列存索引中TopK算子的實(shí)現(xiàn)
在海量數(shù)據(jù)上求TopK是一個(gè)很經(jīng)典的問題,特別是衍生出的深翻頁查詢,給分析型數(shù)據(jù)庫(kù)帶來了很大的挑戰(zhàn)。本文將介紹PolarDB MySQL版的列存索引(In Memory Column Index,IMCI)特性如何應(yīng)對(duì)這樣的挑戰(zhàn)。
背景
業(yè)務(wù)系統(tǒng)中普遍存在這樣一種場(chǎng)景:根據(jù)給定條件篩選一批記錄,這些記錄按用戶指定的條件排序,以分頁的方式展示。例如,篩選出某個(gè)商家在售的商品,按商品銷量排序,以分頁的方式展示。上述場(chǎng)景在數(shù)據(jù)庫(kù)中,通常以ORDER BY column LIMIT n, m這樣的查詢語句實(shí)現(xiàn)。
假設(shè)業(yè)務(wù)系統(tǒng)中每頁展示100條記錄:
通過
ORDER BY column LIMIT 0, 100可以展示第1頁的數(shù)據(jù);通過
ORDER BY column LIMIT 1000000, 100可以展示第10001頁的數(shù)據(jù)。
在沒有索引的情況下,此類查詢?cè)跀?shù)據(jù)庫(kù)中是通過基于堆的經(jīng)典TopK算法來實(shí)現(xiàn)的,邏輯如下:在內(nèi)存中維護(hù)一個(gè)大小為K的堆,堆頂元素是最小的元素,將遍歷到的數(shù)據(jù)與堆頂元素比較,如果比堆頂元素大,替換堆頂元素,并重建堆。遍歷完數(shù)據(jù)后,堆中的元素即為前K個(gè)最大的元素。當(dāng)翻頁較淺時(shí)(如上文中展示第1頁),K較小,基于堆的TopK算法非常高效。
然而,業(yè)務(wù)場(chǎng)景中也存在翻頁較深的場(chǎng)景(下文中簡(jiǎn)稱“深翻頁”),例如上文中展示第10001頁。該場(chǎng)景下的K非常大,內(nèi)存中可能無法緩存大小為K的堆,也就無法使用上述方式獲得查詢結(jié)果。即便內(nèi)存充足,由于維護(hù)堆的操作訪問內(nèi)存是亂序的,當(dāng)堆非常大時(shí),TopK算法的訪存效率較差,最終的性能表現(xiàn)也差強(qiáng)人意。
PolarDB MySQL版IMCI最初也采用了上述方式來實(shí)現(xiàn)分頁查詢,并在內(nèi)存不足以緩存大小為K的堆時(shí),采用了全表排序后取相應(yīng)的位置記錄的方式,所以在深翻頁時(shí)的性能表現(xiàn)也不是非常理想。為此,在分析了深翻頁場(chǎng)景的特點(diǎn)和傳統(tǒng)方案存在的問題,并調(diào)研了相關(guān)研究和工業(yè)界現(xiàn)有方案后,PolarDB MySQL版重新設(shè)計(jì)了IMCI的Sort/TopK算子。在測(cè)試場(chǎng)景中,重新設(shè)計(jì)的Sort/TopK算子顯著提升了IMCI在深翻頁場(chǎng)景的性能表現(xiàn)。
業(yè)界方案調(diào)研
TopK是一個(gè)非常經(jīng)典的問題,存在多種方案來高效地實(shí)現(xiàn)TopK查詢,這些方案的核心都在于減少對(duì)非結(jié)果集數(shù)據(jù)的操作。已經(jīng)在工業(yè)界中應(yīng)用的方案主要有如下三種:
基于Priority Queue的TopK算法
請(qǐng)參見背景部分內(nèi)容描述。
歸并排序時(shí)基于offset和limit做truncate
當(dāng)內(nèi)存不足以緩存大小為K的Priority Queue時(shí),一些數(shù)據(jù)庫(kù)會(huì)使用歸并排序來處理TopK問題(例如PolarDB IMCI、ClickHouse、SQL Server、DuckDB)。因?yàn)門opK算法只需要獲取排在第[offset, offset+limit)位的記錄,所以在每一次歸并排序時(shí),不需要對(duì)所有數(shù)據(jù)做排序,而是僅輸出長(zhǎng)度為offset+limit的新的sorted run即可。上述merge時(shí)的truncation可以在保證結(jié)果正確性的同時(shí)減少對(duì)非結(jié)果集數(shù)據(jù)的操作。

Self-sharpening Input Filter
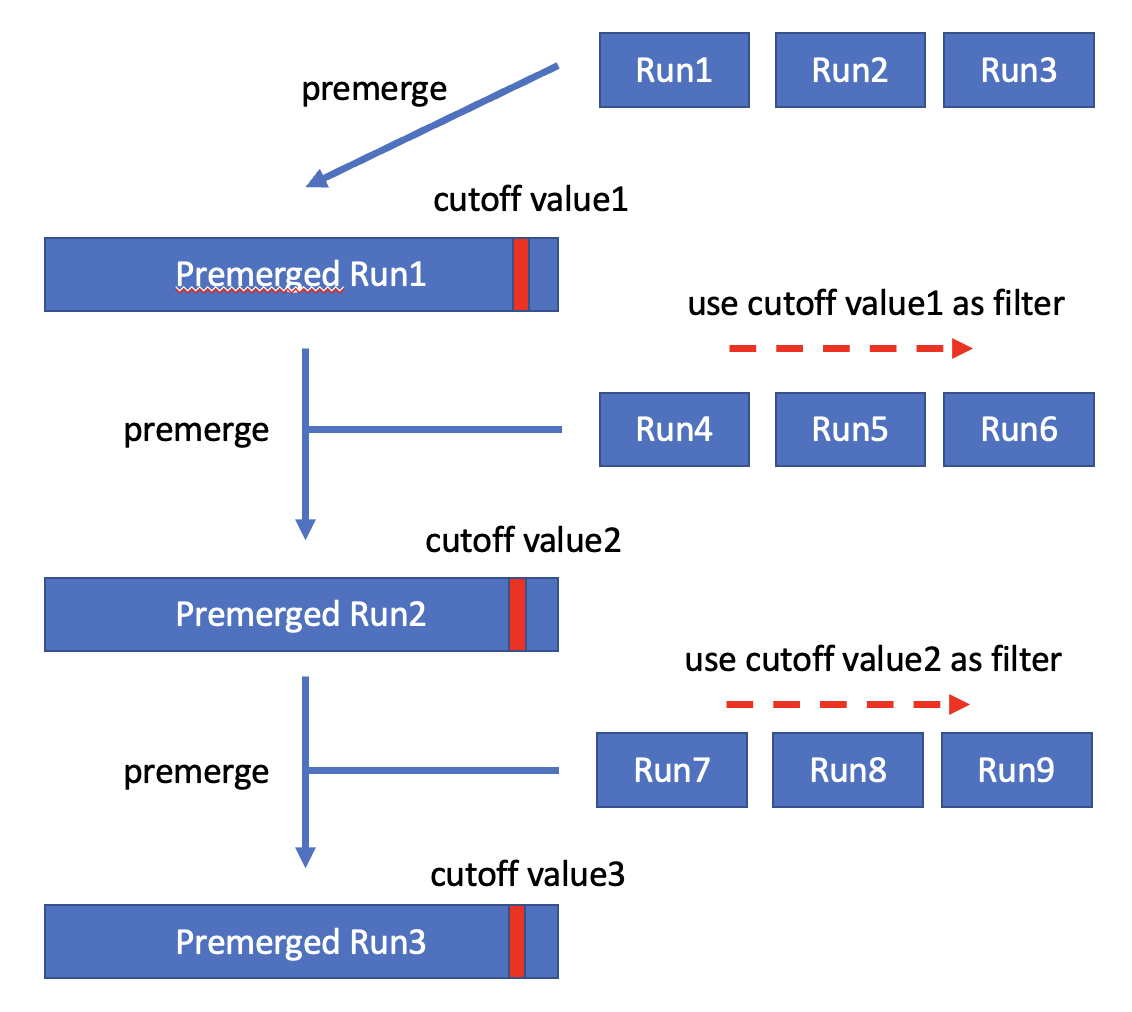
該方案最初是在Goetz Graefe的論文中提出的,云數(shù)據(jù)庫(kù)ClickHouse目前采用了這種方案。該方案在執(zhí)行過程中會(huì)維護(hù)一個(gè)cutoff value,并且保證大于cutoff value的記錄一定不會(huì)出現(xiàn)在TopK的結(jié)果集中。在生成new sorted run時(shí),方案會(huì)使用當(dāng)前的cutoff value對(duì)數(shù)據(jù)進(jìn)行過濾。在生成new sorted run之后,如果K小于new sorted run的長(zhǎng)度,則會(huì)使用new sorted run中第K條記錄替換當(dāng)前cutoff value。由于new sorted run中的數(shù)據(jù)都是經(jīng)過old cutoff value過濾的,因此必定有new cutoff value <= old cutoff value,即cutoff value是一個(gè)不斷sharpening的值。最后只需要合并這些過濾后的sorted run即可得到結(jié)果集。
通過一個(gè)簡(jiǎn)單的例子來說明上述算法:假設(shè)當(dāng)前TopK查詢中K=3,讀取第一批數(shù)據(jù)后生成的sorted run為(1, 2, 10, 15, 21),則cutoff value更新為10。接下來使用cutoff value=10過濾第二批數(shù)據(jù),生成的第二個(gè)sorted run為(2, 3, 5, 6, 8),則cutoff value更新為5。然后讀取并過濾第三批數(shù)據(jù),生成的第三個(gè)sorted run為(1, 2, 3, 3, 3),則cutoff value更新為3。依此類推,不斷sharpen cutoff value從而在接下來過濾更多的數(shù)據(jù)。
如果TopK查詢中K大于單個(gè)sorted run的長(zhǎng)度,該方案會(huì)積累足夠的sorted run(包含的記錄數(shù)量大于K),然后對(duì)這些sorted run提前進(jìn)行merge,從而獲得cutoff value。接下來會(huì)使用cutoff value進(jìn)行過濾并繼續(xù)積累足夠的sorted run,從而獲得更小的cutoff value,依此類推。整個(gè)執(zhí)行過程和K小于單個(gè)sorted run的情況是類似的,區(qū)別在于需要merge足夠的sorted run才能獲得cutoff value。
問題分析
深翻頁是TopK問題中一個(gè)較為特殊的場(chǎng)景,特殊之處在于所求的K特別大,但實(shí)際結(jié)果集很小。例如上文中展示第10001頁的例子,對(duì)于ORDER BY column LIMIT 1000000, 100,K=1,000,100,但最終結(jié)果集只包含100條記錄。該特點(diǎn)會(huì)給上一節(jié)中所述方案帶來如下挑戰(zhàn):
當(dāng)內(nèi)存充足時(shí),如果采用基于Priority Queue的TopK算法,則需要維護(hù)一個(gè)非常大的Priority Queue,隊(duì)列操作對(duì)內(nèi)存的訪問操作是亂序的,訪存效率較差,影響算法實(shí)際運(yùn)行的性能。
當(dāng)內(nèi)存不足時(shí),如果使用歸并排序并基于offset和limit做truncate,則在歸并排序的前期階段,sorted run的長(zhǎng)度可能小于offset+limit,無法進(jìn)行truncate,所有數(shù)據(jù)都將參與排序,truncate的實(shí)際效果受到影響。
本文中的內(nèi)存充足是指,算法中用于管理至少K條記錄的數(shù)據(jù)結(jié)構(gòu)可以在執(zhí)行內(nèi)存中緩存,而不是TopK查詢的輸入數(shù)據(jù)可以在執(zhí)行內(nèi)存中緩存。實(shí)際上本文討論的場(chǎng)景,TopK查詢的輸入數(shù)據(jù)都是遠(yuǎn)大于執(zhí)行內(nèi)存的。
另外,從系統(tǒng)設(shè)計(jì)的角度上看,設(shè)計(jì)深翻頁的解決方案時(shí)還應(yīng)考慮如下兩點(diǎn):
是否采用不同方案來實(shí)現(xiàn)深翻頁和淺翻頁?如果需要使用不同的方案來處理兩種場(chǎng)景,如何判斷深淺翻頁的界線?
如何根據(jù)可用執(zhí)行內(nèi)存的大小自適應(yīng)地選擇內(nèi)存算法或磁盤算法?
方案設(shè)計(jì)
總體設(shè)計(jì)
綜合上述調(diào)研和分析,基于現(xiàn)有的成熟方案,針對(duì)深翻頁問題,PolarDB MySQL版重新設(shè)計(jì)了IMCI的Sort/TopK算子:
內(nèi)存充足時(shí),采用如下的內(nèi)存算法:
采用Self-sharpening Input Filter的設(shè)計(jì),避免訪存效率的問題。
并在此基礎(chǔ)上利用SIMD指令提升過濾效率。
深淺翻頁均采用該內(nèi)存算法,不需要判斷深淺翻頁的界線。
內(nèi)存不足時(shí),采用如下的磁盤算法:
采用歸并排序時(shí)基于offset和limit做truncate的方案。
并在此基礎(chǔ)上利用ZoneMap在歸并排序的前期階段做pruning,盡可能地減少對(duì)非結(jié)果集數(shù)據(jù)的操作。
動(dòng)態(tài)選擇內(nèi)存磁盤算法:不依賴固定的閾值來選擇使用內(nèi)存算法或磁盤算法,而是在執(zhí)行過程中根據(jù)可用執(zhí)行內(nèi)存的大小,動(dòng)態(tài)調(diào)整所用算法。
由于Self-sharpening Input Filter和歸并排序時(shí)基于offset和limit做truncate的方案在前文中已經(jīng)介紹,因此接下來僅介紹選擇這兩種方案的原因,并介紹利用SIMD指令提升過濾效率、利用ZoneMap做pruning以及動(dòng)態(tài)選擇內(nèi)存磁盤算法的部分。
SIMD Accelerated Self-sharpening Input Filter
在內(nèi)存充足時(shí),直接采用Self-sharpening Input Filter的設(shè)計(jì),主要基于兩個(gè)原因:
Self-sharpening Input Filter不管是使用cutoff value進(jìn)行過濾,還是pre-merge,訪問內(nèi)存的模式都是順序的,可以避免Priority Queue訪存效率的問題。
該設(shè)計(jì)無論翻頁深淺都具有優(yōu)異的性能,在應(yīng)用時(shí)不需要考慮深淺翻頁的界線。
實(shí)際上,Self-sharpening Input Filter在某種程度上和基于Priority Queue的算法是類似的,cutoff value類似堆頂,都用于過濾后續(xù)讀取的數(shù)據(jù),兩者的不同之處在于,基于Priority Queue的算法會(huì)實(shí)時(shí)更新堆頂,而Self-sharpening Input Filter則將數(shù)據(jù)積累在sorted run中,以batch的方式更新cutoff value。
使用cutoff value進(jìn)行過濾是Self-sharpening Input Filter中很重要的過程,涉及數(shù)據(jù)比較,操作簡(jiǎn)單重復(fù)但非常頻繁,因此使用SIMD指令來加速這一過程。由于cutoff value過濾和TableScan中使用Predicate過濾是類似的,因此在具體實(shí)現(xiàn)中直接復(fù)用處理Predicate的表達(dá)式,提升過濾的效率,減少計(jì)算TopK的時(shí)間。
Zonemap-based Pruning
在內(nèi)存不足時(shí),采用歸并排序,并基于offset和limit做truncate,主要原因如下:
如果在內(nèi)存不足時(shí)繼續(xù)使用Self-sharpening Input Filter的設(shè)計(jì),就需要將積累的sorted run落盤,并且在pre-merge時(shí)同樣使用外排序算法,產(chǎn)生大量的讀寫磁盤的操作,相對(duì)于內(nèi)存充足場(chǎng)景下的Self-sharpening Input Filter有額外的開銷。當(dāng)K非常大時(shí),pre-merge時(shí)的外排序可能還會(huì)涉及大量非結(jié)果集數(shù)據(jù),因?yàn)樽罱K只需要獲取排在第[offset, offset + limit)位的記錄,而不關(guān)心排在第[0, offset)位的記錄。
在這種場(chǎng)景下,可以使用歸并排序,在生成sorted run的階段僅將sorted run落盤,然后使用統(tǒng)計(jì)信息進(jìn)行pruning,避免不必要的讀寫磁盤的操作,也可以盡可能地避免對(duì)非結(jié)果集數(shù)據(jù)的操作。
以下圖為例來說明使用統(tǒng)計(jì)信息進(jìn)行pruning的原理。下圖中,箭頭表示數(shù)軸,代表sorted run的矩形的左右兩端在數(shù)軸上對(duì)應(yīng)的位置表示sorted run的min/max值,Barrier表示pruning所依賴的一個(gè)閾值。 ARRIER
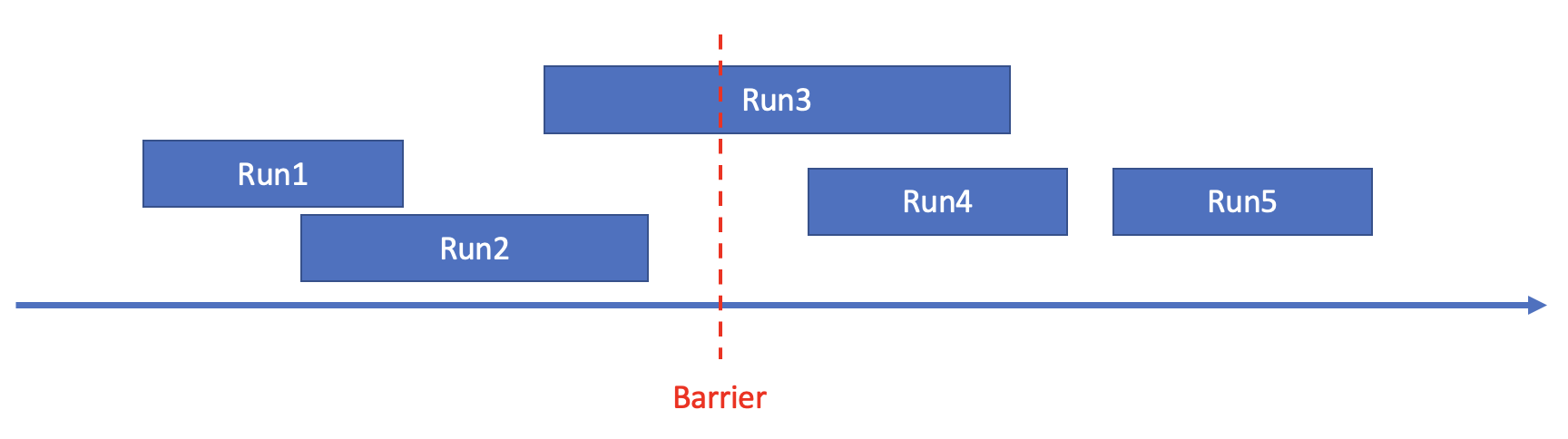
任意一個(gè)Barrier可以將所有sorted run分為三類:
類型A:min value of sorted run<Barrier&&max value of sorted run<Barrier,如上圖中Run1,Run2。
類型B:min value of sorted run<Barrier&&max value of sorted run>Barrier,如上圖中Run3。
類型C:min value of sorted run>Barrier&&max value of sorted run>Barrier,如上圖中Run4,Run5。
對(duì)于任意一個(gè)Barrier,如果類型A和類型B中的數(shù)據(jù)量<TopK查詢中的offset,那么類型A中的數(shù)據(jù)必然排在第[0, offset)位,類型A中的sorted run可以不參與后續(xù)的merge。
對(duì)于任意一個(gè)Barrier,如果類型A中的數(shù)據(jù)量>TopK查詢中的offset+limit,那么類型C中的數(shù)據(jù)必然排在第[offset+limit, N)位,類型C中的sorted run可以不參與后續(xù)的merge。
根據(jù)上述原理,使用統(tǒng)計(jì)信息進(jìn)行pruning的具體流程如下:
構(gòu)建包含sorted run的min/max信息的Zonemap。
基于Zonemap尋找一個(gè)盡可能大的Barrier1滿足類型A和類型B中的數(shù)據(jù)量<TopK查詢中的offset。
基于Zonemap尋找一個(gè)盡可能小的Barrier2滿足類型A中的數(shù)據(jù)量>TopK查詢中的offset+limit。
使用Barrier1和Barrier2對(duì)相關(guān)sorted run進(jìn)行pruning。
動(dòng)態(tài)選擇內(nèi)存磁盤算法
內(nèi)存算法和磁盤算法不同,如果使用一個(gè)固定的閾值來作為選擇內(nèi)存算法或磁盤算法的依據(jù)(比如K小于閾值時(shí)使用內(nèi)存算法,否則使用磁盤算法),那么針對(duì)不同的可用執(zhí)行內(nèi)存就需要設(shè)置不同的閾值,帶來了人工干預(yù)的開銷。
因此PolarDB MySQL版設(shè)計(jì)了一個(gè)簡(jiǎn)單的回退機(jī)制,可以在執(zhí)行過程中根據(jù)可用執(zhí)行內(nèi)存的大小,動(dòng)態(tài)調(diào)整所用算法:
無論可用執(zhí)行內(nèi)存有多大,首先嘗試以內(nèi)存算法計(jì)算TopK。
在內(nèi)存算法的執(zhí)行過程中,如果內(nèi)存始終都是充足的,直接使用內(nèi)存算法完成整個(gè)計(jì)算過程。
在內(nèi)存算法的執(zhí)行過程中,如果出現(xiàn)內(nèi)存不足的情況(例如,K比較大時(shí),可用執(zhí)行內(nèi)存不足以緩存足夠的sorted run使其包含的記錄數(shù)量大于K,或者可用執(zhí)行內(nèi)存不足以完成pre-merge的過程),那么執(zhí)行回退機(jī)制。
回退機(jī)制:采集內(nèi)存中已積累的sorted run的min/max信息,以便于后續(xù)使用Zonemap進(jìn)行pruning,然后將sorted run落盤,這些sorted run將會(huì)參與磁盤算法的計(jì)算過程。
執(zhí)行完回退機(jī)制后,使用磁盤算法完成整個(gè)計(jì)算過程。
由于內(nèi)存算法和磁盤算法采用相同的數(shù)據(jù)組織格式,因此回退機(jī)制并不需要對(duì)數(shù)據(jù)進(jìn)行重新組織,開銷較小。另外,內(nèi)存算法只會(huì)過濾非結(jié)果集的數(shù)據(jù),因此直接使用內(nèi)存算法已積累的sorted run參與磁盤算法的計(jì)算過程不會(huì)有正確性的問題。
其他
延遲物化
延遲物化是一個(gè)工程實(shí)現(xiàn)方面的優(yōu)化,指的是在生成sorted run時(shí)僅物化RowID和ORDER BY相關(guān)的表達(dá)式(列),在計(jì)算出TopK的結(jié)果集后,再根據(jù)結(jié)果集中的RowID從存儲(chǔ)上獲取查詢需要輸出的列。延遲物化相比于在生成sorted run時(shí)就物化查詢需要輸出的所有列有兩個(gè)優(yōu)勢(shì):
物化RowID的空間占用更小,在可用執(zhí)行內(nèi)存一定的情況下,可以使用內(nèi)存算法處理更大的數(shù)據(jù)量。
計(jì)算TopK的過程需要調(diào)整數(shù)據(jù)順序,涉及對(duì)數(shù)據(jù)的Copy/Swap。如果在生成sorted run時(shí)就物化查詢需要輸出的所有列,則計(jì)算過程中對(duì)一條記錄的Copy/Swap需要對(duì)每一列都進(jìn)行相應(yīng)操作,帶來很大的overhead。而如果僅物化RowID,則可以降低Copy/Swap的代價(jià)。
延遲物化的不足之處在于根據(jù)結(jié)果集中的RowID從存儲(chǔ)上獲取查詢需要輸出的列時(shí),可能會(huì)產(chǎn)生一些隨機(jī)IO。分析后發(fā)現(xiàn)深翻頁場(chǎng)景雖然K特別大,但實(shí)際結(jié)果集很小,因此使用延遲物化時(shí)隨機(jī)IO產(chǎn)生的overhead較小。
計(jì)算下推
應(yīng)用Self-sharpening Input Filter時(shí),會(huì)將不斷更新的cutoff value下推至table scan算子,作為SQL中一個(gè)新的predicate,在table scan算子獲取數(shù)據(jù)時(shí)根據(jù)這個(gè)新的predicate,復(fù)用pruner對(duì)pack(或稱為row group)進(jìn)行過濾。
計(jì)算下推可以從兩個(gè)方面提升TopK查詢的性能:
減少IO:table scan時(shí)避免讀取僅包含非結(jié)果集數(shù)據(jù)的pack/row group。
減少計(jì)算:被過濾的pack/row group中的數(shù)據(jù)將不再參與table scan上層算子的后續(xù)計(jì)算。
測(cè)試結(jié)果
在TPCH 100 GB的數(shù)據(jù)集上對(duì)方案進(jìn)行簡(jiǎn)單的驗(yàn)證:
select
l_orderkey,
sum(l_quantity)
from
lineitem
group by
l_orderkey
order by
sum(l_quantity) desc
limit
1000000, 100;測(cè)試結(jié)果如下:
PolarDB IMCI | ClickHouse | MySQL |
11.63 sec | 23.07 sec | 353.15 sec |