將位于遠程數據庫實例的表像本地表一樣訪問,大大方便了用戶管理多個數據庫實例的數據做聚合查詢和分析。但在性能方面還存在以下可以優化的空間:
只有在使用索引RANGE/REF方式掃描時,才可以將索引上的條件作為SQL的一部分發送到遠程數據庫實例,而其他條件都保留在本地數據庫執行;
即使SQL只訪問了Federated表的一列數據,仍然會拉取遠程表的全部列數據到本地執行;
帶有
ORDER BY <cols> LIMIT OFFSET語法的SQL,也會拉取全部數據到本地執行。
針對以上三個問題,PolarDB MySQL版實現了條件下推、按需返回列和[ORDER BY <cols>] LIMIT OFFSET下推功能。條件下推和按需返回列功能可以將不需要的數據和多余列在遠程數據庫上就被過濾掉,減少了網絡資源的帶寬占用,對于過濾性強的條件和寬表有明顯的性能效果;同時,也給遠程數據庫提供了更大的計劃選擇空間,使查詢性能得到顯著的提升。[ORDER BY <cols>] LIMIT OFFSET下推功能在分頁查詢場景中僅查詢需要的數據,加速效果非常明顯。
前提條件
集群版本需為PolarDB MySQL版8.0版本且修訂版本需滿足如下條件:
8.0.1.1.34或以上。
8.0.2.2.13或以上。
如何查看集群版本,請參見查詢版本號。
使用限制
查詢中只能包含一張Federated表;
只支持SELECT語句;
本地表和遠端表定義完全相同,并且本地表和遠端表字符集和排序完全相同;
不支持表達式、子查詢、排序、聚集等復雜算子的下推。
條件下推
簡介
對于涉及Federated引擎的查詢,社區版MySQL只有在可以利用索引RANGE/REF掃描時,才能將索引上的條件下推,其它的條件保留在本地數據庫執行。而在實際場景中,一條查詢的WHERE條件涉及的字段可能比較多,或者在索引字段上使用了函數導致無法直接使用索引。這時Federated引擎會向遠程數據庫發送全表掃描查詢,將所有數據都拉回本地數據庫后再執行查詢。PolarDB MySQL版的條件下推功能盡可能地將查詢中兼容的條件下推,可以使數據在遠程數據庫中就被過濾掉,從而提升了執行性能,降低了網絡傳輸占用帶寬以及本地拷貝和數據格式轉換代價。
使用方法
您可以通過loose_optimizer_switch參數開啟條件下推功能。具體操作請參見設置集群參數和節點參數。
參數名稱 | 級別 | 描述 |
loose_optimizer_switch | Global/Session | 查詢優化的總控制開關。其中,條件下推功能的開關如下:
|
示例
以下示例中包含1千萬條數據的Sysbench表來模擬在不同選擇率條件下,條件下推帶來的性能提升。測試中使用的本地和遠程Server集群規格為polar.mysql.x8.large(獨享規格,4核32 GB),存儲類型為PLS5。
創建遠程表和Federated表
#創建遠程表#
CREATE TABLE `sbtest1` (
`id` int NOT NULL,
`k` int NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_1` (`k`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
#創建Server#
CREATE SERVER s
FOREIGN DATA WRAPPER mysql
OPTIONS (USER 'username', PASSWORD 'password', HOST 'hostname', PORT 3306, DATABASE 'dbname');
#創建Federated表#
CREATE TABLE `sbtest1` (
`id` int NOT NULL,
`k` int NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_1` (`k`)
) ENGINE=FEDERATED DEFAULT CHARSET=utf8 CONNECTION='s';開啟和關閉條件下推功能的SQL查詢
#關閉條件下推的SQL查詢#
set optimizer_switch='engine_condition_pushdown=off';
Query OK, 0 rows affected (0.03 sec)
EXPLAIN SELECT COUNT(*) FROM sbtest1 WHERE id + 1 < 100;
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | sbtest1 | NULL | ALL | NULL | NULL | NULL | NULL | 9850101 | 100.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.04 sec)
#開啟條件下推的SQL查詢#
set optimizer_switch='engine_condition_pushdown=on';
Query OK, 0 rows affected (0.10 sec)
EXPLAIN SELECT COUNT(*) FROM sbtest1 WHERE id + 1 < 100;
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------------------------------------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------------------------------------------------------------------------------------+
| 1 | SIMPLE | sbtest1 | NULL | ALL | NULL | NULL | NULL | NULL | 9850101 | 100.00 | Using where with pushed condition ((`federated`.`sbtest1`.`id` + 1) < 100) |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------------------------------------------------------------------------------------+
1 row in set, 1 warning (0.05 sec)上述SQL查詢中,由于WHERE條件中使用了包含主鍵的函數與常量進行比較,最優的執行計劃是使用全表掃描的方式,主要的差別在于是否將WHERE條件下推到遠程Server執行。通過改變常量值為selectivity * table_size,構造不同的選擇率條件,測試性能如下:
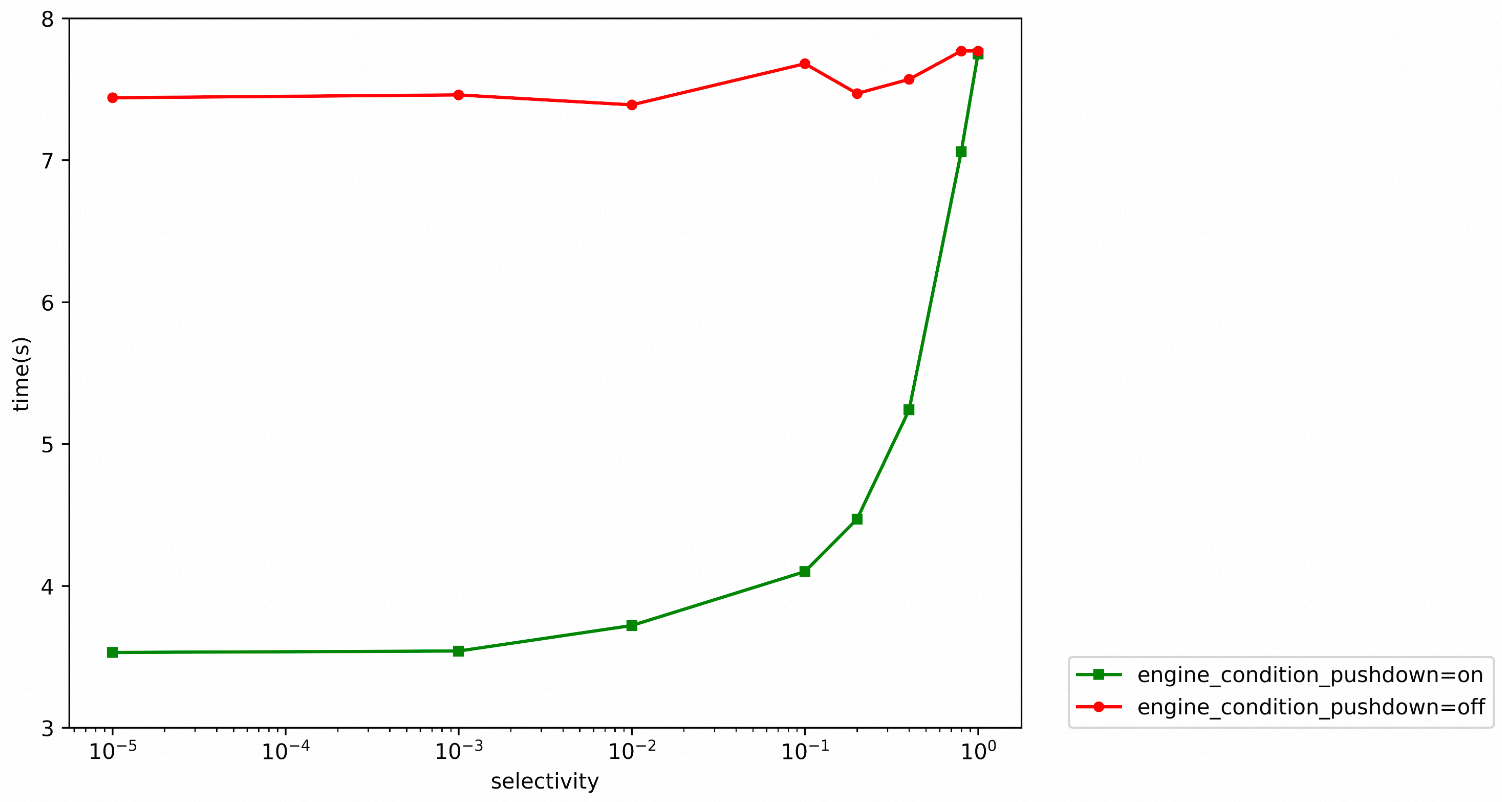
通過上圖可以看到,當條件選擇率selectivity較低時(小于0.1),開啟條件下推相對于關閉條件下推有約一倍的性能提升。
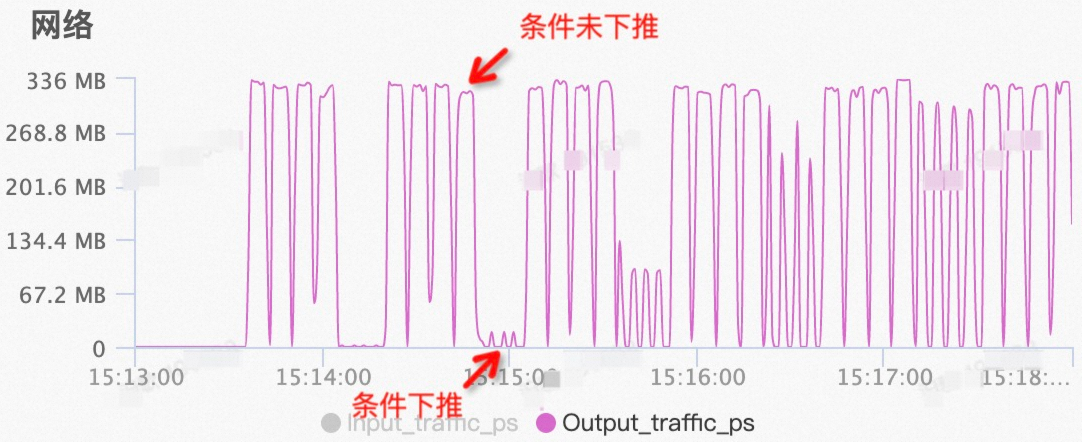
在SQL查詢過程中,交替開啟和關閉條件下推功能。通過PolarDB控制臺的性能監控功能,可以看到SQL查詢期間對于網絡帶寬的占用情況:
當條件不下推時,SQL查詢對于網絡帶寬的占用很高,且在不同選擇率條件下網絡帶寬的占用率都是相同的;
當條件下推且選擇率較低時(小于0.1),網絡的流量非常小且隨著選擇率的增大而逐漸增高。與條件不下推情況下的網絡IO相比有明顯區別。
按需返回列
簡介
Federated查詢在獲取遠程表的數據時,返回的是所有列的值。但在實際情況中,一條查詢可能只需要部分列的值,其他列的值并沒有發揮作用,反而給遠程Server增加了選取、格式轉換數據的代價,占用了更多的網絡傳輸帶寬。因此PolarDB MySQL版在社區版MySQL的基礎上做了進一步的優化,使得Federated查詢只會向遠程Server選取需要的列,大幅減少了遠程Server選取數據的代價和網絡傳輸帶寬,提升了查詢性能,表的列數越多,提升效果越明顯。
示例
以下示例使用包含1百萬條數據、不同列數的表來模擬真實場景。包含100列的表定義如下,重復定義Sysbench表中k、c、pad三列來拓寬表;通過減少字符類型的長度來支持定義更多列,而不至于占用更多的空間。
定義表
CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(15) NOT NULL DEFAULT '',
`pad` char(8) NOT NULL DEFAULT '',
`k1` int(11) NOT NULL DEFAULT '0',
`c1` char(15) NOT NULL DEFAULT '',
`pad1` char(8) NOT NULL DEFAULT '',
...
`k32` int(11) NOT NULL DEFAULT '0',
`c32` char(15) NOT NULL DEFAULT '',
`pad32` char(8) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`)
) ENGINE=InnoDB AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8;開啟和關閉按需返回列功能的SQL查詢
分別在開啟和關閉按需返回列功能的場景下,使用SELECT pad FROM sbtest1進行測試。由于遠程表在pad字段上沒有索引,所以執行計劃使用的是主鍵全表掃描,執行時間(秒)如下:
表列數 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
開啟按需返回列 | 2.97 | 3.1 | 3.09 | 3.96 | 4.55 | 4.95 | 5.74 | 6.91 |
關閉按需返回列 | 3.14 | 3.33 | 4.12 | 6.05 | 8.8 | 12.6 | 20.3 | 38.7 |
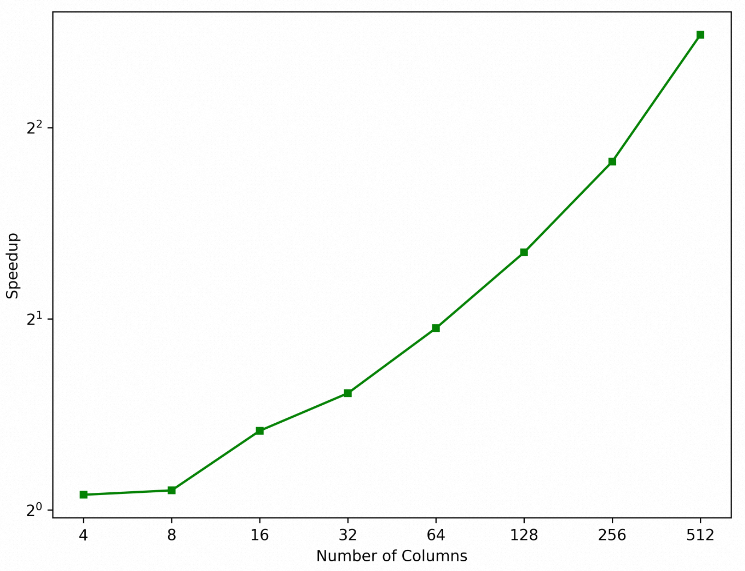
從上述加速比曲線可以看出,隨著表列數的增加,按需返回列功能帶來的加速比接近于線性提升。
此外,按需返回列功能也會增加遠程Server的計劃選擇空間。如果查詢所訪問的列可以使用索引,那么執行計劃會在遠程表上使用索引掃描,而不是全表掃描,這將會進一步帶來性能的提升:
#關閉按需返回列功能進行查詢#
SET federated_fetch_select_field_enabled=OFF;
Query OK, 0 rows affected (0.19 sec)
SELECT SUM(k) FROM federated_col_64.sbtest1;
+--------------+
| SUM(k) |
+--------------+
| 499868973740 |
+--------------+
1 row in set (5.20 sec)
#開啟按需返回列功能進行查詢#
SET federated_fetch_select_field_enabled=ON;
Query OK, 0 rows affected (0.11 sec)
SELECT SUM(k) FROM federated_col_64.sbtest1;
+--------------+
| SUM(k) |
+--------------+
| 499868973740 |
+--------------+
1 row in set (0.45 sec)從上述示例可以看出,在k列上使用索引后,開啟按需返回列功能后查詢性能提升了10倍以上。
[ORDER BY <cols>] LIMIT OFFSET下推
簡介
社區版MySQL在Federated查詢上的分頁查詢由于無法將條件全部下推,所以必須將遠程Server的全部數據返回本地Server,使用WHERE條件過濾后再進行分頁。當PolarDB MySQL版支持條件下推后,如果SQL語句只涉及單個Federated表,且不包含聚合、窗口、UNION、DISTINCT、HAVING等影響結果正確性的語法時,就可以將[ORDER BY <cols>] LIMIT OFFSET語法下推到遠程Server進行處理,僅給本地Server返回需要的數據,本地Server就可以直接輸出結果到客戶端。
使用方法
您可以通過loose_optimizer_switch參數開啟[ORDER BY <cols>] LIMIT OFFSET下推優化功能。具體操作請參見設置集群參數和節點參數。
參數名稱 | 級別 | 描述 |
loose_optimizer_switch | Global/Session | 查詢優化的總控制開關。其中,
|
示例
創建表
CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(15) NOT NULL DEFAULT '',
`pad` char(8) NOT NULL DEFAULT '',
`k1` int(11) NOT NULL DEFAULT '0',
`c1` char(15) NOT NULL DEFAULT '',
`pad1` char(8) NOT NULL DEFAULT '',
...
`k32` int(11) NOT NULL DEFAULT '0',
`c32` char(15) NOT NULL DEFAULT '',
`pad32` char(8) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`)
) ENGINE=InnoDB AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8;開啟和關閉[ORDER BY <cols>] LIMIT OFFSET下推優化功能的SQL查詢
#開啟[ORDER BY <cols>] LIMIT OFFSET下推優化功能進行查詢#
set optimizer_switch='limit_offset_pushdown=on';
Query OK, 0 rows affected (0.05 sec)
EXPLAIN SELECT * FROM federated.sbtest1 LIMIT 100 OFFSET 1000;
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
| 1 | SIMPLE | sbtest1 | NULL | ALL | NULL | NULL | NULL | NULL | 9850101 | 100.00 | Using limit-offset pushdown |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
1 row in set, 1 warning (0.06 sec)
#關閉[ORDER BY <cols>] LIMIT OFFSET下推優化功能進行查詢#
set optimizer_switch='limit_offset_pushdown=off';
Query OK, 0 rows affected (0.05 sec)
EXPLAIN SELECT * FROM federated.sbtest1 LIMIT 100 OFFSET 1000;
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------+
| 1 | SIMPLE | sbtest1 | NULL | ALL | NULL | NULL | NULL | NULL | 9850101 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------+
1 row in set, 1 warning (0.05 sec)#關閉按需ORDER下推#
SET federated_pushdown_order_enabled=OFF;
Query OK, 0 rows affected (0.19 sec)
#開啟按需ORDER下推#
SET federated_pushdown_order_enabled=ON;
Query OK, 0 rows affected (0.11 sec)
mysql> explain select * from federated.sbtest1 order by id limit 100 offset 1000;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------------------+
| 1 | SIMPLE | sbtest1 | NULL | ALL | NULL | NULL | NULL | NULL | 9850101 | 100.00 | Using limit-offset pushdown; Using order pushdown `id` |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------------------+分別在開啟和關閉[ORDER BY <cols>] LIMIT OFFSET下推優化功能的場景下,在1千萬條數據的Sysbench表上使用SELECT * FROM federated.sbtest1 LIMIT 100 OFFSET number進行測試。不同OFFSET值的測試結果如下:
OFFSET 值 | 0 | 10 | 100 | 1000 | 10000 | 100000 | 1000000 | 10000000 |
開啟Limit Offset下推 | 110ms | 168ms | 238ms | 280ms | 219ms | 184ms | 320ms | 1.16s |
關閉Limit Offset下推 | 6.7s | 6.6s | 6.68s | 6.66s | 6.69s | 6.77s | 6.94s | 9.87s |
從上表可以看出,OFFSET值越小,加速越明顯,最高約60倍以上的加速比。